标准库容器
本章作为标准库深度探索章节之一,主要介绍可用的容器。它将解释不同的容器及其分类,以及它们之间的权衡。某些容器会比其他容器讨论得更详细。一旦你学会了如何使用某一类中的一个容器,使用同类中的其他容器就不会有任何问题。有关所有容器所有成员函数的完整参考,请查阅你喜欢的标准库参考资料。
标准库中的容器是通用的数据结构,对于存储数据集合非常有用。当你使用标准库时,几乎不需要使用标准的 C 风格数组、编写链表或设计栈。这些容器是以类模板的形式实现的,因此你可以为任何满足下一节所述基本条件的类型实例化它们。除 array 和 bitset 外,大多数标准库容器的大小都是灵活的,可以自动增长或缩小以容纳更多或更少的元素。与固定大小的旧式 C 风格数组相比,这是一个巨大的优势。由于 C 风格数组的固定大小特性,它们更容易受到越界访问的影响,在最简单的情况下,这仅仅会因为数据损坏而导致程序崩溃,但在最坏的情况下,可能会导致某些类型的安全攻击。通过使用标准库容器,你可以确保你的程序不易受到这类问题的影响。
第 16 章“C++ 标准库概述”对标准库提供的不同容器、容器适配器和序列视图进行了高层概述。下表对其进行了总结。
- 序列容器 - vector (动态数组) - deque - list - forward_list - array - 序列视图 - span - mdspan - 容器适配器 - queue - priority_queue - stack | - 有序关联容器 - map / multimap - set / multiset - 无序关联容器或哈希表 - unordered_map / unordered_multimap - unordered_set / unordered_multiset - 平面 set 和平面 map 关联容器适配器 - flat_map / flat_multimap - flat_set / flat_multiset |
此外,C++ string 和流在某种程度上也可以用作标准库容器,而 bitset 可用于存储固定数量的位。
标准库中的所有内容都在 std 命名空间中。一如既往,本书中的示例通常在源文件中使用通用的 using namespace std; 指令(切勿在头文件中使用!),但在你自己的程序中,你可以更有针对性地选择使用 std 中的哪些符号。
对元素的要求
Section titled “对元素的要求”标准库容器对元素使用值语义。也就是说,它们存储所给元素的副本,使用赋值运算符对元素进行赋值,并使用析构函数销毁元素。因此,当你编写打算与标准库一起使用的类时,需要确保它们是可拷贝的。当从容器请求元素时,会返回所存副本的引用。
如果你更喜欢引用语义,可以存储指向元素的指针,而不是元素本身。当容器拷贝指针时,结果仍然指向同一个元素。另一种方法是在容器中存储 std::reference_wrapper。reference_wrapper 的存在基本上是为了使引用可拷贝,可以使用 std::ref() 和 cref() 辅助函数来创建。reference_wrapper 类模板以及 ref() 和 cref() 函数模板定义在 <functional> 中。本章稍后的“在 vector 中存储引用”一节给出了相关的示例。
可以在容器中存储仅移动(move-only)类型,即不可拷贝类型,但这样做时,容器上的某些操作可能无法通过编译。仅移动类型的一个例子是 std::unique_ptr。
如果你需要在容器中存储指针,如果可能的话,如果容器成为所指对象的所有者,请使用 unique_ptr;如果容器与其他所有者共享所有权,请使用 shared_ptr。不要在容器中使用已过时且被移除的 auto_ptr 类,因为它没有正确实现拷贝。
标准库容器的模板类型参数之一是分配器(allocator)。容器使用此分配器为元素分配和释放内存。分配器类型参数具有默认值,因此你几乎总是可以直接忽略它。例如,vector 类模板如下所示:
template <typename T, typename Allocator = std::allocator<T>> class vector;某些容器(如 map)还接受一个比较器(comparator)作为模板类型参数之一。此比较器用于对元素进行排序。它也有默认值,因此你不必总是指定它。默认值是使用 operator< 比较元素。map 类模板如下所示:
template <typename Key, typename T, typename Compare = std::less<Key>, typename Allocator = std::allocator<std::pair<const Key, T>>> class map;分配器和比较器模板类型参数都将在本章稍后详细讨论。
使用默认分配器和默认比较器的容器对元素的具体要求如下表所示:
| 成员函数 | 说明 | 备注 |
|---|---|---|
| 拷贝构造函数 | 创建一个与旧元素“相等”的新元素,但该新元素可以被安全地销毁而不影响旧元素。 | 每次插入元素时都会使用,除非使用 emplace 成员函数(稍后讨论)。 |
| 移动构造函数 | 通过将源元素的所有内容移动到新元素来创建一个新元素。 | 当源元素是右值时使用,并且在构造新元素后将被销毁;在 vector 扩容时也会使用。移动构造函数应该是 noexcept 的;否则,它将不会被使用! |
| 赋值运算符 | 用源元素的副本替换元素的内容。 | 每次修改元素时都会使用。 |
| 移动赋值运算符 | 通过从源元素移动所有内容来替换元素的内容。 | 当源元素是右值且在赋值操作后将被销毁时使用。移动赋值运算符应该是 noexcept 的;否则,它将不会被使用! |
| 析构函数 | 清理元素。 | 每次移除元素或 vector 扩容时都会使用。 |
| 默认构造函数 | 不带任何参数构造元素。 | 仅对某些操作是必需的,例如带一个参数的 vector::resize() 成员函数和 map::operator[] 访问。 |
operator== | 比较两个元素是否相等。 | 对无序关联容器中的键是必需的,对于某些操作(如两个容器上的 operator==)也是必需的。 |
operator< | 确定一个元素是否小于另一个元素。 | 对有序关联容器和平面关联容器适配器中的键是必需的,对于某些操作(如两个容器上的 operator<)也是必需的。 |
operator>, <=, >=, != | 比较两个元素。 | 在比较两个容器时是必需的。 |
第 9 章“精通类与对象”解释了如何编写这些成员函数。
标准库容器经常移动或拷贝元素。因此,为了获得最佳性能,请确保存储在容器中的对象类型支持移动语义,请参见第 9 章。如果无法使用移动语义,请确保拷贝构造函数和拷贝赋值运算符尽可能高效。
异常与错误检查
Section titled “异常与错误检查”标准库容器提供的错误检查有限。客户端应确保其用法有效。然而,某些容器成员函数在某些情况下会抛出异常,例如越界索引。当然,不可能详尽地列出这些成员函数可能抛出的异常,因为它们对具有未知异常特性的用户指定类型执行操作。本章会在适当的地方提及异常。有关每个成员函数可能抛出的异常列表,请查阅标准库参考资料(见附录 B“带注释的参考书目”)。
vector、deque、list、forward_list 和 array 被称为序列容器(sequential containers),因为它们存储元素的序列。学习序列容器的最佳方法是从 vector 容器的示例开始,它也应该是你的默认容器。下一节详细介绍 vector 容器,随后简要讨论 deque、list、forward_list 和 array。一旦你熟悉了序列容器,在它们之间切换就易如反掌了。
vector
Section titled “vector”标准库 vector 容器类似于标准的 C 风格数组:元素存储在连续的内存中,每个元素都有自己的“槽位”。你可以对 vector 进行索引,也可以在末尾添加新元素或在其他任何地方插入元素。向 vector 中插入和从中删除元素通常需要线性时间,不过在本章稍后的“vector 内存分配方案”一节中会解释,在 vector 末尾执行这些操作实际上运行在均摊常数(amortized constant)时间内。随机访问单个元素具有常数复杂度;有关算法复杂度的讨论,请参阅第 4 章“设计专业的 C++ 程序”。
vector 概述
Section titled “vector 概述”vector 定义在 <vector> 中,是一个带有两个类型参数的类模板:要存储的元素类型和分配器类型:
template <typename T, typename Allocator = allocator<T>> class vector;Allocator 参数指定了内存分配器对象的类型,客户端可以设置该对象以使用自定义内存分配。此模板参数具有默认值。
std::vector 是 constexpr 的(见第 9 章),就像 std::string 一样。这意味着 vector 可用于在编译时执行操作,并可用于 constexpr 函数和其他 constexpr 类的实现中。
固定长度的 vector
Section titled “固定长度的 vector”使用 vector 的一种方式是将其作为固定长度的数组。vector 提供了一个允许你指定元素数量的构造函数,并提供了一个重载的 operator[] 来访问和修改这些元素。当 operator[] 用于访问 vector 边界之外的元素时,其结果是未定义的。这意味着编译器可以决定在这种情况下如何表现。例如,Microsoft Visual C++ 的默认行为是:当程序以调试模式编译时给出运行时错误消息,而为了性能原因,在发布模式下禁用任何边界检查。你可以更改这些默认行为。
与“真正的”数组索引一样,vector 上的 operator[] 不提供边界检查。
除了使用 operator[] 之外,还可以通过 at()、front() 和 back() 访问 vector 元素。at() 成员函数与 operator[] 相同,不同之处在于它执行边界检查,如果索引越界则抛出 out_of_range 异常。front() 和 back() 分别返回对 vector 第一个和最后一个元素的引用。在空容器上调用 front() 或 back() 会触发未定义行为。
下面是一个简单的示例程序,用于“归一化”测试分数,使最高分设定为 100,其他所有分数相应调整。该程序创建一个包含 10 个 double 的 vector,从用户处读取 10 个值,将每个值除以最高分(再乘以 100),并打印出新值。为了创建这个 vector,使用了圆括号 (10) 而不是统一初始化 {10},因为后者会创建一个仅包含一个值为 10 的元素的 vector。为了简洁起见,该程序省去了错误检查。
vector<double> doubleVector(10); // 创建一个包含 10 个 double 的 vector。
// 将 max 初始化为最小的数。double max { -numeric_limits<double>::infinity() };
for (size_t i { 0 }; i < doubleVector.size(); ++i) { print("Enter score {}: ", i + 1); cin >> doubleVector[i]; if (doubleVector[i]> max) { max = doubleVector[i]; }}
max /= 100.0;for (auto& element : doubleVector) { element /= max; print("{} ", element);}正如你从这个例子中看到的,你可以像使用标准 C 风格数组一样使用 vector。请 note,第一个 for 循环使用 size() 成员函数来确定容器中的元素数量。这个例子还演示了在 vector 上使用基于范围的 for 循环。这里,基于范围的 for 循环使用 auto& 而不是 auto,因为需要引用以便在每次迭代中修改实际元素。
动态长度的 vector
Section titled “动态长度的 vector”vector 的真正威力在于它能够动态增长。例如,考虑前一节中的测试分数归一化程序,增加一个要求:它应该能处理任意数量的测试分数。这是新版本:
vector<double> doubleVector; // 创建一个零元素的 vector。
// 将 max 初始化为最小的数。double max { -numeric_limits<double>::infinity() };
for (size_t i { 1 }; true; ++i) { double value; print("Enter score {} (-1 to stop): ", i); cin >> value; if (value == -1) { break; } doubleVector.push_back(value); if (value > max) { max = value; }}
max /= 100.0;for (auto& element : doubleVector) { element /= max; print("{} ", element);}这个版本的程序使用默认构造函数创建一个零元素的 vector。当读取每个分数时,使用 push_back() 成员函数将其添加到 vector 的末尾,该函数负责为新元素分配空间。基于范围的 for 循环不需要任何更改。
Section titled “ 格式化与打印 Vector”从 C++23 开始,std::format() 和 print() 函数可以用一条语句格式化和打印整个容器。这适用于所有标准库序列容器、容器适配器和关联容器,并在第 2 章“使用字符串和字符串视图”中进行了介绍。示例如下:
vector values { 1.1, 2.2, 3.3 };println("{}", values); // 打印如下:[1.1, 2.2, 3.3]你可以指定 n 格式说明符以省略周围的方括号:
println("{:n}", values); // 打印如下:1.1, 2.2, 3.3如果你的编译器尚不支持此功能,你可以使用基于范围的 for 循环来遍历 vector 的元素并打印它们,例如:
for (const auto& value : values) { std::cout << value << ", "; }vector 详解
Section titled “vector 详解”现在你已经初步了解了 vector,是时候深入研究它们的细节了。
构造函数与析构函数
Section titled “构造函数与析构函数”默认构造函数创建一个零元素的 vector。
vector<int> intVector; // 创建一个零元素的 int vector你可以指定元素数量,并可选地为这些元素指定一个值,如下所示:
vector<int> intVector(10, 100); // 创建一个包含 10 个值为 100 的 int 的 vector如果省略默认值,新对象将进行零初始化(zero-initialized)。零初始化使用默认构造函数构造对象,并将原始整数类型(如 char、int 等)初始化为零,将原始浮点类型初始化为 0.0,将指针类型初始化为 nullptr。
你可以像这样创建内置类的 vector:
vector<string> stringVector(10, "hello");用户定义的类也可以用作 vector 元素:
class Element { };…vector<Element> elementVector;可以使用包含初始元素的 initializer_list 来构造 vector:
vector<int> intVector({ 1, 2, 3, 4, 5, 6 });第 1 章“C++ 与标准库速成”中讨论的统一初始化适用于大多数标准库容器,包括 vector。示例如下:
vector<int> intVector = { 1, 2, 3, 4, 5, 6 };vector<int> intVector { 1, 2, 3, 4, 5, 6 };得益于类模板参数推导(CTAD),你可以省略模板类型参数。示例如下:
vector intVector { 1, 2, 3, 4, 5, 6 };不过,使用统一初始化时要小心;通常,在调用对象的构造函数时,可以使用统一初始化语法。示例如下:
string text { "Hello World." };对于 vector,你需要小心。例如,以下代码行调用 vector 构造函数来创建一个包含 10 个值为 100 的整数的 vector:
vector<int> intVector(10, 100); // 创建一个包含 10 个值为 100 的 int 的 vector如果在这里改用如下的统一初始化,则不会创建一个包含 10 个整数的 vector,而是一个仅包含两个元素(初始化为 10 和 100)的 vector:
vector<int> intVector { 10, 100 }; // 创建一个包含两个元素 10 和 100 的 vector你也可以在自由存储区(堆)上分配 vector:
auto elementVector { make_unique<vector<Element>>(10) };拷贝与赋值 Vector
Section titled “拷贝与赋值 Vector”vector 存储对象的副本,其析构函数会调用每个对象的析构函数。vector 类的拷贝构造函数和赋值运算符对 vector 中的所有元素执行深拷贝。因此,为了效率,你应该通过非 const 引用或 const 引用将 vector 传递给函数,而不是通过值传递。
除了正常的拷贝和赋值之外,vector 还提供了一个 assign() 成员函数,它会移除所有当前元素并添加任意数量的新元素。如果你想复用一个 vector,这个成员函数很有用。下面是一个简单的例子。intVector 创建时有 10 个默认值为 0 的元素。然后使用 assign() 移除所有 10 个元素,并将其替换为 5 个值为 100 的元素:
vector<int> intVector(10);println("intVector: {:n}", intVector); // 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…intVector.assign(5, 100);println("intVector: {:n}", intVector); // 100, 100, 100, 100, 100assign() 也可以像下面这样接受一个 initializer_list。在执行此语句后,intVector 具有四个给定值的元素:
intVector.assign({ 1, 2, 3, 4 });println("intVector: {:n}", intVector); // 1, 2, 3, 4vector 提供了一个 swap() 成员函数,允许你在常数时间内交换两个 vector 的内容。下面是一个简单的例子:
vector<int> vectorOne(10);vector<int> vectorTwo(5, 100);println("vectorOne: {:n}", vectorOne); // 0, 0, 0, 0, 0, 0, 0, 0, 0, 0println("vectorTwo: {:n}", vectorTwo); // 100, 100, 100, 100, 100
vectorOne.swap(vectorTwo);
println("vectorOne: {:n}", vectorOne); // 100, 100, 100, 100, 100println("vectorTwo: {:n}", vectorTwo); // 0, 0, 0, 0, 0, 0, 0, 0, 0, 0比较 Vector
Section titled “比较 Vector”标准库为 vector 提供了常用的六个重载比较运算符:==、!=、<、>、<=、>=。如果两个 vector 具有相同数量的元素,并且两个 vector 中所有对应的元素都彼此相等,则这两个 vector 相等。两个 vector 按词法(lexicographically)进行比较;也就是说,如果第一个 vector 中从 0 到 i-1 的所有元素都等于第二个 vector 中从 0 到 i-1 的对应元素,但第一个中的元素 i 小于第二个中的元素 i,则第一个 vector “小于”第二个 vector,其中 i 必须在 0...n 范围内,且 n 必须小于两个 vector 中较小者的 size()。
下面是一个比较 int vector 的程序示例:
vector<int> vectorOne(10);vector<int> vectorTwo(10);
if (vectorOne == vectorTwo) { println("equal!"); }else { println("not equal!"); }
vectorOne[3] = 50;
if (vectorOne < vectorTwo) { println("vectorOne is less than vectorTwo"); }else { println("vectorOne is not less than vectorTwo"); }该程序的输出如下:
equal!vectorOne is not less than vectorTwovector 迭代器
Section titled “vector 迭代器”第 17 章“理解迭代器与 Ranges 库”解释了容器迭代器的概念。那里的讨论可能有点抽象,所以先看一个代码例子会很有帮助。下面是本章前面的测试分数归一化程序的最后一个 for 循环:
for (auto& element : doubleVector) { element /= max; print("{} ", element);}这个循环可以使用迭代器而不是基于范围的 for 循环重写如下:
for (vector<double>::iterator iter { begin(doubleVector) }; iter != end(doubleVector); ++iter) { *iter /= max; print("{} ", *iter);}首先,看一看 for 循环的初始化语句:
vector<double>::iterator iter { begin(doubleVector) };回想一下,每个容器都定义了一个名为 iterator 的类型,用于表示该类容器的迭代器。begin() 返回一个该类型的迭代器,指向容器中的第一个元素。因此,初始化语句在变量 iter 中获取了一个指向 doubleVector 第一个元素的迭代器。接下来,看 for 循环的比较部分:
iter != end(doubleVector);这条语句只是检查迭代器是否已经越过了 vector 中元素序列的末尾。当到达该点时,循环终止。在这类语句中请始终使用 operator!= 而非 operator<,因为并非所有类型的迭代器都支持后者;详见第 17 章。
递增语句 ++iter 递增迭代器,使其指向 vector 中的下一个元素。
for 循环体包含这两行:
*iter /= max;print("{} ", *iter);如你所见,你的代码既可以访问也可以修改它所遍历的元素。第一行使用 operator* 对 iter 进行解引用以获取它所指向的元素,并对该元素进行赋值。第二行再次对 iter 进行解引用,但这次只是为了将元素打印到标准输出控制台。
前面的使用迭代器的 for 循环可以通过使用 auto 关键字来简化:
for (auto iter { begin(doubleVector) }; iter != end(doubleVector); ++iter) { *iter /= max; print("{} ", *iter);}使用 auto 后,编译器会根据初始化器的右侧自动推导变量 iter 的类型,在本例中就是 begin() 调用的结果。
vector 支持以下用于获取迭代器的成员函数:
begin()和end()返回分别指向第一个和最后一个元素之后位置的迭代器。rbegin()和rend()返回分别指向最后一个和第一个元素之前位置的反向迭代器。cbegin()、cend()、crbegin()和crend()返回const迭代器。
