应用设计模式
Design pattern(设计模式)是一种解决通用问题的标准化程序组织方式。与 design technique 相比,design pattern 的语言依赖性通常更弱。pattern 和 technique 之间的边界本来就有些模糊,不同书籍对它们的定义也不完全一致。本书将 technique 定义为“更偏 C++ 语言本身的策略”,而 pattern 则是适用于任何面向对象语言(例如 C++、C#、Java 或 Smalltalk)的更一般化设计策略。实际上,如果你熟悉 C# 或 Java,读本章时你会认出其中很多模式。
设计模式之所以强大,一个重要原因就在于它们有名字。名字本身就携带含义,因此能帮助人们更容易交流解决方案;同时,pattern 的名字也能帮助开发者更快理解某个设计。不过,也要注意:某些 pattern 其实有多个名字,而不同资料对某些 pattern 的区分方式也略有模糊,描述与归类方式并不总是完全一致。事实上,不同书和不同资料中,你甚至可能看到同一个名字被用于不同 pattern。至于究竟哪些设计方法才算 pattern,本身也存在争议。除少数例外外,本书主要遵循那本经典著作 Design Patterns: Elements of Reusable Object-Oriented Software(Erich Gamma 等著,Addison-Wesley Professional, 1994)中的术语体系。若有必要,本章也会注明其他 pattern 名称或变体。
设计模式这个概念本身非常简单,但威力很强。一旦你开始能够识别程序中反复出现的面向对象交互,想要找到一种优雅解法,往往就会变成“该选哪一个合适的 pattern”这个问题。
市面上已有整本书专门讲 design pattern,因此本章只会相对详细地挑选其中一小部分更重要的模式,并给出示例实现。这已经足以帮助你建立对设计模式的整体感受。
任何设计相关话题都很容易引发程序员之间的争论,而我认为这是一件好事。不要把这些 pattern 当成“完成某件任务的唯一方式”;更好的做法,是从它们的方法与思想中吸收可复用部分,再据此继续打磨它们,甚至形成新的模式。
策略模式(Strategy Pattern)
Section titled “策略模式(Strategy Pattern)”Strategy pattern 是支持 dependency inversion principle(DIP)的一种方式;相关讨论见第 6 章“面向复用设计”。在这个模式中,接口被用来反转依赖关系。对每一项对外提供的服务,都应建立一份接口;当某个组件需要一组服务时,就把这些服务的接口注入给这个组件,这种机制叫 dependency injection。Strategy pattern 的一个直接好处,是它会让单元测试更容易,因为你可以很方便地把这些服务 mock 掉。本节将以一个日志机制为例,展示如何用 Strategy pattern 来实现。
示例:日志机制
Section titled “示例:日志机制”这个基于 Strategy pattern 的 logger,会使用一个接口(也就是抽象基类)叫 ILogger。任何想写日志的代码,都只依赖这个 ILogger 接口。随后,一个该接口的具体实现会被注入到任何需要日志能力的代码中。采用这种模式后,单元测试就可以很容易地注入一个专门的 mock 实现,用来验证“是否记录了正确的信息”。它最大的优势,是具体 logger 可以在不修改任何库代码的前提下被轻松替换;客户端代码只需要传入自己想使用的 logger 即可。
基于 Strategy 的 Logger 实现
Section titled “基于 Strategy 的 Logger 实现”这个实现提供一个 Logger 类,具有下列特性:
- 它能够记录单条字符串消息。
- 每条日志都会带上当前系统时间以及对应的 log level。
- logger 可以被配置为“只记录高于某个特定 log level 的消息”。
- 每条写入的日志都会立刻 flush 到磁盘,因此会马上出现在文件里。
先来定义 ILogger interface:
export class ILogger{ public: virtual ~ILogger() = default; // Virtual destructor.
// Enumeration for the different log levels. enum class LogLevel { Debug, Info, Error };
// Sets the log level. virtual void setLogLevel(LogLevel level) = 0;
// Logs a single message at the given log level. virtual void log(std::string_view message, LogLevel logLevel) = 0;};接下来,实现一个 concrete 的 Logger 类:
export class Logger : public ILogger{ public: explicit Logger(const std::string& logFilename); void setLogLevel(LogLevel level) override; void log(std::string_view message, LogLevel logLevel) override; private: // Converts a log level to a human readable string. std::string_view getLogLevelString(LogLevel level) const;
std::ofstream m_outputStream; LogLevel m_logLevel { LogLevel::Error };};Logger 类的实现很直接。日志文件打开之后,每条日志消息都会带着 log level 前缀写进去,然后立刻 flush 到磁盘。
Logger::Logger(const string& logFilename){ m_outputStream.open(logFilename, ios_base::app); if (!m_outputStream.good()) { throw runtime_error { "Unable to initialize the Logger!" }; } println(m_outputStream, "{}: Logger started.", chrono::system_clock::now());}
void Logger::setLogLevel(LogLevel level){ m_logLevel = level;}
string_view Logger::getLogLevelString(LogLevel level) const{ switch (level) { case LogLevel::Debug: return "DEBUG"; case LogLevel::Info: return "INFO"; case LogLevel::Error: return "ERROR"; } throw runtime_error { "Invalid log level." };}
void Logger::log(string_view message, LogLevel logLevel){ if (m_logLevel > logLevel) { return; } println(m_outputStream, "{}: [{}] {}", chrono::system_clock::now(), getLogLevelString(logLevel), message);}使用基于 Strategy 的 Logger
Section titled “使用基于 Strategy 的 Logger”假设你有一个叫 Foo 的类,希望它能使用 logging 功能。采用 Strategy pattern 时,一个 concrete 的 ILogger 实例会被注入到这个类中,例如通过 constructor:
