C++ 与标准库速成
本章的目标是:在你继续阅读本书其余内容之前,先快速覆盖一遍 C++ 中最重要的部分,让你建立起足够的基础。本章并不是一份完整的 C++ 语言或标准库教程。某些更基础的话题,例如“程序是什么”“递归是什么”,这里不会讲。某些偏冷门的知识点,例如 union 的定义或 volatile 关键字,同样也会略过。一些在 C++ 中不那么重要的 C 语言部分,以及后续章节会深入讲解的 C++ 内容,此处也都暂时不展开。
本章的重点,是覆盖程序员每天都会碰到的那些 C++ 内容。例如,如果你还比较新,并且不清楚“引用变量(reference variable)”是什么,那你会在这里学到这类变量。你还会接触标准库中一些常见功能的基本用法,例如 vector 容器、optional 值、string 对象等等。本章之所以在一开始就简要介绍这些标准库里的现代构件,是为了让本书从最早的示例开始,就可以直接使用它们。
如果你已经有相当丰富的 C++ 经验,那就快速浏览本章,确认自己没有遗漏哪些语言基础。如果你是新手,那就认真读完它,并确保自己真正理解了其中的示例。如果你还需要更多入门信息,可以参考 附录 B“带注释的参考书目”中列出的书目。
C++ 速成
Section titled “C++ 速成”C++ 经常被看作“更好的 C”或者“C 的超集”。它最初的主要设计目标,是成为一门面向对象版本的 C,也就是常说的 “C with classes”。再往后,C 语言中许多令人烦躁和粗糙的地方,也在 C++ 中逐步得到了修补。由于 C++ 建立在 C 之上,因此如果你是一位经验丰富的 C 程序员,本节中的部分语法看起来会很熟悉。当然,两门语言的差异同样非常明显。一个很直观的证据是:C23 标准规范文档还不到 800 页,而 C++23 标准规范文档已经超过了 2000 页。所以,如果你来自 C,又或者来自 Java、C#、Python 等其他语言,都请随时准备好迎接新的或不熟悉的语法。
例行公事般的“Hello, World”程序
Section titled “例行公事般的“Hello, World”程序”下面这段代码,大概就是你会遇到的最简单的 C++ 程序了。如果你使用的是较老版本的 C++,那么 import std; 和 std::println() 可能还无法工作。这种情况下,你需要改用本章稍后介绍的替代方式。
// 01_helloworld.cppimport std;
int main(){ std::println("Hello, World!"); return 0;}正如你所预期的那样,这段代码会在屏幕上打印消息 “Hello, World!”。它非常简单,当然不太可能拿什么大奖,但它已经展示了 C++ 程序格式中几个非常重要的概念:
- 注释
- 导入模块
main()函数- 输出文本
- 从函数返回
接下来的小节会简单解释这些概念。
程序的第一行是一条注释(comment),它只对程序员有意义,编译器会直接忽略它。在 C++ 中,标记注释有两种方式。你可以使用两个斜杠,表示这一行剩余内容都是注释:
// 01_helloworld.cpp同样的效果(也就是“什么都不会发生”) 还可以通过多行注释(multiline comment) 达成。多行注释以 /* 开头,以 */ 结尾。如下所示:
/* 这是一条多行注释。 编译器会忽略它。 */第 3 章“编写有风格的代码”会详细讨论注释。
对模块(modules) 的支持,是 C++20 四大新特性之一,它用来替代旧的头文件(header files) 机制。如果你想使用某个模块中的功能,只需要导入它即可。这是通过 import 声明完成的。从 C++23 开始,你可以通过导入一个名为 std 的标准命名模块(standard named module),来访问整个 C++ 标准库。“Hello, World” 程序的第一行导入的就是这个标准模块:
import std;如果程序没有导入这个模块,那它连唯一要做的事情——打印文本——都做不到。
如果没有 C++23 的标准命名模块支持,你就必须显式导入代码真正需要的各个头文件。标准库里有一百多个头文件,因此你并不总能立刻知道到底该导入哪一个。附录 C“标准库头文件”列出了 C++ 标准库的所有头文件,并附有简短内容说明。举例来说,对于这个 “Hello, World” 程序,其实并不需要导入整个 std 命名模块,只导入 <print> 就足以获得文本输出功能。请注意:导入命名模块 std 时不使用尖括号,而导入单个头文件时则必须使用尖括号,如下所示:
import <print>;由于这是一本关于 C++23 的书,因此本书会在所有地方使用模块。C++ 标准库提供的所有功能,依然都对应于明确的头文件。书中的大多数示例会直接导入 std 命名模块,而不是逐个导入头文件,不过正文总会说明某项功能具体由哪个头文件提供。
模块当然不只适用于标准库。你也可以编写自己的模块,向外提供自定义类型和功能,本书后续内容会不断涉及这一点。
编译器如何处理源代码
Section titled “编译器如何处理源代码”简而言之,构建一个 C++ 程序可以看作一个三步过程。严格来说,编译过程中还包含若干更多阶段,但这个简化视角对当前来说已经足够了。
- 首先,代码会经过预处理器(preprocessor),它负责识别代码中的元信息,并处理诸如
#include之类的预处理指令。一个所有预处理指令都已处理完成的源文件,叫做一个翻译单元(translation unit)。 - 接下来,所有翻译单元都会被分别编译(compiled),也就是翻译成机器可读的目标文件(object files)。此时,其中对函数等实体的引用还没有真正被解析。
- 最后,由链接器(linker) 来解析这些引用,并把所有目标文件链接成最终的可执行文件(executable)。
预处理器指令
Section titled “预处理器指令”如果你的编译器还不支持模块,那么你就需要 #include 头文件,而不是导入模块或头文件。也就是说,像 import <print>; 这样的显式 import 声明,需要改写为如下 #include 预处理指令:
#include <print>面向预处理器的指令都以 # 字符开头,例如 #include <print>。在这里,#include 的含义是告诉预处理器:把 <print> 头文件里的所有内容复制进当前文件。<print> 头文件提供了文本输出到屏幕所需的功能。
第 11 章“模块、头文件与其他主题”会更详细地讨论预处理器指令。不过,正如前面提到的,本书会优先使用模块,而不是旧式头文件。
main() 函数
Section titled “main() 函数”main() 当然就是程序开始执行的地方。main() 的返回类型是 int,它表示程序的最终执行状态。main() 函数要么不接收参数,要么接收下面这两个参数:
int main(int argc, char** argv)argc 给出传给程序的参数个数,而 argv 则保存这些参数。要注意,argv[0] 可能是程序名,但也可能只是一个空字符串,因此不要依赖它;如果你需要获取程序名,应当使用平台特定的功能。真正的实际参数从索引 1 开始。
在 C++23 之前,你通常会使用 I/O streams 把文本输出到屏幕上。下一节会先简要介绍它们,第 13 章“揭秘 C++ I/O”会再详细讲解。不过,C++23 引入了一套新的、更加易用的文本输出机制,它会出现在本书几乎每一个代码片段中:std::print() 和 println(),它们都定义在 <print> 中。
第 2 章“使用字符串与字符串视图”会详细讨论 std::print() 和 println() 这两个字符串格式化与输出函数。不过,它们最基础的用法非常简单,因此这里先介绍,以便后续代码片段能直接使用。最基本形式下,println() 可以打印一行文本,并自动在末尾加上换行:
std::println("Hello, World!");println() 的第一个参数是一个格式字符串,其中可以包含若干替换字段(replacement fields),它们会被第二个及之后传入的值替换。你可以通过在字符串中写出花括号 {} 来指定替换字段的位置。例如:
std::println("我爱你的方式有 {} 种。", 219);在这个例子中,数字 219 被插入进字符串,因此输出结果为:
我爱你的方式有 219 种。你可以按需要写任意多个替换字段。例如:
std::println("{} + {} = {}", 2, 4, 6);在这个例子中,每个字段都会按顺序应用,因此最终输出是:
2 + 4 = 6关于替换字段的格式,还有很多内容可讲,不过那要留到 第 2 章。
如果用的是 print() 而不是 println(),那么输出的文本不会自动以换行结尾。
输入/输出流
Section titled “输入/输出流”如果你的编译器还不支持 C++23 的 std::print() 和 println(),那么你就需要把它们改写成输入/输出流版本。
输入/输出流(I/O streams) 会在 第 13 章 中详细讨论,不过输出和输入的基础概念其实很简单。你可以把输出流想象成一条洗衣通道:凡是你往里扔的东西,都会被适当地输出。std::cout 就是面向用户控制台的那条通道,也就是标准输出。当然还有别的通道,例如 std::cerr,它会输出到错误控制台。<< 运算符负责把数据送进这条通道。输出流允许你在一行代码里连续发送多个不同类型的数据。下面这段代码先输出文本,再输出一个数字,然后再输出更多文本:
std::cout << "我爱你的方式有 " << 219 << " 种。" << std::endl;不过从 C++20 开始,更推荐使用定义在 <format> 中的 std::format() 来执行字符串格式化。format() 使用的也是和 print()、println() 一样的替换字段概念,会在 第 2 章 中详细讨论。不过,用它来改写前面的语句非常简单:
std::cout << std::format("我爱你的方式有 {} 种。", 219) << std::endl;因此,如果你的编译器暂时还不支持 print() 和 println(),完全可以改用 cout、format() 和 endl。例如,假设你原来有下面这句:
std::println("{} + {} = {}", 2, 4, 6);那就可以把 println() 换成 format(),再把结果送给 cout,并补上 endl:
std::cout << std::format("{} + {} = {}", 2, 4, 6) << std::endl;std::endl 表示一行的结束。输出流遇到它时,会把当前缓冲区中的内容真正写出去,并移动到下一行。另一种更常见的换行表示方式,是使用 \n。\n 是一个转义序列,代表换行字符。转义序列可以出现在任意带引号的字符串中。下表列出了几种最常见的转义序列:
| 转义序列 | 含义 |
|---|---|
\n | 换行:将光标移到下一行开头 |
\r | 回车:将光标移到当前行开头,但不进入下一行 |
\t | 制表符 |
\\ | 反斜杠字符 |
\" | 双引号 |
要记住,endl 不只是插入一个换行,它还会强制刷新缓冲区。因此不要滥用它,尤其不要在循环里频繁使用,否则会影响性能。相比之下,往流里写入 \n 也能换行,但不会自动刷新缓冲区。
默认情况下,print() 和 println() 会把文本输出到标准输出 std::cout。如果想输出到错误流 std::cerr,可以这样写:
std::println(std::cerr, "错误:{}", 6);流同样可以用来接收用户输入。最直接的方式,就是把 >> 运算符和输入流配合使用。std::cin 负责从键盘读取输入。比如:
import std;int main(){ int value; std::cin >> value; std::println("你输入的是 {}", value);}>> 在读到空格后就会停止,因此它不适合读取包含空格的整段文本。另外,用户输入往往不那么“听话”,因为你永远无法预知用户究竟会输入什么。第 13 章会详细讨论输入流,包括如何读取包含空格的文本。
如果你来自 C 语言背景,可能会好奇经典的 printf() 和 scanf() 跑哪去了。它们在 C++ 里当然仍然能用,但我强烈建议优先使用现代的 print()、println()、format() 以及流库,一个重要原因就是:printf() / scanf() 这套接口几乎没有类型安全可言。
“Hello, World” 程序的最后一行是:
return 0;因为这里是 main(),所以从它返回,就意味着把控制权交还给操作系统。返回值为 0,通常表示程序顺利结束、没有出错;如果要表示出错,则可以返回非零值。
不过 main() 里的 return 其实是可选的。即使你不写,编译器也会默认替你补上 return 0;。
Namespaces 用于解决不同代码片段之间的命名冲突问题。例如,你可能正在编写一段代码,其中有一个名为 foo() 的函数。某天,你决定开始使用一个第三方库,结果那个库中也有一个 foo() 函数。编译器根本无法知道你在代码中引用的到底是哪一个 foo()。你无法修改库中的函数名,而大规模修改自己代码中的函数名也会非常痛苦。
这正是命名空间要解决的问题。借助命名空间,你可以明确一个名字定义在哪个上下文中。要把代码放进命名空间,只需用一个命名空间代码块把它包起来即可。如下所示:
namespace mycode { void foo() { std::println("在 mycode 命名空间中调用了 foo()"); }}把你自己的 foo() 放进 mycode 命名空间之后,它就与第三方库中的 foo() 隔离开了。若要调用带命名空间版本的 foo(),就必须通过 :: 在函数名前加上命名空间。这个 :: 也叫做作用域解析运算符(scope resolution operator):
```mycode::foo(); // 调用 mycode 命名空间中的 foo() 函数
任何位于 `mycode` 命名空间块中的代码,在访问同一命名空间中的其他代码时,都不需要显式写出命名空间前缀。这种隐式命名空间能提升可读性。你还可以通过 `using` 指令来省掉命名空间前缀。这个指令会告诉编译器:后续代码默认会使用指定命名空间中的名字。如下:
```cppusing namespace mycode;
int main(){ foo(); // 等价于 mycode::foo();}单个源文件中当然可以包含多个 using 指令,但不要滥用这种快捷方式。极端情况下,如果你声明自己要使用“所有已知命名空间”,那其实就等于把命名空间机制彻底废掉了! 一旦你所使用的两个命名空间中包含同名实体,命名冲突又会立刻出现。除此之外,你也必须知道自己的代码当前运行在哪个命名空间上下文中,否则很容易不小心调用到错误版本的函数。
你其实已经见过命名空间语法了——在前面的 “Hello, World” 程序中,println 这个名字就定义在 std 命名空间中。使用 using 指令之后,“Hello, World” 可以写成下面这样:
import std;
using namespace std;
int main(){ println("Hello, World!");}using 声明则更细粒度,它只会把命名空间中的某个具体名字引入当前作用域。例如,如果你只希望 print 可以不带限定名使用,就可以写成下面这样:
using std::print;这样一来,后续代码里就可以直接使用 print,但 std 命名空间中的其他名字,例如 println,仍然必须显式写出:
using std::print;print("Hello, ");std::println("World!");绝不要在处于全局作用域的头文件中写 using 指令或 using 声明;否则任何包含该头文件的人都会被强行带上这些名字。如果把它们限制在更小的作用域里——例如命名空间作用域或类作用域——那么即便出现在头文件中,通常也是可以接受的。对于模块接口文件,只要你不把它导出,写 using 指令或声明也完全没问题。不过,本书在模块接口文件中始终会对所有类型写出完整限定名,因为我认为那会让接口更容易理解。模块接口文件以及从模块中导出实体,会在本章后面继续解释。
嵌套命名空间
Section titled “嵌套命名空间”嵌套命名空间,就是在一个命名空间里面再定义另一个命名空间。各层之间同样使用双冒号连接。例如:
namespace MyLibraries::Networking::FTP { /* … */}这种紧凑写法是从 C++17 才开始支持的;在此之前,只能写成下面这种层层嵌套的形式:
namespace MyLibraries { namespace Networking { namespace FTP { /* … */ } }}命名空间别名
Section titled “命名空间别名”命名空间别名可以给一个较长的命名空间起一个新的、更短的名字。例如:
namespace MyFTP = MyLibraries::Networking::FTP;字面量用于在代码中直接写出数字或字符串。C++ 支持多种标准字面量。整数可以写成下面几种形式(它们表示的都是同一个数值 123):
- 十进制字面量:
123 - 八进制字面量:
0173(以 0 开头) - 十六进制字面量:
0x7B(以0x开头) - 二进制字面量:
0b1111011(以0b开头)
除非你写的本来就是八进制字面量,否则不要在数值前面随手加一个 0!