访问对象元素的字段
Section titled “访问对象元素的字段”如果容器的元素是对象,你可以对迭代器使用 -> 运算符来调用这些对象的成员函数或访问其数据成员。例如,以下程序创建了一个包含 10 个 string 的 vector,然后遍历所有字符串,并向每个字符串追加一个新字符串:
vector<string> stringVector(10, "hello");for (auto it { begin(stringVector) }; it != end(stringVector); ++it) { it->append(" there");}通常,使用基于范围的 for 循环会产生更优雅的代码,如本例所示:
for (auto& str : stringVector) { str.append(" there");}const_iterator
Section titled “const_iterator”普通的 iterator 是可读写的。但是,如果你在 const 对象上调用 begin() 或 end(),或者调用 cbegin() 或 cend(),你将收到一个 const_iterator。const_iterator 是只读的;你不能修改它所指向的元素。iterator 总是可以转换为 const_iterator,因此写成下面这样总是安全的:
vector<type>::const_iterator it { begin(myVector) };但是,const_iterator 不能转换为 iterator。如果 myVector 是 const 的,则以下行将无法编译:
vector<type>::iterator it { begin(myVector) };当使用 auto 关键字时,使用 const_iterator 看起来会略有不同。假设你编写以下代码:
vector<string> stringVector(10, "hello");for (auto iter { begin(stringVector) }; iter != end(stringVector); ++iter) { println("{}", *iter);}由于使用了 auto 关键字,编译器会自动推导 iter 变量的类型,并使其成为普通的 iterator,因为 stringVector 不是 const 的。如果你想在结合使用 auto 的同时获得只读的 const_iterator,那么你需要使用 cbegin() 和 cend() 而不是 begin() 和 end(),如下所示:
for (auto iter { cbegin(stringVector) }; iter != cend(stringVector); ++iter) { println("{}", *iter);}现在,编译器会将 const_iterator 用作变量 iter 的类型,因为这正是 cbegin() 的返回值。
基于范围的 for 循环也可以被强制使用 const 迭代器,如下所示:
for (const auto& element : stringVector) { println("{}", element);}迭代器安全性
Section titled “迭代器安全性”通常,迭代器与指针一样安全——也就是说,极度不安全。例如,你可以编写如下代码:
vector<int> intVector;auto iter { end(intVector) };*iter = 10; // Bug!iter 指向的不是有效元素。请记住,end() 返回的迭代器位于 vector 末尾之后的一个位置,而不是指向最后一个元素的迭代器!尝试对其进行解引用会导致未定义行为。迭代器不强制要求执行任何验证。
如果使用不匹配的迭代器,可能会出现另一个问题。例如,以下 for 循环使用来自 vectorTwo 的迭代器初始化 iter,并尝试将其与 vectorOne 的结束迭代器进行比较。不用说,这个循环不会按你预想的那样工作,并且可能永远不会终止。在循环中对迭代器进行解引用可能会产生未定义的结果。
vector<int> vectorOne(10);vector<int> vectorTwo(10);// 错误!可能导致死循环。for (auto iter { begin(vectorTwo) }; iter != end(vectorOne); ++iter) { /* … */ }其他迭代器操作
Section titled “其他迭代器操作”vector 迭代器是随机访问的,这意味着你可以前后移动它,或者随意跳跃。例如,以下代码最终将第五个元素(索引为 4)修改为值 4:
vector<int> intVector(10);auto it { begin(intVector) };it += 5;--it;*it = 4;迭代器 vs. 索引
Section titled “迭代器 vs. 索引”既然你可以编写一个使用简单索引变量和 size() 成员函数的 for 循环来遍历 vector 的元素,那为什么还要费心使用迭代器呢?这是一个很好的问题,主要有三个答案:
- 迭代器允许你在容器的任何位置插入和删除元素或元素序列。请参阅本章稍后的“添加和删除元素”一节。
- 迭代器允许你使用标准库算法,这些算法将在第 20 章“精通标准库算法”中讨论。
- 使用迭代器按顺序访问每个元素通常比通过索引逐个检索元素更高效。这种概括对于
vector并不成立,但适用于list、map和set。
在 vector 中存储引用
Section titled “在 vector 中存储引用”如本章前面所述,可以在容器(如 vector)中存储引用。为此,你需要在容器中存储 std::reference_wrapper。std::ref() 和 cref() 函数模板用于创建非 const 和 const 的 reference_wrapper 实例。get() 成员函数用于获取对 reference_wrapper 所包装对象的访问。所有这些都定义在 <functional> 中。示例如下:
string str1 { "Hello" };string str2 { "World" };
// 创建一个字符串引用的 vector。vector<reference_wrapper<string>> vec { ref(str1) };vec.push_back(ref(str2)); // push_back() 同样适用。
// 修改 vector 中第二个引用所指向的字符串。vec[1].get() += "!";
// 最终结果是 str2 被修改。println("{} {}", str1, str2);添加和删除元素
Section titled “添加和删除元素”如你所知,可以使用 push_back() 成员函数在 vector 末尾追加元素。vector 提供了一个对应的移除成员函数,称为 pop_back()。
pop_back() 不返回被移除的元素。如果你想要那个元素,必须先通过 back() 获取它。
你还可以使用 insert() 成员函数在 vector 的任何位置插入元素,它会在迭代器指定的位置添加一个或多个元素,并将所有后续元素后移以腾出空间。insert() 有五个不同的重载,分别执行以下操作:
-
插入单个元素。
-
插入单个元素的 n 个副本。
-
插入一个迭代器范围内的元素。请记住,迭代器范围是半开的,即包含起始迭代器指向的元素,但不包含终止迭代器指向的元素。
-
通过移动语义将给定元素移动到
vector中来插入单个元素。 -
将一个列表中的元素插入
vector,该列表以initializer_list形式给出。
assign_range() 用于将 vector 中的所有元素替换为给定范围的元素;insert_range() 用于在给定位置将给定范围的所有元素插入 vector;append_range() 用于将给定范围的所有元素追加到 vector 的末尾。第 17 章详细讨论了 range。
你可以使用 erase() 从 vector 的任何位置移除元素,并可以使用 clear() 移除所有元素。erase() 有两个重载:一个接受单个迭代器以移除单个元素,另一个接受两个迭代器指定要移除的元素范围。
让我们看一个演示添加和删除元素成员函数的示例程序。以下代码片段演示了 clear()、push_back()、pop_back()、C++23 的 append_range()、接受两个参数版本的 erase() 以及 insert() 的以下重载:
insert(const_iterator pos, const T& x):在位置pos插入值x。insert(const_iterator pos, size_type n, const T& x):在位置pos插入n次值x。insert(const_iterator pos, InputIterator first, InputIterator last):在位置pos插入范围[first, last)中的元素。
以下是代码片段:
vector vectorOne { 1, 2, 3, 5 };vector<int> vectorTwo;println("{:n}", vectorOne);
// 哎呀,我们忘了加 4。把它插在正确的地方。vectorOne.insert(cbegin(vectorOne) + 3, 4);
// 将元素 6 到 10 添加到 vectorTwo。for (int i { 6 }; i <= 10; ++i) { vectorTwo.push_back(i);}println("{:n}", vectorOne);println("{:n}", vectorTwo);
// 将 vectorTwo 中的所有元素添加到 vectorOne 的末尾。vectorOne.insert(cend(vectorOne), cbegin(vectorTwo), cend(vectorTwo));println("{:n}", vectorOne);
// 使用 C++23 的 append_range() 将 vectorTwo 的所有元素添加到 vectorOne 的末尾。// 注意这比之前的 insert() 调用要清晰得多。vectorOne.append_range(vectorTwo);println("{:n}", vectorOne);
// 现在删除 vectorOne 中的数字 2 到 5。vectorOne.erase(cbegin(vectorOne) + 1, cbegin(vectorOne) + 5);println("{:n}", vectorOne);
// 完全清空 vectorTwo。vectorTwo.clear();
// 并添加 10 个值为 100 的副本。vectorTwo.insert(cbegin(vectorTwo), 10, 100);println("{:n}", vectorTwo);
// 决定只需要 9 个元素。vectorTwo.pop_back();println("{:n}", vectorTwo);程序的输出如下:
1, 2, 3, 51, 2, 3, 4, 56, 7, 8, 9, 101, 2, 3, 4, 5, 6, 7, 8, 9, 101, 2, 3, 4, 5, 6, 7, 8, 9, 10, 6, 7, 8, 9, 101, 6, 7, 8, 9, 10, 6, 7, 8, 9, 10100, 100, 100, 100, 100, 100, 100, 100, 100, 100100, 100, 100, 100, 100, 100, 100, 100, 100回想一下,迭代器对表示半开范围,且 insert() 在给定迭代器位置所指的元素之前添加元素。因此,你可以像这样将 vectorTwo 的全部内容插入到 vectorOne 的末尾:
vectorOne.insert(cend(vectorOne), cbegin(vectorTwo), cend(vectorTwo));接受通用迭代器范围作为参数的成员函数(如 insert() 和 erase())假设起始和结束迭代器指向同一个容器中的元素,且结束迭代器指向的位置在起始迭代器之后或相同。如果这些先决条件不满足,成员函数将无法正确工作!