class Foo{ public: explicit Foo(ILogger* logger) : m_logger { logger } { if (m_logger == nullptr) { throw invalid_argument { "ILogger cannot be null." }; } } void doSomething() { m_logger->log("Hello strategy!", ILogger::LogLevel::Info); } private: ILogger* m_logger;};创建 Foo 实例时,就把一个 concrete ILogger 注入进去:
Logger concreteLogger { "log.out" };concreteLogger.setLogLevel(ILogger::LogLevel::Debug);
Foo f { &concreteLogger };f.doSomething();抽象工厂模式(Abstract Factory Pattern)
Section titled “抽象工厂模式(Abstract Factory Pattern)”现实中的工厂会制造各种实物,例如桌子或汽车。与之类似,object-oriented programming 中的 factory 则负责构造 object。当程序中使用 factory 时,任何想创建某种 object 的代码,都不会直接调用 object constructor,而是向 factory 请求一个该 object 的实例。例如,在一个室内设计程序中,你可能会有一个 FurnitureFactory object。某段代码如果需要一张桌子,就会调用 FurnitureFactory 的 createTable() 成员函数,从而得到一张新桌子。这正是 factory 的主要好处:它把 object creation 过程抽象了出来。
乍看之下,factory 似乎会让设计变得更复杂,因为它看起来只是给程序又加了一层间接性。既然能直接创建 Table object,为什么还要通过 FurnitureFactory 去调用 createTable()?然而,factory 的重要价值之一,是它能够与 class hierarchy 配合,让你在不知道 object 精确类型的前提下,仍然创建出正确 object。正如接下来的例子会展示的,factory 完全可以与 class hierarchy 平行存在。当然,这并不是说 factory 必须平行于 hierarchy;它也可以只是单纯创建任意多个 concrete type。
使用 factory 的另一个好处,是程序里无需到处散落着各种 object creation 逻辑。相反,你只需把 factory 传来传去,让程序不同部分都能通过它创建“同一类领域对象”。
另一个适合使用 factory 的原因,是 object 的创建本身可能依赖某些信息、状态、资源等等,而这些东西由 factory 持有,却不应暴露给 factory 的 client。若 object 的创建过程需要一连串顺序严格、步骤复杂的操作,或者新建 object 必须正确连接到其他 object 上,factory 也非常适合承担这些职责。
factory 还可以被替换;借助 dependency injection,你可以很容易在程序中换掉一套 factory。并且,就像可以对 object 使用 polymorphism 一样,你也可以对 factory 使用 polymorphism。下面的例子就会展示这一点。
在 object-oriented programming 中,factory 相关 pattern 主要有两类:Abstract Factory Pattern 和 Factory Method Pattern。本节先讨论 Abstract Factory Pattern,下一节再讨论 Factory Method Pattern。
示例:汽车工厂模拟
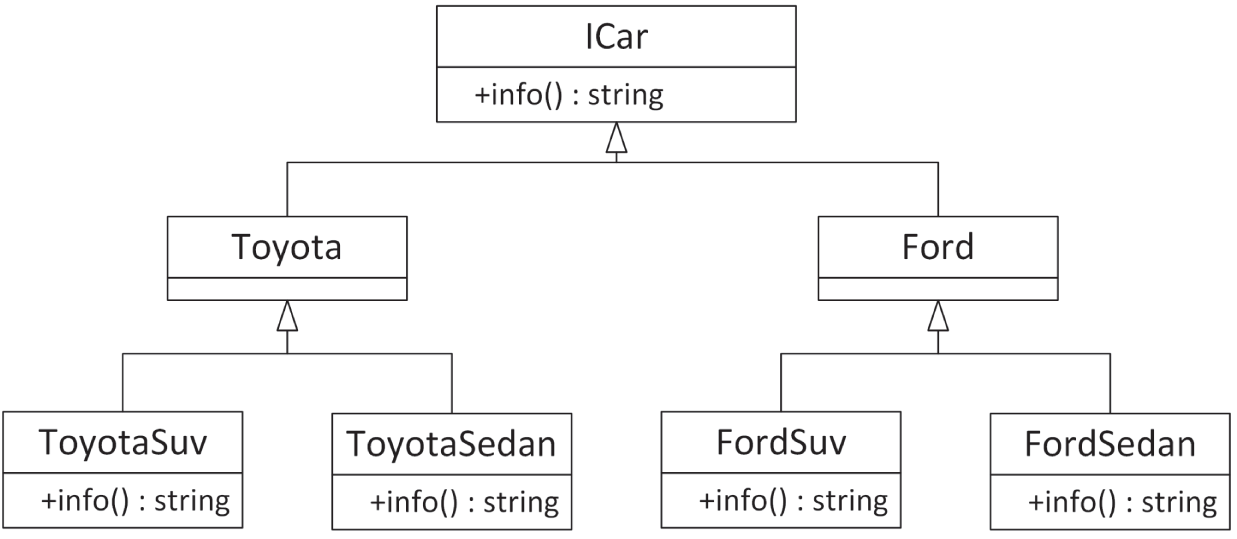
Section titled “示例:汽车工厂模拟”设想一个能生产汽车的工厂。工厂会根据请求,生产对应类型的车。首先,我们需要一套 hierarchy 来表示几种不同汽车。图 33.1 展示了一组车的层次结构:顶层是 ICar interface,它提供一个 virtual 成员函数,用来返回某辆车的信息。Toyota 和 Ford 都派生自 ICar,而且 Ford 与 Toyota 各自都有 sedan 和 SUV 两个型号。
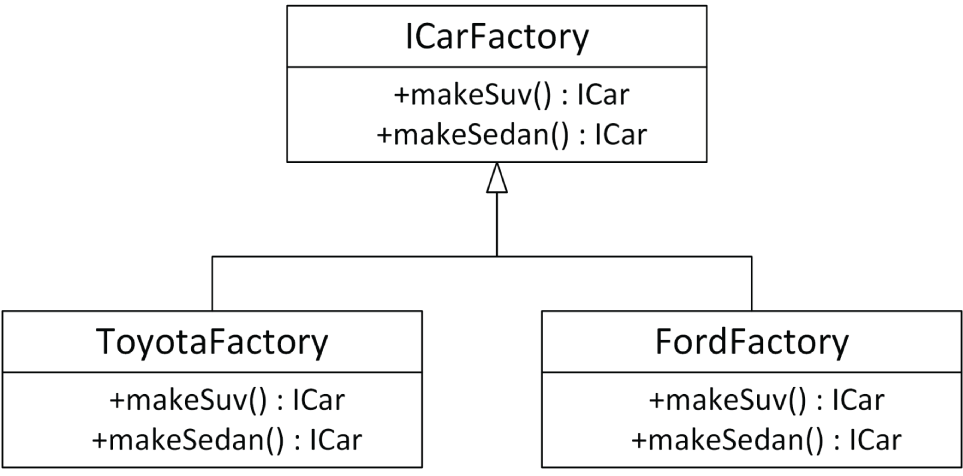
接下来,我们还需要一套与车层次结构并行的 factory hierarchy。abstract factory 只暴露“创建 sedan”与“创建 SUV”的 interface,而不关心品牌;具体品牌和具体车型,则由 concrete factory 构造。图 33.2 展示了这套 hierarchy。
[^FIGURE 33.1]
[^FIGURE 33.2]
抽象工厂的实现
Section titled “抽象工厂的实现”汽车 hierarchy 的实现很直接:
export class ICar{ public: virtual ~ICar() = default; // Always a virtual destructor! virtual std::string info() const = 0;};
export class Ford : public ICar { };
export class FordSedan : public Ford{ public: std::string info() const override { return "Ford Sedan"; }};
export class FordSuv : public Ford{ public: std::string info() const override { return "Ford SUV"; }};
export class Toyota : public ICar { };
export class ToyotaSedan : public Toyota{ public: std::string info() const override { return "Toyota Sedan"; }};
export class ToyotaSuv : public Toyota{ public: std::string info() const override { return "Toyota SUV"; }};接下来是 ICarFactory interface。它只暴露出创建 sedan 与 SUV 的成员函数,而不关心具体是哪家 factory 或哪种车。
export class ICarFactory{ public: virtual ~ICarFactory() = default; // Always a virtual destructor! virtual std::unique_ptr<ICar> makeSuv() = 0; virtual std::unique_ptr<ICar> makeSedan() = 0;};最后是 concrete factory,它们负责创建具体车型。这里只展示 FordFactory;ToyotaFactory 与之类似:
export class FordFactory : public ICarFactory{ public: std::unique_ptr<ICar> makeSuv() override { return std::make_unique<FordSuv>(); } std::unique_ptr<ICar> makeSedan() override { return std::make_unique<FordSedan>(); }};这个例子之所以叫 abstract factory,是因为最终创建出哪一种 object,取决于你使用的是哪一个 concrete factory。
使用抽象工厂
Section titled “使用抽象工厂”下面的例子展示了如何使用前面实现好的 factory。它定义了一个函数,接收 abstract car factory,并用它同时创建一辆 sedan 和一辆 SUV,然后打印每辆车的信息。这个函数对任何 concrete factory 或 concrete car 都毫不知情——它只依赖 interface。main() 则创建了两个 factory,一个生产 Ford,一个生产 Toyota,再把它们分别交给 createSomeCars() 去造车。
