编写高效 C++
无论你的应用领域是什么,程序的 efficiency 都很重要。如果你的产品要在市场上与其他产品竞争,那么速度可能就是关键差异点:面对一个更慢的程序和一个更快的程序,你会选哪个?没有人会买一个需要两周才能启动完成的 operating system。即便你并不打算售卖自己的产品,它们也一样会有用户;而如果用户不得不把大量时间浪费在等待程序完成任务上,他们也绝不会高兴。
现在,你已经理解了专业级 C++ design 和 coding 的核心概念,也已经接触过这门语言中更复杂的一些能力,是时候把 performance 纳入你的程序设计视野了。写出高效程序,既涉及设计层面的思考,也涉及实现层面的细节。虽然本章在全书中位置偏后,但请记住:performance 应当从项目一开始就被纳入考虑。
性能与效率概览
Section titled “性能与效率概览”在进一步展开之前,先明确一下本书中使用的 performance 与 efficiency 这两个词分别是什么意思。程序的 performance 可以指多个方面,例如速度、内存使用、磁盘访问和网络使用。本章聚焦的是速度 performance。而 efficiency 用在程序上时,意味着“尽可能减少浪费地运行”。一个高效程序会在既定条件下尽可能快地完成任务。某个程序即使并不“快”,也仍可能是高效的——只要它所处的应用领域本身就不允许快速完成任务。
还要注意,本章标题“编写高效 C++”指的是“写出运行高效的程序”,而不是“高效地写程序”。换句话说,读完这一章以后,你节省下来的主要不是你自己的时间,而是你用户的时间。
提升效率的两种思路
Section titled “提升效率的两种思路”Language-level efficiency 指的是尽量高效地使用语言本身,例如通过按引用传参而不是按值传参来减少不必要开销。但这只能把你带到一定程度。更重要的是 design-level efficiency:也就是选择更高效的 algorithm,避免不必要的步骤和计算,并做出合适的设计层优化。很多时候,优化现有代码的核心并不是去抠某几行语法细节,而是把一个糟糕的 algorithm 或数据结构换成一个更好的版本。
正如前面所说,efficiency 对任何应用领域都很重要。不过,程序中还有一小类场景——比如 system-level software、embedded system、密集计算应用以及 real-time game——它们对 efficiency 的要求会高到近乎苛刻。多数程序并不会。除非你就在写这种高性能软件,否则你大概率不需要为了榨干每一滴速度,把 C++ 代码抠到极致。可以把它想象成普通家用车和赛车之间的区别:每辆车都应当足够高效,但 sports car 则对 performance 有极高要求。你不会为了让家用车跑得像赛车一样快,而花掉大量时间去做根本用不上的极限优化——因为它们本来也不会超过每小时 70 英里。
C++ 是低效语言吗?
Section titled “C++ 是低效语言吗?”一些 C 程序员常常抗拒在高性能场景中使用 C++。他们会说:由于 C++ 包含 exception、virtual member function 这类 high-level construct,它天生就比 C 或其他类似的 procedural language 更低效。但这种说法有明显问题。
当讨论一门语言的效率时,你不能忽略 compiler 的作用。别忘了:你写下的 C 或 C++ 代码,并不是计算机实际执行的代码。compiler 会先把它翻译成 machine language,并在此过程中做优化。这意味着,你不能简单地把 C 和 C++ 程序跑 benchmark 再直接比较结果,因为你真正比较到的,其实是两种语言在 compiler 优化之后的产物,而不只是语言本身。C++ compiler 能把语言中的很多 high-level construct 优化掉,从而生成与 C 程序相近、甚至更优的 machine code。事实上,如今投入到 C++ compiler 上的研究和开发资源,往往比纯 C compiler 还更多,因此 C++ 代码实际上完全可能被优化得更好,跑得比 C 更快。
当然,批评者仍会坚持说:C++ 的某些特性不可能被完全优化掉。例如,第 10 章“深入继承技巧”解释过,virtual member function 需要依赖 vtable,也就是 virtual table,并在运行时增加一层间接跳转,因此理论上可能比普通非虚函数调用更慢。但仔细想想,这个论点其实并不成立。virtual member function 带来的不只是一次函数调用,它还带来了“运行时决定究竟调用哪个函数”的能力。一个与之等价的 non-virtual 实现,本来也需要先用条件判断决定该调哪个函数。如果你根本不需要这种额外语义,那你完全可以直接使用 non-virtual function。C++ 的一个普遍设计原则就是:“如果你不用某个特性,你就不需要为它买单。”如果你不使用 virtual member function,那么你也不会因为语言“本来可以使用它”就平白付出额外性能成本。因此,在 performance 层面上,C++ 中的 non-virtual function call 与 C 里的普通函数调用并没有本质差别。
更重要的是,C++ 提供的这些 high-level construct,反而让你更容易写出结构更清晰、设计层面更高效、可读性更强、也更易维护的程序,还能有效避免无谓的 dead code 和冗余实现积累。
就开发体验、performance 与代码可维护性而言,我认为选择 C++,通常会比选择 C 这类 procedural language 更有利。
当然,也有其他更高层的 object-oriented language,例如 C# 和 Java,它们都运行在 virtual machine 之上。而 C++ 代码是直接交给 CPU 执行的;它并不需要某个虚拟机来运行你的代码。C++ 离硬件更近,因此在大多数场景下,它确实会比 C# 和 Java 这类语言更快。
语言层面的效率
Section titled “语言层面的效率”很多书、文章以及程序员本身,都会花大量时间试图说服你把各种 language-level optimization 套到代码里。这些 tips and tricks 当然有价值,在某些情况下也的确能提升程序速度。然而,与整体 design 和 algorithm 选择相比,它们的重要性要低得多。你可以在代码里到处 pass-by-reference,但如果你的程序本质上做了两倍于实际需要的磁盘写入,那它依然不可能快。人很容易沉迷于 reference 和 pointer 这些局部细节,却忘了大局。
另外,其中一些 language-level 技巧,本来也能由优秀的 optimizing compiler 自动替你完成。一个经验法则是:除非 profiler(本章后面会讲)明确告诉你某个区域是 bottleneck,否则不要花时间去优化那一小块代码。
尽管如此,某些 language-level optimization——例如 pass-by-reference——依然可以被视为良好 coding style 的一部分。
本书一直尽量在这些策略之间保持平衡。因此,我在这里会列出我认为最有价值的一些 language-level optimization。这个列表当然并不完整,但足以作为写出更优代码的良好起点。不过,也请务必继续阅读并实践本章后面关于 design-level efficiency 的建议,因为它们通常更重要。
对 language-level optimization 一定要谨慎。我的建议是:先做出干净、结构良好的 design 与实现;之后使用 profiler,只有在 profiler 明确指出某部分代码是 performance bottleneck 时,再针对性地投入优化时间。
高效处理对象
Section titled “高效处理对象”C++ 在幕后会替你做很多事情,尤其是在 object 处理方面。因此,你始终应当意识到自己所写代码带来的 performance 影响。只要遵守一些简单原则,你的代码通常就会更高效。需要说明的是,这些原则主要针对 object,而不是 bool、int、float 之类 primitive type。
按值传递还是按引用传递
Section titled “按值传递还是按引用传递”第 1 章“C++ 与标准库速成”和第 9 章“精通类与对象”都给出过一个判断规则,用来决定在函数参数上传值还是传引用。这个规则值得在这里再重复一次。
如果某个参数在函数内部“本来就需要被复制”,并且它所属类型支持 move semantics,那么优先使用 pass-by-value;否则,就使用 reference-to-const。