C++ 中其他常见字面量还包括:
- 浮点值(例如
3.14f) - 双精度浮点值(例如
3.14) - 十六进制浮点字面量(例如
0x3.ABCp-10与0Xb.cp12l) - 单个字符(例如
'a') - 以零结尾的字符数组(例如
"character array")
字面量还可以带后缀,例如 3.14f 里的 f,用来显式指定类型。在这里,3.14f 的类型是 float,而 3.14 的类型则是 double。
单引号还可以在数字字面量中充当分隔符。例如:
23'456'7892'34'56'7890.123'456f
仅由空白分隔的多个字符串字面量,会自动拼接成一个字符串。例如:
std::println("Hello, " "World!");它等价于:
std::println("Hello, World!");你还可以自定义自己的字面量类型,不过这属于进阶主题,详见第 15 章“重载 C++ 运算符”。
在 C++ 中,变量 几乎可以在代码的任意位置声明,并且从声明所在行开始,在当前代码块的后续位置都可以使用。变量可以声明后暂时不赋值,但这种未初始化变量通常会携带当时内存里的残留内容,表现出近乎随机的值,因此是大量 bug 的源头。变量当然也可以在声明时直接初始化。下面的例子展示了这两种写法,类型都为表示整数的 int:
int uninitializedInt;int initializedInt { 7 };println("{} 是一个随机值", uninitializedInt);println("{} 被赋予了初始值", initializedInt);变量 initializedInt 使用的是统一初始化语法。你当然也可以使用下面这种老式赋值写法来完成初始化:
int initializedInt = 7;统一初始化是在 2011 年随 C++11 一起引入的。相比旧式赋值初始化,统一初始化更推荐使用,因此本书会统一采用这一风格。本章后面的“统一初始化”一节会进一步解释它的优势以及推荐理由。
C++ 是强类型语言,也就是说,每个变量都有明确的类型。语言本身已经提供了一整套可直接使用的内建类型。下表列出的是其中最常见的一些:
| 类型 | 描述 | 用法 |
|---|---|---|
(signed) int signed | 有符号整数,可表示正数和负数;范围取决于编译器(通常为 4 字节) | int i {-7}; signed int i {-6}; signed i {-5}; |
(signed) short (int) | 短整型(通常为 2 字节) | short s {13}; short int s {14}; signed short s {15}; signed short int s {16}; |
(signed) long (int) | 长整型(通常为 4 字节) | long l {-7L}; |
(signed) long long (int) | 长长整型;范围依编译器而定,但至少不小于 long(通常为 8 字节) | long long ll {14LL}; |
unsigned (int) unsigned short (int) unsigned long (int) unsigned long long (int) | 对应前述无符号整型,只能表示大于等于 0 的值 | unsigned int i {2U}; unsigned j {5U}; unsigned short s {23U}; unsigned long l {54UL}; unsigned long long ll {140ULL}; |
float | 单精度浮点数 | float f {7.2f}; |
double | 双精度浮点数,精度至少不低于 float | double d {7.2}; |
long double | 扩展精度浮点数,精度至少不低于 double | long double d {16.98L}; |
char unsigned char signed char | 单个字符 | char ch {'m'}; |
char8_t char16_t char32_t | 单个以 UTF-n 编码的 Unicode 字符,其中 n 可以是 8、16 或 32 | char8_t c8 {u8'm'}; char16_t c16 {u'm'}; char32_t c32 {U'm'}; |
wchar_t | 单个宽字符;大小取决于编译器 | wchar_t w {L'm'}; |
bool | 布尔类型,取值只有 true 或 false | bool b {true}; |
signed / unsigned 整数以及 char 类型的大致范围如下:
| 类型 | 有符号 | 无符号 |
|---|---|---|
char | -128 至 127 | 0 到 255 |
| 2 字节整数 | -32,768 至 32,767 | 0 至 65,535 |
| 4 字节整数 | -2,147,483,648 至 2,147,483,647 | 0 至 4,294,967,295 |
| 8 字节整数 | -9,223,372,036,854,775,808 至 9,223,372,036,854,775,807 | 0 至 18,446,744,073,709,551,615 |
要注意,char 和 signed char、unsigned char 并不是同一种类型。char 应当只拿来表示字符。至于它究竟被实现为有符号还是无符号,则取决于编译器,因此不要依赖它的符号性。
浮点类型的范围和精度将在本章后面的“浮点数”部分讨论。
与 char 密切相关的是 <cstddef> 里定义的 std::byte,它表示一个字节。在 C++17 之前,人们通常会用 char 或 unsigned char 表示字节,但那会让代码看起来像是在处理字符。相比之下,std::byte 能更清晰地表达你的真实意图——你操作的是一块单字节内存。它可以像下面这样初始化:
std::byte b { 42 };C++ 提供了一套标准方式来查询数值范围信息,例如当前平台上 int 的最大取值。在 C 里,你可能会直接使用 INT_MAX 这样的常量。虽然这些常量在 C++ 中依然存在,但更推荐使用 <limits> 中定义的 std::numeric_limits 类模板。类模板的细节会在后文讨论,不过现在只需要知道:既然它是模板,你就要在尖括号中写出关心的类型。比如,查询 int 的数值范围时,要写成 std::numeric_limits<int>。至于它还能提供哪些信息,可以查阅标准库参考资料(见附录 B)。
以下是一些示例:
println("int 类型:");println("int 的最大值:{}", numeric_limits<int>::max());println("int 的最小值:{}", numeric_limits<int>::min());println("int 的最低值:{}", numeric_limits<int>::lowest());
println("\ndouble 类型:");println("double 的最大值:{}", numeric_limits<double>::max());println("double 的最小正值:{}", numeric_limits<double>::min());println("double 的最低值:{}", numeric_limits<double>::lowest());这段代码在我的系统上的输出如下:
int 类型:int 的最大值:2147483647int 的最小值:-2147483648int 的最低值:-2147483648
double 类型:double 的最大值:1.7976931348623157e+308double 的最小正值:2.2250738585072014e-308double 的最低值:-1.7976931348623157e+308注意 min() 和 lowest() 之间的差别。对整数来说,两者相同;但对浮点类型而言,min() 表示“可表示的最小正值”,而 lowest() 表示“可表示的最小值”,也就是最负的那个数,它等于 -max()。
你可以用 {0} 或零初始化器 {} 把变量初始化为零。零初始化会把基础整数类型(如 char、int 等)设为 0,把基础浮点类型设为 0.0,把指针设为 nullptr,而对象类型则会调用默认构造函数(后文会讲)。
以下是零初始化 float 和 int 的示例:
float myFloat {};int myInt {};变量可以通过类型转换变成其他类型。例如,可以把 float 转成 int。C++ 提供了三种显式改变变量类型的方式。第一种是从 C 继承下来的写法;不推荐,但遗憾的是仍然很常见。第二种很少用。第三种最啰嗦,但也最清晰,因此最值得推荐。
float myFloat { 3.14f };int i1 { (int)myFloat }; // 方法 1int i2 { int(myFloat) }; // 方法 2int i3 { static_cast<int>(myFloat) }; // 方法 3转换后的整数,会是去掉小数部分后的结果。第 10 章“深入继承技巧”会更详细地介绍各种转换方式。在某些场景下,编译器也会自动进行类型转换,也就是隐式转换。例如,short 可以自动转成 long,因为 long 表示的是同类数据,而且精度至少不比 short 低:
long someLong { someShort }; // 不需要显式转换进行自动类型转换时,要时刻警惕可能发生的数据丢失。例如,把 float 转成 int 会直接丢弃小数部分;如果这个浮点数本身已经超过 int 能表示的上限,那么转换结果甚至可能彻底错误。对于没有显式转换就把 float 赋给 int 这种代码,大多数编译器都会给出警告,甚至直接报错。只有在你非常确定左侧类型和右侧类型完全兼容时,才适合接受隐式转换。
浮点数远比整数难伺候。这里至少要记住几件事:数量级相差很大的浮点数混合运算,可能带来明显误差;两个极其接近的浮点数相减,也会损失精度;此外,还有很多十进制数根本无法被浮点数精确表示。不过,浮点数的数值分析问题,以及如何编写数值稳定的浮点算法,已经超出本书范围了——这类话题足够写一本独立的书。
有几种特殊的浮点数:
- 正/负无穷大: 表示正无穷大和负无穷大,例如非零数除以零的结果
- NaN: “非数字”的缩写,例如 0 除以 0 的结果,这是数学上未定义的值
如果要判断某个浮点值是不是 NaN,可以使用 std::isnan();判断它是不是无穷大,则使用 std::isinf()。这两个函数都定义在 <cmath> 中。
如果你想直接取得这些特殊浮点值,可以借助 numeric_limits,例如 std::numeric_limits<double>::infinity()。
Section titled “ 扩展浮点类型”正如前面介绍变量时提到的,C++ 提供了三种标准浮点类型:float、double 和 long double。
C++23 又增加了一组在某些领域日益常见的扩展浮点类型。这些类型的支持是可选的,因此并不是所有编译器都会提供。
| 类型 | 描述 | 字面量后缀 |
|---|---|---|
std::float16_t | IEEE 754 标准的 16 位格式。 | F16 或 f16 |
std::float32_t | IEEE 754 标准的 32 位格式。 | F32 或 f32 |
std::float64_t | IEEE 754 标准的 64 位格式。 | F64 或 f64 |
std::float128_t | IEEE 754 标准的 128 位格式。 | F128 或 f128 |
std::bfloat16_t | Brain 浮点格式。1 常见于某些 AI 场景。 | BF16 或 bf16 |
大多数时候,float、double 和 long double 这三种标准类型已经足够用了。通常应当把 double 作为默认选择。使用 float 可能带来精度损失,而这种损失是否可接受,则取决于你的具体场景。
浮点类型的范围和精度
Section titled “浮点类型的范围和精度”浮点类型具有有限的范围和有限的精度。下表给出了 C++ 支持的所有标准和扩展浮点类型的详细规范。但是,C++ 标准并未准确指定标准类型float、double 和long double 的规范。该标准仅规定long double应至少具有与double相同的精度,double应至少与float具有相同的精度。对于这三种类型,该表显示了编译器常用的值。
| 类型 | 名称 | 尾数位数 | 十进制有效位 | 指数位数 | 最小值 | 最大值 |
|---|---|---|---|---|---|---|
float | 单精度 | 24 | 7.22 | 8 | 1.18x10-38 | 3.40x10^38 |
double | 双精度 | 53 | 15.95 | 11 | 2.23x10-308 | 1.80x10^308 |
long double | 扩展精度 | 64 | 19.27 | 15 | 3.36x10−4932 | 1.19x10^4932 |
std::float16_t | 半精度 | 11 | 3.31 | 5 | 6.10x10-5 | 65504 |
std::float32_t | 单精度 | 24 | 7.22 | 8 | 1.18x10-38 | 3.40x10^38 |
std::float64_t | 双精度 | 53 | 15.95 | 11 | 2.23x10-308 | 1.80x10^308 |
std::float128_t | 四倍精度 | 113 | 34.02 | 15 | 3.36x10−4932 | 1.19x10^4932 |
std::bfloat16_t | Brain 浮点格式 | 8 | 2.41 | 8 | 1.18x10-38 | 3.40x10^38 |
变量如果不能参与运算,那就没什么意义了。下表列出了一些 C++ 中最常见的运算符及其基本用法。C++ 的运算符既可以是二元的(作用于两个表达式),也可以是一元的(作用于一个表达式),甚至还有三元的(作用于三个表达式)。不过三元运算符在 C++ 里只有一个,会在本章后面的“条件运算符”一节介绍。第 15 章“重载 C++ 运算符”则会专门讲如何让你自己的类型也支持这些运算符。
| 运算符 | 描述 | 用法 |
|---|---|---|
= | 二元运算符,把右侧的值赋给左侧表达式。 | int i; i = 3; int j; j = i; |
! | 一元逻辑非运算符,翻转表达式的真 / 假状态。 | bool b {!true}; bool b2 {!b}; |
+ | 二元加法运算符。 | int i {3 + 2}; int j {i + 5}; int k {i + j}; |
- * / | 二元减法、乘法和除法运算符。 | int i {5 – 1}; int j {5 * 2}; int k {j / i}; |
% | 取余运算符,也称 mod / modulo。例如 5 % 2 = 1。 | int rem {5 % 2}; |
++ | 一元自增运算符。放在后面是后置自增,表达式结果是自增前的值;放在前面是前置自增,表达式结果是自增后的值。 | i++; ++i; |
-- | 一元自减运算符。 | i--; --i; |
+= -= *= /= %= | 下列写法的缩写:i = i + (j); i = i - (j); i = i * (j); i = i / (j); i = i % (j); | i += j; i -= j; i *= j; i /= j; i %= j; |
& &= | 对表达式执行按位与。 | i = j & k; j &= k; |
| |= | 对表达式执行按位或。 | i = j | k; j |= k; |
<< >> <<= >>= | 将表达式的位向左或向右移动指定的位数。 | i = i << 1; i = i >> 4; i <<= 1; i>>= 4; |
^ ^= | 对两个表达式执行按位异或(XOR)。 | i = i ^ j; i ^= j; |
op= 形式的运算符,例如+=,称为复合赋值运算符。
当二元运算符作用于两个不同类型的操作数时,编译器会在运算前插入隐式转换,把其中一个操作数转成另一个类型。你也可以主动使用 static_cast() 来做显式转换。
隐式转换遵循一套固定规则。例如,一个较小整数类型和一个较大整数类型一起参与运算时,前者往往会被提升为后者。但这种自动行为并不总能得到你想要的结果。因此,我建议对隐式转换保持警惕,在需要明确语义时主动使用显式转换。
下面这段代码把几种常见变量类型和运算符串在了一起,也展示了显式转换为什么有时是必要的。如果你还不太确定这些规则是怎么运作的,不妨先自己猜一下程序输出,再运行验证。
int someInteger { 256 };short someShort;long someLong;float someFloat;double someDouble;
someInteger++;someInteger *= 2;// 从更大的整数类型转换到更小的整数类型// 可能导致警告或错误,因此需要使用 static_cast()。someShort = static_cast<short>(someInteger);someLong = someShort * 10000;someFloat = someLong + 0.785f;// 为了确保除法以 double 精度执行,// 先把 someFloat 显式转换为 double。someDouble = static_cast<double>(someFloat) / 100000;println("{}", someDouble);C++ 对表达式的求值顺序有明确规则。但如果一个表达式里塞进了太多运算符,实际执行顺序往往并不直观。因此,更好的做法通常是把复杂表达式拆成几个较小的表达式,或者用括号显式分组。比如,下面这行代码如果你不清楚运算优先级,看起来就会有些绕:
int i { 34 + 8 * 2 + 21 / 7 % 2 };加上括号以后,先算什么就一目了然了:
int i { 34 + (8 * 2) + ( (21 / 7) % 2 ) };这两种写法是等价的,最终 i 都等于 51。如果你误以为 C++ 会严格从左往右算,那么答案可能会被你算成 1。实际上,C++ 会先计算 /、* 和 %(同级时从左到右),再处理加减,之后才轮到位运算等更低优先级的部分。括号的价值就在于:它能明确告诉编译器和读代码的人,哪些部分要先算。
更正式地说,运算顺序由运算符的优先级决定。优先级越高,越先执行。下面这份列表给出了上表中那些运算符的大致优先级顺序:越靠上的,优先级越高。
++ −−(后缀)! ++ −−(前缀)* / %+ −<< >>&^|= += -= *= /= %= &= |= ^= <<= >>=
这里只列出了 C++ 运算符中的一部分。第 15 章会给出更完整的全景介绍,包括它们的优先级。
一个整数本质上只是“整个整数集合中的某一个值”。而枚举则允许你定义属于自己的一组离散取值,并据此声明变量。比如,在一个国际象棋程序里,你可以用 int 表示棋子的种类,并定义若干常量来代表不同棋子,就像下面这样。这里这些整数常量都被声明为 const,表示它们不会再被修改。
const int PieceTypeKing { 0 };const int PieceTypeQueen { 1 };const int PieceTypeRook { 2 };const int PieceTypePawn { 3 };// 等等。int myPiece { PieceTypeKing };这种表示其实很危险。因为棋子本质上只是一个 int,如果后来有别的程序员写出“把棋子值加一”的代码会怎样?国王加一就变成王后了,这显然不合理。更糟的是,还可能有人把棋子设成 -1,而这个值根本没有任何对应含义。
强类型枚举可以很好地解决这些问题,因为它把变量允许的取值范围限定得非常明确。下面的代码声明了一个新类型 PieceType,它包含四个可能的值,这些值称为枚举项,分别代表四种棋子:
enum class PieceType { King, Queen, Rook, Pawn };这个新类型可以这样使用:
PieceType piece { PieceType::King };在底层实现上,枚举仍然对应整数值。默认情况下,King、Queen、Rook 和 Pawn 的底层值分别是 0、1、2、3。当然,你也可以手动指定这些整数值:
enum class PieceType{ King = 1, Queen, Rook = 10, Pawn};如果某个枚举项没有显式赋值,编译器会把它设为前一个枚举项再加 1。如果第一个枚举项也没有赋值,则默认为 0。因此在这个例子中,King 的值是 1,Queen 会被编译器自动设为 2,Rook 为 10,而 Pawn 会继续自动变成 11。
虽然枚举项底层对应整数,但它们不会自动隐式转换成整数,因此下面这种写法是非法的:
int underlyingValue { piece };std::to_underlying() 来取得底层整数值。例如:
int underlyingValue { to_underlying(piece) };默认情况下,枚举的底层类型是 int,但也可以像下面这样改成别的整数类型:
enum class PieceType : unsigned long{ King = 1, Queen, Rook = 10, Pawn};对于 enum class 来说,枚举项名字不会自动暴露到外层作用域。因此,它们不会轻易和外层已有名字发生冲突。也正因为如此,不同的强类型枚举完全可以拥有同名枚举项。例如下面这两段定义都是合法的:
enum class State { Unknown, Started, Finished };enum class Error { None, BadInput, DiskFull, Unknown };这样做的一大好处,是你可以放心使用更短、更自然的枚举项名字,比如直接写 Unknown,而不必退回到 UnknownState、UnknownError 这种冗长写法。但代价是:默认情况下你必须写全限定名,或者借助 using enum / using 声明。下面是 using enum 的示例:
using enum PieceType;PieceType piece { King };如果你只想省掉某几个具体枚举项前面的限定名,也可以使用 using 声明。例如下面这段代码中,King 可以直接写,但其他枚举项仍然要完整限定:
using PieceType::King;PieceType piece { King };piece = PieceType::Queen;虽然 C++ 允许你省去枚举项前面的完整限定名,但我仍然建议谨慎使用这项功能。至少要把 using enum 或 using 声明的作用域控制得足够小,否则命名冲突的问题又会回来了。本章后面介绍 switch 语句时,会展示一个作用域控制得比较恰当的 using enum 用法。
新代码应当始终优先使用上一节介绍的强类型枚举。不过在遗留代码库中,你仍然会见到旧式枚举,也叫无作用域枚举:它写作 enum,而不是 enum class。前面的 PieceType 如果改写成旧式枚举,就是这样:
enum PieceType { PieceTypeKing, PieceTypeQueen, PieceTypeRook, PieceTypePawn };这类旧式枚举的枚举项名字会直接暴露到外围作用域中。换句话说,在父作用域里你可以不写限定名就直接使用它们,例如:
PieceType myPiece { PieceTypeQueen };当然,这也意味着它们很容易和外围作用域中已有的名字撞车,并引发编译错误。例如:
bool ok { false };enum Status { error, ok };这段代码无法编译,因为 ok 先被定义成了一个布尔变量,后面又被拿来当作枚举项名字。Visual C++ 2022 给出的错误如下:
error C2365: 'ok': redefinition; previous definition was 'data variable'因此,如果你不得不使用旧式枚举,就应该尽量让枚举项名字本身足够独特,例如使用 PieceTypeQueen,而不是单独一个 Queen。
旧式枚举也不是强类型的,也就是说它们不具备类型安全。它们会被当成普通整数处理,因此你可能会不小心把两个完全不同枚举里的值拿来比较,或者把错误枚举里的值传给函数。
请始终优先使用强类型的 enum class,避免使用旧式、无作用域且不类型安全的 enum。
结构体允许你把一个或多个现有类型组合成一个新类型。结构体最经典的例子之一,就是数据库记录。假设你正在编写一个人事系统,想存储每位员工的名首字母、姓首字母、员工编号和工资,那么把这些信息放进同一个结构体就很自然。下面这份 employee.cppm 模块接口文件就给出了这样一个例子。这也是本书中你会自己编写的第一个模块。模块接口文件通常以 .cppm 为扩展名。文件第一行是模块声明,用来说明这个文件定义了一个名为 employee 的模块。此外,模块还必须显式说明自己导出了什么,也就是别的地方导入该模块后能看见什么。导出一个类型时,只需在 struct 之类的定义前加上 export 即可。
export module employee;
export struct Employee { char firstInitial; char lastInitial; int employeeNumber; int salary;};凡是声明为 Employee 类型的变量,都会拥有这些内置字段。结构体中的各个字段可以通过 . 运算符访问。下面的示例创建了一个员工对象,并把其中的值输出出来。和标准命名模块 std 一样,导入自定义模块时也不需要写尖括号。
import std;import employee; // 导入我们自己的 employee 模块
using namespace std;
int main(){ // 创建并填充一个 employee 对象。 Employee anEmployee; anEmployee.firstInitial = 'J'; anEmployee.lastInitial = 'D'; anEmployee.employeeNumber = 42; anEmployee.salary = 80000; // 输出 employee 对象中的值。 println("员工:{}{}", anEmployee.firstInitial, anEmployee.lastInitial); println("编号:{}", anEmployee.employeeNumber); println("工资:${}", anEmployee.salary);}条件语句(conditional statements) 让你能够根据条件是否成立来决定执行哪段代码。在 C++ 中,最常见的两类条件语句是 if/else 和 switch。
if/else 语句
Section titled “if/else 语句”最常见的条件语句就是 if,它也可以带一个 else 分支。如果 if 中给出的条件为 true,就执行对应的语句或语句块;否则,就继续执行 else 分支(如果存在),或者直接跳到整个条件语句后面的代码。下面这段代码展示了一个级联 if 语句,也就是 if 的 else 分支里又接了另一个 if,如此层层展开:
if (i> 4) { // 做些事情。} else if (i> 2) { // 做点别的事情。} else { // 做点别的事情。}if 括号中的表达式必须本身是布尔值,或者能够求值为布尔值。值 0 会被当作 false,任何非零值都会被当作 true。例如,if (0) 和 if (false) 是等价的。本章稍后介绍的逻辑求值运算符,就是用来构造这类会产生 true 或 false 的表达式的。
if 语句的初始化器
Section titled “if 语句的初始化器”C++ 允许你在 if 语句中同时写初始化器,语法如下:
if (<初始化器>; <条件表达式>) { <if_主体>} else if (<else_if_表达式>) { <else_if_主体>} else { <else_主体>}在 <初始化器> 中引入的变量,只在 <条件表达式>、<if_主体>、所有 <else_if_表达式> / <else_if_主体>,以及 <else_主体> 中可见;一旦离开这个 if 语句,这些变量就不再可用。
本书后面会给出更贴近实际的例子,不过你现在先看看它的写法就够了:
if (Employee employee { getEmployee() }; employee.salary> 1000) { … }在这个例子里,初始化器通过调用 getEmployee() 函数得到一个员工对象。本章后面会介绍函数。条件部分随后检查这位员工的工资是否高于 1000;只有条件成立时,if 语句体才会执行。本书后续还会不断看到这种写法。
switch 语句
Section titled “switch 语句”switch 语句提供了另一种基于表达式取值执行动作的写法。在 C++ 中,switch 的控制表达式必须是整数类型、可转换为整数的类型、枚举,或者强类型枚举,并且它会和一组常量值进行比较。每一个常量值就是一个 case。一旦表达式和某个 case 匹配,就会从那里开始执行后续语句,直到遇到 break。你也可以提供一个 default 分支,用来处理所有其他 case 都不匹配的情况。下面的伪代码展示了 switch 的常见形式:
switch (menuItem) { case OpenMenuItem: // 打开文件的代码 break; case SaveMenuItem: // 保存文件的代码 break; default: // 输出错误消息的代码 break;}任何 switch 语句,理论上都可以改写成 if/else。前面的例子改写后就是:
if (menuItem == OpenMenuItem) { // 打开文件的代码} else if (menuItem == SaveMenuItem) { // 保存文件的代码} else { // 输出错误消息的代码}通常,当你要根据表达式的多个特定取值执行不同操作时,会更适合使用 switch;这样可以避免写出一长串级联 if/else。如果你只需要检查一种情况,直接用 if 或 if/else 通常就足够了。
一旦找到和 switch 条件匹配的 case,程序就会继续向下执行后面的所有语句,直到遇到 break 为止;即使途中又碰到下一个 case 标签,也不会自动停下。这种行为叫做 fallthrough。下面这个例子中,Mode::Standard 和 Mode::Default 共用同一组语句;如果模式是 Custom,则会先把 value 从 42 改成 84,然后继续执行 Standard / Default 对应的语句。换句话说,Custom 分支会一路贯穿,直到最终遇到 break 或走到 switch 末尾。这个例子也顺便展示了一个作用域控制得当的 using enum 用法,它让不同的 case 标签不必反复写 Mode::Custom、Mode::Standard、Mode::Default。
enum class Mode { Default, Custom, Standard };
int value { 42 };Mode mode { /* … */ };switch (mode) { using enum Mode;
case Custom: value = 84; case Standard: case Default: // 用 value 做点事情…… break;}fallthrough 很容易成为 bug 的来源,例如你可能只是不小心漏写了一个 break。因此,一些编译器在检测到 switch 中可能发生贯穿时,会发出警告,除非那个 case 本来就是空的。在前面的例子里,编译器通常不会对 Standard 继续落到 Default 发警告,但有可能会对 Custom 的贯穿给出提示。为了消除这种警告,同时也让读代码的人和编译器都明确知道这次贯穿是故意的,可以使用 [[fallthrough]] 属性:
switch (mode) { using enum Mode;
case Custom: value = 84; [[fallthrough]]; case Standard: case Default: // 用 value 做点事情…… break;}给 case 后面的语句块再包一层大括号,很多时候是可选的,但在某些场景下是必须的,例如你要在里面定义变量时。比如:
switch (mode) { using enum Mode;
case Custom: { int someVariable { 42 }; value = someVariable * 2; [[fallthrough]]; } case Standard: case Default: // 用 value 做点事情…… break;}当 switch 的控制对象是枚举时,大多数编译器都会在你没有覆盖所有枚举项时发出警告。你可以通过为每个枚举项都显式写出 case,或者只列出部分 case 再配合一个 default,来消除这种警告。不过,我更建议在针对枚举的 switch 中不要写 default,而是把所有枚举项都明确列出来。这样做的好处是:将来如果你给这个枚举新增了枚举项,却忘了同步更新某个 switch,编译器就会提醒你;否则,新的枚举项可能会被 default 悄悄吞掉。
switch 语句的初始化器
Section titled “switch 语句的初始化器”和 if 一样,switch 也支持初始化器,语法如下:
switch (<初始化器>; <表达式>) {<主体> }在 <初始化器> 中引入的变量,只在 <表达式> 和 <主体> 中可见;离开这个 switch 语句后,它们就失效了。
C++ 有一个接受三个操作数的运算符,通常叫做三元运算符(ternary operator)。它可以看作“如果 [某事成立],就 [执行某动作],否则 [执行另一动作]”这种条件表达式的简写形式。条件运算符由 ? 和 : 组成。下面这段代码会在变量 i 大于 2 时输出“是”,否则输出“否”:
println("{}", (i> 2) ? "是" : "否");i > 2 外层的括号是可选的,因此下面的写法完全等价:
println("{}", i> 2 ? "是" : "否");条件运算符的优势在于:它是一个表达式,而不是像 if 或 switch 那样的语句。因此,它几乎可以出现在任何可以放表达式的地方。前面的例子里,它就直接被嵌进了输出语句中。记忆这个语法的一个好办法,是把问号前面的内容当成一个真正的问题来读:例如,“i 是否大于 2?如果是,结果就是‘是’;否则,结果就是‘否’。”
逻辑求值运算符
Section titled “逻辑求值运算符”你其实已经见过逻辑求值运算符(logical evaluation operators) 了,只是前面还没有正式点名。比如 > 运算符会比较两个值;如果左边比右边大,结果就是 true。所有逻辑求值运算符都遵循同样的模式:它们最终都会产生一个 true 或 false。
下表列出了最常见的一些逻辑求值运算符:
| 运算符 | 描述 | 用法 |
|---|---|---|
< <= > >= | 判断左侧是否小于、小于等于、大于或大于等于右侧。 | if (i < 0) { print("i 是负数"); } |
== | 判断左侧是否等于右侧。不要把它和赋值运算符 = 混淆。 | if (i == 3) { print("i 等于 3"); } |
!= | 不等于。如果左侧不等于右侧,结果就是 true。 | if (i != 3) { print("i 不等于 3"); } |
<=> | 三向比较运算符,也叫宇宙飞船运算符。下一节会详细介绍。 | result = i <=> 0; |
! | 逻辑非。它会翻转布尔表达式的 true / false 状态。这是一个一元运算符。 | if (!bool1) { print("bool1 为 false"); } |
&& | 逻辑与。只有表达式两部分都为 true,结果才是 true。 | if (bool1 && bool2) { print("两者都为 true"); } |
|| | 逻辑或。只要表达式任意一部分为 true,结果就是 true。 | if (bool1 || bool2) { print("至少有一个为 true"); } |
C++ 在求值逻辑表达式时采用短路逻辑。这意味着:一旦整个表达式的最终结果已经确定,剩余部分就不会再被计算。例如,如果你把多个布尔表达式用逻辑“或”连起来,只要其中一个先被求值为 true,整个结果就已经确定为 true,后面的部分根本不会再检查。
bool result { bool1 || bool2 || (i> 7) || (27 / 13 % i + 1) < 2 };在这个例子里,如果 bool1 已经是 true,那整个表达式必然为 true,所以后面那些部分都不会执行。这样做的好处,是语言能帮你省掉不必要的工作;但如果后面的子表达式本来会改变程序状态(例如里面调用了某个函数),那短路也可能变成难以发现的 bug 来源。
下面这段使用 && 的代码,也会在第二项之后发生短路,因为 0 永远会被当作 false:
bool result { bool1 && 0 && (i> 7) && !done };短路往往还能改善性能。你可以把成本更低的测试放在前面,这样一旦逻辑提前得出结论,就连后面更昂贵的测试都不必执行了。在指针相关的代码里,它也很有用,因为可以借此避免在指针无效时继续求值后面的表达式。本章稍后讨论指针时,还会回到这个话题。
三向比较运算符(three-way comparison operator) 可用于判断两个值之间的顺序关系。它也常被叫作宇宙飞船运算符(spaceship operator),因为它的写法 <=> 看起来很像一艘飞船。通过一个表达式,它就能告诉你一个值是等于、小于,还是大于另一个值。由于它返回的信息不止 true 或 false,因此返回类型不是布尔值,而是定义在 <compare> 中、位于 std 命名空间里的某种“类似枚举”的类型。如果操作数是整数类型,那么结果属于强排序(strong ordering),其值可能是:
strong_ordering::less: 第一个操作数小于第二个strong_ordering::greater: 第一个操作数大于第二个strong_ordering::equal: 第一个操作数等于第二个
下面是一个使用示例:
int i { 11 };strong_ordering result { i <=> 0 };if (result == strong_ordering::less) { println("更小"); }if (result == strong_ordering::greater) { println("更大"); }if (result == strong_ordering::equal) { println("相等"); }某些类型并不存在完整的总排序。例如,NaN(非数字)形式的浮点值,永远不会等于、小于或大于任何其他浮点值。因此,这类比较得到的是部分排序(partial ordering):
partial_ordering::less:第一个操作数小于第二个partial_ordering::greater:第一个操作数大于第二个partial_ordering::equivalent:第一个操作数与第二个等价,也就是!(a < b) && !(b < a);例如,-0.0与+0.0等价,但它们并不相等partial_ordering::unordered:一个或两个操作数是 NaN(非数字)
如果你确实需要对浮点值做强排序——例如你很确定它们绝不会是 NaN(非数字)——那么可以使用 std::strong_order(),它总会产生 std::strong_ordering 结果。
此外还有一种弱排序(weak ordering),它是你在为自己的类型实现三向比较时可以选择的另一种排序类别。对于弱排序,所有值都能排出次序,也就是说不会出现 unordered;但它又不属于强排序,因为可能存在“彼此等价但并不相等”的值。一个典型例子,是按不区分大小写的规则对字符串排序。在这种情况下,字符串 “Hello World” 和 “hello world” 当然不相等,但它们可以被视为等价。弱排序可能得到的结果有:
weak_ordering::less:第一个操作数小于第二个weak_ordering::greater:第一个操作数大于第二个weak_ordering::equivalent:第一个操作数与第二个等价
这三种排序类型之间还支持一部分隐式转换:strong_ordering 可以隐式转换成 partial_ordering 或 weak_ordering;weak_ordering 则可以隐式转换成 partial_ordering。
对于基础类型来说,使用三向比较运算符,相比单独写 ==、<、>,收益并不算大。不过,一旦比较对象本身代价较高,这个运算符就会变得很有价值。因为你只需一个运算符,就能获得顺序结果,而不必潜在地调用多个单独的比较运算符,触发多次昂贵比较。第 9 章“精通类与对象”会解释如何为你自己的类型加入三向比较支持。
最后,<compare> 还提供了一组具名比较函数(named comparison functions),用来解释排序结果:std::is_eq()、is_neq()、is_lt()、is_lteq()、is_gt() 和 is_gteq()。如果某个排序结果分别表示 ==、!=、<、<=、> 或 >=,这些函数就会返回 true,否则返回 false。例如:
int i { 11 };strong_ordering result { i <=> 0 };if (is_lt(result)) { println("更小"); }if (is_gt(result)) { println("更大"); }if (is_eq(result)) { println("相等"); }对于任何稍微有点规模的程序来说,把所有代码都塞进 main() 都是无法管理的。为了让程序更容易理解,你需要把代码拆分,也就是分解(decompose) 成一组简洁的函数。
在 C++ 中,函数通常要先声明,其他代码才能使用它。如果某个函数只在单个文件内部使用,一般会直接在那个源文件中声明并定义它。如果函数要供其他模块或文件使用,则可以把它的声明从模块接口文件中导出,而函数定义既可以写在同一个模块接口文件里,也可以写在模块实现文件中(稍后会讲)。
下面这段代码就是一个函数声明。这里的返回类型是 void,表示函数不会向调用者返回结果。调用者必须传给它两个参数:一个整数和一个字符。
void myFunction(int i, char c);如果只有声明而没有与之匹配的实际定义,那么编译流程中的链接阶段就会失败,因为调用这个函数的代码最终会指向一段根本不存在的实现。下面这个定义会把两个参数的值打印出来:
void myFunction(int i, char c){ println("i 的值是 {}。", i); println("c 的值是 {}。", c);}在程序的其他位置,你就可以调用 myFunction(),并为这两个参数传入实参。下面是一些示例调用:
int someInt { 6 };char someChar { 'c' };myFunction(8, 'a');myFunction(someInt, 'b');myFunction(5, someChar);C++ 函数当然也可以向调用者返回(return) 一个值。下面这个函数会把两个数字相加并返回结果:
int addNumbers(int number1, int number2){ return number1 + number2;}这个函数可以这样调用:
int sum { addNumbers(5, 3) };函数返回类型推导
Section titled “函数返回类型推导”你也可以让编译器自动推导函数的返回类型。要启用这个特性,只需把返回类型写成 auto:
auto addNumbers(int number1, int number2){ return number1 + number2;}编译器会根据函数体里 return 语句所返回的表达式来推导返回类型。函数里可以有多个 return,但它们都必须推导出完全相同的类型,因为编译器不会为了推导返回类型而插入隐式转换。这样的函数甚至可以递归调用自己,不过函数中的第一个 return 语句必须不是递归返回。
当前函数的名称
Section titled “当前函数的名称”每个函数内部都有一个局部预定义变量 __func__,它保存着当前函数的名字。这个变量的一个典型用途,就是写日志。
int addNumbers(int number1, int number2){ println("进入函数 {}", __func__); return number1 + number2;}函数重载(function overloading) 指的是:提供多个同名函数,但让它们拥有不同的参数列表。仅仅返回类型不同是不够的,因为调用函数时返回值完全可能被忽略;真正必须不同的是参数的个数和/或类型。
假设你想提供既能处理整数、又能处理 double 的 addNumbers() 版本。如果没有重载机制,你就只能分别起不同的名字,例如:
int addNumbersInts(int a, int b) { return a + b; }double addNumbersDoubles(double a, double b) { return a + b; }有了函数重载之后,你就不必为了不同版本的同一功能去发明不同名字了。下面这段代码定义了两个都叫 addNumbers() 的函数:一个处理整数,另一个处理 double:
int addNumbers(int a, int b) { return a + b; }double addNumbers(double a, double b) { return a + b; }当调用 addNumbers() 时,编译器会根据传入参数自动选择正确的重载版本。这个过程叫做重载解析(overload resolution)。
println("{}", addNumbers(1, 2)); // 调用整数版本println("{}", addNumbers(1.11, 2.22)); // 调用 double 版本属性是一种把可选信息和/或编译器厂商特定信息附加到源代码中的机制。在属性被标准化之前,各家编译器都各自定义自己的写法,例如 __attribute__、__declspec 等。从 C++11 开始,语言通过双中括号语法 [[attribute]] 提供了统一的标准支持。
本章前面已经见过 [[fallthrough]] 属性,它用于告诉编译器:某个 switch case 的贯穿行为是故意的,从而避免相关警告。C++ 标准还定义了若干其他标准属性。
[[nodiscard]]
Section titled “[[nodiscard]]”[[nodiscard]] 属性可以标在“会返回值”的函数上。如果调用方忽略了这个返回值,编译器就会发出警告。例如:
[[nodiscard]] int func() { return 42; }
int main(){ func();}编译器会发出类似下面这样的警告:
warning C4834: discarding return value of function with 'nodiscard' attribute例如,这个属性很适合用于那些返回错误码的函数。给这类函数加上 [[nodiscard]] 之后,调用方就不容易悄悄忽略返回的错误信息。
更一般地说,[[nodiscard]] 还可以用于类、结构体、函数和枚举。一个典型做法,是把它加在代表错误状态的类上。这样一来,只要某个函数返回了这种错误对象,而调用方却什么也没做,编译器就会给出警告。
你还可以给 [[nodiscard]] 附带一段字符串形式的原因说明。如果调用方忽略了返回值,这段说明就会出现在编译器生成的警告消息里。例如:
[[nodiscard("Some explanation")]] int func();[[maybe_unused]]
Section titled “[[maybe_unused]]”[[maybe_unused]] 属性可以用来抑制“某个东西未被使用”的编译器警告,例如:
int func(int param1, int param2){ return 42;}如果编译器的警告级别开得足够高,这个函数定义会触发两个警告。例如,Microsoft Visual C++ 会给出下面这些提示:
warning C4100: 'param2': unreferenced formal parameterwarning C4100: 'param1': unreferenced formal parameter使用 [[maybe_unused]] 后,就可以抑制这类警告:
int func(int param1, [[maybe_unused]] int param2){ return 42;}在这个例子里,第二个参数被标上了抑制警告的属性,因此编译器现在只会针对 param1 发出警告:
warning C4100: 'param1': unreferenced formal parameter[[maybe_unused]] 可以用于类、结构体、非 static 数据成员、联合、typedef、类型别名、变量、函数、枚举以及枚举项。其中有些术语你现在也许还不熟,不过本书后面都会讲到。
[[noreturn]]
Section titled “[[noreturn]]”给函数加上 [[noreturn]] 属性,意味着这个函数永远不会把控制权返回给调用者。通常,这类函数要么会导致某种终止(例如终止进程或终止线程),要么会抛出异常。本章稍后会讨论异常。有了这个属性,编译器就能更准确地理解函数意图,从而避免发出某些不必要的警告或错误。例如:
import std;using namespace std;
[[noreturn]] void forceProgramTermination(){ exit(1); // 定义于 <cstdlib>}
bool isDongleAvailable(){ bool isAvailable { false }; // 检查授权加密狗是否存在…… return isAvailable;}
bool isFeatureLicensed(int featureId){ if (!isDongleAvailable()) { // 没有找到授权加密狗,终止程序执行! forceProgramTermination(); } else { // 已检测到加密狗,检查给定功能的授权情况…… bool isLicensed { featureId == 42 }; return isLicensed; }}
int main(){ bool isLicensed { isFeatureLicensed(42) }; println("{}", isLicensed);}这段代码可以顺利编译,不会产生任何警告或错误。不过,如果把 [[noreturn]] 去掉,编译器就会生成类似下面的警告(来自 Visual C++):
warning C4715: 'isFeatureLicensed': not all control paths return a value[[deprecated]]
Section titled “[[deprecated]]”[[deprecated]] 可以把某个实体标记为“已弃用”。这表示它仍然能用,但已经不再推荐继续使用。这个属性还可以接受一个可选参数,用来解释弃用原因,例如:
[[deprecated("Unsafe function, please use xyz")]] void func();如果你继续使用这个已弃用的函数,编译器通常会给出错误或警告。例如,GCC 会输出类似下面的警告:
warning: 'void func()' is deprecated: Unsafe function, please use xyz[[likely]] 和 [[unlikely]]
Section titled “[[likely]] 和 [[unlikely]]”似然属性 [[likely]] 和 [[unlikely]] 可以帮助编译器进行优化。例如,你可以用它们来标记 if 或 switch 中某个分支更可能被走到,或者更不可能被走到。不过,大多数时候其实不需要它们。如今的编译器和硬件通常已经具备很强的分支预测能力,能够自己处理这类问题;只有在某些性能极其关键的代码里,你才可能需要主动提供这类提示。语法如下:
int value { /* … */ };if (value> 11) [[unlikely]] { /* 做点事情…… */ }else { /* 做点别的事情…… */ }
switch (value){ [[likely]] case 1: // 做点事情…… break; case 2: // 做点事情…… break; [[unlikely]] case 12: // 做点事情…… break;}
Section titled “ [[assume]]”[[assume]] 属性允许编译器假定某个表达式恒为真,而不必在运行时真的去检查它。编译器可以利用这种假设进一步优化代码。举个例子,先看下面这个函数:
int divideBy32(int x){ return x / 32;}这个函数接收的是有符号整数,因此编译器必须生成能同时处理正数和负数除法的代码。如果你可以确定 x 永远不会是负数,但又因为某些原因无法把它改成 unsigned,就可以加入如下假设:
int divideBy32(int x){ [[assume(x >= 0)]]; return x / 32;}有了这个假设,编译器就可以省掉处理负数所需的额外代码,并把这次除法优化成一条更简单的指令,也就是右移 5 位。
C 风格数组
Section titled “C 风格数组”本节会简要介绍 C 风格数组,因为你在遗留代码里仍然会遇到它们。不过在现代 C++ 中,最好尽量避免使用 C 风格数组,而改用标准库设施,例如接下来会讲到的 std::array 和 vector。
数组(array) 用来保存一串相同类型的值,每个值都可以通过它在数组中的位置来访问。在 C++ 中,声明数组时必须写出数组大小。这个大小不能是普通变量,必须是常量,或者是常量表达式(constant expression, constexpr);常量表达式会在第 9 章中讨论。下面的代码先声明了一个包含 3 个整数的数组,然后用三行代码把每个元素初始化为 0:
int myArray[3];myArray[0] = 0;myArray[1] = 0;myArray[2] = 0;在 C++ 中,数组的第一个元素永远在位置 0,而不是位置 1!最后一个合法位置永远是“数组大小减 1”!