void createSomeCars(ICarFactory& carFactory){ auto sedan { carFactory.makeSedan() }; auto suv { carFactory.makeSuv() }; println("Sedan: {}", sedan->info()); println("SUV: {}", suv->info());}
int main(){ FordFactory fordFactory; ToyotaFactory toyotaFactory; createSomeCars(fordFactory); createSomeCars(toyotaFactory);}输出如下:
Sedan: Ford SedanSUV: Ford SUVSedan: Toyota SedanSUV: Toyota SUV工厂方法模式(Factory Method Pattern)
Section titled “工厂方法模式(Factory Method Pattern)”factory 相关 pattern 的另一大类,叫作 Factory Method Pattern。在这个 pattern 中,由 concrete factory 自己决定具体该创建什么对象。而在前面的 Abstract Factory 例子中,ICarFactory 明确有成员函数可创建 SUV 或 sedan。Factory Method Pattern 的思路则不同:你只管向 factory 要一辆车,至于最终返回 Toyota 还是 Ford,由 concrete factory 自己决定。来看另一个汽车工厂模拟例子。
示例:第二个汽车工厂模拟
Section titled “示例:第二个汽车工厂模拟”现实中,当你说“我想开车”时,通常并不需要先说明具体是什么车。你可能在说一辆 Toyota,也可能在说一辆 Ford。这并不重要,因为无论 Toyota 还是 Ford,它们都能开。现在,再假设你想买一辆新车。你是不是必须明确说“我要 Toyota”或“我要 Ford”?其实也不一定。你完全可以只说:“我想要一辆车。”而你最终拿到什么车,很可能取决于你当时身处哪里:如果你站在 Toyota 工厂里,大概率就会给你一辆 Toyota;如果你站在 Ford 工厂里,那拿到的多半就是 Ford。(当然,也可能是你先被保安带走,这取决于你是怎么提这个要求的。)
同样的概念也适用于 C++ 编程。第一层含义——也就是“generic 的 car 都能被 drive”——并不新鲜;这只是标准的 polymorphism,见第 5 章“使用类进行设计”。你可以写一个 abstract 的 ICar interface,定义一个 virtual 的 drive() 成员函数;然后让 Toyota 和 Ford 都实现这个 interface。
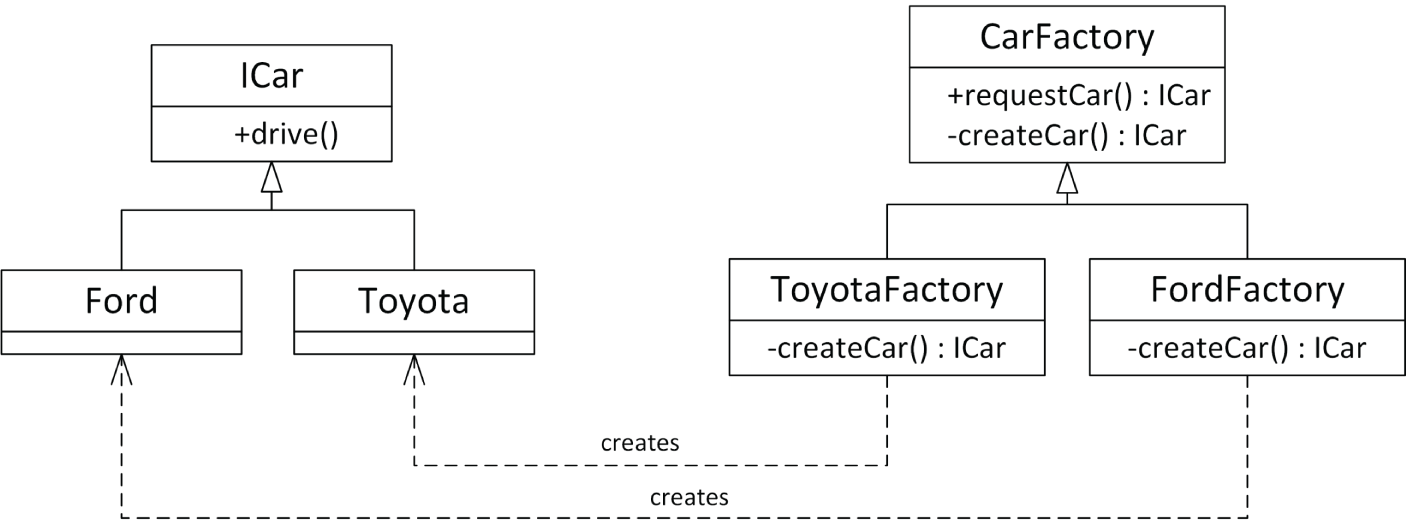
这样,你的程序在驾驶车辆时就不需要知道它到底是 Toyota 还是 Ford。但在标准 object-oriented programming 中,真正必须区分 Toyota 和 Ford 的地方,往往恰好出现在 object creation 本身:在那里,你必须明确调用某一方的 constructor。也就是说,你还没法真的只说一句 “I want a car”。不过,如果你同时再建立一套平行的 car factory hierarchy,就可以做到这一点。CarFactory base class 可以定义一个 public 的 non-virtual requestCar() 成员函数,并把实际工作转发给一个 private 的 virtual createCar() 成员函数。ToyotaFactory 与 FordFactory 这些派生类,则通过 override createCar() 来分别创建 Toyota 或 Ford。图 33.3 展示了 ICar 和 CarFactory 这两套 hierarchy。
[^FIGURE 33.3]
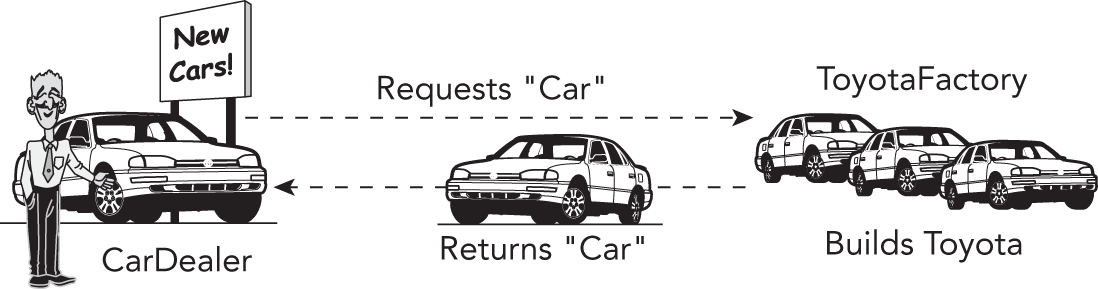
现在,假设程序里存在一个 CarFactory object。当代码中的某个部分(比如 car dealer)想要一辆新车时,它就对这个 CarFactory object 调用 requestCar()。至于该 factory 实际上是 ToyotaFactory 还是 FordFactory,对 client 而言并不重要;无论哪一种,它都会返回一辆可以被驾驶的车。图 33.4 展示的是 car dealer 程序使用 ToyotaFactory 时的对象关系。
[^FIGURE 33.4]
图 33.5 则展示了同样程序改用 FordFactory 时的情况。请注意,CarDealer object 自身以及它与 factory 的关系并没有变化。
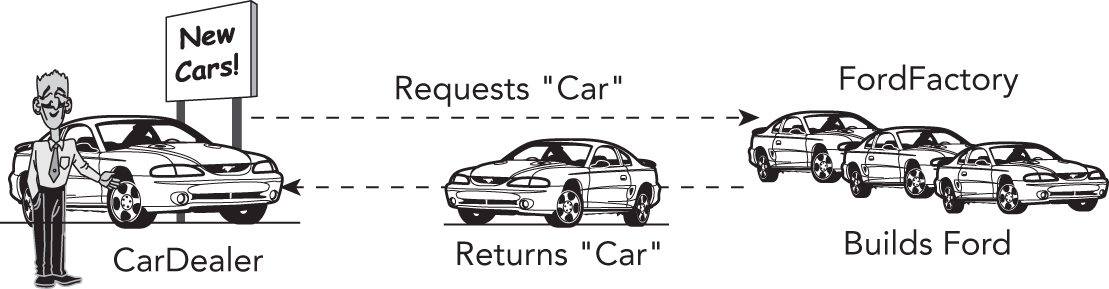
[^FIGURE 33.5]
这个例子展示的是:如何把 polymorphism 用在 factory 身上。当你向某个 car factory 要一辆车时,你也许并不知道它究竟是 Toyota factory 还是 Ford factory;但无论是哪一种,它总会给你一辆能开的车。这样的设计极易扩展:只要替换掉 factory instance,程序就能轻松切换到完全不同的一组对象与类。
工厂方法的实现
Section titled “工厂方法的实现”使用 factory 的一个常见原因,是“你想创建的对象类型本身依赖于某种条件”。例如,如果你想要一辆车,那么你也许希望把订单交给“当前接单数量最少的工厂”,而不在意最终拿到的是 Toyota 还是 Ford。下面这个实现就展示了:如何在 C++ 中写出这样的 factory。
首先,我们需要一套 car hierarchy:
export class ICar{ public: virtual ~ICar() = default; // Always a virtual destructor! virtual std::string info() const = 0;};
export class Ford : public ICar{ public: std::string info() const override { return "Ford"; }};
export class Toyota : public ICar{ public: std::string info() const override { return "Toyota"; }};CarFactory base class 则稍微有趣一些。每个 factory 都会记录自己一共生产了多少辆车。每当 public 的 non-virtual requestCar() 成员函数被调用时,它都会先把“已生产车辆数”加一,然后再调用 private 的 virtual 成员函数 createCar(),由后者真正创建并返回一辆 concrete 的 car。这个 idiom 也常被叫作 non-virtual interface idiom(NVI)。其核心思想是:具体工厂只需要 override createCar() 来返回正确类型的车;而像“更新已生产数量”这样的通用逻辑,则统一放在 CarFactory 自己实现的 requestCar() 中。这个 requestCar() 也是 template method design pattern 的一个例子。
CarFactory 还额外提供了一个 public 成员函数,用于查询每个工厂已生产车辆的数量。CarFactory 及其派生类定义如下:
export class CarFactory{ public: virtual ~CarFactory() = default; // Always a virtual destructor! // Omitted defaulted default ctor, copy/move ctor, copy/move assignment op.