如果你想移除所有满足条件的元素,一种解决方法是编写一个循环遍历所有元素,并删除每个匹配条件的元素。但是,这种解决方案具有平方复杂度,对性能不利。这种平方复杂度可以通过使用 remove-erase-idiom 来避免,它具有线性复杂度。remove-erase-idiom 在第 20 章中讨论。
然而,从 C++20 开始,有一种更优雅的解决方案,即为所有标准库容器定义的 std::erase() 和 std::erase_if() 非成员函数。以下代码片段演示了前者:
vector values { 1, 2, 3, 2, 1, 2, 4, 5 };println("{:n}", values);
erase(values, 2); // 移除所有等于 2 的值。println("{:n}", values);输出如下:
1, 2, 3, 2, 1, 2, 4, 51, 3, 1, 4, 5erase_if() 的工作原理类似,但不是传递一个值作为第二个参数,而是传递一个谓词(predicate),该谓词对应该移除的元素返回 true,对应该保留的元素返回 false。谓词可以是函数指针、函数对象或 lambda 表达式,所有这些都在第 19 章“函数指针、函数对象和 Lambda 表达式”中详细讨论。
向 vector 添加元素可以在某些情况下利用移动语义来提高性能。例如,假设你有以下字符串 vector:
vector<string> vec;你可以像这样向此 vector 添加一个元素:
string myElement(5, 'a'); // 构造字符串 "aaaaa"vec.push_back(myElement);但是,由于 myElement 不是临时对象,push_back() 会创建 myElement 的副本并将其放入 vector。
vector 类还定义了 push_back(T&&), 它是 push_back(const T&) 的移动等价版本。因此,如果你按如下方式调用 push_back(),就可以避免拷贝:
vec.push_back(move(myElement));此语句明确表示应将 myElement 移动到 vector 中。请注意,在此调用之后,myElement 处于有效但未确定的状态。除非你先将其恢复到确定状态(例如通过调用其 clear()),否则不应再使用 myElement!你还可以像下面这样调用 push_back():
vec.push_back(string(5, 'a'));这种对 push_back() 的调用会触发对移动重载版本的调用,因为对 string 构造函数的调用会产生一个临时对象。push_back() 成员函数将这个临时 string 对象移动到 vector 中,从而避免了任何拷贝。
Emplace 操作
Section titled “Emplace 操作”C++ 在包括 vector 在内的大多数标准库容器上都支持 emplace 操作(emplace operations)。Emplace 的意思是“就地放入”。一个例子是 vector 的 emplace_back() 成员函数,它不拷贝或移动任何内容。相反,它在容器中腾出空间,并就地(in place)构造对象,如下例所示:
vec.emplace_back(5, 'a');emplace 成员函数作为一个变长参数模板(variadic template)接受可变数量的参数。变长参数模板在第 26 章“高级模板”中讨论,但不需要这些细节也能理解如何使用 emplace_back()。基本上,传递给 emplace_back() 的参数会被转发给存储在 vector 中的类型的构造函数。使用移动语义的 emplace_back() 和 push_back() 之间的性能差异取决于你的特定编译器如何实现 these 操作。在大多数情况下,你可以根据你喜欢的语法来选择其中之一:
vec.push_back(string(5, 'a'));// 或者vec.emplace_back(5, 'a');emplace_back() 成员函数返回对插入元素的引用。还有一个 emplace() 成员函数,它在 vector 的特定位置就地构造一个对象,并返回一个指向插入元素的迭代器。
算法复杂度和迭代器失效
Section titled “算法复杂度和迭代器失效”在 vector 中插入或删除元素会导致所有后续元素向上或向下移动,以腾出空间或填补受影响元素留下的空洞。因此,这些操作具有线性复杂度。此外,指向插入或删除点或后续位置的所有迭代器在操作后都是无效的。迭代器不会“神奇地”移动以跟上 vector 中向上或向下移动的元素——这取决于你。
还请记住,内部 vector 重新分配会导致指向 vector 中元素的所有迭代器失效,而不仅仅是指向插入或删除点之后元素的迭代器。详见下一节。
vector 内存分配方案
Section titled “vector 内存分配方案”vector 会自动分配内存来存储你插入的元素. 回想一下,vector 的要求规定元素必须位于连续内存中,就像标准的 C 风格数组一样。由于不可能要求在当前内存块末尾添加内存,每当 vector 分配更多内存时,它必须在单独的内存位置分配一个新的、更大的块,并将所有元素拷贝/移动到新块中。这个过程非常耗时,因此 vector 实现会尝试通过在必须执行重新分配时分配比所需更多的空间来避免这种情况。这样,它们就可以避免每次插入元素时都重新分配内存。
此时一个显而易见的问题是,作为 vector 的客户端,你为什么要关心它内部如何管理内存。你可能认为抽象原则应该允许你忽略 vector 内存分配方案的内部细节。遗憾的是,有两个原因导致你需要了解它的工作原理:
- 效率:
vector分配方案可以保证元素插入以均摊常数时间(amortized constant time)运行:大多数时候操作是常数时间的,但偶尔(如果需要重新分配)是线性时间的。如果你担心效率,可以控制vector何时执行重新分配。 - 迭代器失效:重新分配会使指向
vector中元素的所有迭代器失效。
因此,vector 接口允许你查询和控制 vector 的重新分配,这两点都将在接下来的小节中解释。
如果你不显式控制重新分配,你应该假设所有插入操作都会导致重新分配,从而使所有迭代器失效。
vector 提供了两个成员函数用于获取有关其大小的信息:size() 和 capacity()。size() 成员函数返回 vector 中的元素数量,而 capacity() 返回它在不重新分配的情况下可以容纳的元素数量。因此,在不导致重新分配的情况下可以插入的元素数量是 capacity() - size()。
还有非成员的 std::size() 和 std::empty() 全局函数,它们可以用于所有容器。它们也可以用于无法通过指针访问的静态分配 C 风格数组,以及 initializer_list。下面是一个在 vector 上使用它们的例子:
vector vec { 1, 2, 3 };println("{}", size(vec)); // 3println("{}", empty(vec)); // false此外,全局非成员辅助函数 std::ssize() 以有符号整数类型返回大小。示例如下:
auto s1 { size(vec) }; // 类型为 size_t (无符号)auto s2 { ssize(vec) }; // 类型为 long long (有符号)如果你不关心效率或迭代器失效,则永远不需要显式控制 vector 内存分配. 但是,如果你想让程序尽可能高效,或者你想保证迭代器不会失效,你可以强制 vector 预分配足够的空间来容纳其所有元素。当然,你需要知道它将容纳多少个元素,这有时是无法预测的。
预分配空间的一种方法是调用 reserve(),它分配足够的内存来容纳指定数量的元素。接下来的轮询(round-robin)类示例展示了 reserve() 成员函数的实际应用。
预留元素空间会改变容量,但不会改变大小。也就是说,它实际上并没有创建元素。不要访问超过 vector 大小的元素。
预分配空间的另一种方法是在构造函数中,或者使用 resize() 或 assign() 成员函数指定你希望 vector 存储多少个元素. 此成员函数实际上创建了一个该大小(可能也是该容量)的 vector。
收回所有内存
Section titled “收回所有内存”vector 在需要时会自动分配更多内存;然而,除非 vector 被销毁,否则它永远不会释放任何内存。从 vector 中移除元素会减小 vector 的大小,但绝不会减小其容量。那么你该如何收回它的内存呢?