本章后面的“循环”部分会讲如何用循环初始化数组的每个元素。不过,除了前面的逐项赋值方式,你也可以直接用下面这一行完成零初始化(zero initialization):
int myArray[3] = { 0 };你甚至可以把那个 0 也省掉:
int myArray[3] = {};最后,连等号也可以省掉,因此还可以写成:
int myArray[3] {};数组也可以通过初始化列表来初始化;在这种情况下,编译器会自动推导数组大小。例如:
int myArray[] { 1, 2, 3, 4 }; // 编译器会创建一个包含 4 个元素的数组。如果你显式写出了数组大小,而初始化列表中的元素个数少于这个大小,那么剩余元素都会被设为 0。例如,下面这段代码只把第一个元素设成 2,其他元素都会变成 0:
int myArray[3] { 2 };如果想取得一个栈上 C 风格数组的大小,可以使用定义在 <array> 中的 std::size() 函数。它返回 std::size_t,这是定义在 <cstddef> 中的无符号整数类型。例如:
std::size_t arraySize { std::size(myArray) };过去更常见的一种做法,是用 sizeof 运算符来求栈上 C 风格数组的大小。sizeof 会返回其参数所占的字节数。要得到数组里的元素个数,就用整个数组的字节大小,除以第一个元素的字节大小。例如:
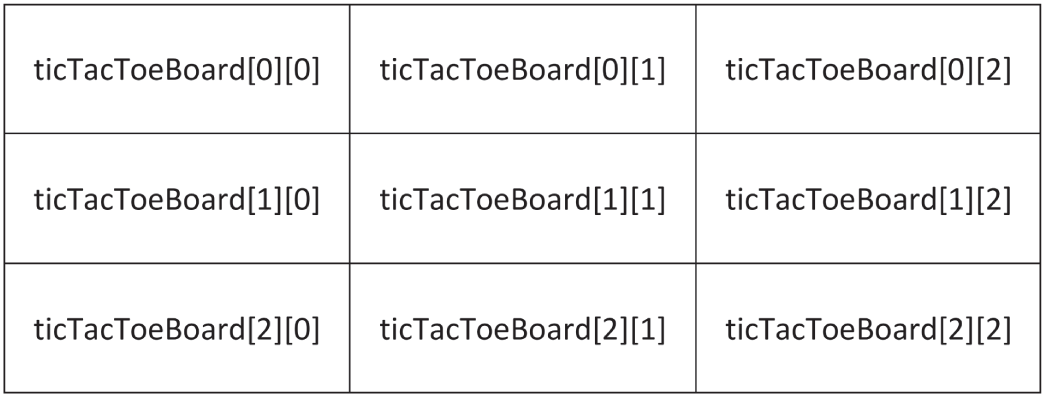
std::size_t arraySize { sizeof(myArray) / sizeof(myArray[0]) }; // C++17 之前, 见第 1 章前面的例子展示的是一个一维整数数组,你可以把它想象成一排按编号排列的格子。C++ 也支持多维数组。二维数组可以类比成棋盘:每个位置都同时有一个 x 轴坐标和一个 y 轴坐标。三维数组则可以想象成一个立方体,再更高维就不太容易直观想象了。下面的代码演示了如何为井字棋棋盘创建一个二维字符数组,并在中心格子里放一个 'o':
char ticTacToeBoard[3][3];ticTacToeBoard[1][1] = 'o';图 1.1 展示了这个棋盘的示意图,以及每个方格对应的位置。
std::array
Section titled “std::array”上一节介绍的数组来自 C,在 C++ 中当然仍然可用。不过,C++ 还提供了一种专门的固定大小容器类型 std::array,定义在 <array> 中。你可以把它理解为 C 风格数组的一层轻量封装。
[^FIGURE 1.1]
使用 std::array 代替 C 风格数组有不少好处。它始终知道自己的大小,不会自动退化成指针,从而避免某些常见错误;同时它还提供迭代器,便于遍历元素。迭代器会在第 17 章“理解迭代器和范围库”中详细讨论。
下面这个例子展示了如何使用 array 容器。array 是一个类模板(class template),它接受若干模板参数,让你可以指定容器中元素的类型以及元素个数。你需要把这些模板参数写在 array 后面的尖括号里,例如 array<int, 3>。第 12 章“使用模板编写通用代码”会详细讨论模板;现在你只要记住,这里必须写两个参数:第一个是数组元素类型,第二个是数组大小。
array<int, 3> arr { 9, 8, 7 };println("数组大小 = {}", arr.size());println("第 2 个元素 = {}", arr[1]);C++ 支持类模板参数推导(class template argument deduction, CTAD),这一点会在第 12 章 里详细解释。此刻你只需要知道:对于某些类模板,它可以让你不必手动写出尖括号里的模板参数。CTAD 只有在存在初始化器时才起作用,因为编译器需要根据初始化器自动推导模板参数。对 std::array 来说,前面的数组还可以这样写:
array arr { 9, 8, 7 };如果你需要一个动态大小的数组,推荐使用下一节要介绍的 std::vector。当你往里添加新元素时,vector 会自动扩容。
std::vector
Section titled “std::vector”C++ 标准库提供了许多大小不固定的容器,用来存储信息;声明在 <vector> 中的 std::vector 就是其中之一。vector 用一种更灵活、更安全的机制,取代了 C 风格数组的概念。作为使用者,你无需亲自管理内存,因为 vector 会自动分配足够的空间来容纳元素。vector 还是动态的,这意味着元素可以在运行时添加和删除。第 18 章“标准库容器”会更系统地讲解容器,不过 vector 的基本用法非常直接,所以本书在一开始就先介绍它,方便后面的示例直接使用。下面的代码展示了 vector 的基本功能:
// 创建一个整数 vector。vector<int> myVector { 11, 22 };
// 使用 push_back() 再向 vector 追加几个整数。myVector.push_back(33);myVector.push_back(44);
// 访问元素。println("第 1 个元素:{}", myVector[0]);myVector 被声明为 vector<int>。和 std::array 一样,你需要用尖括号来指定模板参数。vector 是一个通用容器,几乎可以存放任意类型的对象,但同一个 vector 里的所有元素都必须属于同一种类型,而这个类型就写在尖括号中。模板会在第 12 章和第 26 章“高级模板”中展开讨论。
和 std::array 一样,vector 类模板也支持 CTAD,因此 myVector 还可以写成:
vector myVector { 11, 22 };同样,CTAD 需要初始化器才能工作,因此下面这种写法是非法的:
vector myVector;要向 vector 添加元素,可以使用成员函数 push_back()。访问单个元素时,则可以使用和数组类似的语法,也就是 operator[]。
std::pair
Section titled “std::pair”std::pair 类模板在<utility> 中定义。它将两个可能不同类型的值组合在一起。这些值可通过first 和second 公共数据成员访问。这是一个例子:
pair<double, int> myPair { 1.23, 5 };println("{} {}", myPair.first, myPair.second);pair还支持CTAD,因此您可以如下定义myPair:
pair myPair { 1.23, 5 };std::optional
Section titled “std::optional”std::optional 定义在 <optional> 中,它要么保存一个特定类型的值,要么什么都不保存。之所以在第 1 章就介绍它,是因为它在整本书后续的很多示例里都很有用。
从本质上说,如果你希望某个值是“可选的”,就可以在函数参数中使用 optional。如果一个函数有时能返回结果、有时又没有结果,它也很适合作为返回类型。这样一来,就不必再用 nullptr、-1、EOF 之类“特殊值”来表达“没有结果”。它还避免了另一种老写法:函数本身只返回一个布尔值表示成功或失败,而真正的结果则通过输出参数带回(也就是通过“对非 const 的引用”参数返回,本章稍后会讲到)。
optional 是一个类模板,因此你必须在尖括号里写出它实际要保存的类型,例如 optional<int>。这和为 vector 指定元素类型时的语法很像,比如 vector<int>。
下面是一个返回 optional 的函数示例:
optional<int> getData(bool giveIt){ if (giveIt) { return 42; } return nullopt; // 或者直接写 return {};}你可以这样调用这个函数:
optional<int> data1 { getData(true) };optional<int> data2 { getData(false) };要判断一个 optional 里是否真的有值,可以调用成员函数 has_value(),也可以直接把它放进 if 语句里判断:
println("data1.has_value = {}", data1.has_value());if (!data2) { println("data2 没有值。");}如果 optional 里有值,你可以通过 value() 取出它,也可以使用解引用运算符 *。这个运算符会在本章后面的指针部分详细介绍。
println("data1.value = {}", data1.value());println("data1.value = {}", *data1);如果你对一个空的 optional 调用 value(),就会抛出 std::bad_optional_access 异常。本章稍后会介绍异常。
value_or() 可以在 optional 为空时返回另一个后备值;如果它有值,则返回里面的值:
println("data2.value = {}", data2.value_or(0));你不能在 optional 中存放引用(引用也会在本章后面讲到),因此 optional<T&> 是行不通的。相对地,你可以在 optional 里存放指针。
结构化绑定(structured bindings) 允许你一次声明多个变量,并用某个数据结构(例如 array、struct 或 pair)中的元素来初始化它们。
假设你有下面这样一个 std::array:
array values { 11, 22, 33 };你可以像下面这样声明三个变量 x、y 和 z,并用数组中的三个值来初始化它们。结构化绑定必须使用 auto 关键字;也就是说,你不能把这里的 auto 换成 int。
auto [x, y, z] { values };结构化绑定左侧声明的变量个数,必须和右侧表达式中可分解出的值的个数一致。
如果一个 struct 的所有非 static 成员都是公有的,那么结构化绑定同样可以用于它。例如:
struct Point { double m_x, m_y, m_z; };Point point;point.m_x = 1.0; point.m_y = 2.0; point.m_z = 3.0;auto [x, y, z] { point };最后再看一个例子:下面这段代码把一个 pair 分解成两个独立变量:
pair myPair { "你好", 5 };auto [theString, theInt] { myPair }; // 使用结构化绑定进行分解。println("字符串:{}", theString);println("整数:{}", theInt);你还可以借助结构化绑定创建一组“对非 const 的引用”或“对 const 的引用”,只需把 auto 换成 auto& 或 const auto& 即可。这两种引用形式也会在本章后面讨论。
计算机最擅长的事情之一,就是一遍又一遍重复同样的操作。C++ 提供了四种循环机制:while、do/while、for,以及基于范围的(range-based) for。
while 循环
Section titled “while 循环”只要给定表达式求值为 true,while 循环就会反复执行同一段代码。例如,下面这段非常无厘头的代码会把“这很傻。”打印 5 次:
int i { 0 };while (i < 5) { println("这很傻。"); ++i;}关键字 break 可以在循环内部使用,用来立刻跳出循环,并从循环后面的第一行代码继续执行。关键字 continue 则会让程序直接回到循环顶部,再次检查 while 条件。不过,在循环中频繁使用 continue 往往会让执行流程变得跳来跳去,因此通常被认为风格不佳,使用时要谨慎。
do/while 循环
Section titled “do/while 循环”C++ 还提供了 while 的一个变体,叫做 do/while。它和 while 的工作方式类似,区别在于:先执行代码块,再在末尾检查是否继续。因此,当你希望某段代码至少执行一次,并且可能根据条件继续执行多次时,这种循环就很合适。下面的例子即使最终条件为假,也仍然会把“这很傻。”打印一次:
int i { 100 };do { println("这很傻。"); ++i;} while (i < 5);for 循环
Section titled “for 循环”for 循环提供了另一种循环语法。任何 for 循环原则上都能改写成 while,反过来也一样。不过,for 的语法通常更方便,因为它把循环的起始表达式、终止条件,以及每次迭代结束后要执行的语句都放在同一行里。在下面的代码中,i 先被初始化为 0;只要 i 小于 5,循环就会继续;每轮结束时,i 都会加 1。这和前面的 while 例子做的是同一件事,但通常更易读,因为起始值、结束条件和迭代动作都集中写在了一起。
for (int i { 0 }; i < 5; ++i) { println("这很傻。");}基于范围的 for 循环
Section titled “基于范围的 for 循环”基于范围的 for 循环是第四种循环机制。它可以非常方便地遍历容器中的元素。这种循环适用于 C 风格数组、初始化列表(本章稍后会讲),以及任何提供 begin() / end() 并返回迭代器的类型(见第 17 章),例如 std::array、vector,以及第 18 章 中介绍的其他所有标准库容器。
下面这个例子先定义了一个包含 4 个整数的 array。随后,基于范围的 for 循环会遍历这个 array 中每个元素的副本,并依次打印出来。如果你想遍历元素本身、而不是副本,那么应当像本章后面会讲到的那样,使用引用变量。
array arr { 1, 2, 3, 4 };for (int i : arr) { println("{}", i); }基于范围的 for 循环的初始化器
Section titled “基于范围的 for 循环的初始化器”和 if、switch 一样,基于范围的 for 循环也支持初始化器,语法如下:
for (<初始化器>; <区间声明> : <区间表达式>) {<主体> }在 <初始化器> 中引入的变量,只在 <区间声明>、<区间表达式> 以及 <主体> 中可见;离开这个基于范围的 for 后,它们就不再可用。例如:
for (array arr { 1, 2, 3, 4 }; int i : arr) { println("{}", i); }初始化列表定义在 <initializer_list> 中,它让编写“可接收可变数量参数”的函数变得更容易。std::initializer_list 本身是一个类模板,因此你需要像为 vector 指定元素类型那样,在尖括号里写明列表元素的类型。下面的例子展示了初始化列表的基本用法:
import std;using namespace std;
int sum(initializer_list<int> values){ int total { 0 }; for (int value : values) { total += value; } return total;}由于 sum() 接收的是一个整数初始化列表,因此你可以直接用“花括号初始化器”把一组整数传给它。函数体内部使用基于范围的 for 循环把它们累加起来。这个函数可以这样使用:
int a { sum({ 1, 2, 3 }) };int b { sum({ 10, 20, 30, 40, 50, 60 }) };初始化列表是类型安全的。列表中的所有元素都必须属于同一种类型。对于这里的 sum() 来说,初始化列表中的元素必须全部是整数。如果像下面这样传入一个 double,就会得到编译错误或警告,指出从 double 转成 int 需要发生窄化。
int c { sum({ 1, 2, <b>3.0</b> }) };C++ 中的字符串
Section titled “C++ 中的字符串”在 C++ 中处理字符串,大致有两种方式:
- C 风格: 把字符串表示为字符数组
- C++ 风格: 用一种更易用、更安全的字符串类型来封装 C 风格表示
第 2 章会详细讨论字符串。此刻你只需要知道:C++ 的 std::string 类型定义在 <string> 中,而且你几乎可以像使用基础类型一样自然地使用它。下面这个例子展示了 string 可以像字符数组那样被访问:
string myString { "Hello, World" };println("myString 的值是 {}", myString);println("第二个字母是 {}", myString[1]);C++ 作为面向对象语言
Section titled “C++ 作为面向对象语言”如果你是一名 C 程序员,那么到目前为止,本章介绍的很多功能看起来可能都像是对 C 语言的方便增强。正如 C++ 这个名字所暗示的那样,在很多方面它确实像是“更好的 C”。但这种看法忽略了一个关键事实:和 C 不同,C++ 是一门面向对象语言。
面向对象编程(OOP)是一种不同的、也可以说更自然的编程方式。如果你习惯了 C、Pascal 这类过程式语言,也不用担心。第 5 章“用类进行设计”会系统介绍把思维方式切换到面向对象范式所需的背景知识。如果你已经熟悉 OOP 理论,那么本节剩余部分会帮助你快速掌握——或者回顾——C++ 中最基础的对象语法。
类(class) 用来定义对象具备哪些特征。在 C++ 中,类通常会在模块接口文件(.cppm)中定义并导出;其定义既可以直接写在同一个模块接口文件中,也可以写在对应的模块实现文件(.cpp)中。第 11 章会深入讨论模块。
下面的示例展示了一个“机票类”的基本定义。这个类可以根据航班里程数,以及顾客是否属于 Elite Super Rewards 计划会员,来计算机票价格。
类定义首先声明类名。接着,在一对大括号中声明类的数据成员(data members,也就是属性) 和成员函数(member functions,也就是行为)。每个数据成员和成员函数都对应一个访问级别:public、protected 或 private。这些标签的出现顺序不限,也可以重复书写。public 成员可以从类外部访问;private 成员则不能从类外直接访问。protected 成员则可以被派生类访问,这会在第 10 章 的继承部分详细说明。通常建议把所有数据成员都设为 private,然后在需要时通过 public 或 protected 的 getter 读取数据,通过 public 或 protected 的 setter 修改数据。这样做的好处是:即使你以后改变了内部数据表示方式,也仍然可以保持外部 public / protected 接口不变。
请记住:在编写模块接口文件时,不要忘了用 export module 声明说明你正在定义哪个模块,也不要忘了显式导出你希望提供给模块使用者的类型。
export module airline_ticket;
import std;
export class AirlineTicket{ public: AirlineTicket(); ~AirlineTicket();
double calculatePriceInDollars();
std::string getPassengerName(); void setPassengerName(std::string name);
int getNumberOfMiles(); void setNumberOfMiles(int miles);
bool hasEliteSuperRewardsStatus(); void setHasEliteSuperRewardsStatus(bool status); private: std::string m_passengerName; int m_numberOfMiles; bool m_hasEliteSuperRewardsStatus;};本书遵循一种命名约定:类中的每个数据成员都以前缀 m_ 开头,例如 m_passengerName。
与类同名、且没有返回类型的成员函数,叫做构造函数(constructor)。创建该类对象时,它会被自动调用。以波浪号 ~ 开头、后面跟类名的成员函数,则叫做析构函数(destructor)。对象销毁时,它会被自动调用。
在这个例子中,.cppm 模块接口文件定义了类,而成员函数的实现则放在 .cpp 模块实现文件中。这个源文件以如下模块声明开头,告诉编译器:这是 airline_ticket 模块的实现文件:
module airline_ticket;初始化类的数据成员有多种方式。其中一种是使用构造函数初始化器(constructor initializer),也就是在构造函数头后面加一个冒号,然后依次初始化成员。下面就是带构造函数初始化器的 AirlineTicket 构造函数:
AirlineTicket::AirlineTicket() : m_passengerName { "Unknown Passenger" } , m_numberOfMiles { 0 } , m_hasEliteSuperRewardsStatus { false }{}另一种做法,是把初始化逻辑直接写在构造函数体内部,例如:
AirlineTicket::AirlineTicket(){ // 初始化数据成员。 m_passengerName = "Unknown Passenger"; m_numberOfMiles = 0; m_hasEliteSuperRewardsStatus = false;}不过,如果构造函数唯一做的事情只是初始化数据成员,而不包含其他逻辑,那实际上根本不必专门写这个构造函数,因为数据成员本身就可以直接在类定义内部初始化,这也叫类内初始化器(in-class initializers)。例如,你完全可以不写 AirlineTicket 构造函数,而是像下面这样在类定义里直接初始化数据成员:
private: std::string m_passengerName { "Unknown Passenger" }; int m_numberOfMiles { 0 }; bool m_hasEliteSuperRewardsStatus { false };如果你的类还需要执行其他初始化工作,例如打开文件、分配内存等,那么你仍然需要编写构造函数来处理这些事情。
下面是 AirlineTicket 类的析构函数:
AirlineTicket::~AirlineTicket(){ // 无需执行清理操作}这个析构函数什么也没做,因此在这个类里其实可以直接删掉。它放在这里的唯一目的,是让你认识析构函数的语法。只有当你确实需要做清理工作,例如关闭文件、释放内存等,析构函数才是必要的。第 8 章“深入掌握类与对象”和第 9 章 会更详细地讨论析构函数。
AirlineTicket 其余成员函数的定义如下:
double AirlineTicket::calculatePriceInDollars(){ if (hasEliteSuperRewardsStatus()) { // Elite Super Rewards 会员可以免费乘机! return 0; } // 票价等于里程数乘以 0.1。 // 现实中的航空公司大概会有更复杂的公式! return getNumberOfMiles() * 0.1;}
string AirlineTicket::getPassengerName() { return m_passengerName; }void AirlineTicket::setPassengerName(string name) { m_passengerName = name; }
int AirlineTicket::getNumberOfMiles() { return m_numberOfMiles; }void AirlineTicket::setNumberOfMiles(int miles) { m_numberOfMiles = miles; }
bool AirlineTicket::hasEliteSuperRewardsStatus(){ return m_hasEliteSuperRewardsStatus;}void AirlineTicket::setHasEliteSuperRewardsStatus(bool status){ m_hasEliteSuperRewardsStatus = status;}正如本节开头提到的,你也可以把成员函数的实现直接写在模块接口文件中。语法如下:
export class AirlineTicket{ public: double calculatePriceInDollars() { if (hasEliteSuperRewardsStatus()) { return 0; } return getNumberOfMiles() * 0.1; }
std::string getPassengerName() { return m_passengerName; } void setPassengerName(std::string name) { m_passengerName = name; }
int getNumberOfMiles() { return m_numberOfMiles; } void setNumberOfMiles(int miles) { m_numberOfMiles = miles; }
bool hasEliteSuperRewardsStatus() { return m_hasEliteSuperRewardsStatus; } void setHasEliteSuperRewardsStatus(bool status) { m_hasEliteSuperRewardsStatus = status; } private: std::string m_passengerName { "Unknown Passenger" }; int m_numberOfMiles { 0 }; bool m_hasEliteSuperRewardsStatus { false };};要使用 AirlineTicket 类,首先要导入它所在的模块:
import airline_ticket;下面这个示例程序使用了该类。它展示了一个栈上 AirlineTicket 对象的创建方式:
AirlineTicket myTicket;myTicket.setPassengerName("Sherman T. Socketwrench");myTicket.setNumberOfMiles(700);double cost { myTicket.calculatePriceInDollars() };println("这张机票的价格是 ${}", cost);AirlineTicket 这个例子让你先熟悉了创建和使用类的基本语法。当然,关于类,还有很多内容需要深入学习,这正是第 8 章、第 9 章 和第 10 章 的主题。
作为一名 C++ 程序员,你需要熟悉作用域(scope) 这个概念,它决定了某个名字在程序中的哪些位置可见。程序里的每个名字——包括变量名、函数名和类名——都处于某个作用域之中。命名空间、函数定义、由大括号包起来的代码块,以及类定义,都会引入新的作用域。在 for 循环和基于范围的 for 循环初始化语句中声明的变量,只在对应的 for 循环里可见;离开循环后,它们就不可见了。同样,在 if 或 switch 初始化器中声明的变量,也只在对应语句内部有效。当你访问某个变量、函数或类时,编译器会先从最近的外围作用域开始查找,然后再逐层向外查找,直到全局作用域(global scope)。任何不位于命名空间、函数、大括号块或类中的名字,都被视为位于全局作用域。如果连全局作用域里也找不到它,编译器就会报出未定义符号错误。
有时,某个作用域中的名字会遮蔽掉其他作用域里的同名实体。还有些时候,你想要访问的那个作用域,并不属于当前这行代码默认的名字查找路径。如果你不想依赖默认的作用域解析规则,就可以使用作用域解析运算符 ::,用一个特定作用域来限定名字。下面这个例子展示了它的用法。代码里定义了一个类 Demo,其中有一个成员函数 get();另外还有一个位于全局作用域的 get(),以及一个位于命名空间 NS 中的 get()。
class Demo{ public: int get() { return 5; }};
int get() { return 10; }
namespace NS{ int get() { return 20; }}全局作用域本身没有名字,但你仍然可以只写一个作用域解析运算符 :: 来显式访问它。不同的 get() 函数可以像下面这样调用。这个例子里的代码位于 main() 中,而 main() 永远位于全局作用域:
int main(){ Demo d; println("{}", d.get()); // 输出 5 println("{}", NS::get()); // 输出 20 println("{}", ::get()); // 输出 10 println("{}", get()); // 输出 10}如果前面那个名为 NS 的命名空间被改成了未命名命名空间(unnamed / anonymous namespace),也就是如下这种没有名字的命名空间:
namespace{ int get() { return 20; }}那么下面这行代码就会因为名字解析不明确而编译失败,因为此时全局作用域里有一个 get(),未命名命名空间里又有另一个 get():
println("{}", get());如果你在 main() 前面再加上下面这个 using 指令,也会出现同样的错误:
using namespace NS;在 C++11 之前,类型的初始化方式并不统一。例如,看看下面这两个“圆”的定义:一个写成结构体,一个写成类:
struct CircleStruct{ int x, y; double radius;};
class CircleClass{ public: CircleClass(int x, int y, double radius) : m_x { x }, m_y { y }, m_radius { radius } {} private: int m_x, m_y; double m_radius;};在 C++11 之前,CircleStruct 类型变量和 CircleClass 类型变量的初始化写法看起来并不一样:
CircleStruct myCircle1 = { 10, 10, 2.5 };CircleClass myCircle2(10, 10, 2.5);对于结构体版本,你可以使用 {…} 语法;但对于类版本,你则需要使用函数式写法 (…) 来调用构造函数。
从 C++11 开始,初始化语法变得统一得多,你可以更一致地用 {…} 来初始化对象:
CircleStruct myCircle3 = { 10, 10, 2.5 };CircleClass myCircle4 = { 10, 10, 2.5 };myCircle4 的定义会自动调用 CircleClass 的构造函数。甚至连等号也可以省略,因此下面这些写法是等价的:
CircleStruct myCircle5 { 10, 10, 2.5 };CircleClass myCircle6 { 10, 10, 2.5 };再举一个例子。在本章前面的“结构体”部分中,Employee 结构体是这样初始化的:
Employee anEmployee;anEmployee.firstInitial = 'J';anEmployee.lastInitial = 'D';anEmployee.employeeNumber = 42;anEmployee.salary = 80'000;使用统一初始化后,它可以改写成:
Employee anEmployee { 'J', 'D', 42, 80'000 };统一初始化并不局限于结构体和类。你几乎可以用它来初始化 C++ 中的任何东西。例如,下面的代码会把 4 个变量都初始化为值 3:
int a = 3;int b(3);int c = { 3 }; // 统一初始化int d { 3 }; // 统一初始化统一初始化还可以用来做零初始化;你只需写一对空花括号即可:
int e { }; // 统一初始化,e 会被初始化为 0这种语法也适用于结构体。如果你像下面这样创建一个 Employee 结构体实例,那么它的数据成员会被默认初始化;而对 char、int 这类基础类型来说,这通常意味着它们会带有内存中残留的随机数据:
Employee anEmployee;但如果你像下面这样创建实例,那么所有数据成员都会被零初始化:
Employee anEmployee { };统一初始化的一大好处,是它可以防止窄化(narrowing)。当你使用旧式赋值语法初始化变量时,C++ 可能会隐式执行窄化转换,例如:
int main(){ int x = 3.14;}在 main() 中这条语句里,C++ 会先把 3.14 截断成 3,然后再赋给 x。有些编译器可能会针对这种窄化发出警告,也有些不会。无论如何,窄化转换都不该被忽视,因为它们很可能带来隐蔽或不那么隐蔽的 bug。使用统一初始化后,如果你的编译器完整遵循 C++11 标准,那么给 x 赋值的这行代码必须报编译错误:
int x { 3.14 }; // 因为发生窄化而报错如果你确实需要窄化转换,我建议使用 Guidelines Support Library (GSL) 中提供的 gsl::narrow_cast() 函数。
统一初始化还可以用在构造函数初始化器中,用来初始化类成员里的数组。
class MyClass{ public: MyClass() : m_array { 0, 1, 2, 3 } { } private: int m_array[4];};统一初始化也可以和标准库容器一起使用,例如本章前面已经展示过的 std::vector。
指定初始化器
Section titled “指定初始化器”指定初始化器(designated initializers) 可以通过成员名来初始化聚合类型的数据成员。聚合类型(aggregate type) 指的是数组对象,或者满足以下限制的结构体 / 类对象:只有 public 数据成员,没有用户声明的或继承来的构造函数,没有 virtual 函数(见第 10 章),并且没有 virtual、private 或 protected 基类(也见第 10 章)。指定初始化器以一个点号开头,后面跟数据成员的名字。它们的书写顺序必须与数据成员的声明顺序一致。指定初始化器和非指定初始化器不能混用。那些没有被显式指定初始化的数据成员,会使用自己的默认值来初始化,这意味着:
- 带有类内初始化器的数据成员会得到那个类内初始值。
- 没有类内初始化器的数据成员会被零初始化。
来看一个稍作修改的 Employee 结构。这一次,salary 数据成员有一个默认值 75'000。
struct Employee { char firstInitial; char lastInitial; int employeeNumber; int salary { 75'000 };};在本章前面,这样的 Employee 结构体是通过统一初始化语法来初始化的:
Employee anEmployee { 'J', 'D', 42, 80'000 };使用指定初始化器后,可以写成下面这样:
Employee anEmployee { .firstInitial = 'J', .lastInitial = 'D', .employeeNumber = 42, .salary = 80'000};这种写法的好处是,相比统一初始化语法,它更容易一眼看出每个初始化器到底对应哪个字段。
使用指定初始化器时,如果你对某些成员的默认值已经满意,就可以直接跳过它们。例如,在创建员工对象时,你可以不显式初始化 employeeNumber;由于它没有类内初始化器,因此它会被零初始化:
Employee anEmployee { .firstInitial = 'J', .lastInitial = 'D', .salary = 80'000};而如果使用统一初始化语法,这种“跳过中间成员”的写法就做不到了;你必须显式给员工编号写出一个 0:
Employee anEmployee { 'J', 'D', 0, 80'000 };如果你像下面这样跳过 salary 的初始化,那么 salary 就会得到它的默认值,也就是类内初始化时写下的 75'000:
Employee anEmployee { .firstInitial = 'J', .lastInitial = 'D'};指定初始化器的最后一个好处是:当你以后给这个数据结构新增成员时,现有使用指定初始化器的代码往往仍然可以继续工作。新增的数据成员只会使用自己的默认值进行初始化。
指针和动态内存
Section titled “指针和动态内存”动态内存让你能够编写那些“数据大小在编译时并不固定”的程序。几乎所有稍微复杂一点的程序,都会以某种形式使用动态内存。
栈和自由存储
Section titled “栈和自由存储”C++ 应用程序里的内存大致可以分成两部分:栈(stack) 和 自由存储(free store)。想象栈的一个办法,是把它看成一叠纸牌。最上面那张牌代表程序当前所在的作用域,通常也就是当前正在执行的函数。当前函数里声明的所有变量,都会占用最顶层那个栈帧(也就是牌堆顶部那张牌)中的内存。如果当前函数——假设叫做 foo()——又调用了另一个函数 bar(),那么牌堆上就会再压上一张新牌,让 bar() 拥有自己的栈帧(stack frame)。从 foo() 传给 bar() 的参数,也会从 foo() 的栈帧复制到 bar() 的栈帧中。图 1.2 展示了一个假想函数 foo() 在执行时的栈布局,其中它声明了两个整数值。
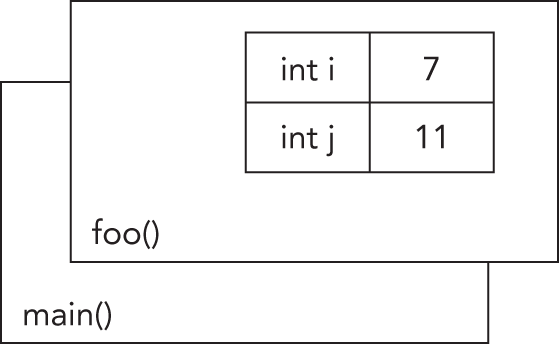
[^FIGURE 1.2]
栈帧非常有用,因为它为每个函数都提供了一块彼此独立的内存工作区。如果某个变量是在 foo() 的栈帧中声明的,那么调用 bar() 不会改变它,除非你明确把它传过去。另外,当 foo() 执行结束后,它的栈帧也会随之消失,函数内部声明的所有变量就都不再占用内存。那些分配在栈上的变量不需要程序员手动释放;这一步会自动完成。
自由存储(free store) 则是一片完全独立于当前函数和栈帧的内存区域。如果你希望某个变量在创建它的函数结束之后依然存在,就可以把它放在自由存储上。自由存储的结构不像栈那样整齐,你可以把它想象成一大堆内存块。程序可以在任何时刻往里面再申请新的内存,也可以修改已经存在的数据。问题在于:凡是你在自由存储上分配的内存,都必须自己确保之后被释放(delete)。除非你使用智能指针,否则这件事不会自动发生;而智能指针会在第 7 章“内存管理”中详细讲解。
这里之所以介绍指针,是因为你一定会遇到它们,尤其是在遗留代码库里。不过在新代码中,只有在“不涉及所有权”的情况下,才应当使用这种原始 / 裸指针;否则,你应该使用第 7 章中介绍的智能指针。
只要显式为某个对象分配内存,你就可以把它放到自由存储上。例如,如果你想把一个整数放到自由存储上,首先需要声明一个指针(pointer):
int* myIntegerPointer;int 后面的 * 表示:你声明的这个变量并不是一个整数本身,而是“指向某块整数内存”的东西。你可以把指针想象成一个箭头,它指向动态分配的自由存储内存。此时它还没有指向任何具体对象,因为你还没有给它赋值;换句话说,它是一个未初始化变量(uninitialized variable)。未初始化变量都应该尽量避免,未初始化指针尤其危险,因为它们会指向内存中的某个随机位置。使用这样的指针,程序极有可能直接崩溃。这就是为什么你几乎总应当在声明指针的同时就初始化它!如果你暂时还不想分配内存,可以先把它初始化为空指针 nullptr(关于它的更多内容,见后面的“空指针常量”一节):
int* myIntegerPointer { nullptr };空指针是一个特殊的默认值,任何有效指针都不会拥有这个值;当它出现在布尔表达式中时,会被视为 false。例如:
if (!myIntegerPointer) { /* myIntegerPointer 是空指针。 */ }你可以用 new 运算符来分配内存:
myIntegerPointer = new int;在这个例子中,指针指向的是单个整数对象的地址。要访问这个值,你需要对指针进行解引用(dereference)。可以把解引用理解成:顺着指针这支箭头,找到自由存储上真正的那个对象。要给这个新分配出来的整数赋值,可以这样写:
*myIntegerPointer = 8;注意,这和“把 myIntegerPointer 自身设为 8”完全不是一回事。你并没有修改指针本身,而是在修改它所指向的内存内容。如果你真的把指针值改成 8,那么它就会去指向地址 8,而那几乎肯定是一块毫无意义的垃圾地址,最终大概率会让你的程序崩溃。
当你用完这块动态分配的内存之后,就必须使用 delete 运算符把它释放掉。为了防止释放后继续误用这个指针,通常建议立刻把它重新设为 nullptr:
delete myIntegerPointer;myIntegerPointer = nullptr;指针在被解引用之前,必须是有效的。解引用空指针或未初始化指针都会导致未定义行为。程序可能直接崩溃,也可能继续运行,但开始给出各种奇怪结果。
指针并不一定总是指向自由存储内存。你也可以声明一个指向栈上变量的指针,甚至是一个“指向另一个指针的指针”。要获得某个变量的地址,可以使用 &(取地址)运算符:
int i { 8 };int* myIntegerPointer { &i }; // 指向值为 8 的变量C++ 还为“指向结构体或类的指针”提供了一种专门的语法。从技术上讲,如果你有一个指向结构体或类的指针,那么可以先用 * 对它解引用,再像平时那样用 . 语法访问其字段,如下面代码所示。这个例子也演示了如何动态分配和释放一个 Employee 实例。
Employee* anEmployee { new Employee { 'J', 'D', 42, 80'000 } };println("{}", (*anEmployee).salary);delete anEmployee; anEmployee = nullptr;不过这种写法有点别扭。->(箭头)运算符可以把“解引用 + 访问字段”这两步合并成一步。下面这行语句和前面的 println() 等价,但更易读:
println("{}", anEmployee->salary);还记得本章前面提到过的短路逻辑吗?它和指针搭配使用时非常有用,因为可以避免误用无效指针。比如:
bool isValidSalary { anEmployee && anEmployee->salary> 0 };或者写得更啰嗦一点:
bool isValidSalary { anEmployee != nullptr && anEmployee->salary> 0 };只有当 anEmployee 是一个有效指针时,表达式才会去解引用它并读取工资。如果它是空指针,那么逻辑运算就会发生短路,anEmployee 不会被解引用。
动态分配的数组
Section titled “动态分配的数组”自由存储还可以用来动态分配数组。你可以使用 new[] 运算符为数组申请内存。
int arraySize { 8 };int* myVariableSizedArray { new int[arraySize] };这会分配足够容纳 arraySize 个整数的内存。图 1.3 展示了执行完这段代码后,栈与自由存储的布局。正如你看到的,指针变量本身依然位于栈上,而动态创建出来的数组则位于自由存储中。
既然内存已经分配好了,你就可以像使用普通栈数组那样使用 myVariableSizedArray:
myVariableSizedArray[3] = 2;当代码用完这个数组之后,就应该把它从自由存储中释放掉,以便这块内存能被其他对象再次使用。在 C++ 中,这需要使用 delete[] 运算符:
delete[] myVariableSizedArray;myVariableSizedArray = nullptr;delete 后面的方括号表示:你正在删除的是一个数组!