使用 pass-by-value 时,有几个问题必须记住。如果你把某个 derived class 的 object 以值传递的方式,传给一个以 base class 作为参数类型的函数,那么这个 derived object 会被 sliced 成 base class 的形态,从而造成信息丢失;详见第 10 章。另一方面,pass-by-value 还可能带来本可通过 pass-by-reference 避免的复制开销。
不过,在某些场景下,pass-by-value 反而正是最优选择。比如,考虑下面这个用于表示人的类:
class Person{ public: Person() = default; explicit Person(string firstName, string lastName, int age) : m_firstName { move(firstName) }, m_lastName { move(lastName) } , m_age { age } { } virtual ~Person() = default;
const string& getFirstName() const { return m_firstName; } const string& getLastName() const { return m_lastName; } int getAge() const { return m_age; }
private: string m_firstName, m_lastName; int m_age { 0 };};正如前面的规则所建议的那样,Person 构造函数按值接收 firstName 和 lastName,然后再把它们 move 给 m_firstName 与 m_lastName,因为反正这些值最终无论如何都要被复制一份进 object 中。这种写法在第 9 章里已有解释。
现在来看下面这个按值接收 Person object 的函数:
void processPerson(Person p) { /* 处理该 person。 */ }你可以这样调用它:
Person me { "Marc", "Gregoire", 42 };processPerson(me);表面上看,这似乎和下面这个按引用接收的版本没什么区别:
void processPerson(const Person& p) { /* 处理该 person。 */ }调用方式完全一样。但如果你用的是第一个“按值传递”的版本,就意味着为了初始化 processPerson() 的参数 p,对象 me 必须先被复制一次,而这会触发 copy constructor。即使你没有手写 copy constructor,compiler 也会自动生成一个,把各个 data member 逐个复制。表面上看,Person 不过就三个 data member;但问题是,其中两个是 string,而 string 自己也是 object,也各自会走自己的 copy constructor。相比之下,按引用传递的版本则完全没有这些复制成本。因此,在这个例子里,pass-by-reference 在函数进入时就已经避免了相当多的开销。
而且事情还没完。别忘了,在第一个版本里,参数 p 是 processPerson() 的局部变量,因此函数退出时它还必须被销毁。这意味着还要调用 Person destructor,而后者又会进一步调用所有 data member 的 destructor。由于 string 自带 destructor,所以只要你按值传递这个 Person,函数退出时就会额外发生三次析构调用。而在按引用版本中,这些析构根本不存在。
按值返回还是按引用返回
Section titled “按值返回还是按引用返回”为了避免不必要的 object copy,你当然可以考虑让函数按 reference 返回 object。但不幸的是,这在某些场景中根本做不到,例如当你实现重载的 operator+ 以及类似运算符时。而且,你绝对不应返回指向局部对象的 reference 或 pointer,因为这些局部对象会在函数退出时被销毁。
不过,大多数情况下,从函数中按值返回 object 完全没有问题。这得益于强制性与非强制性的 copy/move elision,以及 move semantics;这两者都会优化“按值返回 object”的成本,而它们都已在第 9 章中详细讨论。
按引用捕获异常
Section titled “按引用捕获异常”正如第 14 章“错误处理”中所说,你应当按 reference 捕获 exception,以避免 slicing 和不必要的复制。抛出 exception 本身就是相对昂贵的,因此任何能进一步改善它效率的小细节,都会有帮助。
使用移动语义
Section titled “使用移动语义”你应确保自己的 class 支持 move semantics(见第 9 章),无论这种支持来自 compiler 自动生成的 move constructor / move assignment operator,还是你手动实现的版本。根据 Rule of Zero(同样见第 9 章),你应尽量把 class 设计成让 compiler 自动生成的 copy / move constructor 以及 copy / move assignment operator 就足够使用。如果 compiler 不能隐式生成这些操作,那么先试试看是否能显式 = default 它们;如果这也行不通,那就需要你自己实现。只要 object 支持 move semantics,大量操作就会更高效,尤其是配合 Standard Library container 和 algorithm 使用时更是如此。
避免创建临时对象
Section titled “避免创建临时对象”在不少场景下,compiler 会自动构造临时的、匿名的 object。第 9 章解释过:如果某个类实现了全局 operator+,那么只要其他类型能够被转换成该类 object,你就可以把这个类的 object 和那些类型相加。例如,第 9 章里的 SpreadsheetCell 类定义(支持 arithmetic operator)部分长这样:
export class SpreadsheetCell{ public: // 其他构造函数为了简洁而省略。 SpreadsheetCell(double initialValue); // 其余部分为了简洁而省略。};
export SpreadsheetCell operator+(const SpreadsheetCell& lhs, const SpreadsheetCell& rhs);这个 non-explicit、接收 double 的构造函数,让你可以写出如下代码:
SpreadsheetCell myCell { 4 }, aThirdCell;aThirdCell = myCell + 5.6;aThirdCell = myCell + 4;第二条语句会先根据 5.6 构造一个临时 SpreadsheetCell object,然后用 myCell 和这个临时 object 作为参数来调用 operator+;结果再保存进 aThirdCell。第三条语句也是同样的过程,只不过 4 还得先被提升成 double,才能调用 SpreadsheetCell 的 double 构造函数。
这个例子里最重要的一点是:在这两次加法中,compiler 都不得不额外生成一个匿名的 SpreadsheetCell 临时对象。而这个对象既要被构造,也要在之后被析构;也就是说,你实际会付出 constructor / destructor 调用的成本。如果你对此仍有怀疑,不妨在 constructor 和 destructor 里插入 print(),然后观察运行输出。
更一般地说,只要你的代码为了让某个表达式成立,而把一种类型的变量转换成另一种类型,compiler 通常都会构造临时对象。这个规则尤其常见于函数调用。例如,假设你写了下面这个函数原型:
void doSomething(const SpreadsheetCell& s);你于是就可以这样调用它:
doSomething(5.56);这时,compiler 会借助 double 构造函数,从 5.56 构造一个临时 SpreadsheetCell object,然后把这个临时 object 传给 doSomething()。要注意的是,如果你去掉参数 s 上的 const,那么就不能再用 constant 去调用 doSomething() 了;你必须传入一个 lvalue。
一般而言,你应尽量避免让 compiler 被迫去构造临时 object。虽然有些场景确实无法避免,但至少你应该清楚这种“特性”的存在,这样在面对 performance 或 profiling 结果时,就不会被它们吓一跳。
另外,compiler 会借助 move semantics 让临时 object 的处理更高效一些。这也是为什么你应当确保自己的 class 支持 move semantics。详见第 9 章。