std::unique_ptr<ICar> requestCar() { // Increment the number of cars produced and return the new car. ++m_numberOfCarsProduced; return createCar(); }
unsigned getNumberOfCarsProduced() const { return m_numberOfCarsProduced; } private: virtual std::unique_ptr<ICar> createCar() = 0; unsigned m_numberOfCarsProduced { 0 };};
export class FordFactory final : public CarFactory{ private: std::unique_ptr<ICar> createCar() override { return std::make_unique<Ford>(); }};
export class ToyotaFactory final : public CarFactory{ private: std::unique_ptr<ICar> createCar() override { return std::make_unique<Toyota>(); }};正如你看到的,派生类需要做的事其实很简单:只要 override createCar(),返回自己负责生产的具体车型即可。
使用工厂方法
Section titled “使用工厂方法”使用 factory 最简单的方式,就是先实例化它,再调用相应的成员函数,例如:
ToyotaFactory myFactory;auto myCar { myFactory.requestCar() };println("{}", myCar->info()); // Outputs Toyota不过,更有意思的例子,是利用“virtual constructor”这个思路,让程序总是在“当前产量最少的工厂”里造一辆车。为此,你可以再定义一个新的 factory,叫 LeastBusyFactory,它继承自 CarFactory,并在 constructor 中接收若干其他 CarFactory object。和所有 CarFactory 一样,LeastBusyFactory 需要 override createCar()。其实现会在 constructor 传入的 factories 中找出当前最闲的那个,然后要求它来创建一辆车。实现如下:
class LeastBusyFactory final : public CarFactory{ public: // Constructs an instance, taking ownership of the given factories. explicit LeastBusyFactory(vector<unique_ptr<CarFactory>> factories); private: unique_ptr<ICar> createCar() override; vector<unique_ptr<CarFactory>> m_factories;};
LeastBusyFactory::LeastBusyFactory(vector<unique_ptr<CarFactory>> factories) : m_factories { move(factories) }{ if (m_factories.empty()) { throw runtime_error { "No factories provided." }; }}
unique_ptr<ICar> LeastBusyFactory::createCar(){ auto leastBusyFactory { ranges::min_element(m_factories, [](const auto& factory1, const auto& factory2) { return factory1->getNumberOfCarsProduced() < factory2->getNumberOfCarsProduced(); }) }; return (*leastBusyFactory)->requestCar();}下面这段代码使用这个 factory 来建造 10 辆车——至于它们最终是 Ford 还是 Toyota,并不重要——全部从当前最不忙的工厂中生产:
vector<unique_ptr<CarFactory>> factories;
// Create 3 Ford factories and 1 Toyota factory.factories.push_back(make_unique<FordFactory>());factories.push_back(make_unique<FordFactory>());factories.push_back(make_unique<FordFactory>());factories.push_back(make_unique<ToyotaFactory>());
// To get more interesting results, preorder some cars from specific factories.for (size_t i : {0, 0, 0, 1, 1, 2}) { factories[i]->requestCar(); }
// Create a factory that automatically selects the least busy// factory from a list of given factories.LeastBusyFactory leastBusyFactory { move(factories) };
// Build 10 cars from the least busy factory.for (unsigned i { 0 }; i < 10; ++i) { auto theCar { leastBusyFactory.requestCar() }; println("{}", theCar->info());}运行时,程序会输出每一辆被生产出来的车的品牌:
ToyotaFordToyotaFordFordToyotaFordFordFordToyotaFactory Method Pattern 的用途,并不局限于“模拟真实工厂”。例如,想象一个 word processor,它需要支持多种 document language,而每个 document 在任意时刻只使用一种语言。语言不同,程序里就会有很多方面需要差异化支持:字符集、spell checker、thesaurus、文档显示方式,等等。你完全可以借助 factory 来设计出结构清晰的 word processor:写一个 LanguageFactory base class,再为每一种语言提供一个派生工厂,例如 EnglishLanguageFactory 和 FrenchLanguageFactory。当用户为文档指定语言时,程序就通过对应的 LanguageFactory,去创建那些语言相关的具体功能实例。例如,它会调用 factory 上的 createSpellchecker(),来构造该语言对应的 spell checker,然后把原先挂在文档上的旧 spell checker 替换掉。
其他工厂模式
Section titled “其他工厂模式”前几节讨论了两种和 factory 相关的具体 pattern:Abstract Factory Pattern 与 Factory Method Pattern。
除此之外,还有其他类型的 factory。比如,factory 完全可以不做成 class hierarchy,而是只由单个 class 实现。此时,factory 上往往只提供一个 create() 成员函数;它接收某个类型或字符串参数,再据此决定该创建哪种 object,而不是把这项职责分派给 concrete subclass。这类函数通常被称为 factory function。这种 factory pattern 不提供 dependency inversion,也不支持对 construction process 的可定制化。
factory function 的一个例子,是对 pimpl idiom 的另一种实现方式。pimpl idiom 已在第 9 章“精通类与对象”中讨论过。它会在 public interface 与具体实现之间建立一道隔离墙。采用 factory function 时,典型写法如下。首先,对外暴露的是下面这些内容,其中包含一个 create() factory function:
// Public interface (to be included in the rest of the program,// shared from a library, ...)class Foo{ public: virtual ~Foo() = default; // Always a virtual destructor! // Omitted defaulted copy/move ctor, copy/move assignment op. static unique_ptr<Foo> create(); // Factory function. // Public functionality... virtual void bar() = 0; protected: Foo() = default; // Protected default constructor.};然后,具体实现会对外界隐藏:
// Implementationclass FooImpl : public Foo{ public: void bar() override { /* ... */ }};
unique_ptr<Foo> Foo::create(){ return make_unique<FooImpl>();}任何需要 Foo instance 的 client code,都可以这样创建它:
auto fooInstance { Foo::create() };fooInstance->bar();适配器模式(Adapter Pattern)
Section titled “适配器模式(Adapter Pattern)”有时,某个 class 提供出来的抽象并不适合当前设计,而且你又没法修改它。这种情况下,就可以编写一个 adapter class。adapter 提供的是“剩余代码真正想使用的抽象”,同时充当“期望抽象”与“底层实际代码”之间的桥梁。它通常有两类典型用法:
- 通过复用现有实现,来实现某个既定 interface。在这种用法下,adapter 往往会在内部自行创建底层实现对象。
- 让某份已有功能以新的 interface 形式被使用。在这种用法下,adapter 的 constructor 通常会直接接收一个底层对象实例。
第 18 章“标准库容器”已经讨论过:Standard Library 是如何通过 Adapter Pattern,把 stack 和 queue 这类容器建立在 deque、list 等底层容器之上的。
示例:适配一个 Logger 类
Section titled “示例:适配一个 Logger 类”在这个 Adapter Pattern 的例子里,先假设我们已经有一个非常基础的 Logger 类。其 interface 和 class 定义如下:
// Definition of a logger interface.export class ILogger{ public: virtual ~ILogger() = default; // Always a virtual destructor! enum class LogLevel { Debug, Info, Error }; // Logs a single message at the given log level. virtual void log(LogLevel level, const std::string& message) = 0;};
// Concrete implementation of ILogger.export class Logger : public ILogger{ public: Logger(); void log(LogLevel level, const std::string& message) override; private: // Converts a log level to a human readable string. std::string_view getLogLevelString(LogLevel level) const;};Logger 的 constructor 会向标准输出写一行文本,而 log() 成员函数则会把给定消息写到控制台,并在前面加上当前系统时间和 log level。对应实现如下:
Logger::Logger() { println("Logger constructor"); }