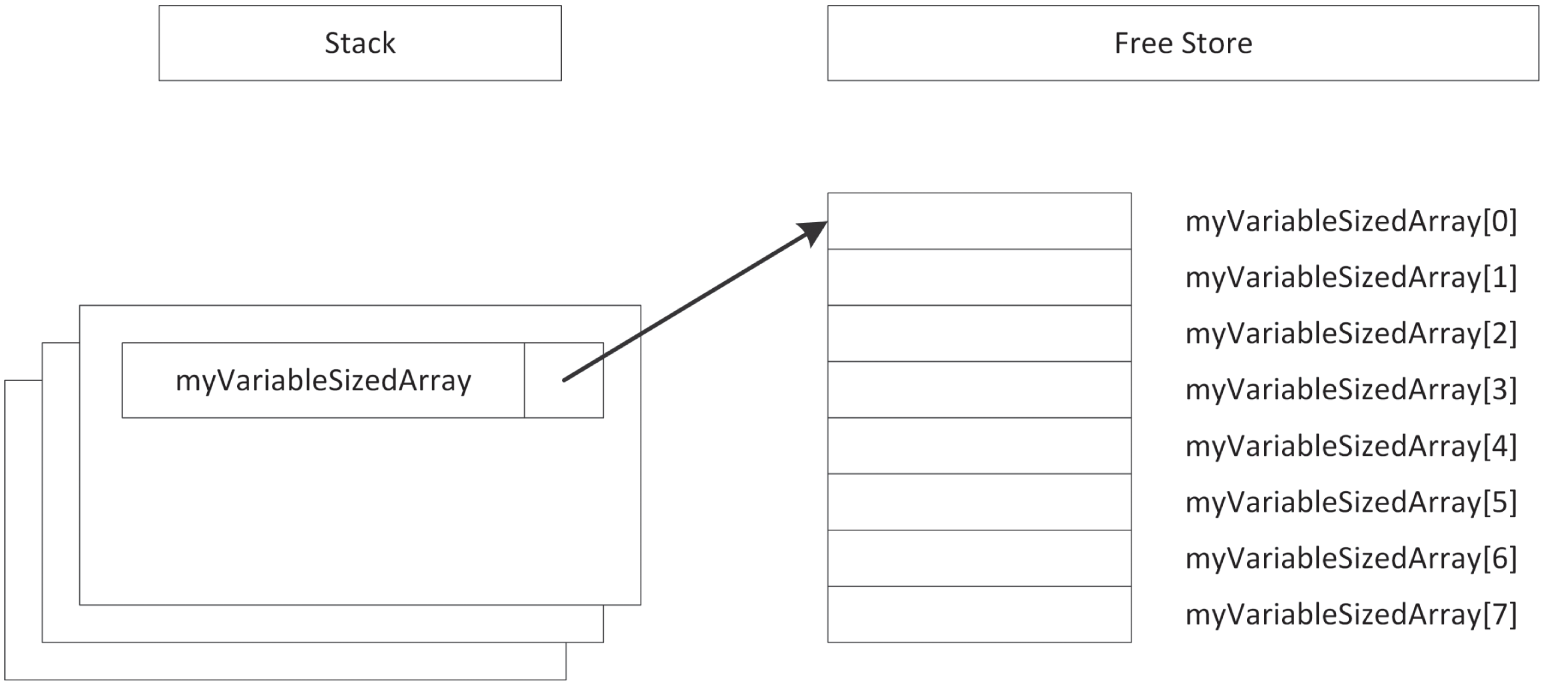
[^FIGURE 1.3]
为了防止内存泄漏,每一次 new 调用都应该配对一次 delete,每一次 new[] 调用都应该配对一次 delete[]。如果忘记调用 delete / delete[],或者配对关系写错,就会导致内存泄漏,甚至更糟的后果。这些复杂问题都会在第 7 章 中详细讨论。
在 C++11 之前,空指针通常使用定义在 <cstddef> 中的常量 NULL 表示。你不能通过 import 声明获得这个常量;相反,必须使用 #include <cstddef>。问题在于,NULL 本质上只是常量 0,这可能带来麻烦。例如:
#include <cstddef>
void func(int i) { /* … */ }
int main(){ func(NULL);}这段代码定义了一个只接收单个整数参数的函数 func()。main() 使用参数 NULL 去调用它,而这个参数本来是想表达“空指针常量”。但由于 NULL 其实并不是一个真正的指针,而只是整数 0,因此它会匹配到 func(int)。这很可能不是你原本想要的行为,所以有些编译器甚至会对此发出警告。
这个问题可以通过真正的空指针常量 nullptr 来避免。下面这段代码使用了真正的空指针常量,因此会触发编译错误——因为这里根本没有接收指针的 func() 重载:
func(nullptr);const 的使用
Section titled “const 的使用”关键字 const 在 C++ 中有几种不同的用法。它们彼此相关,但又存在一些细微差别。const 之所以经常成为面试题,就是因为这些微妙之处。
从根本上说,const 就是 “constant” 的缩写,用来表示某个东西应当保持不变。编译器会通过把任何修改尝试标记为错误来强制执行这一点。除此之外,在开启优化时,编译器还可以利用这些信息生成更高效的代码。
const 作为类型的限定符
Section titled “const 作为类型的限定符”如果你觉得 const 显然和“常量”有关,那你已经抓住了它最常见的一个用途。在 C 中,程序员经常使用预处理器 #define(见第 11 章)为那些在程序运行期间不会改变的值定义符号名,例如版本号。而在 C++ 中,更推荐尽量避免 #define,转而用 const 来定义常量。用 const 定义常量的写法和定义普通变量几乎一样,只是编译器会保证代码无法修改这个值。下面是一些例子:
const int versionNumberMajor { 2 };const int versionNumberMinor { 1 };const std::string productName { "Super Hyper Net Modulator" };const double PI { 3.141592653589793238462 };你几乎可以把任何变量都标记为 const,包括全局变量和类的数据成员。
const 与指针
Section titled “const 与指针”当变量通过指针引入一层或多层间接访问时,const 的使用就会变得更微妙。先看看下面这段代码:
int* ip;ip = new int[10];ip[4] = 5;假设你现在决定给 ip 加上 const。先别管这样做到底有没有意义,先想清楚它到底应该限制谁:你是想防止 ip 这个变量本身被修改,还是想防止它所指向的值被修改?也就是说,你到底是想禁止第二行,还是第三行?
如果你是想防止“被指向的值”被修改(也就是禁止第三行那种写法),可以像下面这样把 const 加到 ip 的声明里:
const int* ip;ip = new int[10];ip[4] = 5; // 无法编译!这样一来,你就不能修改 ip 所指向的值了。还有一种语义完全等价的写法:
int const* ip;ip = new int[10];ip[4] = 5; // 无法编译!把 const 放在 int 前面还是后面,在这里没有功能上的区别。
如果你真正想标记为 const 的是 ip 本身(而不是它所指向的值),那么需要写成这样:
int* const ip { nullptr };ip = new int[10]; // 无法编译!ip[4] = 5; // 错误:解引用了空指针由于现在 ip 自身不能再被修改,所以编译器要求你在声明时就初始化它。这个初值可以是前面示例中的 nullptr,也可以是一块新分配的内存,例如:
int* const ip { new int[10] };ip[4] = 5;你还可以让“指针本身”和“它所指向的值”同时都是 const,写法如下:
int const* const ip { nullptr };这是一个替代但等效的语法:
const int* const ip { nullptr };尽管这种语法看上去有点绕,但其实有一个很简单的规则:const 作用于它左边紧挨着的东西。再看这行代码:
int const* const ip { nullptr };从左往右看,第一个 const 紧挨着 int,因此它作用于 ip 指向的那个 int,也就是说:你不能修改 ip 所指向的值。第二个 const 紧挨着 *,因此它作用于“指向 int 的那个指针”,也就是变量 ip 本身。这表示:你不能修改 ip 这个指针本身。
这条规则之所以会让人困惑,是因为它有一个例外:第一个 const 也可以写在类型名前面,就像这样:
const int* const ip { nullptr };这种“特殊写法”其实反而更常见。
这套规则可以一路扩展到任意多层间接访问,例如:
const int * const * const * const ip { nullptr };const 保护参数
Section titled “const 保护参数”在 C++ 中,你可以把一个非 const 对象“当作 const 对象来看待”。为什么要这么做?因为这样可以在一定程度上防止其他代码意外修改它。如果你在调用某个同事编写的函数,而且你希望确保该函数不会改动你传入参数的值,就可以要求那个函数把参数声明成 const。这样一来,只要函数试图修改这个参数,对应代码就无法通过编译。
在下面的代码里,调用 mysteryFunction() 时,string* 会自动转换为 const string*。如果 mysteryFunction() 的作者试图修改传进来的字符串,代码就无法编译。当然,也不是说完全没有办法绕开这个限制;但要绕过它,必须进行明确而刻意的操作。C++ 能防止的是“无意中”修改 const 对象。
void mysteryFunction(const string* someString){ *someString = "Test"; // 无法编译}
int main(){ string myString { "The string" }; mysteryFunction(&myString); // &myString 的类型是 string*}你也可以把 const 用在基础类型参数上,以防止在函数体内部不小心修改它们。例如,下面这个函数的整数参数就是 const。在函数体内部,你不能修改 param;如果试图修改,编译器会报错。
void func(const int param) { /* 不允许修改 param…… */ }const 成员函数
Section titled “const 成员函数”const 的另一个常见用途,是把类成员函数标记为 const,从而表示它们不会修改对象的数据成员。前面介绍的 AirlineTicket 类,就可以把所有只读成员函数都改成 const。这里的 const 必须同时出现在成员函数声明和定义中。如果某个 const 成员函数试图修改 AirlineTicket 的任意数据成员,编译器就会报错。
export class AirlineTicket{ public: double calculatePriceInDollars() const;
std::string getPassengerName() const; void setPassengerName(std::string name);
int getNumberOfMiles() const; void setNumberOfMiles(int miles);
bool hasEliteSuperRewardsStatus() const; void setHasEliteSuperRewardsStatus(bool status); private: std::string m_passengerName { "Unknown Passenger" }; int m_numberOfMiles { 0 }; bool m_hasEliteSuperRewardsStatus { false };};
std::string AirlineTicket::getPassengerName() const{ return m_passengerName;}// 其他成员函数省略……专业的 C++ 代码——包括本书中的大量代码——都会大量使用引用(reference)。在 C++ 中,引用就是另一个变量的一个别名(alias)。对引用做出的所有修改,都会直接作用到它所引用的那个变量上。你可以把引用看成一种“隐式指针”,这样你就不用自己显式取地址、再手动解引用;你也可以干脆把它理解为原变量的另一个名字。你可以创建独立的引用变量,在类中声明引用数据成员,把引用作为函数参数传入,甚至从函数返回引用。
引用变量在创建时就必须立即初始化,例如:
int x { 3 };int& xRef { x };把 & 附在类型后面,表示这个变量是一个引用。它在使用方式上和普通变量几乎一样,但在底层,你可以把它理解为和原变量绑定在一起。变量 x 和引用变量 xRef 实际上都对应同一个值;也就是说,xRef 只是 x 的另一个名字。只要通过其中任意一个修改了值,另一个看到的也会是同样的变化。例如,下面的代码会通过 xRef 把 x 改成 10:
xRef = 10;你不能在类定义之外声明一个“尚未初始化”的引用变量。
int& emptyRef; // 无法编译!引用变量在创建时必须始终初始化。
引用永远绑定到它初始化时绑定的那个变量;一旦创建完成,这种绑定关系就不能再改变。对 C++ 初学者来说,这里的语法有时会让人误会。如果你在声明引用时用一个变量来初始化它,那么这个引用就会绑定到那个变量上。但如果在此之后你把另一个变量赋给这个引用,并不会让引用改绑到新变量上;真正发生的事情,是“原来被引用的那个变量”会被赋成新变量的值。看下面这个例子:
int x { 3 }, y { 4 };int& xRef { x };xRef = y; // 把 x 的值改成 4,并不会让 xRef 改为引用 y。你可能会试图通过取 y 的地址来绕过这一点:
xRef = &y; // 无法编译!这段代码编译不过。因为 y 的地址是一个指针,而 xRef 被声明为“对 int 的引用”,并不是“对指针的引用”。
有些程序员甚至会进一步尝试挑战引用的语义:如果把一个引用赋给另一个引用,会不会让第一个引用改为引用第二个引用所绑定的变量呢?你可能会想写出下面这种代码:
int x { 3 }, z { 5 };int& xRef { x };int& zRef { z };zRef = xRef; // 赋的是值,不是引用关系最后那条语句并不会改变 zRef 的绑定对象。相反,它只是把 z 的值设成了 3,因为 xRef 绑定的是 x,而 x 的值正好是 3。
一旦引用被初始化并绑定到某个特定变量,你就不能再让它改为引用另一个变量;你唯一能改的,只是它所引用的那个变量的值。
const 引用
Section titled “const 引用”把 const 用在引用上,通常要比把 const 用在指针上简单,原因有两个。首先,引用在“重新绑定”这件事上天生就是不可变的——你不能让它改为引用别的对象,所以不需要再专门用 const 去约束这一点。其次,你不能创建“对引用的引用”,因此引用通常只有一层间接性。想要得到多层间接访问,唯一办法是创建“对指针的引用”。
因此,当 C++ 程序员说“对 const 的引用”时,他们指的是像下面这样的东西:
int z;const int& zRef { z };zRef = 4; // 无法编译在这里,把 const 用到 int& 上之后,就禁止了通过 zRef 进行赋值。和指针的写法类似,const int& zRef 与 int const& zRef 是等价的。不过要注意,这并不意味着 z 自己也变成了不可修改;你依然可以绕过这个引用,直接修改 z 本身。
你不能让一个普通引用去绑定一个匿名值,例如整数字面量;除非这个引用是“对 const 的引用”。下面这个例子里,unnamedRef1 之所以编译不过,是因为它属于“对非常量的引用”,却想去绑定字面量常量 5。这会暗示你可以去修改一个常量,而这显然不合理。unnamedRef2 则可以成立,因为它是对 const 的引用,因此你也就无法写出 unnamedRef2 = 7 这样的代码。
int& unnamedRef1 { 5 }; // 无法编译const int& unnamedRef2 { 5 }; // 正常工作这一点对临时对象同样成立。你不能创建“对临时对象的非 const 引用”,但“对 const 的引用”则没问题。例如,假设你有下面这个返回 std::string 对象的函数:
string getString() { return "Hello world!"; }你可以创建一个“对 getString() 返回结果的 const 引用”,而这个引用会把那个临时 std::string 对象的生命周期延长到引用离开作用域为止:
string& string1 { getString() }; // 无法编译const string& string2 { getString() }; // 正常工作对指针的引用和对引用的指针
Section titled “对指针的引用和对引用的指针”你可以为任何类型创建引用,包括指针类型。下面是一个“对 int 指针的引用”示例:
int* intP { nullptr };int*& ptrRef { intP };ptrRef = new int;*ptrRef = 5;delete ptrRef; ptrRef = nullptr;这个语法看起来有点怪,因为 * 和 & 紧挨着出现了。不过语义其实很简单:ptrRef 是 intP 的引用,而 intP 本身又是一个指向 int 的指针。因此,修改 ptrRef 实际上就是在修改 intP。这种“对指针的引用”并不常见,但偶尔会非常有用;本章后面的“引用参数”一节就会看到它的用途。
对引用取地址,得到的结果和“对它所引用的变量取地址”是一样的。例如:
int x { 3 };int& xRef { x };int* xPtr { &xRef }; // 对引用取地址,得到的是指向底层值的指针。*xPtr = 100;这段代码通过获取 x 的引用地址,让 xPtr 指向了 x。随后给 *xPtr 赋值 100,也就把 x 的值改成了 100。由于类型不匹配,xPtr == xRef 这种比较无法编译:xPtr 是“指向 int 的指针”,而 xRef 是“对 int 的引用”。不过,xPtr == &xRef 和 xPtr == &x 都可以正常编译,而且结果都会是 true。
最后还要注意:你不能声明“对引用的引用”或者“对引用的指针”。例如,int& & 和 int&* 都是不允许的。
结构化绑定和引用
Section titled “结构化绑定和引用”本章前面介绍过结构化绑定,其中一个例子是:
pair myPair { "你好", 5 };auto [theString, theInt] { myPair }; // 使用结构化绑定分解既然你现在已经理解了引用和 const 变量,就该知道:它们同样可以和结构化绑定结合起来使用。例如:
auto& [theString, theInt] { myPair }; // 分解为对非常量的引用const auto& [theString, theInt] { myPair }; // 分解为对常量的引用引用数据成员
Section titled “引用数据成员”类的数据成员也可以是引用。正如前面说过的,引用必须绑定到某个已有变量上,而且一旦绑定就不能改绑。因此,引用型数据成员不能在构造函数体内部再去初始化,而必须在构造函数初始化器(constructor initializer) 中完成初始化。从语法上看,构造函数初始化器紧跟在构造函数头之后,并以一个冒号开始。下面是一个简短例子;更完整的讨论见第 9 章。
class MyClass{ public: MyClass(int& ref) : m_ref { ref } { /* 构造函数体 */ } private: int& m_ref;};引用在创建时必须始终初始化。通常,引用会在声明时创建并同时初始化;而对于引用型数据成员,这个初始化工作则必须放在所属类的构造函数初始化器中完成。
在实际 C++ 代码中,独立的引用变量和引用型数据成员并不算常见。引用最常见的用途,是作为函数参数。默认的参数传递语义是按值传递:函数接收到的是参数的副本,因此即使函数内部修改了参数,原始实参也不会受影响。在 C 中,人们经常通过“指向栈变量的指针”来让函数修改其他栈帧中的变量。通过解引用那个指针,函数就可以间接改动原变量。问题是:这种方式会把指针语法的复杂度带进原本很简单的任务中。
C++ 提供了一种更好的机制,叫做按引用传递(pass-by-reference):函数参数是引用,而不是指针。下面给出两个 addOne() 版本。第一个对传入变量没有真实影响,因为它是按值传递,函数拿到的是副本;第二个则使用引用,因此会直接修改原始变量。
void addOne(int i){ i++; // 实际上没有影响,因为这里只是原始值的一个副本}
void addOne(int& i){ i++; // 会真正修改原始变量}调用这个“按引用接收整数”的 addOne() 时,语法和调用一个普通接收整数的函数并没有区别。
int myInt { 7 };addOne(myInt);下面再看一个按引用传递非常合适的例子:一个简单的交换函数,用来交换两个 int 的值:
void swap(int& first, int& second){ int temp { first }; first = second; second = temp;}你可以这样调用它:
int x { 5 }, y { 6 };swap(x, y);当你用 x 和 y 调用 swap() 时,参数 first 会绑定到 x,参数 second 会绑定到 y。因此,当 swap() 修改 first 和 second 时,真正被改动的就是 x 和 y。
一个常见场景是:你手上拿着的是一个指针,但又需要把它传给一个接收引用的函数。这时可以通过解引用指针,把它“变成”一个可用于初始化引用参数的对象。例如,swap() 可以这样调用:
int x { 5 }, y { 6 };int* xp { &x }, *yp { &y };swap(*xp, *yp);最后,如果某个函数需要“返回一个复制代价很高的类对象”,你可能会在旧代码里看到这样一种风格:函数不直接返回对象,而是接收一个“对非 const 的引用”作为输出参数,然后在函数内部去修改它。过去很多人认为这是避免返回对象时产生复制开销的推荐写法。然而,即使在当年,编译器通常也已经足够聪明,能够消除很多冗余复制。因此,我们可以给出下面这条规则:
从函数返回对象时,推荐按值返回,而不是通过输出参数返回。
传递“对 const 的引用”
Section titled “传递“对 const 的引用””把参数声明成“对 const 的引用”,其主要价值在于效率。按值传递给函数时,系统必须创建一个完整副本;而按引用传递时,本质上只是把对原对象的间接访问传进函数,因此无需复制。通过传递“对 const 的引用”,你可以同时获得两方面好处:既避免了复制,又保证了原对象不会被修改。对于对象类型来说,这一点尤其重要,因为对象可能很大,而复制它们不仅成本高,还可能带来不希望出现的副作用。下面这个例子演示了如何把 std::string 作为“对 const 的引用”传给函数:
import std;using namespace std;void printString(const string& myString) { println("{}", myString); }
int main(){ string someString { "Hello World" }; printString(someString); printString("Hello World"); // 传入字面量也没问题。}按引用传递 vs. 按值传递
Section titled “按引用传递 vs. 按值传递”当你希望函数修改参数,并且这些修改能反映到调用方传入的变量上时,就必须使用按引用传递。不过,也不应该只在这种场景下才考虑引用。按引用传递避免了参数复制,因此还带来两个额外好处:
- 效率: 大对象的复制可能代价很高;按引用传递只需传递一个引用。
- 适用性: 并不是所有类都支持按值传递。
如果你想享受这些好处,但又不希望函数修改原对象,就应当把参数声明为 const,也就是使用“对 const 的引用传递”。
函数也可以返回引用。当然,这种技巧只有在“被返回引用所绑定的对象,在函数结束后依然继续存在”时才成立。
永远不要从函数中返回一个对“该函数局部变量”的引用,例如栈上自动分配的局部对象;因为函数一结束,它们就会被销毁。
返回引用的一个重要原因,是你希望返回值本身可以直接作为左值(lvalue) 使用,也就是出现在赋值语句左侧。许多重载运算符都会返回引用,例如 =、+= 等。第 15 章 会详细解释如何自己编写这类重载运算符。
另一个原因是:返回类型如果复制成本很高,那么通过返回引用或“对 const 的引用”,就可以避免复制。不过别忘了前面的警告:只有在被引用对象在函数返回后仍然活着的前提下,这样做才安全。本章后面就会看到:类成员函数经常会通过“返回对 const 的引用”来返回对象。
在引用和指针之间做选择
Section titled “在引用和指针之间做选择”有人会觉得 C++ 的引用有点“多余”,因为理论上凡是引用能做到的事,指针也都能做到。例如,前面那个 swap() 函数,其实也可以写成这样:
void swap(int* first, int* second){ int temp { *first }; *first = *second; *second = temp;}不过这段代码明显比“使用引用的版本”更乱。引用能让程序更清晰、更易读。它通常也比指针更安全:不存在空引用,而且你不会显式对引用做解引用,因此也就不会直接碰到那些典型的指针解引用错误。当然,关于“引用更安全”的这些说法,只在没有掺杂原始指针时才真正成立。比如,看看这个接收 int 引用的函数:
void refcall(int& t) { ++t; }你完全可以声明一个指针,并把它初始化成指向内存中的某个随机位置;然后再把它解引用,作为引用参数传给 refcall(),像下面这样。这段代码可以顺利编译,但运行时会发生什么则完全未定义;例如,它可能直接崩溃。
int* ptr { (int*)8 };refcall(*ptr);在大多数情况下,你都可以优先用引用而不是指针。对象引用和对象指针一样,也支持多态(polymorphism);这一点会在第 10 章 中详细讨论。不过,某些场景下你确实必须使用指针。一个典型例子是:你需要改变“它所指向的位置”。别忘了,引用一旦绑定就不能改绑。例如,当你动态分配内存时,保存结果的只能是指针,而不是引用。第二个必须用指针的场景,是“这个东西本身可能不存在”,也就是它可能为 nullptr。还有一种情况,是你想在容器里存放多态类型(也会在第 10 章 中讨论)。
在过去、尤其是遗留代码里,人们有一种区分“参数和返回值里该用指针还是引用”的思路:看谁拥有(owns) 这块内存。如果接收端代码会成为所有者,并负责释放该对象对应的内存,那它就应该接收指向该对象的指针。如果接收端不负责释放内存,那它通常就接收一个引用。不过在今天,更推荐避免原始指针,改用智能指针(smart pointers,见第 7 章) 来表达所有权转移。
考虑这样一个函数:它要把一个 int 数组拆成两个数组,一个保存偶数,一个保存奇数。这个函数事先并不知道源数组里到底有多少个奇数和偶数,所以必须先检查源数组,再为目标数组动态分配内存。它还需要把两个新数组的大小一起返回。总共要“带回”4 项信息:两个新数组的指针,以及这两个数组各自的大小。显然,这种场景就需要用到按引用传递。按照传统 C 风格,这个函数大概会写成下面这样:
void separateOddsAndEvens(const int arr[], size_t size, int** odds, size_t* numOdds, int** evens, size_t* numEvens){ // 统计奇数和偶数的个数。 *numOdds = *numEvens = 0; for (size_t i = 0; i < size; ++i) { if (arr[i] % 2 == 1) { ++(*numOdds); } else { ++(*numEvens); } }
// 分配两个大小合适的新数组。 *odds = new int[*numOdds]; *evens = new int[*numEvens];
// 把奇数和偶数分别复制到新数组中。 size_t oddsPos = 0, evensPos = 0; for (size_t i = 0; i < size; ++i) { if (arr[i] % 2 == 1) { (*odds)[oddsPos++] = arr[i]; } else { (*evens)[evensPos++] = arr[i]; } }}这个函数的最后 4 个参数,本质上承担的是“输出参数”的职责。为了修改它们所代表的值,separateOddsAndEvens() 必须不断显式解引用,这让函数体里出现了不少难看的语法。另外,调用这个函数时,你还必须传入两个指针的地址,让函数能修改那两个真正的指针;同时还要传入两个 size_t 的地址,让函数能修改真正的 size_t。别忘了:调用者还得自己负责释放 separateOddsAndEvens() 创建出来的那两个数组!