使用像第 18 章“标准库容器”中讨论过的 C++ Standard Library container,有个非常大的好处:它们会替你处理所有内存管理问题。你在其中不断加入元素时,container 会自动增长。但有时,这也会带来 performance 惩罚。以 std::vector 为例:它要求元素在内存中连续存放。一旦它需要扩容,就必须分配一块新的内存,然后把旧内存里的全部元素 move(或 copy)过去。如果你在循环中对一个 vector 做数百万次 push_back(),这种扩容就会带来非常明显的开销。
如果你提前知道将要加入 vector 的元素数量,或者至少有个大致估计,那么就应当在开始插入之前先预分配足够内存。vector 有两个相关概念:capacity,也就是“不触发重新分配时最多还能容纳多少元素”;以及 size,也就是当前实际包含了多少元素。你可以通过 reserve() 来预分配 capacity,也可以通过 resize() 调整 vector 大小。更多细节见第 18 章。
使用内联函数
Section titled “使用内联函数”有些 compiler 会把 inline 关键字当作一种提示,告诉 optimizer 更积极地优化这个函数(尤其是在较低优化级别时)。如果你确认某个很小的函数是性能瓶颈,可以尝试把它标记为 inline。不过,不要滥用这个特性,因为它会破坏一个很基本的 design 原则:interface 与 implementation 应分离,使 implementation 可以在不影响 interface 的前提下演进。
Section titled “ 标记不可达代码”C++ Standard Library 在 <utility> 中提供了 std::unreachable,可用于把 source code 的某个位置标记为 unreachable。这样做能够帮助 compiler 更好地优化最终生成的 executable code。例如,1下面这个函数接收一个整数参数,而函数作者非常确定:这个参数只可能是 0、1、2 或 3,不会出现其他值。
void doSomething(int number_that_is_only_0_1_2_or_3){ switch (number_that_is_only_0_1_2_or_3) { case 0: case 2: handle0Or2(); break; case 1: handle1(); break; case 3: handle3(); break; }}但是,在 compiler 看来,它看到的只是一个 int 参数,因此它并不知道这个值只会是 0、1、2 或 3。虽然函数中的 switch 已经覆盖了参数的所有可能值,但 compiler 并不知道这一点,因此它必须生成额外的 executable code,用来先判断该参数究竟是 0、1、2、3 还是其他值;若是其他值,就还得跳到 switch 后的第一条语句去执行。
如果你给这个 switch 增加一个 default 分支,并明确告诉 compiler:这个 default 分支永远不可能被走到,那么 compiler 就可以省掉那部分额外检查逻辑,直接跳到正确的 case。在某些场景下——例如紧凑 loop 中——这可能提升最终 executable code 的 performance。
void doSomething(int number_that_is_only_0_1_2_or_3){ switch (number_that_is_only_0_1_2_or_3) { // 与之前相同的 0、1、2 和 3 情况,为了简洁而省略... default: unreachable(); }}如果程序在运行期真的走到了 unreachable(),那么结果就是 undefined behavior。例如,用参数 8 去调用 doSomething(),就会触发 undefined behavior,而 compiler 完全可以在这种情况下随意选择它想做的事。
设计层面的效率
Section titled “设计层面的效率”你的程序 performance 受 design 决策影响,远比受“按引用传参”这类语言细节影响更大。举个例子,如果你为程序中的某项基础任务选择了一个 O(n^2) 的 algorithm,而不是一个更简单、但复杂度只有 O(n) 的实现,那么你很可能做了“本来根本没必要做”的平方级操作量。换成数字更直观:一个采用 O(n^2) algorithm、执行了 1,000,000 次操作的任务,如果换成一个 O(n) algorithm,可能只需要 1,000 次操作。即便你在语言层面对那 1,000,000 次操作进行了看似极限的优化,它依然敌不过“其实压根只需要 1,000 次”的更好 algorithm。永远都要认真选择你的 algorithm。关于 algorithm 设计与 big-O notation,可参考本书第二部分,尤其是第 4 章“设计专业级 C++ 程序”。
除了 algorithm 选择之外,design-level efficiency 还包括不少具体策略。与其自己重写数据结构和 algorithm,不如尽量复用现有实现,例如 C++ Standard Library、Boost(boost.org)或其他库中的现成组件,因为这些实现通常出自专家之手,而且已经被大量使用,很多 bug 也大多早已被发现并修复。你还应当考虑在 design 中纳入 multithreading,以便充分利用机器上的全部计算能力。详见第 27 章“使用 C++ 进行多线程编程”。本节剩余部分还会介绍另外两种 design-level optimization 技术:caching 与 object pool。
在需要处使用缓存
Section titled “在需要处使用缓存”Caching 指的是:把某些东西存起来,以便将来复用,避免再次获取或重复计算。你可能已经从计算机硬件中熟悉这个概念。现代 processor 自带的 memory cache,会把最近或高频访问的内存值保存在比主存更快的位置。由于绝大多数被访问过的内存位置,往往会在短时间内再次被访问,因此硬件层面的 caching 可以显著加快计算。
软件中的 caching 采用的是同样思路。如果某项任务或计算特别慢,就应先确认你是不是在不必要地重复做它。第一次完成该任务时,就应把结果保存在内存中,以便将来直接复用。下面这些任务通常都比较慢:
- Disk access: 不要在程序中反复打开并读取同一个文件。如果内存允许,而你又会频繁访问该文件,就把内容缓存到 RAM 中。
- Network communication: 只要程序需要通过网络通信,它就会受到网络状况波动影响。应当像对待文件访问一样对待网络访问,把尽可能多的静态信息缓存起来。
- Mathematical computation: 如果某个复杂计算结果会在多个地方用到,那就只算一次,再共享结果。但如果它本身并不复杂,那么从 cache 读取未必比重新计算更快,最好通过 profiler 来确认。
- Object allocation: 如果程序中需要大量创建和使用生命周期很短、但创建成本高的 object,可以考虑稍后会介绍的 object pool。
- Thread creation: 创建线程很慢。你也可以像缓存 object 一样“缓存线程”,也就是使用 thread pool。
Caching 的一个常见问题在于:cache 中保存的内容往往只是底层真实信息的副本,而原始数据本身可能在 cache 生命周期内发生变化。例如,你可能把配置文件内容缓存起来,避免重复读取;但如果用户在程序运行时修改了该配置文件,那么 cache 中的内容立刻就会过时。这种情况下,你就需要某种 cache invalidation 机制:一旦底层数据变化,要么停止使用旧 cache,要么自动重建它。
一种常见的 cache invalidation 技术,是让负责管理底层数据的实体在发生变化时主动通知你的程序。这可以通过程序向其注册一个 callback 来完成。另一种方式,则是程序自己轮询某些事件,一旦检测到条件成立,就自动重新填充 cache。无论你采用哪种具体 cache invalidation 方案,都应在真正依赖 cache 之前,先认真想清楚这些问题。
如果你打算把 caching 加进某个数据结构中,请确保你的 design 把这些缓存细节彻底隐藏在 public interface 之后。client code 不应意识到内部实现用了任何 caching。这也能让你在不影响 public interface 的前提下,自由替换底层 caching mechanism。
object pool 有很多种。本节讨论的是其中一种:它会一次性分配一大块内存,并在这块内存里原地创建多个较小 object。这些 object 可以被发放给 client 使用;当 client 用完后,它们又会被放回 pool 中重用,而不需要为每个 object 单独再次调用 memory manager 做分配或释放。