一种选择是使用 shrink_to_fit() 成员函数,它请求 vector 将其容量减小到其大小。然而,这仅仅是一个请求,标准库实现允许忽略此请求。
可以使用以下技巧收回 vector 的所有内存:将该 vector 与一个空 vector 进行交换。以下代码片段展示了如何通过一条语句收回名为 values 的 vector 的内存。第三行代码构造了一个与 values 类型相同的临时空默认构造 vector,并将其与 values 交换。所有为 values 分配的内存现在都属于这个临时 vector,它在该语句结束时自动销毁,释放其所有内存。最终结果是 values 分配的所有内存都被收回,且 values 的容量变为零。
vector<int> values;// 填充 values …vector<int>().swap(values);直接访问数据
Section titled “直接访问数据”vector 将其数据连续存储在内存中. 你可以使用 data() 成员函数获取指向该内存块的指针。
还有一个非成员函数 std::data() 可用于获取指向数据的指针. 它适用于 array 和 vector 容器、string、无法通过指针访问的静态分配 C 风格数组以及 initializer_list。以下是 vector 的示例:
vector vec { 1, 2, 3 };int* data1 { vec.data() };int* data2 { data(vec) };另一种访问 vector 内存块的方法是获取第一个元素的地址,例如:&vec[0]。你可能会在遗留代码库中发现这种代码,但它对于空 vector 是不安全的;因此,我建议不要使用它,而应使用 data()。
所有标准库容器都通过包含移动构造函数和移动赋值运算符来支持移动语义. 有关移动语义的详细信息,请参见第 9 章。标准库容器可以从函数中按值返回,而不会损失性能。看看下面这个函数:
vector<int> createVectorOfSize(size_t size){ vector<int> vec(size); for (int contents { 0 }; auto& i : vec) { i = contents++; } return vec;}…vector<int> myVector;myVector = createVectorOfSize(123);如果没有移动语义,将 createVectorOfSize() 的结果赋值给 myVector 可能会调用拷贝赋值运算符. 有了标准库容器中的移动语义支持,就避免了 vector 的拷贝。相反,对 myVector 的赋值会触发对移动赋值运算符的调用。
但请记住,为了让移动语义在标准库容器中正常工作,存储在容器中的类型的移动构造函数和移动赋值运算符必须标记为 noexcept!为什么不允许这些移动成员函数抛出任何异常?想象一下如果允许它们抛出异常。现在,当向 vector 添加新元素时,可能 vector 的容量不足,需要分配更大的内存块。随后,vector 必须将所有数据从 original 内存块拷贝或移动到新块。如果这是使用可能抛出异常的移动成员函数完成的,那么在部分数据已经移动到新内存块时,可能会抛出异常。那我们能做什么呢?做不了什么。为了避免这类问题,标准库容器仅在保证不抛出任何异常的情况下才会使用移动成员函数。如果它们未标记为 noexcept,则会改用拷贝成员函数,以保证强异常安全性。
在实现自己的类标准库容器时,可以使用一个名为 std::move_if_noexcept() 的有用辅助函数,它定义在 <utility> 中. 这可以根据移动构造函数是否为 noexcept 来调用移动构造函数或拷贝构造函数。move_if_noexcept() 本身并不做太多工作。它接受一个引用作为参数,如果移动构造函数是 noexcept,则将其转换为右值引用,否则转换为 const 引用,但这个简单的技巧允许你通过一次调用来调用正确的构造函数。
标准库没有提供类似的辅助函数来根据前者是否为 noexcept 调用移动赋值运算符或拷贝赋值运算符. 自己实现一个并不太复杂,但需要一些模板元编程技术和类型特征(type traits)来检查类型的属性。这两个主题都在第 26 章中讨论,该章还给出了实现你自己的 move_assign_if_noexcept() 的示例。
vector 示例:轮询类
Section titled “vector 示例:轮询类”计算机科学中的一个常见问题是在有限的资源列表中分配请求. 例如,一个简单的操作系统可以保留一个进程列表,并为每个进程分配一个时间片(如 100ms),让该进程执行其部分工作。时间片结束后,操作系统挂起该进程,并给列表中的下一个进程一个时间片来执行其工作。解决这个问题最简单的算法方案之一是轮询调度(round-robin scheduling)。当最后一个进程的时间片结束时,调度程序从第一个进程开始重新循环。例如,在有三个进程的情况下,第一个时间片给第一个进程,第二个给第二个进程,第三个给第三个进程,第四个时间片回到第一个进程。循环将以这种方式无限进行。
假设你决定编写一个通用的轮询调度类,可以与任何类型的资源一起使用. 该类应支持添加和删除资源,并支持循环遍历资源以获取下一个资源。你可以直接使用 vector,但编写一个包装类通常更有帮助,该类可以更直接地提供特定应用程序所需的功能。以下示例显示了一个 RoundRobin 类模板,并附有解释代码的注释。首先是类定义,从一个名为 round_robin 的模块中导出:
export module round_robin;import std;
// 类模板 RoundRobin// 为元素列表提供简单的轮询语义。export template <typename T>class RoundRobin final{ public: // 客户端可以给出预期元素数量的提示,以提高效率。 explicit RoundRobin(std::size_t numExpected = 0); // 禁止拷贝构造和拷贝赋值 RoundRobin(const RoundRobin& src) = delete; RoundRobin& operator=(const RoundRobin& rhs) = delete; // 显式默认移动构造函数和移动赋值运算符 RoundRobin(RoundRobin&& src) noexcept = default; RoundRobin& operator=(RoundRobin&& rhs) noexcept = default; // 在列表末尾追加元素。可以在对 getNext() 的调用之间调用。 void add(const T& element); // 移除列表中第一个(且仅第一个)与 element 相等(使用 operator==)的元素。 // 可以在对 getNext() 的调用之间调用。 void remove(const T& element); // 返回列表中的下一个元素,从第一个开始, // 到达列表末尾时循环回到第一个, // 同时考虑添加或移除的元素。 T& getNext(); private: std::vector<T> m_elements; typename std::vector<T>::iterator m_nextElement;};如你所见,公共接口很简单:只有三个成员函数加上构造函数. 资源存储在名为 m_elements 的 vector 中。迭代器 m_nextElement 始终指向将在下一次调用 getNext() 时返回的元素。如果尚未调用 getNext(),则 m_nextElement 等于 begin(m_elements)。注意在声明 m_nextElement 的行前面使用了 typename 关键字。到目前为止,你只见过该关键字用于指定模板类型参数,但它还有另一种用法。每当你访问基于一个或多个模板参数的类型时,都必须显式指定 typename。在这种情况下,模板参数 T 被用于访问 iterator 类型。因此,你必须指定 typename。
由于 m_nextElement 数据成员的存在,该类还禁用了拷贝构造和拷贝赋值. 要使拷贝构造和拷贝赋值正常工作,你必须实现赋值运算符和拷贝构造函数,并确保 m_nextElement 在目标对象中是有效的。
RoundRobin 类的实现如下,并附有解释代码的注释. 请注意构造函数中 reserve() 的使用,以及 add()、remove() 和 getNext() 中迭代器的广泛使用。最棘手的部分是在 add() 和 remove() 成员函数中处理 m_nextElement。
template <typename T> RoundRobin<T>::RoundRobin(std::size_t numExpected){ // 如果客户端给出了指导意见,则预留相应空间。 m_elements.reserve(numExpected);
// 即使在至少有一个元素之前不会使用 m_nextElement,也要对其进行初始化。 m_nextElement = begin(m_elements);}
// 始终在末尾添加新元素。template <typename T> void RoundRobin<T>::add(const T& element){ // 即使我们将元素添加到末尾,vector 也可能发生重新分配, // 并通过 push_back() 调用使 m_nextElement 迭代器失效。 // 利用随机访问迭代器特性来保存我们的位置。 // 注意:ptrdiff_t 是能够存储两个随机访问迭代器之差的类型。 std::ptrdiff_t pos { m_nextElement - begin(m_elements) };
// 添加元素。 m_elements.push_back(element);
// 重新设置我们的迭代器以确保它是有效的。 m_nextElement = begin(m_elements) + pos;}
template <typename T> void RoundRobin<T>::remove(const T& element){ for (auto it { begin(m_elements) }; it != end(m_elements); ++it) { if (*it == element) { // 如果移除元素的位置在 m_nextElement 之前, // 那么移除操作会使 m_nextElement 迭代器失效。 // 利用迭代器的随机访问特性来跟踪移除后当前元素的位置。 std::ptrdiff_t newPos;
if (m_nextElement == end(m_elements) - 1 && m_nextElement == it) { // m_nextElement 指向列表中的最后一个元素, // 且我们要移除的就是这最后一个元素,因此循环回到开头。 newPos = 0; } else if (m_nextElement <= it) { // 否则,如果 m_nextElement 在我们要移除的元素之前或正是该元素, // 则新位置与之前相同。 newPos = m_nextElement - begin(m_elements); } else { // 否则,它比之前少一个。 newPos = m_nextElement - begin(m_elements) - 1; }
// 擦除元素(并忽略返回值)。 m_elements.erase(it);
// 现在重新设置我们的迭代器以确保它是有效的。 m_nextElement = begin(m_elements) + newPos;
return; } }}
template <typename T> T& RoundRobin<T>::getNext(){ // 首先,确保有元素。 if (m_elements.empty()) { throw std::out_of_range { "No elements in the list" }; }
// 存储我们需要返回的当前元素。 auto& toReturn { *m_nextElement };
// 对元素数量取模递增迭代器。 ++m_nextElement; if (m_nextElement == end(m_elements)) { m_nextElement = begin(m_elements); }
// 返回对元素的引用。 return toReturn;}下面是一个使用 RoundRobin 类模板的调度程序的简单实现,附有代码解释注释:
// 基础 Process 类。class Process final{ public: // 接受进程名称的构造函数。 explicit Process(string name) : m_name { move(name) } {}
// 让进程在时间片期间执行其工作。 void doWorkDuringTimeSlice() { println("Process {} performing work during time slice.", m_name); // 实际实现省略。 }
// RoundRobin::remove() 成员函数正常工作所需的运算符。 bool operator==(const Process&) const = default; // 自 C++20 起可使用 = default。 private: string m_name;};
// 基于轮询的基础进程调度器。class Scheduler final{ public: // 构造函数接受一个进程 vector。 explicit Scheduler(const vector<Process>& processes) { // 添加进程。 for (auto& process : processes) { m_processes.add(process); } }
// 使用轮询调度算法选择下一个进程,并允许它在此时间片内执行一些工作。 void scheduleTimeSlice() { try { m_processes.getNext().doWorkDuringTimeSlice(); } catch (const out_of_range&) { println(cerr, "No more processes to schedule."); } }
// 从进程列表中移除给定进程。 void removeProcess(const Process& process) { m_processes.remove(process); } private: RoundRobin<Process> m_processes;};
int main(){ vector processes { Process { "1" }, Process { "2" }, Process { "3" } };
Scheduler scheduler { processes }; for (size_t i { 0 }; i < 4; ++i) { scheduler.scheduleTimeSlice(); }
scheduler.removeProcess(processes[1]); println("Removed second process");
for (size_t i { 0 }; i < 4; ++i) { scheduler.scheduleTimeSlice(); }}输出应如下所示:
Process 1 performing work during time slice.Process 2 performing work during time slice.Process 3 performing work during time slice.Process 1 performing work during time slice.Removed second processProcess 3 performing work during time slice.Process 1 performing work during time slice.Process 3 performing work during time slice.Process 1 performing work during time slice.vector 特化
Section titled “vector 特化”C++ 标准要求对 bool 类型的 vector 进行特化,旨在通过“打包”布尔值来优化空间分配。回想一下,bool 值要么是 true 要么是 false,因此可以用单个位来表示,而单个位恰好可以表示两个值。C++ 没有原生存储恰好一个位的类型。某些编译器使用与 char 大小相同的类型来表示布尔值;其他编译器则使用 int。vector<bool> 特化应该将“bool 数组”存储在单个位中,从而节省空间。
为了提供一些位字段例程,vector<bool> 有一个额外的成员函数 flip(),用于对位求反;即 true 变为 false,false 变为 true,类似于逻辑非(NOT)运算符. 该成员函数既可以在容器上调用(此时会对容器中的所有元素求反),也可以在 operator[] 或类似成员函数返回的单个引用上调用(此时仅对该单个元素求反)。
此时,你可能会纳闷如何对 bool 的引用调用成员函数. 答案是你做不到。vector<bool> 特化实际上定义了一个名为 reference 的类,它作为底层 bool(或位)的代理(proxy)。当你调用 operator[]、at() 或类似的成员函数时,vector<bool> 会返回一个 reference 对象,它是真实 bool 的代理。
由于 vector<bool> 返回的是代理引用,这意味着你无法获取它们的地址来得到指向容器中实际元素的指针.