void Logger::log(LogLevel level, const string& message){ println("{}: [{}] {}", chrono::system_clock::now(), getLogLevelString(level), message);}
string_view Logger::getLogLevelString(LogLevel level) const{ /* See the strategy-based logger earlier in this chapter. */ }你之所以可能想给这个基础 Logger 外面再包一层 adapter,一个原因是:你希望改变它的 interface。也许你根本不关心 log level,希望以后调用 log() 时只传一个参数——也就是实际消息本身。又或者,你希望这个 interface 不再接收 string,而改成接收 std::string_view。
适配器的实现
Section titled “适配器的实现”实现 Adapter Pattern 的第一步,是先定义“对底层功能的全新 interface”。这个新 interface 叫 IAdaptedLogger,定义如下:
export class IAdaptedLogger{ public: virtual ~IAdaptedLogger() = default; // Always virtual destructor! // Logs a single message with Info as log level. virtual void log(std::string_view message) = 0;};这个类是一个 abstract class,它声明了“你希望新 logger 对外呈现的 interface”。该 interface 只包含一个 pure virtual 成员函数,即一个只接收单个 string_view 参数的 log()。
下一步,就是编写新的 concrete logger 类 AdaptedLogger。它实现 IAdaptedLogger,从而暴露你刚设计好的新 interface。具体实现方式,则是在内部包一个 Logger 实例,也就是使用 composition:
export class AdaptedLogger : public IAdaptedLogger{ public: AdaptedLogger(); void log(std::string_view message) override; private: Logger m_logger;};这个新类的 constructor 会往标准输出写一行文字,用来追踪究竟调用了哪些 constructor。随后,代码通过把调用转发给内部那个 Logger 实例的 log() 成员函数,来实现 IAdaptedLogger 里的 log()。在转发时,传入的 string_view 会先被转换成 string,而 log level 则被硬编码成 Info。
AdaptedLogger::AdaptedLogger() { println("AdaptedLogger constructor"); }
void AdaptedLogger::log(string_view message){ m_logger.log(Logger::LogLevel::Info, string { message });}因为 adapter 的存在,就是为了让底层功能拥有一个“更适合当前使用场景”的 interface,所以从使用者角度看,它的使用方式理应直接而简单。基于前面的实现,下面这段代码就会通过新的简化 interface 来使用 logging 功能:
AdaptedLogger logger;logger.log("Testing the logger.");输出如下:
Logger constructorAdaptedLogger constructor2023-08-12 14:06:53.3694244: [INFO] Testing the logger.代理模式(Proxy Pattern)
Section titled “代理模式(Proxy Pattern)”Proxy Pattern 是一类把类的抽象与其底层表示分离开的 pattern 之一。proxy object 充当的是某个真实对象的替身。通常只有在“直接使用真实对象要么很耗时、要么根本不可行”时,才会引入 proxy。例如,想想文档编辑器:一个文档中可能包含很多很大的对象,比如图片。打开文档时,如果一开始就把这些图片全部加载进来,会非常慢。这时,编辑器完全可以先用 proxy object 替代所有图片。这些 proxy 不会立刻加载真正图片。只有当用户滚动文档、滚动到某张图片位置时,编辑器才会要求该 image proxy 去绘制自己;而这时 proxy 再把真正工作委托给真实 image object,由后者去完成图片加载。
proxy 也可以被用来正确地屏蔽某些功能细节,同时又确保 client 无法通过 cast 等技巧绕过这层屏蔽。
示例:隐藏网络连接问题
Section titled “示例:隐藏网络连接问题”设想一个 networked game,其中有一个 Player 类,用来表示互联网上加入了游戏的某个人。Player 类中包含一些依赖网络连接的功能,比如 instant messaging。如果某位玩家的连接失去响应,那么代表他的那个 Player object 就无法再接收 instant message。
既然你不希望把这种网络问题直接暴露给用户,那么一个合理设计,就是单独写一个类,把 Player 中依赖网络的部分隐藏起来。这个 PlayerProxy object 会替代真实的 Player object:要么所有 client 一开始就一直通过 PlayerProxy 去访问真实 Player,让它充当 gatekeeper;要么系统在某个 Player 不可用时,再动态用 PlayerProxy 去替代它。网络断开时,PlayerProxy 仍然可以显示玩家名字、最后已知状态,并继续工作;而真正的 Player object 此时则已经失效。也就是说,这个 proxy class 屏蔽了底层 Player 类中那些不理想的语义。
第一步,是定义一个 IPlayer interface,用来表示 Player 的 public interface:
class IPlayer{ public: virtual ~IPlayer() = default; // Always virtual destructor. virtual string getName() const = 0; // Sends an instant message to the player over the network and // returns the reply as a string. virtual string sendInstantMessage(string_view message) const = 0;};Player 类本身按下面的方式实现 IPlayer interface。这里假设 sendInstantMessage() 要正常工作就必须依赖网络连接,一旦网络断开,它就会抛出 exception。
class Player : public IPlayer{ public: string getName() const override; // Network connectivity is required. // Throws an exception if network connection is down. string sendInstantMessage(string_view message) const override;};PlayerProxy 类同样实现 IPlayer interface,并且内部再持有另一个 IPlayer 实例(也就是那个“真实”的 Player):
class PlayerProxy : public IPlayer{ public: // Create a PlayerProxy, taking ownership of the given player. explicit PlayerProxy(unique_ptr<IPlayer> player); string getName() const override; // Network connectivity is optional. string sendInstantMessage(string_view message) const override; private: bool hasNetworkConnectivity() const; unique_ptr<IPlayer> m_player;};constructor 会接管传入的 IPlayer 所有权:
PlayerProxy::PlayerProxy(unique_ptr<IPlayer> player) : m_player { move(player) } { }getName() 成员函数只是简单转发给底层 Player:
string PlayerProxy::getName() const { return m_player->getName(); }而 PlayerProxy 的 sendInstantMessage() 则会先检查网络连通性:如果网络正常,就把请求转发下去;如果网络断了,则直接返回一个默认字符串。这样一来,底层 Player 的 “网络断开时抛 exception” 这一事实,就被 proxy 屏蔽掉了。
string PlayerProxy::sendInstantMessage(string_view message) const{ if (hasNetworkConnectivity()) { return m_player->sendInstantMessage(message); } else { return "The player has gone offline."; }}如果 proxy 写得够好,那么从使用者角度看,它本应和使用普通对象没什么区别。对于 PlayerProxy 这个例子来说,使用它的代码甚至可以完全不知道 proxy 的存在。下面这个函数会在某个 Player 获胜时被调用;它面对的既可能是真正的 Player,也可能是 PlayerProxy。之所以同一份代码能同时处理这两种情况,正是因为 proxy 保证了外部总能得到一个合理结果。
bool informWinner(const IPlayer& player){ auto result { player.sendInstantMessage("You have won! Play again?") }; if (result == "yes") { println("{} wants to play again.", player.getName()); return true; } else { // The player said no, or is offline. println("{} does not want to play again.", player.getName()); return false; }}迭代器模式(Iterator Pattern)
Section titled “迭代器模式(Iterator Pattern)”Iterator Pattern 提供了一种机制,用来把 algorithm 或 operation 与它们所作用的数据结构本身分离开。简单说,iterator 让 algorithm 可以导航某个数据结构,而无需知道底层数据的具体组织方式。乍看之下,这似乎与 object-oriented programming 中“把数据与操作这些数据的行为放在同一个 class 里”的基本原则相冲突。这个担心在某种层面上确实有道理,但 Iterator Pattern 并不是主张把最核心的行为从 class 中全部剥离出去;它真正要解决的,是当数据和行为耦合得过紧时,常常会出现的两个具体问题。
第一个问题是:如果数据与行为绑定得太死,那么就很难写出能作用于多种数据结构的 generic algorithm。想写 generic algorithm,你需要某种标准化机制,让它在完全不了解具体数据结构的前提下,也能访问其中内容。
第二个问题是:在数据与行为紧耦合时,新增行为往往会很困难。最起码,你得能访问那些数据对象的 source code。可如果你想操作的数据 hierarchy 来自某个你无法修改的 third-party framework 或 library 呢?如果能在不改动原始 class hierarchy 的情况下,就额外加入一个操作或 algorithm,那当然会方便得多。