下面这个 object pool 实现,在“对象具有很大的 data member”时尤其能发挥作用,稍后的 benchmark 会展示这一点。但 object pool 到底是不是某个具体 use case 的正确答案,最终仍只能靠 profiling 来决定。
对象池的实现
Section titled “对象池的实现”这一节会给出一个 object pool class template 的实现,可以直接拿来在程序中使用。其实现维护了一份“按 chunk 划分的 T object 内存块 vector”,同时还维护了一份“所有空闲 object 的指针列表 vector”。pool 通过 acquireObject() 成员函数把 object 发给外部;如果调用 acquireObject() 时已经没有空闲 object,它就会额外分配一个新的 chunk。acquireObject() 的返回值是一个 shared_ptr。
这里的实现使用的是 vector 这类 Standard Library container,而且没有额外同步机制。因此,这个版本不是 thread-safe 的。想要把它改成 thread-safe,可参考第 27 章。
下面是完整的 class 定义,代码中的注释会解释各部分细节。这个 class template 有两个模板参数:一是 pool 中存储的 object 类型 T,二是用于分配/释放 chunk 的 allocator 类型。
// 提供一个可用于任何类的对象池。//// acquireObject() 从空闲对象列表中返回一个对象。如果// 没有更多的空闲对象,acquireObject() 会创建一个新的 chunk// 对象块。// 该池只会增长:在池销毁之前,对象永远不会从池中移除。//// acquireObject() 返回一个带有自定义删除器的 std::shared_ptr,该删除器// 会在 shared_ptr 被销毁且其引用计数达到 0 时,// 自动将对象放回对象池。exporttemplate <typename T, typename Allocator = std::allocator<T>>class ObjectPool final{ public: ObjectPool() = default; explicit ObjectPool(const Allocator& allocator); ~ObjectPool();
// 禁止移动构造和移动赋值。 ObjectPool(ObjectPool&&) = delete; ObjectPool& operator=(ObjectPool&&) = delete;
// 禁止拷贝构造和拷贝赋值。 ObjectPool(const ObjectPool&) = delete; ObjectPool& operator=(const ObjectPool&) = delete;
// 从池中保留并返回一个对象。可以提供参数 // 并将其完美转发给 T 的构造函数。 template <typename... Args> std::shared_ptr<T> acquireObject(Args&&... args);
private: // 创建一个新的未初始化内存块,其大小足以容纳 // m_newChunkSize 个 T 实例。 void addChunk(); // 包含将要在其中创建 T 实例的内存块。 // 对于每个 chunk,存储指向其第一个对象的指针。 std::vector<T*> m_pool; // 包含指向池中所有可用空闲 T 实例的指针。 // std::vector<T*> m_freeObjects; // 第一个分配的 chunk 中应容纳的 T 实例数量。 static constexpr std::size_t ms_initialChunkSize { 5 }; // 新分配的 chunk 中应容纳的 T 实例数量。 // 在每个新创建的 chunk 之后,此值将翻倍。 std::size_t m_newChunkSize { ms_initialChunkSize }; // 用于分配和释放 chunk 的分配器。 Allocator m_allocator;};使用这个 object pool 时,你必须保证:object pool 本身的生命周期长于所有从它手中借出去的 object。
构造函数很简单,只是把给定的 allocator 存进一个数据成员:
template <typename T, typename Allocator>ObjectPool<T, Allocator>::ObjectPool(const Allocator& allocator) : m_allocator { allocator }{}负责分配新 chunk 的 addChunk() 成员函数实现如下。它的第一部分负责真正分配新的 chunk。所谓一个 “chunk”,本质上就是一块未初始化的内存,由 allocator 分配,容量足以容纳 m_newChunkSize 个 T 实例。注意:增加一个 chunk 时,并不会真正构造任何 object;也就是说,没有任何 constructor 会在这里被调用。真正的 object 构造会在稍后的 acquireObject() 中发生。addChunk() 的第二部分则负责为新 chunk 中的每一个未来 object 生成指针,并把这些指针都放进空闲对象列表。这里使用了定义在 <numeric> 中的 iota() algorithm。回顾一下:iota() 会用第三个参数给出的起始值,填满由前两个参数表示的区间,并对后续每个值递增一。由于这里操作的是 T* 指针,对 T* 加一就意味着跳到该内存块中的下一个 T。最后,m_newChunkSize 会翻倍,以便下次分配出的 chunk 比当前 chunk 更大;这是一种基于 performance 的策略,也与 std::vector 的扩容思路一致。实现如下:
template <typename T, typename Allocator>void ObjectPool<T, Allocator>::addChunk(){ std::println("Allocating new chunk...");
// 分配一个新的未初始化内存块,其大小足以容纳 // m_newChunkSize 个 T 实例,并将其添加到池中。 // 确保在发生异常时所有内容都能被清理。 m_pool.push_back(nullptr); try { m_pool.back() = m_allocator.allocate(m_newChunkSize); } catch (...) { m_pool.pop_back(); throw; }
// 为新 chunk 中的每个单独对象创建指针 // 并将它们存储在空闲对象列表中。 auto oldFreeObjectsSize { m_freeObjects.size() }; m_freeObjects.resize(oldFreeObjectsSize + m_newChunkSize); std::iota(begin(m_freeObjects) + oldFreeObjectsSize, end(m_freeObjects), m_pool.back());
// 为下一次翻倍 chunk 大小。 m_newChunkSize *= 2;}作为一个 variadic 成员函数模板,acquireObject() 负责从 pool 中取出一个空闲 object;如果没有可用空闲 object,就先分配新 chunk。正如前面所说,新 chunk 只是分配了一块未初始化内存;真正的 T 实例构造由 acquireObject() 负责完成。这里通过 placement new 在指定内存位置原地构造 T。任何传给 acquireObject() 的参数,都会被 perfect forwarding 给 T 的 constructor。
acquireObject() 在用 placement new 构造出 T 之后,如果 T 含有 const 或 reference 成员,那么直接使用原始指针访问这个新构造对象会触发 undefined behavior。为了把这件事变成 defined behavior,需要使用定义在 <new> 中的 std::launder() 对这块内存做“洗白”。2
最后,洗白后的 T* 会被包装进带自定义 deleter 的 shared_ptr 中。这个 deleter 并不会真正释放任何内存;它只会通过 std::destroy_at() 手动调用 object 的 destructor,然后再把该指针放回空闲对象列表。