int unSplit[] { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int* oddNums { nullptr };int* evenNums { nullptr };size_t numOdds { 0 }, numEvens { 0 };
separateOddsAndEvens(unSplit, std::size(unSplit), &oddNums, &numOdds, &evenNums, &numEvens);
// 使用这两个数组……
delete[] oddNums; oddNums = nullptr;delete[] evenNums; evenNums = nullptr;如果这种语法已经让你觉得烦躁——它确实应该让你烦躁——那么你可以改用引用,把同一个函数写成真正的按引用传递语义:
void separateOddsAndEvens(const int arr[], size_t size, int*& odds, size_t& numOdds, int*& evens, size_t& numEvens){ numOdds = numEvens = 0; for (size_t i { 0 }; i < size; ++i) { if (arr[i] % 2 == 1) { ++numOdds; } else { ++numEvens; } }
odds = new int[numOdds]; evens = new int[numEvens];
size_t oddsPos { 0 }, evensPos { 0 }; for (size_t i { 0 }; i < size; ++i) { if (arr[i] % 2 == 1) { odds[oddsPos++] = arr[i]; } else { evens[evensPos++] = arr[i]; } }}在这个版本里,odds 和 evens 参数都是“对 int* 的引用”。因此,separateOddsAndEvens() 可以直接修改作为实参传进来的那两个 int*,不再需要显式解引用。同理,numOdds 和 numEvens 是“对 size_t 的引用”,处理方式也是一样。这样一来,调用这个版本时,你就不必再传指针地址或 size_t 地址了;引用参数会自动帮你处理这一层:
separateOddsAndEvens(unSplit, std::size(unSplit), oddNums, numOdds, evenNums, numEvens);虽然引用参数已经比指针参数干净得多,但更好的建议通常是:尽量避免动态分配原始数组。举例来说,如果使用标准库中的 vector 容器,那么 separateOddsAndEvens() 就可以被改写得更安全、更短、更优雅,也更易读,因为所有内存的申请与释放都会自动完成。
void separateOddsAndEvens(const vector<int>& arr, vector<int>& odds, vector<int>& evens){ for (int i : arr) { if (i % 2 == 1) { odds.push_back(i); } else { evens.push_back(i); } }}这个版本可以像下面这样使用:
vector<int> vecUnSplit { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };vector<int> odds, evens;separateOddsAndEvens(vecUnSplit, odds, evens);注意,你完全不需要手动释放 odds 和 evens 容器;vector 类会自动处理这些事情。这个版本比前面基于指针或引用的版本都更容易使用。
使用 vector 的版本已经远远好过前面那些基于原始数组和输出参数的版本了。但正如前面我建议过的:应尽量避免输出参数。如果函数需要返回东西,那它就应该直接把东西返回出来,而不是通过输出参数“带回来”!从 C++17 开始,对于形如 return object; 的语句,如果 object 是一个无名临时对象,编译器不允许对其执行任何复制或移动操作。这叫做强制性复制/移动省略(mandatory copy/move elision),意味着按值返回这样的对象完全不会带来性能损失。如果 object 是一个不是函数参数的局部变量,则还允许另一种优化:非强制复制/移动省略,也就是大家常说的命名返回值优化(NRVO, named return value optimization)。标准并不保证 NRVO 一定发生;有些编译器甚至只会在发布版本中启用它,而不会在调试版本中启用。无论是强制省略还是 NRVO,本质上都意味着:编译器常常可以避免对返回对象进行任何复制。这就带来了接近“零拷贝按值返回”的语义。请注意,对于 NRVO,即使复制 / 移动构造函数不会真的被调用,它们仍然必须是可访问的;否则,按照标准,这个程序仍然是不良构形式。关于复制 / 移动操作和构造函数的更多细节,会在第 9 章讨论;此刻暂时不必深入。
下面这个版本的 separateOddsAndEvens() 直接返回一个简单的 struct,其中包含两个 vector,而不是再接收两个输出 vector 参数。同时它还使用了指定初始化器:
struct OddsAndEvens { vector<int> odds, evens; };
OddsAndEvens separateOddsAndEvens(const vector<int>& arr){ vector<int> odds, evens; for (int i : arr) { if (i % 2 == 1) { odds.push_back(i); } else { evens.push_back(i); } } return OddsAndEvens { .odds = odds, .evens = evens };}经过这些调整后,调用 separateOddsAndEvens() 的代码就变得既紧凑,又清晰易懂:
vector<int> vecUnSplit { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };auto oddsAndEvens { separateOddsAndEvens(vecUnSplit) };// 对 oddsAndEvens.odds 和 oddsAndEvens.evens 做些处理……const_cast()
Section titled “const_cast()”在 C++ 中,每个变量都有明确的类型。在某些场景下,你可以把一种类型的变量转换为另一种类型。为此,C++ 提供了 5 类转换:const_cast()、static_cast()、reinterpret_cast()、dynamic_cast() 和 std::bit_cast()。本节讨论的是 const_cast()。第二种转换 static_cast() 本章前面已经简单提过,并会在第 10 章 进一步讨论;其他几种转换也会在第 10 章 中介绍。
在这几种转换中,const_cast() 是最直接的一种。你可以用它给一个变量“加上 const 属性”,也可以“去掉 const 属性”。它是这 5 类转换里唯一允许你移除 const 性质的工具。按理说,从理论层面讲,你本来不应该需要“去掉 const”;如果一个对象是 const,那它就该一直是 const。但在实践中,你有时会碰到这样一种局面:某个函数规范上接收的是 const 参数,可它内部又必须把这个值转手传给一个接收非 const 参数的函数,而你又百分之百确定后者不会真的修改对象。理想情况下,程序中所有关于 const 的设计都应该前后一致;但现实并不总允许你做到这点,尤其是在和第三方库打交道时。因此,有时你确实不得不“抛弃一个对象的 const 性质”。但务必记住:只有在你完全确定被调用函数不会修改该对象时,才可以这样做;否则,你就只能重构程序。下面是一个例子:
void thirdPartyLibraryFunction(char* str);
void f(const char* str){ thirdPartyLibraryFunction(const_cast<char*>(str));}此外,标准库还提供了一个名为 std::as_const() 的辅助函数,定义在 <utility> 中。它会返回“其引用参数的 const 引用”。基本上,as_const(obj) 等价于 const_cast<const T&>(obj),其中 T 是 obj 的类型。和直接使用 const_cast() 相比,as_const() 生成的代码通常更短,也更易读。本书后面还会看到它更具体的用法;现在先看它最基本的形式:
string str { "C++" };const string& constStr { as_const(str) };C++ 是一门非常灵活的语言,但这也意味着它允许你做一些不安全的事情。例如,编译器可以允许你编写“向随机内存地址乱写数据”的代码,或者去尝试做除以零(而计算机并不擅长处理无穷大)。语言中用来提高一定安全性的机制之一,就是异常(exceptions)。
所谓异常,就是一种“异常情况”——也就是在程序正常执行流程中你既不期望、也不希望发生的情况。例如,假设你正在编写一个抓取网页的函数,那么可能会出很多问题:提供网页的主机可能宕机了,网页返回的内容可能为空,网络连接也可能中途断掉。面对这种情况,一种做法是让函数返回一个特殊值,比如 nullptr 或错误码;而异常则提供了一种更好的处理机制。
异常也带来了一些新术语。当某段代码检测到异常情况时,它会抛出(throw) 一个异常。另一段代码则会捕获(catch) 这个异常,并采取适当措施。下面这个例子中的函数 divideNumbers(),会在调用者传入分母为 0 时抛出异常。std::invalid_argument 异常定义在 <stdexcept> 中。
double divideNumbers(double numerator, double denominator){ if (denominator == 0) { throw invalid_argument { "分母不能为 0。" }; } return numerator / denominator;}当执行 throw 语句时,函数会立刻结束,而不会返回普通值。如果调用者像下面这样用 try/catch 块把函数调用包起来,那么它就能接收到这个异常并进行处理。第 14 章“处理错误”会系统介绍异常处理;此时你先记住一点就好:推荐通过“对 const 的引用”来捕获异常,例如下面示例中的 const invalid_argument&。另外要注意,所有标准库异常类都带有一个名为 what() 的成员函数,它会返回一个简短说明异常原因的字符串。
try { println("{}", divideNumbers(2.5, 0.5)); println("{}", divideNumbers(2.3, 0)); println("{}", divideNumbers(4.5, 2.5));} catch (const invalid_argument& exception) { println("捕获到异常:{}", exception.what());}对 divideNumbers() 的第一次调用会成功执行,其结果会打印到屏幕上。第二次调用则会抛出异常,因此不会返回任何普通值,屏幕上只会输出在 catch 中打印的错误消息。第三次调用永远不会执行,因为第二次调用抛出异常后,程序控制流就直接跳到了 catch 块。上面这段代码的输出如下:
5捕获到异常:分母不能为 0。异常在 C++ 里很快就会变得复杂。要正确使用异常,你需要理解“抛出异常时栈上的局部对象会发生什么”,还要谨慎地捕获并处理真正需要处理的异常。此外,如果你想在异常里附带更丰富的错误信息,也可以定义自己的异常类型。最后还要注意:C++ 编译器并不会强迫你捕获所有可能出现的异常。如果你的代码从来没有捕获异常,而某个异常真的被抛了出来,那么程序就会被终止。这些更复杂的内容会在第 14 章 详细讨论。
类型别名(type alias) 能为已有类型声明提供一个新名字。你可以把它理解为:它只是给现有类型引入了一个“同义词”,并不会创建出一个真正的新类型。下面这行代码给 int* 这个类型起了一个新名字 IntPtr:
using IntPtr = int*;你可以交替使用新名字和它所对应的原始类型定义。例如,下面两行都完全合法:
int* p1;IntPtr p2;通过这个新名字声明出来的变量,与用原始类型声明出来的变量是完全兼容的。实际上,它们不只是“兼容”,而是同一种类型。因此下面的写法也完全没有问题:
p1 = p2;p2 = p1;类型别名最常见的用途,是在真实类型声明过于冗长时,为它提供一个更易于管理的名字。这种情况在模板代码里尤其常见。标准库本身就有一个例子:用 std::basic_string<T> 表示字符串。它是一个类模板,其中 T 表示字符串中每个字符的类型,例如 char。每次你想引用这种类型时,都必须写出模板类型参数。也就是说,声明变量、写函数参数时,你都得写 basic_string<char>:
void processVector(const vector<basic_string<char>>& vec) { /* 省略 */ }
int main(){ vector<basic_string<char>> myVector; processVector(myVector);}由于 basic_string<char> 太常用了,标准库干脆为它提供了一个更短、更直观的类型别名:
using string = basic_string<char>;有了这个别名,前面的代码就可以写得优雅得多:
void processVector(const vector<string>& vec) { /* 省略 */ }
int main(){ vector<string> myVector; processVector(myVector);}typedef
Section titled “typedef”类型别名是 C++11 才引入的。在 C++11 之前,如果你想做类似的事情,就只能使用 typedef,而它的写法更别扭。这里仍然会解释这种旧机制,因为你在遗留代码库中一定会遇到它。
和类型别名一样,typedef 也可以为现有类型声明起一个新名字。例如,考虑下面这个类型别名:
using IntPtr = int*;它可以用 typedef 改写成:
typedef int* IntPtr;正如你看到的,typedef 的可读性要差得多。顺序被颠倒了,这会造成不少混乱——哪怕是对专业的 C++ 开发者来说也是如此。除了写法更绕之外,typedef 的行为与类型别名基本一致。例如,你同样可以这样使用它:
IntPtr p;不过,类型别名和 typedef 也并不完全等价。和 typedef 相比,类型别名在和模板一起使用时更强大;但这已经属于第 12 章 的内容了,因为它需要更多模板背景。
类型推断(type inference) 允许编译器自动推导某个表达式的类型。与类型推断相关的两个关键字是 auto 和 decltype。
auto 关键字
Section titled “auto 关键字”auto 关键字有多种不同用途:
- 推导函数返回类型(本章前面已经提到)
- 定义结构化绑定(本章前面已经提到)
- 推导表达式的类型(本节讨论)
- 推导非类型模板参数的类型;见第 12 章
- 定义缩写函数模板;见第 12 章
- 与
decltype(auto)配合使用;见第 12 章 - 使用替代函数语法书写函数;见第 12 章
- 编写泛型 lambda 表达式;见第 19 章“函数指针、函数对象和 Lambda 表达式”
auto 可以用来让编译器在编译时自动推导变量类型。下面这条语句展示了它在这种语境下最简单的用法:
auto x { 123 }; // x 的类型是 int。在这个例子里,写 auto 而不是 int 并没有带来多少实际收益;但一旦类型变复杂,auto 就会非常有用了。假设你有一个名为 getFoo() 的函数,而它的返回类型很复杂。如果你想把 getFoo() 的结果赋给一个变量,那么你可以硬着头皮把那个复杂类型完整写出来,也可以直接使用 auto,让编译器替你推导:
auto result { getFoo() };这样做的另一个好处是:如果以后你修改了函数的返回类型,就不需要回过头去逐一更新代码中所有调用这个函数的位置。
auto& 语法
Section titled “auto& 语法”使用auto 来推导表达式的类型会去除引用和const 限定符。假设您有以下情况:
const string message { "Test" };const string& foo() { return message; }你可以调用 foo(),并把结果存进一个使用 auto 声明的变量中,例如:
auto f1 { foo() };由于 auto 会去掉引用和 const 限定符,所以 f1 的类型实际上是 string,这意味着这里创建了一个副本!如果你真正想得到的是“对 const 的引用”,那么就必须显式把它写成引用,并标上 const,例如:
const auto& f2 { foo() };本章前面已经介绍过 as_const() 这个辅助函数。它会返回其引用参数的“对 const 的引用”版本。不过,as_const() 和 auto 一起使用时要格外小心:由于 auto 会去掉引用和 const 限定符,所以下面这个 result 的实际类型是 string,而不是 const string&,因此这里依然会产生一个副本:
string str { "C++" };auto result { as_const(str) };请始终记住:auto 会去掉引用和 const 限定符,因此很可能创建出一个副本!如果你不想复制对象,请使用 auto& 或 const auto&。
auto* 语法
Section titled “auto* 语法”auto 关键字也可以用于指针。例如:
int i { 123 };auto p { &i };这里 p 的类型是 int*。和前一节讨论的“引用 + auto”不同,这里不存在意外产生副本的问题。不过在处理指针时,我仍然建议使用 auto* 语法,因为它能更清楚地表明“这里涉及的是指针”,例如:
auto* p { &i };此外,使用 auto* 而不是单纯的 auto,还能避免在 auto、const 和指针一起出现时的某些诡异行为。假设你写了下面这句:
const auto p1 { &i };大多数情况下,这并不会产生你以为的结果!