在实践中,通过打包 bool 节省的那点空间似乎并不值得额外付出这些努力. 更糟糕的是,访问和修改 vector<bool> 中的元素比访问 vector<int> 等容器要慢得多。许多 C++ 专家建议避免使用 vector<bool>,转而使用 bitset。如果你确实需要动态大小的位字段,只需使用 vector<std::int_fast8_t> 或 vector<unsigned char> 即可。std::int_fast8_t 类型定义在 <cstdint> 中。它是一种有符号整数类型,编译器必须为其使用至少 8 位且速度最快的整数类型。
deque(double-ended queue,双端队列的缩写)与 vector 几乎完全相同,但使用频率远低于后者. 它定义在 <deque> 中。主要区别如下:
- 元素在内存中不是连续存储的.
deque支持在首尾两端进行真正的常数时间插入和删除元素(vector仅在末尾支持均摊常数时间操作).deque提供了以下vector所不具备的成员函数:push_front():在开头插入元素.pop_front():移除第一个元素.emplace_front():在开头就地创建一个新元素,并返回对插入元素的引用.prepend_range():将给定范围的所有元素添加到deque的开头。自 C++23 起可用.
- 在开头或末尾插入元素时,
deque绝不会像vector那样将元素移动到更大的数组中. 这也意味着在这种情况下,deque不会使任何迭代器失效。 deque不通过reserve()或capacity()暴露其内存 management 方案.
与 vector 相比,deque 很少被使用,因此不再进一步讨论. 有关所有受支持成员函数的详细列表,请参阅标准库参考。
标准库 list 类模板定义在 <list> 中,是一个标准的双向链表. 它支持在链表的任何位置以常数时间插入和删除元素,但访问单个元素的速度较慢(线性时间)。事实上,list 甚至不提供像 operator[] 这样的随机访问操作。只能通过迭代器访问单个元素。
大多数 list 操作与 vector 相同,包括构造函数、析构函数、拷贝操作、赋值操作和比较操作. 本节重点介绍那些与 vector 不同的成员函数。
list 提供的访问元素的唯一成员函数是 front() 和 back(),它们都以常数时间运行. 这些成员函数返回对 list 第一个和最后一个元素的引用。所有其他元素访问必须通过迭代器执行。
与 vector 一样,list 支持 begin()、end()、rbegin()、rend()、cbegin()、cend()、crbegin() 和 crend().
list 不提供对元素的随机访问.
list 迭代器是双向的,不像 vector 迭代器那样是随机访问的. 这意味着你不能将 list 迭代器相互加减,也不能对它们进行其他指针算术运算。例如,如果 p 是一个 list 迭代器,你可以通过 ++p 或 --p 遍历 list 的元素,但不能使用加法或减法运算符;p+n 和 p-n 是行不通的。
添加和删除元素
Section titled “添加和删除元素”list 支持与 vector 相同的添加和删除元素的成员函数,包括 push_back()、pop_back()、emplace()、emplace_back()、五种形式的 insert()、assign_range()、insert_range()、append_range()、两种形式的 erase() 以及 clear(). 与 deque 一样,它还提供 push_front()、emplace_front()、pop_front() 和 prepend_range()。一旦找到了正确的位置,添加或删除单个元素的成员函数以常数时间运行,而添加或删除多个元素的成员函数以线性时间运行。因此,对于需要在数据结构中执行许多插入和删除操作,但不需要快速基于索引访问元素的应用程序,list 可能是合适的。但即便如此,vector 仍可能更快。请使用性能分析器进行确认。
list 大小
Section titled “list 大小”与 deque 类似,且与 vector 不同,list 不暴露其底层内存模型. 因此,它们支持 size()、empty() 和 resize(),但不支持 reserve() 或 capacity()。请注意,list 上的 size() 成员函数具有常数复杂度。
特殊 list 操作
Section titled “特殊 list 操作”list 提供了一些特殊的内置操作,这些操作利用了其快速插入和删除元素的特性. 本节提供其中一些操作的概述及示例。有关所有成员函数的详尽参考,请查阅标准库参考。
接合(Splicing)
Section titled “接合(Splicing)”链表的特性使得 list 能够以常数时间在另一个 list 的任何位置接合(splice)或插入整个 list. 此成员函数的最简单版本如下所示:
// 将以 a 开头的单词存储在主词典中.list<string> dictionary { "aardvark", "ambulance" };// 存储以 b 开头的单词.list<string> bWords { "bathos", "balderdash" };// 将以 c 开头的单词添加到主词典中.dictionary.push_back("canticle");dictionary.push_back("consumerism");// 将 b 开头的单词接合到主词典中.if (!bWords.empty()) { // 获取指向最后一个 b 单词的迭代器. auto iterLastB { --(cend(bWords)) }; // 迭代到我们要插入 b 单词的位置. auto it { cbegin(dictionary) }; for (; it != cend(dictionary); ++it) { if (*it > *iterLastB) { break; } } // 添加 b 单词。此操作会从 bWords 中移除这些元素. dictionary.splice(it, bWords);}// 打印词典.println("{:n:}", dictionary);运行该程序的结果如下:
aardvark, ambulance, bathos, balderdash, canticle, consumerismsplice() 还有另外两个重载:一个从另一个 list 插入单个元素,另一个从另一个 list 插入一个范围. 此外,所有 splice() 重载都支持对源 list 使用普通引用或右值引用。
接合(Splicing)对作为参数传递的 list 是破坏性的,即它会从一个 list 中移除接合的元素并将其插入到另一个 list 中.