template <typename T, typename Allocator>template <typename... Args>std::shared_ptr<T> ObjectPool<T, Allocator>::acquireObject(Args&&... args){ // 如果没有空闲对象,分配一个新 chunk。 if (m_freeObjects.empty()) { addChunk(); }
// 获取一个空闲对象。 T* object { m_freeObjects.back() };
// 在未初始化的内存块中使用 placement new // 初始化(即构造)一个 T 实例,并且 // 将任何提供的参数完美转发给构造函数。 ::new(object) T { std::forward<Args>(args)... };
// 洗白对象指针。 T* constructedObject { std::launder(object) };
// 从空闲对象列表中移除该对象。 m_freeObjects.pop_back();
// 包装构造的对象并返回它。 return std::shared_ptr<T> { constructedObject, [this](T* object) { // 销毁对象。 std::destroy_at(object); // 将对象放回空闲对象列表。 m_freeObjects.push_back(object); } };}最后,pool 的 destructor 还必须通过给定 allocator 释放全部已分配的内存:
template <typename T, typename Allocator>ObjectPool<T, Allocator>::~ObjectPool(){ // 注意:此实现假设此池分发的所有对象 // 在池销毁之前都已归还到池中。 // 如果情况并非如此,以下语句将触发断言。 assert(m_freeObjects.size() == ms_initialChunkSize * (std::pow(2, m_pool.size()) - 1));
// 释放所有已分配的内存。 std::size_t chunkSize { ms_initialChunkSize }; for (auto* chunk : m_pool) { m_allocator.deallocate(chunk, chunkSize); chunkSize *= 2; } m_pool.clear();}assert() 是一个定义在 <cassert> 中的 macro。它接收一个 Boolean expression;如果结果为 false,就会打印错误信息并终止程序。更多细节可见第 31 章“调试攻坚”。这里 assert() 所使用的那个公式,来自这样一个事实:每个新 chunk 的大小,都是前一个 chunk 的两倍。
假设某个应用中会大量使用生命周期很短、但 data member 很大的 object,而这类 object 的分配成本又很高。比如,假设我们有一个 ExpensiveObject class,它的定义如下:
class ExpensiveObject{ public: ExpensiveObject() { /* ... */ } virtual ~ExpensiveObject() = default; // 用特定信息填充对象的成员函数。 // 检索对象数据的成员函数。 // (未显示) private: // 一个昂贵的数据成员。 array<double, 4 * 1024 * 1024> m_data; // 其他数据成员(未显示)};与其在整个程序生命周期中不断分配、释放大量这样的 object,不如直接使用前一节写好的 object pool。下面这段代码借助 chrono library(见第 22 章“日期与时间工具”)来 benchmark 这个 object pool:
using MyPool = ObjectPool<ExpensiveObject>;
shared_ptr<ExpensiveObject> getExpensiveObject(MyPool& pool){ // 从池中获取一个 ExpensiveObject 对象。 auto object { pool.acquireObject() }; // 填充对象。(未显示) return object;}
void processExpensiveObject(ExpensiveObject& object) { /* ... */ }
int main(){ const size_t NumberOfIterations { 500'000 };
println("Starting loop using pool..."); MyPool requestPool; auto start1 { chrono::steady_clock::now() }; for (size_t i { 0 }; i < NumberOfIterations; ++i) { auto object { getExpensiveObject(requestPool) }; processExpensiveObject(*object.get()); } auto end1 { chrono::steady_clock::now() }; auto diff1 { end1 - start1 }; println("{}", chrono::duration<double, milli>(diff1));
println("Starting loop using new/delete..."); auto start2 { chrono::steady_clock::now() }; for (size_t i { 0 }; i < NumberOfIterations; ++i) { auto object { std::make_unique<ExpensiveObject>() }; processExpensiveObject(*object); } auto end2 { chrono::steady_clock::now() }; auto diff2 { end2 - start2 }; println("{}", chrono::duration<double, milli>(diff2));}main() 中包含了一段简单 benchmark:在循环中请求 500,000 个 object,并记录耗时。这段循环会做两次,一次使用我们的 object pool,一次使用标准的 new/delete。在一台测试机器上,以 release build 运行时,结果如下:
Starting loop using pool...Allocating new chunk...54.526msStarting loop using new/delete...9463.2393ms在这个例子里,使用 object pool 的速度大约快了 170 倍。不过需要记住,这个 object pool 的设计是专门偏向“data member 特别大”的 object,这一点在示例中的 ExpensiveObject 上正好成立——它包含一个 32MB 的 array 数据成员。
在设计和写代码时,把 efficiency 放在脑子里当然是件好事。如果凭常识或经验就能看出某段程序明显低效,那当然没有理由故意写得很糟糕。不过,我仍然强烈建议你不要在 design 与 coding 阶段过度沉迷 performance。更好的方式是:先做出干净、结构良好的 design 与实现;然后使用 profiler;最后只优化那些被 profiler 明确标记为 performance bottleneck 的部分。还记得第 4 章介绍过的 “90/10” rule 吗?它指出:大多数程序 90% 的运行时间,往往只花在 10% 的代码上(Hennessy and Patterson, Computer Architecture, A Quantitative Approach, Fourth Edition, Morgan Kaufmann, 2006)。这意味着:就算你把 90% 的代码都优化了一遍,也可能只让程序整体运行时间改善 10%。显然,你真正应该优化的,是那些在你预期 workload 下最常被执行的代码路径。
因此,对程序做 profile 往往非常有帮助。它能帮助你判断:到底哪些部分值得优化。市面上有很多 profiling tool,它们会在程序运行时对其进行分析,并生成 performance 数据。多数 profiling tool 都会在函数层面给出分析结果,例如告诉你每个函数花了多少时间,或者占总执行时间的百分之多少。对程序跑过 profiler 之后,通常很容易立刻看出哪些地方最值得优化。并且,在优化前后都做 profiling,是证明“你的优化真的有效”的关键。