其实你早就已经在 Standard Library 中见过 Iterator Pattern。概念上说,Standard Library 的 iterator 提供了一种方式,让 operation 或 algorithm 可以顺序访问 container 中的元素。它之所以叫 iterator,源自英语动词 iterate,意思是“重复”。iterator 之所以贴切,就是因为它通过反复执行“向前移动一步”这一动作,逐个到达序列中的新元素。在 Standard Library 中,generic algorithm 正是通过 iterator 来访问其所操作 container 的元素。通过定义一套标准 iterator interface,Standard Library 让你可以写出适用于任何容器的 algorithm——只要该容器提供满足要求的 iterator interface 即可。你甚至还能为同一个数据结构提供多个不同 iterator,从而让 algorithm 以不同方式遍历数据。例如,对 tree 这种数据结构,就可以提供 top-down 和 bottom-up 两种 traversal 方式。换句话说,iterator 让你可以编写 generic algorithm,使它们在完全不了解底层结构的前提下也能遍历数据。图 33.6 把 iterator 画成了中心协调者:operation 依赖 iterator,而 data object 则提供 iterator。
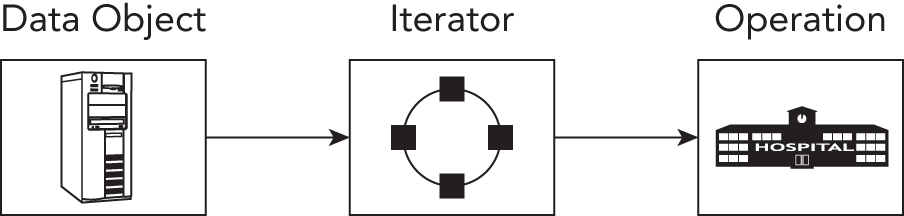
[^FIGURE 33.6]
第 25 章“定制与扩展 Standard Library”已经给出过一个较完整的例子,展示如何为某个数据结构实现符合 Standard Library 约定的 iterator,也就是那种可以直接被 generic Standard Library algorithm 使用的 iterator。
观察者模式(Observer Pattern)
Section titled “观察者模式(Observer Pattern)”Observer Pattern 用来让 observer 在 observable object(也就是 subject)发生变化时收到通知。具体的 observer 会先向自己感兴趣的 observable object 注册。当 observable object 的状态变化时,它就会通知所有已注册 observer。使用 Observer Pattern 的主要好处,在于它能降低耦合:observable class 不需要知道究竟是哪些 concrete observer 正在观察它。
示例:对 Subject 暴露事件
Section titled “示例:对 Subject 暴露事件”这个例子会实现一套通用事件机制,并允许事件带有 variadic 数量的参数。subject 可以暴露若干具体事件,例如“subject 数据被修改时触发的事件”“subject 数据被删除时触发的事件”等等。
Observable 的实现
Section titled “Observable 的实现”首先,定义一个 variadic class template Event。variadic class template 的相关内容见第 26 章“高级模板”。这个类内部保存的是一个 map,其中存放了带 variadic 参数的 function。类提供 addObserver() 成员函数,用来注册新的 observer;observer 本质上是一个 function,会在该事件被触发时收到通知。addObserver() 会返回一个 EventHandle,之后可以把这个 handle 传给 removeObserver() 来取消注册。这个 EventHandle 本质上只是一个数字,每注册一个 observer,它就会递增一次。最后,raise() 成员函数则负责通知所有已注册 observer:该事件已经发生。
using EventHandle = unsigned int;
template <typename... Args>class Event final{ public: // Adds an observer. Returns an EventHandle to unregister the observer. [[nodiscard]] EventHandle addObserver( function<void(const Args&...)> observer) { auto number { ++m_counter }; m_observers[number] = move(observer); return number; }
// Unregisters the observer pointed to by the given handle. void removeObserver(EventHandle handle) { m_observers.erase(handle); }
// Raise event: notifies all registered observers. void raise(const Args&... args) { for (const auto& [_, callback] : m_observers) { callback(args...); } } private: unsigned int m_counter { 0 }; map<EventHandle, function<void(const Args&...)>> m_observers;};任何想对外暴露事件、供 observer 注册的类,只需要提供对应的 register / unregister 成员函数即可。由于这里用了 variadic class template,因此 Event 实例本身可以带任意数量参数。这样,observable object 在触发事件时,就能把任何相关信息一并传给 observer。示例如下:
class ObservableSubject{ public: EventHandle registerDataModifiedObserver(const auto& observer) { return m_eventDataModified.addObserver(observer); } void unregisterDataModifiedObserver(EventHandle handle) { m_eventDataModified.removeObserver(handle); }
EventHandle registerDataDeletedObserver(const auto& observer) { return m_eventDataDeleted.addObserver(observer); } void unregisterDataDeletedObserver(EventHandle handle) { m_eventDataDeleted.removeObserver(handle); }
void modifyData() { // ... m_eventDataModified.raise(1, 2.3); }
void deleteData() { // ... m_eventDataDeleted.raise(); } private: Event<int, double> m_eventDataModified; Event<> m_eventDataDeleted;};下面是一段测试代码,用来展示如何使用刚才实现好的 Observer Pattern。先假设存在一个独立的全局函数 modified(),它能处理“数据被修改”的事件:
void modified(int a, double b) { println("modified({}, {})", a, b); }再假设我们还有一个 Observer 类,它同样能够处理 modification event:
class Observer final{ public: explicit Observer(ObservableSubject& subject) : m_subject { subject } { m_subjectModifiedHandle = m_subject.registerDataModifiedObserver( [this](int i, double d) { onSubjectModified(i, d); }); }
~Observer() { m_subject.unregisterDataModifiedObserver(m_subjectModifiedHandle); } private: void onSubjectModified(int a, double b) { println("Observer::onSubjectModified({}, {})", a, b); } ObservableSubject& m_subject; EventHandle m_subjectModifiedHandle;};最后,就可以构造一个 ObservableSubject 实例,并注册若干 observer:
ObservableSubject subject;
auto handleModified { subject.registerDataModifiedObserver(modified) };auto handleDeleted { subject.registerDataDeletedObserver( []{ println("deleted"); }) };Observer observer { subject };
subject.modifyData();subject.deleteData();
println("");
subject.unregisterDataModifiedObserver(handleModified);subject.modifyData();subject.deleteData();输出如下:
modified(1, 2.3)Observer::onSubjectModified(1, 2.3)deleted
Observer::onSubjectModified(1, 2.3)deleted装饰器模式(Decorator Pattern)
Section titled “装饰器模式(Decorator Pattern)”Decorator Pattern 顾名思义,就是给一个类“加装饰”。这个 pattern 用于在运行期增强或改变某个类的行为。Decorator 在某种意义上很像派生类,但它能动态改变被装饰类的行为。代价在于:Decorator 在改变行为方面的自由度比派生类更低,因为例如某些 helper member function,Decorator 并不能直接 override。另一方面,Decorator 的最大优势在于它是 non-intrusive 的:也就是说,你无需修改底层类中的代码,就能适配它的行为。而且,Decorator 还可以非常自然地相互组合,从而精确得到你想要的功能,而不必为每种组合单独写一套派生类。
例如,假设你有一条数据流,在解析过程中遇到了一段表示图片的数据。这时,你完全可以临时用一个 ImageStream object 去装饰原有 stream object。ImageStream 的 constructor 接收那个 stream object 作为参数,并内建对图像解析的知识。图片解析完之后,你又可以继续用原来的 stream object 去解析剩余数据。在这个场景里,ImageStream 就是一个 decorator,因为它在不改变原始 object(stream)的前提下,给它加上了新的功能(image parsing)。
示例:为 Web 页面定义样式
Section titled “示例:为 Web 页面定义样式”你大概已经知道,web page 是使用一种简单的文本结构编写的,这种结构叫 HyperText Markup Language(HTML)。在 HTML 中,你可以通过 style tag 为文本添加样式,例如用 <b> 和 </b> 表示 bold,用 <i> 和 </i> 表示 italic。下面这一行 HTML 会把消息显示为 bold:
<b>A party? For me? Thanks!</b>下面这一行则会同时以 bold 和 italic 显示消息:
<i><b>A party? For me? Thanks!</b></i>HTML 中的 paragraph 则由 <p> 和 </p> 包裹,例如:
<p>This is a paragraph.</p>现在假设你正在编写一个 HTML 编辑器,用户应能输入 paragraph 文本,并为其应用一个或多个样式。你当然可以把不同样式组合都写成不同的派生类,如图 33.7 所示;但这种设计既笨重,又会随着新样式的加入而呈指数级膨胀。
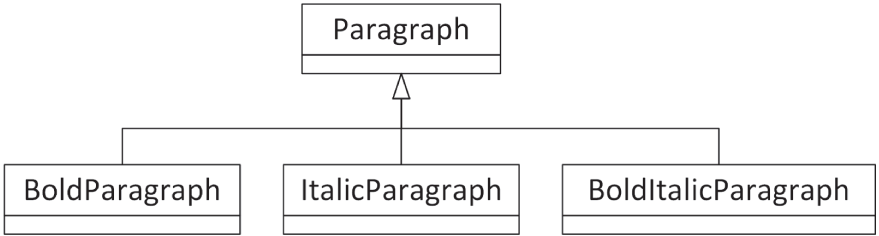
[^FIGURE 33.7]
另一种思路,是把“带样式的 paragraph”不看作 paragraph 的不同类型,而看作 paragraph 被不断装饰之后的结果。这就会形成如图 33.8 所示的结构:一个 ItalicParagraph 作用于一个 BoldParagraph,而 BoldParagraph 又作用于一个基础的 Paragraph。对象装饰的递归嵌套方式,与 HTML 中样式标签的嵌套形式恰好一致。
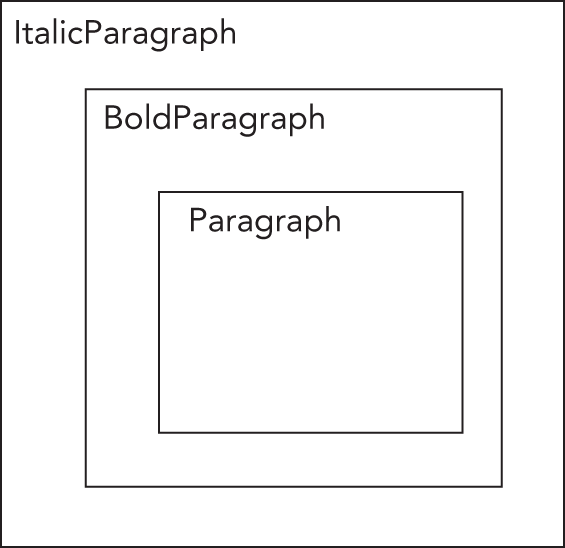
[^FIGURE 33.8]
装饰器的实现
Section titled “装饰器的实现”首先,需要定义一个 IParagraph interface:
class IParagraph{ public: virtual ~IParagraph() = default; // Always a virtual destructor! virtual std::string getHTML() const = 0;};Paragraph 类会实现这个 IParagraph interface:
class Paragraph : public IParagraph{ public: explicit Paragraph(std::string text) : m_text { std::move(text) } {} std::string getHTML() const override {return format("<p>{}</p>", m_text); } private: std::string m_text;};如果想给一个 Paragraph 加上 0 个或多个样式,那么就需要一组“可从既有 IParagraph 构造”的 styled IParagraph class。这样,它们既可以装饰一个原始 Paragraph,也可以继续装饰另一个 styled IParagraph。下面是 BoldParagraph 的实现:它派生自 IParagraph 并实现 getHTML()。关键点在于:由于它只打算用作 decorator,因此其唯一的 public 非复制构造函数接收的是 IParagraph 的 reference-to-const。
class BoldParagraph : public IParagraph{ public: explicit BoldParagraph(const IParagraph& paragraph) : m_wrapped { paragraph } { }
std::string getHTML() const override { return format("<b>{}</b>", m_wrapped.getHTML()); } private: const IParagraph& m_wrapped;};ItalicParagraph 的实现与之类似:
class ItalicParagraph : public IParagraph{ public: explicit ItalicParagraph(const IParagraph& paragraph) : m_wrapped { paragraph } { }
std::string getHTML() const override { return format("<i>{}</i>", m_wrapped.getHTML()); } private: const IParagraph& m_wrapped;};从用户视角看,Decorator Pattern 的吸引力在于:它既容易应用,又在应用后显得相当透明。一个 BoldParagraph 用起来就和一个普通 Paragraph 一样。不过需要记住的是:由于 BoldParagraph 内部只保存了对某个 IParagraph 的引用,因此如果那个 IParagraph 的文本后来被改掉了,这种变化也会自然反映到 BoldParagraph 上。
下面这个例子创建并输出一个 paragraph:先输出 bold 版本,再输出 bold+italic 版本。
Paragraph text { "A party? For me? Thanks!" };// Boldprintln("{}", BoldParagraph{text}.getHTML());// Bold and Italicprintln("{}", ItalicParagraph{BoldParagraph{text}}.getHTML());输出如下:
<b><p>A party? For me? Thanks!</p></b><i><b><p>A party? For me? Thanks!</p></b></i>责任链模式(Chain of Responsibility Pattern)
Section titled “责任链模式(Chain of Responsibility Pattern)”Chain of Responsibility 用于“让一串对象都有机会尝试执行某个动作”。这类链最常见的用法,大概就是 event handling。许多现代应用,尤其是图形界面程序,本质上都可以看作一连串 event 与 response。例如,当用户点击 File 菜单并选择 Open 时,就会触发一个 “open” event;当用户在绘图程序的可绘制区域内移动鼠标时,就会持续产生 mouse move event;如果用户按下鼠标按钮,则会触发相应的 “mouse down” event。程序随后可以开始关注后续 mouse move event,让用户“画出”某个对象,并持续到 “mouse up” event 发生为止。每个操作系统对这些 event 的命名与使用方式都不同,但整体思想是一样的:当某个 event 发生时,它会被以某种方式传播给一系列对象,由它们决定是否以及如何处理。
你可能会觉得 Chain of Responsibility Pattern 与 Decorator Pattern 有点像。但它们之间仍有明显区别。你可以把 Chain of Responsibility 看成是一种结构化的 if-else cascade:它的目标是找到“第一个匹配的处理者”。而 Decorator Pattern 的目标,则是扩展功能。
正如你知道的,C++ 本身并没有任何内建的图形编程设施,也没有“event、event 传递或 event handling”这类语言概念。Chain of Responsibility 则提供了一种非常合理的方式,让不同对象都有机会处理某些 event。
示例:事件处理
Section titled “示例:事件处理”设想一个绘图程序:应用有一个窗口,窗口中可以绘制各种形状。用户可能会在窗口中的某个位置按下鼠标按钮。一旦发生这种事,应用就应判断:用户是不是点中了某个 shape。如果点中了,那么就把 “mouse button down” event 交给该 shape 来处理;如果 shape 判断自己不需要处理这个 event,它就把 event 传给 window,让 window 获得下一次处理机会;如果 window 也不想处理,那么它再把 event 转发给 application 本身——也就是责任链中的最后一个处理者。之所以叫 Chain of Responsibility,就是因为链中的每一个 handler 都可以选择:要么自己处理 event,要么把它交给链条中的下一个 handler。
责任链的实现
Section titled “责任链的实现”首先,假设所有可能的 event 都定义在这样一个 enumeration 里:
enum class Event { LeftMouseButtonDown, LeftMouseButtonUp, RightMouseButtonDown, RightMouseButtonUp };接下来,定义如下的 Handler base class:
class Handler{ public: virtual ~Handler() = default; // Omitted defaulted default ctor, copy/move ctor, copy/move assignment op. explicit Handler(Handler* nextHandler) : m_nextHandler { nextHandler } { } virtual void handleMessage(Event message) = 0; protected: void nextHandler(Event message) { if (m_nextHandler) { m_nextHandler->handleMessage(message); } } private: Handler* m_nextHandler { nullptr };};然后,Application、Window 和 Shape 这三个类作为 concrete handler,都派生自 Handler。在这个例子中,Application 只处理 RightMouseButtonDown,Window 只处理 LeftMouseButtonUp,而 Shape 只处理 LeftMouseButtonDown。如果某个 handler 收到的是自己不认识的消息,它就把该消息传给链中的下一个 handler。
class Application : public Handler{ public: explicit Application(Handler* nextHandler) : Handler { nextHandler } { }
void handleMessage(Event message) override { println("Application::handleMessage()"); if (message == Event::RightMouseButtonDown) { println(" Handling message RightMouseButtonDown"); } else { nextHandler(message); } }};
class Window : public Handler{ public: explicit Window(Handler* nextHandler) : Handler { nextHandler } { }
void handleMessage(Event message) override { println("Window::handleMessage()"); if (message == Event::LeftMouseButtonUp) { println(" Handling message LeftMouseButtonUp"); } else { nextHandler(message); } }};
class Shape : public Handler{ public: explicit Shape(Handler* nextHandler) : Handler { nextHandler } { }
void handleMessage(Event message) override { println("Shape::handleMessage()"); if (message == Event::LeftMouseButtonDown) { println(" Handling message LeftMouseButtonDown"); } else { nextHandler(message); } }};上一节实现的责任链,可以按下面这样进行测试:
Application application { nullptr };Window window { &application };Shape shape { &window };
shape.handleMessage(Event::LeftMouseButtonDown);println("");
shape.handleMessage(Event::LeftMouseButtonUp);println("");
shape.handleMessage(Event::RightMouseButtonDown);println("");
shape.handleMessage(Event::RightMouseButtonUp);输出如下:
Shape::handleMessage() Handling message LeftMouseButtonDown
Shape::handleMessage()Window::handleMessage() Handling message LeftMouseButtonUp
Shape::handleMessage()Window::handleMessage()Application::handleMessage() Handling message RightMouseButtonDown
Shape::handleMessage()Window::handleMessage()Application::handleMessage()当然,在真实应用中,还必须有某个其他类负责把 event dispatch 给正确对象,也就是调用正确对象上的 handleMessage()。由于这项任务高度依赖所用 framework 或平台,下面只能给出一段 pseudo-code,用来说明“如何处理一次左键按下事件”:
MouseLocation location { getMouseLocation() };Shape* clickedShape { findShapeAtLocation(location) };if (clickedShape) { clickedShape->handleMessage(Event::LeftMouseButtonDown);} else { window.handleMessage(Event::LeftMouseButtonDown);}这种链式结构在 object-oriented hierarchy 中非常灵活,而且也有不错的结构美感。缺点则在于:它高度依赖程序员的严谨。如果某个类忘记把消息传给下一个 handler,那么 event 就等于悄悄丢失了。更糟的是,如果你把它传给了错误对象,甚至可能直接进入无限循环!