更高效的算法版本
Section titled “更高效的算法版本”除了 splice() 之外,list 还为几个通用的标准库算法提供了特殊的实现. 通用形式在第 20 章中讨论。这里仅讨论 list 提供的特定版本。
下表总结了 list 以成员函数形式提供特殊实现的算法. 有关这些算法的更多详细信息,请参见第 20 章。
| 成员函数 | 说明 |
|---|---|
remove() remove_if() | 从 list 中移除所有符合特定条件的元素,并返回移除的元素数量. |
unique() | 基于 operator== 或用户提供的二元谓词,从 list 中移除连续重复的元素,并返回移除的元素数量. |
merge() | 合并两个 list. 两个 list 必须根据 operator< 或用户定义的比较器进行排序. 与 splice() 一样,merge() 对作为参数传递的 list 具有破坏性。 |
sort() | 对 list 中的元素执行稳定排序. |
reverse() | 反转 list 中元素的顺序. |
list 示例:确定注册人数
Section titled “list 示例:确定注册人数”假设你正在为一所大学编写计算机注册系统. 你可能提供的一项功能是,根据每个班级的学生列表生成大学中完整注册学生的列表。为了这个例子,假设你只需要编写一个函数,该函数接受一个包含学生姓名(string 形式)的 list 的 vector,以及一个因为未缴学费而被退课的学生 list。该函数应该生成一份包含所有课程中所有学生的完整 list,不能有任何重复,且不能包含那些已被退课的学生。请注意,学生可能会参加多门课程。
以下是该函数的代码,附带解释代码的注释. 凭借标准库 list 的力量,该函数实际上比其书面描述还要简短!注意标准库允许你“嵌套”容器:在本例中,你可以使用 list 的 vector。
// courseStudents 是一个包含 list 的 vector,每个课程对应一个 list.// list 包含注册这些课程的学生. 它们是未排序的.//// droppedStudents 是因未缴纳学费而被退课的学生 list.//// 该函数返回所有课程中每位已注册(非退课)学生的 list.list<string> getTotalEnrollment(const vector<list<string>>& courseStudents, const list<string>& droppedStudents){ list<string> allStudents;
// 将所有课程列表连接到主列表中 for (auto& lst : courseStudents) { allStudents.append_range(lst); }
// 对主列表进行排序 allStudents.sort();
// 移除重复的学生姓名(即参加了多门课程的学生). allStudents.unique();
// 移除在退课名单上的学生. // 遍历退课名单,为主列表中的每位退课学生调用 remove. for (auto& str : droppedStudents) { allStudents.remove(str); }
// 完成! return allStudents;}forward_list
Section titled “forward_list”forward_list 定义在 <forward_list> 中,与 list 类似,不同之处在于它是单向链表,而 list 是双向链表. 这意味着 forward_list 仅支持正向迭代,因此,其范围的指定方式与 list 不同。如果你想修改任何列表,你需要访问感兴趣的第一个元素之前的那个元素。因为 forward_list 没有支持向后移动的迭代器,所以没有简单的方法可以回到前面的元素。出于这个原因,要修改的范围(例如提供给 erase() 和 splice() 的范围)必须在开头是开放的(open at the beginning)。前面讨论的 begin() 函数返回指向第一个元素的迭代器,因此只能用于构造在开头是闭合的范围。因此,forward_list 类提供了一个 before_begin() 成员函数,它返回一个指向列表开头之前的想象元素的迭代器。你不能解引用该迭代器,因为它指向无效数据。然而,将该迭代器增加 1 后,它就与 begin() 返回的迭代器相同了;因此,它可以用来创建一个在开头是开放的范围。
list 和 forward_list 的构造函数和赋值运算符类似. C++ 标准要求 forward_list 尽量减少内存使用. 这就是为什么没有 size() 成员函数的原因,因为通过不提供它,就没有必要存储列表的大小。此外,list 必须存储指向列表中前一个和下一个元素的指针,而 forward_list 只需要存储指向下一个元素的指针,从而进一步减少了内存使用。例如,在 64 位系统上,list<int> 中的每个元素需要 20 字节(两个 64 位指针共 16 字节,加上 int 本身的 4 字节)。而 forward_list<int> 每个元素仅需要 12 字节(一个 64 位指针 8 字节,加上 int 本身的 4 字节)。
下表总结了 list 和 forward_list 之间的区别. 实心框 ( ) 表示容器支持该操作,而空框 (
) 表示容器支持该操作,而空框 ( ) 表示不支持该操作.
) 表示不支持该操作.
| 操作 | list | forward_list |
|---|---|---|
| append_range() (C++23) | | |
| assign() | | |
| assign_range() (C++23) | | |
| back() | | |
| before_begin() | | |
| begin() | | |
| cbefore_begin() | | |
| cbegin() | | |
| cend() | | |
| clear() | | |
| crbegin() | | |
| crend() | | |
| emplace() | | |
| emplace_after() | | |
| emplace_back() | | |
| emplace_front() | | |
| empty() | | |
| end() | | |
| erase() | | |
| erase_after() | | |
| front() | | |
| insert() | | |
| insert_after() | | |
| insert_range() (C++23) | | |
| insert_range_after() (C++23) | | |
| iterator / const_iterator | | |
| max_size() | | |
| merge() | | |
| pop_back() | | |
| pop_front() | | |
| prepend_range() (C++23) | | |
| push_back() | | |
| push_front() | | |
| rbegin() | | |
| remove() | | |
| remove_if() | | |
| rend() | | |
| resize() | | |
| reverse() | | |
| reverse_iterator / const_reverse_iterator | | |
| size() | | |
| sort() | | |
| splice() | | |
| splice_after() | | |
| swap() | | |
| unique() | | |
以下示例演示了 forward_list 的用法:
// 使用 initializer_list 创建 3 个 forward list// 以初始化它们的元素(统一初始化).forward_list<int> list1 { 5, 6 };forward_list list2 { 1, 2, 3, 4 }; // 支持 CTAD.forward_list list3 { 7, 8, 9 };
// 使用 splice 将 list2 插入到 list1 的前端.list1.splice_after(list1.before_begin(), list2);
// 在 list1 的开头添加数字 0.list1.push_front(0);
// 在 list1 的末尾插入 list3.// 为此,我们首先需要一个指向最后一个元素的迭代器.auto iter { list1.before_begin() };auto iterTemp { iter };while (++iterTemp != end(list1)) { ++iter; }list1.insert_after(iter, cbegin(list3), cend(list3));
// 输出 list1 的内容.println("{:n}", list1);要将 list3 插入到 list1 的末尾,你需要一个指向 list1 最后一个元素的迭代器. 然而,因为这是 forward_list,你不能使用 --end(list1),因此你需要从头开始遍历列表并在最后一个元素处停止. 输出如下:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9array 定义在 <array> 中,与 vector 类似,不同之处在于它的大小是固定的;它不能增长或缩小. 固定大小的目的是允许 array 在栈上分配,而不是像 vector 那样总是要求访问自由存储区.
对于包含原始类型(整数、浮点数、字符、布尔值等)的 array,其元素的初始化方式与 vector、list 等容器不同. 如果在创建 array 时未给定初始化值,则 array 元素将是未初始化的,即包含垃圾值. 对于 vector 和 list 等其他容器,元素总是会被初始化,要么使用给定的值,要么使用零初始化. 因此,array 的行为实际上与 C 风格数组完全相同.
与 vector 一样,array 支持随机访问迭代器,且元素存储在连续内存中. array 支持 front()、back()、at() 和 operator[]. 它还支持 fill() 成员函数,用特定元素填充 array. 由于大小固定,它不支持 push_back()、pop_back()、insert()、erase()、clear()、resize()、reserve()、capacity() 或任何基于范围的成员函数. 与 vector 相比,一个缺点是 array 的 swap() 成员函数以线性时间运行,而 vector 为常数复杂度. 此外,array 也无法以常数时间移动,而 vector 可以. array 有 size() 成员函数,这是优于 C 风格数组的一个明显优势. 以下示例演示了如何使用 array 类. 请注意,array 声明需要两个模板参数:第一个指定元素的类型,第二个指定 array 中固定的元素数量.
// 创建一个包含 3 个整数的 array,并使用统一初始化// 通过给定的 initializer_list 初始化它们.array<int, 3> arr { 9, 8, 7 };// 输出 array 的大小.println("Array size = {}", arr.size()); // 或 std::size(arr)// 使用 C++23 对格式化范围的支持输出内容.println("{:n}", arr);// 再次使用基于范围的 for 循环输出内容.for (const auto& i : arr) { print("{} ", i); }println("");
println("Performing arr.fill(3)…");// 使用 fill 成员函数更改 array 的内容.arr.fill(3);// 使用迭代器输出 array 的内容.for (auto iter { cbegin(arr) }; iter != cend(arr); ++iter) { print("{} ", *iter);}输出如下:
Array size = 39, 8, 79 8 7Performing arr.fill(3)…3 3 3你可以使用 std::get<n>() 函数模板来检索 std::array 中给定索引 n 处的元素. 索引必须是常量表达式,因此它不能是循环变量. 使用 std::get<n>() 的好处是编译器会在编译时检查给定索引是否有效;否则会导致编译错误,如下例所示:
array myArray { 11, 22, 33 }; // std::array 支持 CTAD.println("{}", std::get<1>(myArray));println("{}", std::get<10>(myArray)); // 错误!编译错误!std::to_array() 定义在 <array> 中,它使用元素的拷贝初始化将给定的 C 风格数组转换为 std::array. 该函数仅适用于一维数组. 下面是一个快速示例:
auto arr1 { to_array({ 11, 22, 33 }) }; // 类型为 array<int, 3>
double carray[] { 9, 8, 7, 6 };auto arr2 { to_array(carray) }; // 类型为 array<double, 4>C++ 标准库提供了两种序列视图(sequential views):std::span 和 std::mdspan. 后者是 C++23 中的新特性. span 提供了一个指向连续数据序列的一维、非拥有(non-owning)视图. mdspan 推广了这一概念,允许对连续数据序列创建多维、非拥有视图.
假设你有这个函数来打印 vector 的内容:
void print(const vector<int>& values){ for (const auto& value : values) { print("{} ", value); } println("");}假设你还想打印 C 风格数组的内容. 一种选择是重载 print() 函数,使其接受指向数组第一个元素的指针以及要打印的元素数量:
void print(const int values[], size_t count){ for (size_t i { 0 }; i < count; ++i) { print("{} ", values[i]); } println("");}如果你还想打印 std::array,你可以提供第三个重载,但函数参数类型是什么呢?对于 std::array,你必须将类型和数组中的元素数量指定为模板参数. 你看,事情变得复杂了.
定义在 <span> 中的 std::span 在这里派上了用场,因为它允许你编写一个通用的函数,该函数适用于任何大小的 vector、C 风格数组和 std::array. 下面是使用 span 实现的一个 print() 函数:
void print(span<int> values){ for (const auto& value : values) { print("{} ", value); } println("");}请注意,与第 2 章中的 string_view 一样,span 的拷贝开销很低;它基本上只包含一个指向序列第一个元素的指针和元素数量. span 绝不会拷贝数据!因此,它通常通过值传递.