如果你使用的是 Microsoft Visual C++,那么你手头已经有一个非常好的内建 profiler;本章后面会讲到它。如果你还没用 Visual C++,Microsoft 也提供了免费的 community edition(visualstudio.microsoft.com):对学生、open-source 开发者以及独立开发者来说,它可免费用于开发免费或收费应用;小型组织中最多五位用户也可免费使用。另一个优秀 profiler 是 IBM 的 Rational PurifyPlus(www.almtoolbox.com/purify.php)。此外,还有不少更轻量的免费 profiling tool:比如 Windows 上常见的 Very Sleepy(www.codersnotes.com/sleepy)和 Luke Stackwalker(lukestackwalker.sourceforge.net),以及 Unix/Linux 上广为人知的 Valgrind(valgrind.org)和 gprof(GNU profiler,sourceware.org/binutils/docs/gprof)。当然,可选工具远不止这些。本节会展示两个 profiler:Linux 下的 gprof,以及 Visual C++ 2022 自带的 profiler。
使用 gprof 的性能分析示例
Section titled “使用 gprof 的性能分析示例”profiling 的威力,最好通过一个真实编码例子来看。当然先说明一下:下面第一个实现中的 performance bug 并不算隐蔽!真实世界里的性能问题通常会更复杂,但如果为了展示它们写一个完整程序,那篇幅就超出本书承受范围了。
假设你在美国社会保障局(US Social Security Administration)工作。每年,政府都会提供一个网站,让用户查询前一年新生婴儿名字的流行度。你的任务,是编写后端程序来响应这些查询。输入是一份文件,其中包含每一个新生儿的名字;很显然,文件中会有大量重复名字。例如,在 2003 年男婴的文件中,名字 Jacob 是最热门的,一共出现了 29,195 次。你的程序必须先读取这份文件,构建一个驻内存数据库。之后,用户就可以查询某个名字对应的绝对人数,或者它在所有名字中的排名。
第一版设计尝试
Section titled “第一版设计尝试”这个程序的一个自然设计,是做一个 NameDB 类,并提供如下 public 成员函数:
export class NameDB{ public: // 读取 nameFile 中的婴儿名字列表以填充数据库。 // 如果无法打开或读取 nameFile,则抛出 invalid_argument。 explicit NameDB(const std::string& nameFile);
// 返回名字的排名(第 1 名、第 2 名等)。 // 如果未找到名字,则返回 -1。 int getNameRank(const std::string& name) const;
// 返回具有给定名字的婴儿数量。 // 如果未找到名字,则返回 -1。 int getAbsoluteNumber(const std::string& name) const;
// 尚未显示的私有成员 ...};真正困难的地方,在于如何为这个内存数据库选一个合适的数据结构。第一版尝试可以是:用一个保存 name/count pair 的 vector。还记得 pair 是一个 utility class,用来把两个可能不同类型的值组合在一起。这个 vector 中的每个条目,保存一个名字,以及该名字在原始数据文件中出现的次数。下面就是基于这一设计的完整类定义:
export class NameDB{ public: explicit NameDB(const std::string& nameFile); int getNameRank(const std::string& name) const; int getAbsoluteNumber(const std::string& name) const; private: std::vector<std::pair<std::string, int>> m_names;
// 辅助成员函数 bool nameExists(const std::string& name) const; void incrementNameCount(const std::string& name); void addNewName(const std::string& name);};下面是 constructor 以及三个 helper——nameExists()、incrementNameCount() 和 addNewName()——的实现。注意,nameExists() 与 incrementNameCount() 里的 loop 都会遍历整个 vector。
// 从文件中读取名字并填充数据库。// 数据库是一个包含 名字/计数 对的 vector,存储// 每个名字在原始数据中出现的次数。NameDB::NameDB(const string& nameFile){ // 打开文件并检查错误。 ifstream inputFile { nameFile }; if (!inputFile) { throw invalid_argument { "Unable to open file" }; }
// 一次读取一个名字。 string name; while (inputFile >> name) { // 在目前的数据库中查找该名字。 if (nameExists(name)) { // 如果名字存在于数据库中,只需递增计数。 incrementNameCount(name); } else { // 如果名字尚不存在,则以计数 1 添加它。 addNewName(name); } }}
// 如果名字存在于数据库中,则返回 true,否则返回 false。bool NameDB::nameExists(const string& name) const{ // 遍历名字 vector 以查找该名字。 for (auto& entry : m_names) { if (entry.first == name) { return true; } } return false;}
// 前置条件:名字存在于名字 vector 中。// 后置条件:与名字关联的计数被递增。void NameDB::incrementNameCount(const string& name){ for (auto& entry : m_names) { if (entry.first == name) { entry.second += 1; return; } }}
// 向数据库添加一个新名字。void NameDB::addNewName(const string& name){ m_names.emplace_back(name, 1);}注意,你本来也可以使用 std::find_if() 这类 Standard Library algorithm(见第 20 章“掌握标准库算法”)来完成与 nameExists() / incrementNameCount() 中 loop 相同的工作。这里故意把 loop 明着写出来,是为了更直观地暴露 performance 问题。
其实你现在大概已经能闻到性能问题了:如果名字数量是几十万呢?在构建数据库过程中,频繁的线性查找很快就会变得非常慢。
为了把这个例子补完整,下面再给出两个 public 成员函数的实现:
// 返回名字的排名。// 首先查找名字以获取具有该名字的婴儿数量。// 然后遍历所有名字,计算所有计数高于// 指定名字的名字数量。将该计数作为排名返回。int NameDB::getNameRank(const string& name) const{ // 利用 getAbsoluteNumber() 成员函数。 int num { getAbsoluteNumber(name) };
// 检查是否找到了该名字。 if (num == -1) { return -1; }
// 现在计算 vector 中所有计数高于 // 此名字的名字数量。如果没有名字计数更高, // 则此名字排名为 1。每个计数更高的名字 // 都会使此名字的排名下降 1。 int rank { 1 }; for (auto& entry : m_names) { if (entry.second > num) { ++rank; } } return rank;}
// 返回与给定名字关联的计数。int NameDB::getAbsoluteNumber(const string& name) const{ for (auto& entry : m_names) { if (entry.first == name) { return entry.second; } } return -1;}对第一版设计做性能分析