通常,当你写 const 时,你真正想保护的是“指针所指向的对象”。你可能会以为 p1 的类型是 const int*,但实际上它的类型是 int* const,也就是说:它是一个“指向非 const int 的 const 指针”!把 const 放在 auto 后面也帮不上忙;类型依然是 int* const:
auto const p2 { &i };当你把 auto* 和 const 结合起来使用时,行为就会更符合直觉。例如:
const auto* p3 { &i };现在 p3 的类型是 const int*。如果你真正想要的是“const 指针”而不是“指向 const int 的指针”,那就把 const 放到最后:
auto* const p4 { &i };p4 的类型为 int* const。
最后,利用这种语法,你还可以同时让“指针本身”和“它所指向的整数”都成为常量:
const auto* const p5 { &i };p5 的类型是 const int* const。如果省略 *,你就做不到这一点。
复制列表与直接列表初始化
Section titled “复制列表与直接列表初始化”使用花括号初始化器列表时,存在两种初始化形式:
- 复制列表初始化:
T obj = {arg1, arg2, …}; - 直接列表初始化:
T obj {arg1, arg2, …};
一旦和 auto 类型推导结合起来,复制列表初始化与直接列表初始化之间就会出现一个非常重要的差异。看下面这个例子:
// 复制列表初始化auto a = { 11 }; // initializer_list<int>auto b = { 11, 22 }; // initializer_list<int>
// 直接列表初始化auto c { 11 }; // intauto d { 11, 22 }; // 错误,元素太多。对于复制列表初始化,花括号中的所有元素必须具有相同类型。例如,下面的代码就无法编译:
auto b = { 11, 22.33 }; // 编译错误decltype 关键字
Section titled “decltype 关键字”decltype 关键字以一个表达式作为参数,并得出该表达式的类型,例如:
int x { 123 };decltype(x) y { 456 };在这个例子中,编译器会把 y 的类型推导为 int,因为 x 的类型就是 int。
auto 和 decltype 的区别在于:decltype 不会去掉引用和 const 限定符。继续使用前面那个“返回对 const string 的引用”的函数 foo()。如果像下面这样使用 decltype 定义 f2,那么 f2 的类型就会是 const string&,因此不会产生复制:
decltype(foo()) f2 { foo() };乍看之下,decltype 好像并没有带来特别大的价值。不过在模板语境中,它会变得非常强大;相关内容会在第 12 章和第 26 章中讨论。
C++ 自带一套标准库,其中包含大量可以直接在代码里使用的实用类和工具。使用这些类的好处在于:你不需要重新发明轮子,也不必浪费时间去实现那些已经有人为你实现好的功能。另一个好处是,标准库中的类已经经过成千上万用户的长期使用、测试和正确性验证。它们通常还做过性能优化,因此和自己手写实现相比,使用标准库往往更容易获得更好的性能。
标准库能做的事情非常多。第 16 章 到第 24 章 会进一步展开介绍;不过,当你刚开始接触 C++ 时,最好从一开始就对标准库能帮你做些什么有一个基本印象。这一点对 C 程序员尤其重要。作为 C 程序员,你可能会下意识地沿用在 C 中解决问题的方式;但在 C++ 中,往往已经有一种更简单、更安全的标准库方案在等着你。
这也正是为什么本章已经提前引入了一些标准库类,例如 std::string、array、vector、pair 和 optional。从本书最开始的示例起,它们就会被频繁使用,目的就是让你尽早养成优先使用标准库的习惯。更多标准库类会在第 16 章到第 24 章 中继续介绍。
你的第一个更大的 C++ 程序
Section titled “你的第一个更大的 C++ 程序”下面这个程序建立在前面讲结构体时用过的“员工数据库”示例之上。这一次,你最终会得到一个功能完整的 C++ 程序,它会综合运用本章中介绍过的许多语言特性。这个更贴近真实世界的例子会涉及类、异常、流、vector、命名空间、引用,以及其他不少语言功能。
员工记录系统
Section titled “员工记录系统”接下来的部分会实现一个用于管理公司员工记录的程序,具备以下功能:
- 添加和解雇员工
- 员工晋升和降职
- 查看所有员工(包括在职与离职)
- 查看所有在职员工
- 查看所有离职员工
这个程序的设计会把代码分成 3 个部分:Employee 类负责封装描述单个员工的信息;Database 类负责管理公司中的全部员工;最后,单独的 UserInterface 文件负责为程序提供交互界面。
Employee 类维护有关员工的所有信息。它的成员函数提供了一种查询和更改该信息的方法。 Employee 也知道如何在控制台上显示自己。此外,成员函数的存在是为了调整员工的工资和就业状况。
Employee.cppm
Section titled “Employee.cppm”Employee.cppm 模块接口文件定义Employee 类。该文件的各个部分将在下面的文本中单独描述。前几行如下:
export module employee;import std;namespace Records {第一行是模块声明,指出该文件导出一个名为 employee 的模块,然后导入标准库功能。此代码还声明大括号内包含的后续代码位于 Records 命名空间中。 Records 是在整个程序中用于特定于应用程序的代码的命名空间。
接下来,在 Records 命名空间内定义以下两个常量。本书采用的惯例是不使用任何特殊字母作为常量前缀,并以大写字母开头,以便更好地将它们与变量进行对比。
const int DefaultStartingSalary { 30'000 }; export const int DefaultRaiseAndDemeritAmount { 1'000 };第一个常量表示新员工的默认起薪。该常量不会被导出,因为该模块外部的代码不需要访问它。 employee 模块中的代码可以以 Records::DefaultStartingSalary 的形式访问该常量。
第二个常量是晋升或降职员工的默认金额。该常量是导出的,因此该模块外部的代码可以将员工晋升为默认金额的两倍。
接下来,定义并导出 Employee 类及其公共成员函数:
export class Employee { public: Employee(const std::string& firstName, const std::string& lastName);
void promote(int raiseAmount = DefaultRaiseAndDemeritAmount); void demote(int demeritAmount = DefaultRaiseAndDemeritAmount); void hire(); // 雇用或重新雇用该员工 void fire(); // 解雇该员工 void display() const; // 将员工信息打印到控制台
// 访问器与修改器 void setFirstName(const std::string& firstName); const std::string& getFirstName() const;
void setLastName(const std::string& lastName); const std::string& getLastName() const;
void setEmployeeNumber(int employeeNumber); int getEmployeeNumber() const;
void setSalary(int newSalary); int getSalary() const;
bool isHired() const;提供了一个接受名字和姓氏的构造函数。 promote() 和demote() 成员函数都有整数参数,其默认值等于DefaultRaiseAndDemeritAmount。这样,其他代码可以省略该参数,会自动使用默认值。提供了雇用和解雇员工的成员函数,以及显示有关员工信息的成员函数。许多 setter 和 getter 提供更改信息或查询员工当前信息的功能。
数据成员声明为private,以便代码的其他部分不能直接修改它们:
private: std::string m_firstName; std::string m_lastName; int m_employeeNumber { -1 }; int m_salary { DefaultStartingSalary }; bool m_hired { false }; };}setter 和 getter 提供修改或查询这些值的唯一公共方式。数据成员直接在类定义中初始化,而不是在构造函数中初始化。默认情况下,新员工没有姓名,员工编号为 –1,默认起薪,状态为未雇用。
Employee.cpp
Section titled “Employee.cpp”模块实现文件的前几行如下:
module employee;import std;using namespace std;第一行指定该源文件针对哪个模块,后跟std 的导入和using 指令。
接受名字和姓氏的构造函数只是设置相应的数据成员:
namespace Records { Employee::Employee(const string& firstName, const string& lastName) : m_firstName { firstName }, m_lastName { lastName } { }promote() 和demote() 成员函数只是用新值调用setSalary()。整数参数的默认值这里不再赘述;它们只允许出现在函数声明中,而不能出现在定义中。
void Employee::promote(int raiseAmount) { setSalary(getSalary() + raiseAmount); }
void Employee::demote(int demeritAmount) { setSalary(getSalary() - demeritAmount); }hire() 和 fire() 成员函数只是适当地设置 m_hired 数据成员:
void Employee::hire() { m_hired = true; } void Employee::fire() { m_hired = false; }display() 成员函数使用 println() 来显示当前员工的信息。由于这段代码本身就位于 Employee 类内部,所以它完全可以直接访问数据成员,例如 m_salary,而不必通过 getSalary() 这样的 getter。不过,一般仍然认为:如果 getter 和 setter 已经存在,那么即便在类内部,优先使用它们也属于较好的风格。
void Employee::display() const { println("员工:{},{}", getLastName(), getFirstName()); println("-------------------------"); println("{}", (isHired() ? "在职" : "离职")); println("员工编号:{}", getEmployeeNumber()); println("工资:${}", getSalary()); println(""); }最后,一组 getter 和 setter 负责读取和修改这些值:
// 访问器与修改器 void Employee::setFirstName(const string& firstName) {m_firstName = firstName;} const string& Employee::getFirstName() const { return m_firstName; }
void Employee::setLastName(const string& lastName) { m_lastName = lastName; } const string& Employee::getLastName() const { return m_lastName; }
void Employee::setEmployeeNumber(int employeeNumber) { m_employeeNumber = employeeNumber; } int Employee::getEmployeeNumber() const { return m_employeeNumber; }
void Employee::setSalary(int salary) { m_salary = salary; } int Employee::getSalary() const { return m_salary; }
bool Employee::isHired() const { return m_hired; }}虽然这些成员函数看起来都很简单,但即便是简单的 getter / setter,也通常比直接把数据成员设为 public 更好。例如,将来你可能会想在 setSalary() 里加入边界检查。getter 和 setter 还会让调试更容易,因为你可以直接在它们里面打断点,在值被读取或写入时检查状态。另一个重要原因是:如果你以后改变了类内部保存数据的方式,那么往往只需要改这些 getter 和 setter,而使用该类的其他代码则可以保持不动。
EmployeeTest.cpp
Section titled “EmployeeTest.cpp”当你在编写单独的类时,先把它们独立测试一下通常很有帮助。下面这段代码里有一个 main() 函数,它会对 Employee 类做一些简单操作。一旦你确认 Employee 类已经正常工作,就应该删掉这个文件,或者至少把它注释掉,避免之后把多个 main() 一起拿去编译。
import std;import employee;
using namespace std;using namespace Records;
int main(){ println("测试 Employee 类。"); Employee emp { "Jane", "Doe" }; emp.setFirstName("John"); emp.setLastName("Doe"); emp.setEmployeeNumber(71); emp.setSalary(50'000); emp.promote(); emp.promote(50); emp.hire(); emp.display();}另一种更好的测试单个类的方法,是使用单元测试(unit testing);这一点会在第 30 章“成为测试专家”中讨论。单元测试是一些专门用于测试特定功能的小代码片段,而且它们会长期保留在代码库中。所有单元测试都会被频繁执行,例如由构建系统自动运行。它的好处在于:只要你改动了现有功能,单元测试就会立刻告诉你有没有把什么东西改坏。
接下来要实现 Database 类。它使用标准库中的 std::vector 来存放 Employee 对象。
Database.cppm
Section titled “Database.cppm”下面是 database.cppm 模块接口文件的前几行:
export module database;import std;import employee;
namespace Records { const int FirstEmployeeNumber { 1'000 };由于数据库会自动给新员工分配员工编号,因此这里用一个常量来规定编号从哪里开始。
接着,定义并导出 Database 类:
export class Database { public: Employee& addEmployee(const std::string& firstName, const std::string& lastName); Employee& getEmployee(int employeeNumber); Employee& getEmployee(const std::string& firstName, const std::string& lastName);这个数据库提供了一种简单方式:通过名字和姓氏来添加新员工。为了方便起见,这个成员函数会返回“对新员工对象的引用”。外部代码还可以通过 getEmployee() 成员函数获取某位员工的引用。这里声明了它的两个重载版本:一个可以按员工编号查找,另一个则按名字和姓氏查找。
因为数据库是所有员工记录的中央仓库,所以它还提供了下面这些成员函数,用来显示全部员工、当前在职员工,以及已经离职的员工:
void displayAll() const; void displayCurrent() const; void displayFormer() const;最后,private 数据成员定义如下:
private: std::vector<Employee> m_employees; int m_nextEmployeeNumber { FirstEmployeeNumber }; };}m_employees 数据成员保存所有 Employee 对象,而 m_nextEmployeeNumber 则负责记录“下一个新员工应该分到的编号”,并用 FirstEmployeeNumber 常量作为初始值。
Database.cpp
Section titled “Database.cpp”下面是 addEmployee() 成员函数的实现:
module database;import std;
using namespace std;
namespace Records { Employee& Database::addEmployee(const string& firstName, const string& lastName) { Employee theEmployee { firstName, lastName }; theEmployee.setEmployeeNumber(m_nextEmployeeNumber++); theEmployee.hire(); m_employees.push_back(theEmployee); return m_employees.back(); }addEmployee() 会先创建一个新的 Employee 对象,填好信息,然后把它追加进 vector。m_nextEmployeeNumber 在使用之后会自增,因此下一位员工会拿到新的编号。vector 的成员函数 back() 会返回容器最后一个元素的引用,也就是刚刚添加进去的那位员工。
下面展示的是其中一个 getEmployee() 重载的实现。另一个重载的实现方式几乎一样,所以这里就不再重复展示。它们都会通过基于范围的 for 循环遍历 m_employees 中的所有员工,并检查某个 Employee 是否和传给成员函数的信息匹配。如果找不到匹配项,就抛出异常。还请注意这里使用了 auto&:因为循环并不想处理 Employee 的副本,而是希望直接操作 m_employees 中那些对象本身的引用。
Employee& Database::getEmployee(int employeeNumber) { for (auto& employee : m_employees) { if (employee.getEmployeeNumber() == employeeNumber) { return employee; } } throw logic_error { "未找到员工。" }; }下面这些显示函数使用的思路都差不多:遍历所有员工,并在满足显示条件时,让每位员工自己把信息输出到控制台上。
void Database::displayAll() const { for (const auto& employee : m_employees) { employee.display(); } }
void Database::displayCurrent() const { for (const auto& employee : m_employees) { if (employee.isHired()) { employee.display(); } } }
void Database::displayFormer() const { for (const auto& employee : m_employees) { if (!employee.isHired()) { employee.display(); } } }}DatabaseTest.cpp
Section titled “DatabaseTest.cpp”下面展示了一个针对数据库基础功能的简单测试:
import std;import database;
using namespace std;using namespace Records;
int main(){ Database myDB; Employee& emp1 { myDB.addEmployee("Greg", "Wallis") }; emp1.fire();
Employee& emp2 { myDB.addEmployee("Marc", "White") }; emp2.setSalary(100'000);
Employee& emp3 { myDB.addEmployee("John", "Doe") }; emp3.setSalary(10'000); emp3.promote();
println("所有员工:\n=============="); myDB.displayAll();
println("\n在职员工:\n=================="); myDB.displayCurrent();
println("\n离职员工:\n================="); myDB.displayFormer();}程序的最后一部分,是一个基于菜单的用户界面,它让用户能够比较方便地操作员工数据库。
下面这个 main() 函数包含一个循环:显示菜单、执行用户所选的操作,然后再回来继续显示菜单。对于多数操作,都定义了独立函数;而对于一些更简单的动作,例如显示员工列表,则直接把代码写在相应的 case 中。
import std;import database;import employee;
using namespace std;using namespace Records;
int displayMenu();void doHire(Database& db);void doFire(Database& db);void doPromote(Database& db);
int main(){ Database employeeDB; bool done { false }; while (!done) { int selection { displayMenu() }; switch (selection) { case 0: done = true; break; case 1: doHire(employeeDB); break; case 2: doFire(employeeDB); break; case 3: doPromote(employeeDB); break; case 4: employeeDB.displayAll(); break; case 5: employeeDB.displayCurrent(); break; case 6: employeeDB.displayFormer(); break; default: println(cerr, "未知命令。"); break; } }}displayMenu() 函数负责打印菜单并读取用户输入。这里有一个重要前提:这段代码假设用户会“表现良好”,在要求输入数字时真的输入一个数字。等你读到第 13 章 里的 I/O 内容时,就会知道该如何防御错误输入。
int displayMenu(){ int selection; println(""); println("员工数据库"); println("-----------------"); println("1) 雇用新员工"); println("2) 解雇员工"); println("3) 晋升员工"); println("4) 列出所有员工"); println("5) 列出所有在职员工"); println("6) 列出所有离职员工"); println("0) 退出"); println(""); print("---> "); cin >> selection; return selection;}doHire() 会从用户那里读入新员工的名字和姓氏,然后通知数据库添加这位员工:
void doHire(Database& db){ string firstName; string lastName;
print("名字?"); cin >> firstName;
print("姓氏?"); cin >> lastName;
auto& employee { db.addEmployee(firstName, lastName) }; println("已雇用员工 {} {},员工编号为 {}。", firstName, lastName, employee.getEmployeeNumber());}doFire() 和 doPromote() 都会先通过员工编号去数据库中查找对应员工,然后调用 Employee 对象的 public 成员函数完成修改:
void doFire(Database& db){ int employeeNumber; print("员工编号?"); cin >> employeeNumber;
try { auto& emp { db.getEmployee(employeeNumber) }; emp.fire(); println("员工 {} 已被解雇。", employeeNumber); } catch (const std::logic_error& exception) { println(cerr, "无法解雇员工:{}", exception.what()); }}
void doPromote(Database& db){ int employeeNumber; print("员工编号?"); cin >> employeeNumber;
int raiseAmount; print("加薪多少?"); cin >> raiseAmount;
try { auto& emp { db.getEmployee(employeeNumber) }; emp.promote(raiseAmount); } catch (const std::logic_error& exception) { println(cerr, "无法晋升员工:{}", exception.what()); }}评析这个程序
Section titled “评析这个程序”前面这个程序覆盖了许多从简单到较复杂的主题。你可以用很多不同方式去扩展它。例如,当前用户界面并没有暴露 Database 和 Employee 类的全部功能;你完全可以修改 UI,把那些功能也加进去。你还可以尝试为这两个类设计并实现更多你能想到的附加功能,这会是巩固本章内容的很好练习。
如果这个程序里的某些部分看起来还不太明白,就回头查阅本章中对应的讲解部分,再把相关主题复习一遍。如果仍然觉得有些地方不清楚,最好的学习方式就是亲手改代码、多做实验。例如,如果你还不确定条件运算符该怎么用,那就自己写一个简短的 main(),专门练练它。
完成这一章的 C++ 与标准库速成导论后,你就已经具备了继续深入学习本书其余部分的基础。等你在后面的章节里进一步钻研 C++ 语言时,本章可以随时作为一份速查材料,帮你回顾那些需要临时刷新记忆的知识点。有时候,只要回头看一眼本章中的某个示例,就足以把一个差点忘掉的概念重新唤回来。
下一章会更深入地讨论 C++ 中的字符串处理,因为几乎你写的每个程序,都绕不开字符串。
通过完成下面这些练习,你可以巩固本章讲到的内容。所有练习的参考解答都可以在本书网站 www.wiley.com/go/proc++6e 的代码下载中找到。不过,如果你在做题时遇到困难,我仍然建议先回头重读本章相关部分,尽量自己找到答案,再去查看网站上的解答。
- 练习 1-1: 修改本章开头的
Employee结构,把它放入一个名为HR的命名空间中。为了使用这个新实现,你需要对main()里的代码做哪些修改?另外,把代码改成使用指定初始化器。 - 练习 1-2: 在练习 1-1 的结果基础上继续扩展,在
Employee中添加一个枚举数据成员title,用来表示员工是经理、高级工程师还是工程师。你会选择哪一种枚举?为什么?需要新增的所有内容都放进HR命名空间。在main()函数中测试这个新的Employee数据成员,并使用switch语句打印出可读的职位名称字符串。 - 练习 1-3: 使用
std::array存储练习 1-2 中具有不同数据的三个Employee实例。随后,使用基于范围的for循环打印出array中的员工。 - 练习 1-4: 与练习 1-3 相同,但使用
std::vector而不是array,并使用push_back()将元素插入到vector中。 - 练习 1-5: 采用练习 1-4 的解决方案,并将第一个和最后一个姓名缩写的数据成员替换为表示完整名字和姓氏的字符串。
- 练习 1-6: 现在你已经了解了
const、引用以及它们的用途,请修改本章前面的AirlineTicket类,让它在可能的地方尽量使用引用,并做到const正确。 - 练习 1-7: 在练习 1-6 的
AirlineTicket类基础上,加入一个“可选的常旅客编号”数据成员。你认为表示这个可选数据成员的最佳方式是什么?添加一个 setter 和一个 getter 来设置和获取这个常旅客编号,并修改main()函数测试你的实现。
Footnotes
Section titled “Footnotes”-
由 Google Brain(Google 的人工智能团队)开发。它被用于 AI 处理器,并且在较新的 NVIDIA GPU 硬件中也得到支持。 ↩