单例模式(Singleton Pattern)
Section titled “单例模式(Singleton Pattern)”Singleton Pattern 是最简单的 design pattern 之一。英语里 singleton 的意思是“独一无二的个体”或“唯一对象”,在编程里它也基本就是这个含义。Singleton Pattern 的目标,是在整个程序中强制某个类恰好只存在一个实例。只要把一个类设计成 singleton,就意味着该类在程序运行期间只会被创建出一个对象。同时,这个唯一对象还应当可以从程序任意位置被全局访问。程序员通常会把遵循 Singleton Pattern 的类直接称为 singleton class。
如果你的程序依赖“某个类在全局范围内只能有一个实例”这一假设,那么确实可以用 Singleton Pattern 来强制这个假设。在 C++ 里,从技术上说,你也可以完全用 global variable 加一组 namespace 级 free function 来达成类似效果;但在 Java 这类语言中,本来就没有 global variable 这一概念。
不过,Singleton Pattern 有不少缺点,你必须非常清楚。首先,如果系统中存在多个 singleton,那么在程序启动时让它们按正确顺序完成初始化,并不容易;程序关闭时,也同样很难保证调用方还没来得及用它时,它却已经不在了。除此之外,singleton class 还会引入隐藏依赖、加剧紧耦合,并让 unit testing 变得麻烦。比如,在 unit test 中,你可能很想为一个访问网络或数据库的 singleton 提供 mock 版本(见第 30 章“精通测试”);但按照典型 singleton 的实现方式,这件事往往并不好做。
更合适的模式,通常是本章前面已经讨论过的 Strategy Pattern。采用 Strategy Pattern 时,你会为每一类服务都定义 interface,并把所需服务的 interface 注入给具体 component。这样就很容易切换到不同实现,也天然有利于在 unit testing 中注入 mock / stub。尽管如此,本章仍然讨论 Singleton Pattern,因为你在现实中——尤其是在 legacy code base 中——几乎一定会遇到它。
由于 Singleton Pattern 存在诸多问题,因此在新代码中应尽量避免使用它。优先选择其他 pattern,例如 Strategy Pattern。
示例:日志机制
Section titled “示例:日志机制”很多应用里都有 logger 的概念:也就是一个负责把状态信息、调试数据和错误统一写到某个中心位置的类。一个 logging class 往往具备以下特征:
- 它始终可用
- 它很容易使用
- 它只有一个实例
从表面看,Singleton Pattern 似乎非常适合满足这些需求。不过还是那句话:在新代码中,我仍然建议尽量不要主动引入新的 singleton。
在 C++ 中,实现 singleton 行为大体有两种办法。第一种,是写一个只包含 static 成员函数的类。这样的类不需要被实例化,并且可以在程序任意位置被访问。问题在于:这种做法并没有内建的 constructor / destructor 机制;而且从严格意义上说,一个“只有静态成员函数的类”其实并不是真正的 Singleton Pattern,而更接近 monostate pattern。也就是说,这样的类虽然可以创建多个实例,但状态只有一份;而 singleton 一词真正强调的是:这个类的实例恰好只有一个。关于 monostate,本节不再展开。
第二种实现方式,则是结合使用访问控制级别与 static 关键字,从而真正控制“只允许存在唯一实例”,这才是真正的 singleton。下面就以一个 Logger 类为例说明。这一版 Logger 提供的功能,与本章前面那个基于 Strategy 的 Logger 大致类似。
要在 C++ 中构建一个真正的 singleton,可以借助访问控制和 static 机制。运行期确实会存在一个真实的 Logger instance,而这个类本身会强制:只允许被实例化一次。client 永远都可以通过一个名为 instance() 的 static 成员函数,拿到这唯一实例。类定义如下:
export class Logger final{ public: enum class LogLevel { Debug, Info, Error };
// Sets the name of the log file. // Note: needs to be called before the first call to instance()! static void setLogFilename(std::string logFilename);
// Returns a reference to the singleton Logger object. static Logger& instance();
// Prevent copy/move construction. Logger(const Logger&) = delete; Logger(Logger&&) = delete;
// Prevent copy/move assignment operations. Logger& operator=(const Logger&) = delete; Logger& operator=(Logger&&) = delete;
// Sets the log level. void setLogLevel(LogLevel level);
// Logs a single message at the given log level. void log(std::string_view message, LogLevel logLevel); private: // Private constructor and destructor. Logger(); ~Logger();
// Converts a log level to a human-readable string. std::string_view getLogLevelString(LogLevel level) const;
static inline std::string ms_logFilename; std::ofstream m_outputStream; LogLevel m_logLevel { LogLevel::Error };};这个实现采用的是 Scott Meyers 风格的 singleton。也就是说,instance() 成员函数内部会保存一个局部 static 的 Logger 实例。C++ 保证这个局部 static 会以 thread-safe 的方式完成初始化,因此你在这种 singleton 实现里不需要手动做线程同步。这类对象也常被叫作 magic static 或 thread-safe static local variable。不过要注意:只有初始化本身是 thread-safe 的!如果多个线程接下来还要继续调用 Logger 上的成员函数,那么你依然必须让这些成员函数自身也是 thread-safe 的。相关同步机制可见第 27 章“使用 C++ 进行多线程编程”。
Logger 的实现本身很直接。日志文件一旦打开,每条日志消息就会在前面加上时间戳和 log level,然后写入文件,并立刻 flush 到磁盘。constructor 与 destructor 都会在 instance() 内部那个 static Logger 实例被创建和销毁时自动调用。由于 constructor 和 destructor 都是 private 的,因此任何外部代码都无法自行创建或删除一个 Logger。
下面是 setLogFilename()、instance()、constructor 和 destructor 的实现。其余成员函数与本章前面 Strategy-Based Logger 的实现相同。
void Logger::setLogFilename(string logFilename){ ms_logFilename = move(logFilename); }
Logger& Logger::instance(){ static Logger instance; // Thread-safe static local variable. return instance;}
Logger::Logger(){ m_outputStream.open(ms_logFileName, ios_base::app); if (!m_outputStream.good()) { throw runtime_error { "Unable to initialize the Logger!" }; } println(m_outputStream, "{}: Logger started.", chrono::system_clock::now());}
Logger::~Logger(){ println(m_outputStream, "{}: Logger stopped.", chrono::system_clock::now()); }singleton 版 Logger 可以按下面这样测试:
// Set the log filename before the first call to instance().Logger::setLogFilename("log.out");// Set log level to Debug.Logger::instance().setLogLevel(Logger::LogLevel::Debug);// Log some messages.Logger::instance().log("test message", Logger::LogLevel::Debug);// Set log level to Error.Logger::instance().setLogLevel(Logger::LogLevel::Error);// Now that the log level is set to Error, logging a Debug// message will be ignored.Logger::instance().log("A debug message", Logger::LogLevel::Debug);执行完成后,文件 log.out 中会包含如下内容:
2023-08-12 17:36:15.1370238: Logger started.2023-08-12 17:36:15.1372522: [DEBUG] test message2023-08-12 17:36:15.1373057: Logger stopped.本章让你初步体会了 design pattern 如何帮助你把 object-oriented 概念组织成更高层的设计。Wikipedia 上收录并讨论了大量 design pattern(en.wikipedia.org/wiki/Software_design_pattern)。pattern 的数量非常多,很容易让人迷失方向。因此,我建议你先专注于少数几个真正引起你兴趣的 pattern,慢慢把自己的 pattern 工具箱建立起来。
我想用下面这句引用来结束本章,它很好地表达了我们为什么要使用 pattern:
The use of [design patterns] provides us in our daily lives with decisive speed advantages for understanding complex structures. This is also why patterns found their way into software development years ago… Consistently applied patterns help us deal with the complexity of source code.
CAROLA LILIENTHAL, SOFTWARE ARCHITECTURE METRICS, O’REILLY MEDIA
通过完成下面这些练习,你可以巩固本章讨论的内容。所有练习的参考解答都包含在本书网站 www.wiley.com/go/proc++6e 提供的代码下载包中。不过,如果你在某道题上卡住了,建议先回过头重读本章相关部分,尽量自己找到答案,再去看网站上的解答。
本章练习与其他章节略有不同。下面这些练习会简要引入一些新 pattern,并要求你自己去查阅和研究,以进一步理解它们。
- 练习 33-1: 虽然本章已经讨论了一些不错的 pattern,但当然还有更多模式可学。其中一个例子就是 command pattern。它会把一个操作或一组操作封装进对象中。这个 pattern 的一个重要 use case,是实现可撤销操作。请使用附录 B“带注释的参考书目”中的 pattern 资料,去查阅和学习 command pattern;或者,你也可以从 Wikipedia 上的
en.wikipedia.org/wiki/Software_design_pattern开始调查。 - 练习 33-2: 另一个 pattern 是 facade pattern。在这个 pattern 中,你会提供一个更高层、也更易使用的 interface,以屏蔽某个 subsystem 的复杂性,从而让 subsystem 更容易被使用。请自行研究 facade pattern。
- 练习 33-3: Prototype pattern 的思路是:通过构造一组 prototype instance,来指定各种可被创建的对象类型。这些 prototype 通常会被注册在某种 registry 中。随后,client 可以向 registry 请求某一类对象的 prototype,再对其进行 clone,以供后续使用。请自行研究 prototype pattern。
- 练习 33-4: Mediator pattern 用于控制一组对象之间的交互。它强调让不同 subsystem 之间保持 loose coupling。请自行研究 mediator pattern。