Section titled “对第一版设计做性能分析”为了测试程序,你还需要一个 main():
import name_db;import std;using namespace std;
int main(){ NameDB boys { "boys_long.txt" }; println("{}", boys.getNameRank("Daniel")); println("{}", boys.getNameRank("Jacob")); println("{}", boys.getNameRank("William"));}这个 main() 会创建一个名为 boys 的 NameDB 数据库,并让它使用 boys_long.txt 填充自己。该文件包含了 500,500 个名字。
使用 gprof 分三步:
-
在编译好
name_db模块之后,带上特殊编译选项重新编译主程序,使它在运行时记录原始执行信息。若使用 GCC,选项是-pg,例如:> gcc -lstdc++ -std=c++2b -pg -fmodules-ts -o namedb NameDB.cpp NameDBTest.cpp -
运行程序。这会在当前工作目录生成一个名为
gmon.out的文件。运行时请耐心一点,因为第一版程序非常慢。 -
运行
gprof命令。最后这一步会分析gmon.out中的 profiling 信息,并生成一份“还算能读”的报告。由于 gprof 会把结果输出到标准输出,因此通常要重定向到文件中:> gprof namedb gmon.out> gprof_analysis.out
现在你就可以分析数据了。遗憾的是,输出文件多少有些晦涩,也颇具压迫感,因此一开始读起来需要适应。gprof 会提供两组信息:第一组总结的是程序中每个函数自身执行所花的时间;第二组——也是更有价值的一组——总结的是“某函数及其所有 descendants 一共花了多少时间”,这也叫 call graph。下面是我从 gprof_analysis.out 中摘出、并略作整理的一部分输出。请注意,你在自己机器上看到的数字会不同。
index %time self children called name[1] 100.0 0.00 14.06 main [1] 0.00 14.00 1/1 NameDB::NameDB [2] 0.00 0.04 3/3 NameDB::getNameRank [25] 0.00 0.01 1/1 NameDB::~NameDB [28]各列含义如下:
index: 这条 call graph 条目的索引编号。%time: 该函数及其 descendants 占整个程序总执行时间的百分比。self: 该函数自身一共执行了多少秒。children: 该函数的 descendants 一共执行了多少秒。called: 该函数被调用了多少次。name: 函数名;若后面跟着方括号中的数字,则表示它在 call graph 中的另一个索引。
上面的输出告诉你:main() 及其 descendants 一共占用了程序总执行时间的 100%,总耗时 14.06 秒。而第二行说明,仅 NameDB constructor 就占去了其中 14.00 秒。于是,性能问题究竟在哪里,立刻就清楚了。若想继续追踪到底 constructor 里哪一部分最慢,就要跳到索引为 2 的那条 call graph 项,因为这正是该构造函数名后面方括号里的编号。在我的测试系统上,索引 2 的内容如下:
[2] 99.6 0.00 14.00 1 NameDB::NameDB [2] 1.20 6.14 500500/500500 NameDB::nameExists [3] 1.24 5.24 499500/499500 NameDB::incrementNameCount [4] 0.00 0.18 1000/1000 NameDB::addNewName [19] 0.00 0.00 1/1 vector::vector [69]NameDB::NameDB 下面这些缩进行,表示它的 descendants 各自花了多少时间。你可以看到:nameExists() 一共花了 6.14 秒,而 incrementNameCount() 一共花了 5.24 秒。第四列显示的是这些函数被调用的次数(nameExists() 500,500 次,incrementNameCount() 499,500 次)。除此之外,没有其他函数消耗特别显著的时间。
即便不再深挖,单凭这份分析,也已经有两件事非常明显:
- 用大约 14 秒去构建一个包含约 500,000 个名字的数据库,太慢了。也许你需要更好的数据结构。
nameExists()和incrementNameCount()花的时间几乎一样,调用次数也几乎一样。联系应用场景来看,这完全合理:输入文件中的大多数名字都是重复的,因此大多数对nameExists()的调用,后面都紧接着一次对incrementNameCount()的调用。回头看看代码,你会发现这两个函数的逻辑几乎是一样的;它们很可能应该合并。此外,它们的大部分工作都在搜索vector,而如果使用一种已排序的数据结构,查找成本显然会更低。
第二版设计尝试
Section titled “第二版设计尝试”基于 gprof 输出给出的这两个观察,现在就是重新设计程序的时候了。新版设计会把底层数据结构从 vector 换成 map。还记得第 18 章说过:Standard Library 的 map 会维护元素有序,并提供 O(log n) 的查找复杂度,而不像 vector 那样只能做 O(n) 搜索。一个很好的练习,是你自己试试把它改成 std::unordered_map——它在期望情况下的查找复杂度是 O(1)——再借助 profiler 比较一下,在这个应用里它是否比 std::map 更快。
新版程序还会把 nameExists() 和 incrementNameCount() 合并成一个函数,叫 incrementIfExists()。
下面是新的类定义:
export class NameDB{ public: explicit NameDB(const std::string& nameFile); int getNameRank(const std::string& name) const; int getAbsoluteNumber(const std::string& name) const; private: std::map<std::string, int> m_names; bool incrementIfExists(const std::string& name); void addNewName(const std::string& name);};对应的成员函数实现如下:
// 从文件中读取名字并填充数据库。// 数据库是一个将名字与频率关联起来的 map。NameDB::NameDB(const string& nameFile){ // Open the file and check for errors. ifstream inputFile { nameFile }; if (!inputFile) { throw invalid_argument { "Unable to open file" }; }
// 一次读取一个名字。 string name; while (inputFile >> name) { // 在目前的数据库中查找该名字。 if (!incrementIfExists(name)) { // 如果名字存在于数据库中, // 成员函数会递增它,所以我们直接继续。 // 如果不存在则执行到这里,在这种情况下 // 我们以计数 1 添加它。 addNewName(name); } }}
// 如果名字存在于数据库中则返回 true,否则返回// false。如果找到了,则递增它。bool NameDB::incrementIfExists(const string& name){ // 在 map 中查找该名字。 auto res { m_names.find(name) }; if (res != end(m_names)) { res->second += 1; return true; } return false;}
// 向数据库添加一个新名字。void NameDB::addNewName(const string& name){ m_names[name] = 1;}
int NameDB::getNameRank(const string& name) const { /* Omitted, same as before */ }
// 返回与给定名字关联的计数。int NameDB::getAbsoluteNumber(const string& name) const{ auto res { m_names.find(name) }; if (res != end(m_names)) { return res->second; } return -1;}对第二版设计做性能分析
Section titled “对第二版设计做性能分析”按前面同样的步骤对新版本程序运行 gprof,你会得到一份很鼓舞人的结果:
index %time self children called name[1] 100.0 0.00 0.21 main [1] 0.02 0.18 1/1 NameDB::NameDB [2] 0.00 0.01 1/1 NameDB::~NameDB [13] 0.00 0.00 3/3 NameDB::getNameRank [28][2] 95.2 0.02 0.18 1 NameDB::NameDB [2] 0.02 0.16 500500/500500 NameDB::incrementIfExists[3] 0.00 0.00 1000/1000 NameDB::addNewName [24] 0.00 0.00 1/1 map::map [87]你在自己机器上看到的输出会不同。甚至有可能,你根本在输出中看不到多少 NameDB 成员函数的数据。因为在第二版设计里,程序已经快到一定程度,以至于很多时候 profiler 显示出来的可能反而是更多 map 的成员函数,而不是 NameDB 自己的成员函数。
在我的测试系统上,main() 现在总共只花了 0.21 秒——相当于快了 67 倍!当然,这个程序还可以继续改进。例如,当前 constructor 的逻辑仍然是先查一遍 map 看名字是否已存在;如果不存在,再把它插进去。这两步其实可以直接合并为下面这一行:
m_names[name] += 1;如果名字已经在 map 中,这一行就只是递增其计数;如果还不存在,那么这一行会先向 map 中插入一个条目,key 是该名字,value 则是零初始化的值,随后再把它加一,因此最终计数恰好变成 1。
做完这项改进之后,你可以彻底删除 incrementIfExists() 和 addNewName(),并把 constructor 改写成:
NameDB::NameDB(const string& nameFile){ // Open the file and check for errors. ifstream inputFile { nameFile }; if (!inputFile) { throw invalid_argument { "Unable to open file" }; }
// 一次读取一个名字。 string name; while (inputFile >> name) { m_names[name] += 1; }}不过,getNameRank() 仍然需要遍历整个 map。一个很好的练习,是你自己想想:是否还能设计一种别的数据结构,从而让 getNameRank() 中那次线性遍历也被消除掉。
使用 Visual C++ 2022 的性能分析示例
Section titled “使用 Visual C++ 2022 的性能分析示例”Microsoft Visual C++ 2022 的大多数版本都内建了一个非常不错的 profiler,这一节会简要介绍它。VC++ profiler 拥有完整的图形界面。这里并不是说某个 profiler 一定优于另一个 profiler;不过,让你知道 command-line profiler(如 gprof)与 GUI profiler(如 VC++ 自带 profiler)各自能做到什么,还是很有帮助的。
要在 Visual C++ 2022 中开始 profile 一个 application,首先要在 Visual Studio 里打开该项目。本节示例仍然使用前面“第一版低效设计”中的 NameDB 代码,因此这里不再重复贴出。项目打开后,请确保配置为 Release,而不是 Debug;然后点击 Debug 菜单,选择 Performance Profiler。此时会弹出一个新窗口,类似图 29.1。
[^FIGURE 29.1]
根据你使用的 VC++ 版本不同,这个窗口中可见的分析工具数量也会有所不同。下面简要解释其中两个:
- CPU Usage: 用于以较低开销监控应用。这意味着“对应用做 profile”本身不会给目标程序带来太大性能影响。
- Instrumentation: 它会向程序中插入额外代码,从而更精确地统计函数调用次数,并对每一次函数调用精确计时。但它对应用本身的性能影响也会更大。通常建议先用 CPU Usage 工具大致判断 bottleneck 在哪里;如果它给你的信息不够,再尝试 Instrumentation。
在这个 profiling 示例中,只启用 CPU Usage 工具,然后点击 Start。这样就会启动程序并分析它的 CPU usage。程序运行结束后,Visual Studio 会自动打开 profiling report。图 29.2 展示了 profile 那个第一版 NameDB 应用时,报告大致会长什么样。
从这份报告中,你可以立刻看到 hot path。和 gprof 一样,它同样显示 NameDB constructor 占据了程序绝大部分运行时间。Visual Studio 的 profiling report 还是可交互的。比如,你可以在图 29.2的 hot path tree 中点击 NameDB::NameDB constructor,进一步 drill down。这样会打开这个函数的下钻报告,如图 29.3 所示。
[^FIGURE 29.2]
这个 drill-down view 上方会显示 hot path,下方则直接显示该成员函数的源代码。代码视图还会给出每一行代码所消耗的运行时间百分比,而最耗时的代码行会用不同深浅的红色标出。通过这个视图,你几乎立刻就能看出:incrementNameCount() 与 nameExists() 两者消耗的时间几乎相同。
在这份报告顶部,还有一个名为 Current View 的下拉菜单,可以让你切换 profiling 数据的不同视图。
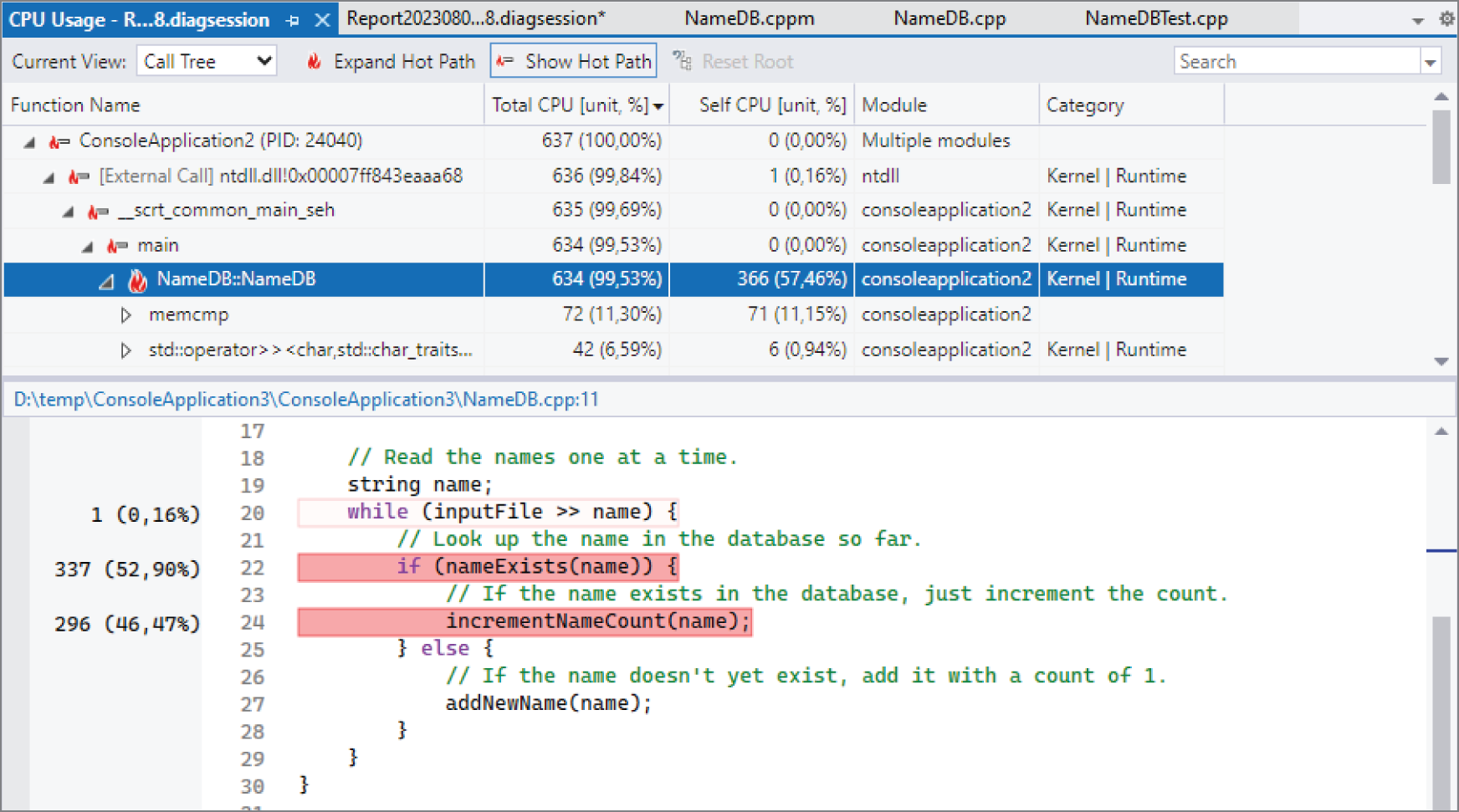
[^FIGURE 29.3]
本章讨论了 C++ 程序中 efficiency 与 performance 的关键方面,并给出了多种用于设计与编写更高效应用的具体技巧。理想情况下,你现在应当已经更能体会 performance 的重要性,也更能理解 profiling tool 的价值。
本章有两件事尤其值得记住。第一,不要在设计和写代码的过程中,对 performance 过度执念。更推荐的做法是:先做出正确、结构清晰的 design 与实现,然后使用 profiler,最后只优化那些被 profiler 明确指出为 performance bottleneck 的部分。
第二,也是更重要的一点:design-level efficiency 远比 language-level efficiency 更重要。比如,如果明明有更好的 algorithm 或数据结构可用,那么你就不该继续使用复杂度很差的方案。
通过完成下面这些练习,你可以巩固本章讨论的内容。所有练习的参考解答都包含在本书网站 www.wiley.com/go/proc++6e 提供的代码下载包中。不过,如果你在某道题上卡住了,建议先回过头重读本章相关部分,尽量自己找到答案,再去看网站上的解答。
- 练习 29-1: 本章最需要记住的两件事是什么?
- 练习 29-2: 修改 “Profiling” 一节中最终版
NameDB的实现,把底层map改成std::unordered_map。在修改前后都 profile 一下,并比较结果。 - 练习 29-3: 在练习 29-2 的 profiling 结果里,看起来
NameDBconstructor 中的operator>>现在成了 bottleneck。你能否改写实现,避免使用operator>>?既然输入文件中每一行都只有一个名字,也许直接使用std::getline()会更快?试着这样修改,并对修改前后结果做 profiling 对比。
Footnotes
Section titled “Footnotes”-
这个例子来自
std::unreachable()的官方提案论文 P0627R6。 ↩ -
C++23 还引入了一个与之略相关的函数,叫
std::start_lifetime_as()。它与launder()的区别在于:launder()不会创建新对象,它只是“洗白”一个指向已构造对象的指针;而start_lifetime_as()则会真正创建一个新对象,但不会运行任何 constructor 代码。当你手里有一块内存,并且确定它本质上表示某个对象(例如它是从网络中收到的一段数据缓冲区)时,这会非常有用;你可以把它转换成一个对象,比如start_lifetime_as<MyObjectType>(networkBuffer)。 ↩