有几个构造函数可以用来创建 span. 例如,可以创建一个包含给定 vector、std::array 或 C 风格数组中所有元素的 span. 也可以创建一个仅包含容器一部分的 span,方法是传递第一个元素的地址和你希望包含在 span 中的元素数量.
可以使用 subspan() 成员函数从现有 span 创建子视图(subview). 它的第一个参数是进入 span 的偏移量,第二个参数是子视图中包含的元素数量. 还有两个名为 first() 和 last() 的额外成员函数,分别返回包含 span 前 n 个元素或后 n 个元素的子视图.
span 有几个与 vector 和 array 类似的成员函数:begin()、end()、rbegin()、rend()、front()、back()、operator[]、data()、size() 和 empty().
以下代码片段演示了调用 print(span) 函数的几种方式:
vector v { 11, 22, 33, 44, 55, 66 };// 传递整个 vector,隐式转换为 span.print(v);// 传递显式创建的 span.span mySpan { v };print(mySpan);// 创建一个子视图并传递它.span subspan { mySpan.subspan(2, 3) };print(subspan);// 传递内联创建的子视图.print({ v.data() + 2, 3 });
// 传递 std::array.array<int, 5> arr { 5, 4, 3, 2, 1 };print(arr);print({ arr.data() + 2, 3 });
// 传递 C 风格数组.int carr[] { 9, 8, 7, 6, 5 };print(carr); // 整个 C 风格数组.print({ carr + 2, 3 }); // C 风格数组的一个子视图.输出如下:
11 22 33 44 55 6611 22 33 44 55 6633 44 5533 44 555 4 3 2 13 2 19 8 7 6 57 6 5与提供 string 只读视图的 string_view 不同,span 可以提供对底层元素的读/写访问. 请记住,span 仅包含指向序列第一个元素的指针和元素数量;也就是说,span 绝不拷贝数据!因此,修改 span 中的元素实际上会修改底层序列中的元素. 如果不希望这样,可以创建一个 const 元素的 span. 例如,print() 函数没有理由修改给定 span 中的任何元素. 我们可以按如下方式防止此类修改:
void print(span<const int> values){ for (const auto& value : values) { print("{} ", value); } println("");}
Section titled “ mdspan”std::mdspan 定义在 <mdspan> 中,与 std::span 类似,但允许你对连续的数据序列创建多维视图. 与 span 一样,mdspan 不拥有数据,因此其拷贝开销很低. mdspan 有四个模板类型参数:
ElementType:底层元素的类型.Extents:维数及其大小,是std::extents的特化.LayoutPolicy:一种策略,指定如何将多维索引转换为底层连续数据序列中的一维索引. 你可以实现所需的任何布局策略,如平铺布局(tiled layout)、希尔伯特曲线(Hilbert curve)等. 以下是可用的标准策略:layout_right:行主序(row-major)多维数组布局,其中最右侧的维度步长(stride)为 1. 这是默认策略.layout_left:列主序(column-major)多维数组布局,其中最左侧的维度步长为 1.layout_stride:具有用户定义步长的布局映射.
AccessorPolicy:一种策略,指定如何将底层连续数据序列中的一维索引转换为对该位置实际元素的引用. 默认值是std::default_accessor.
有许多构造函数可用. 其中一个是接受指向连续数据序列的指针作为第一个参数,后跟一个或多个维度大小(extents). 作为构造函数参数传递的这类维度大小称为动态维度(dynamic extents). 可以使用多维 operator[] 访问数据. size() 成员函数返回 mdspan 中的元素数量,empty() 在 mdspan 为空时返回 true. stride(n) 成员函数可用于查询维度 n 的步长. 维度的大小可以使用 extents() 成员函数查询. 它返回一个 std::extents 实例,你可以对其调用 extent(n) 来查询维度 n 的大小. 示例如下:
template <typename T> void print2Dmdspan(const T& mdSpan){ for (size_t i { 0 }; i < mdSpan.extents().extent(0); ++i) { for (size_t j { 0 }; j < mdSpan.extents().extent(1); ++j) { print("{} ", mdSpan[i, j]); } println(""); }}
int main(){ vector data { 1, 2, 3, 4, 5, 6, 7, 8 }; // 将数据视为一个 2 行 4 列的二维数组, // 使用默认的行主序布局策略. mdspan data2D { data.data(), 2, 4 }; print2Dmdspan(data2D);}输出如下:
1 2 3 45 6 7 8此代码使用默认的行主序布局策略. 以下代码片段改用列主序布局策略. 由于布局策略是第三个模板类型参数,因此你还必须指定第一和第二个模板类型参数. 代码现在不再将每个维度的大小作为参数传递给构造函数,而是传递一个 std::extents 作为第二个模板类型参数:
mdspan<int, extents<int, 2, 4>, layout_left> data2D { data.data() };现在的输出如下所示:
1 3 5 72 4 6 8这个 mdspan 定义将所有维度的范围(extent)指定为编译时常量,即静态维度(static extents). 也可以将静态维度和动态维度结合使用. 以下示例将第一个维度指定为编译时常量,将第二个维度指定为动态维度. 然后,你必须将所有动态维度的大小作为参数传递给构造函数.
mdspan<int, extents<int, 2, dynamic_extent>> data2D { data.data(), 4 };输出再次如下:
1 2 3 45 6 7 8除了标准的序列容器外,标准库还提供了三种容器适配器(container adapters):queue、priority_queue 和 stack. 这些适配器中的每一个都是对某个序列容器的包装. 它们允许你在不更改其余代码的情况下交换底层的容器. 适配器的目的是简化接口,并仅提供适合 stack、queue 或 priority_queue 抽象的功能. 这些适配器不提供对底层容器的访问,因此是第 4 章“设计专业的 C++ 程序”中解释的数据隐藏原则的完美示例. 例如,适配器不提供同时删除多个元素的能力,也不提供迭代器. 后者意味着你不能将它们与基于范围的 for 循环或第 20 章中讨论的任何标准迭代器算法一起使用. 不过,从 C++23 开始,std::format() 和 print() 函数支持格式化和打印这些容器适配器的内容.
定义在 <queue> 中的 queue(队列)容器适配器提供标准的先进先出(FIFO)语义. 像往常一样,它被编写为一个类模板,如下所示:
template <typename T, typename Container = deque<T>> class queue;T 模板参数指定你打算存储在 queue 中的类型. 第二个模板参数允许你规定 queue 所适配的底层容器. 然而,queue 要求序列容器同时支持 push_back() 和 pop_front(),因此你只有两个内置选择:deque 和 list. 对于大多数用途,你只需使用默认的 deque 即可.
queue 操作
Section titled “queue 操作”queue 接口极其简单:只有九个成员函数、一组构造函数和比较运算符. C++23 中新增了一个接受迭代器对 [begin, end) 的构造函数,它会构造一个包含给定迭代器范围内元素的 queue. push() 和 emplace() 成员函数在队列末尾添加一个新元素,而 pop() 移除队列开头的元素. C++23 增加了 push_range() 以向 queue 添加一个范围的元素. 你分别通过 front() 和 back() 获取对第一个和最后一个元素的引用,而不会将其移除. 像往常一样,当在 const 对象上调用时,front() 和 back() 返回 const 引用;当在非 const 对象上调用时,它们返回非 const 引用(可读写).
pop() 不返回弹出的元素. 如果你想保留副本,必须先通过 front() 获取它.
队列还支持 size()、empty() 和 swap().
queue 示例:网络数据包缓冲区
Section titled “queue 示例:网络数据包缓冲区”当两台计算机通过网络通信时,它们相互发送的信息被划分为离散的块,称为数据包(packets). 计算机操作系统的网络层必须在数据包到达时接收并存储它们. 然而,计算机可能没有足够的带宽一次性处理所有数据包. 因此,网络层通常会缓冲(buffer)或存储这些数据包,直到更高层有机会处理它们. 数据包应按到达顺序进行处理,因此这个问题非常适合使用 queue 结构. 下面是一个简单的 PacketBuffer 类,附有解释代码的注释,它将传入的数据包存储在 queue 中,直到它们被处理. 它是一个类模板,以便网络堆栈的不同层可以将其用于不同种类的数据包,如 IP 数据包或 TCP 数据包. 它允许客户端指定最大大小,因为操作系统通常会限制可以存储的数据包数量,以免消耗过多内存. 当缓冲区满时,随后到达的数据包将被忽略.
export template <typename T>class PacketBuffer final{ public: // 如果 maxSize 为 0,则大小不受限制,因为创建大小为 0 的缓冲区 // 没什么意义. 否则,缓冲区在任何时候仅允许容纳 maxSize 个数据包. explicit PacketBuffer(std::size_t maxSize = 0);
// 在缓冲区中存储一个数据包. // 如果数据包因缓冲区无剩余空间而被丢弃,则返回 false,否则返回 true. bool bufferPacket(const T& packet);
// 返回下一个数据包. 如果缓冲区为空,则抛出 out_of_range. [[nodiscard]] T getNextPacket(); private: std::queue<T> m_packets; std::size_t m_maxSize;};
template <typename T> PacketBuffer<T>::PacketBuffer(std::size_t maxSize/*= 0*/) : m_maxSize { maxSize }{}
template <typename T> bool PacketBuffer<T>::bufferPacket(const T& packet){ if (m_maxSize > 0 && m_packets.size() == m_maxSize) { // 无剩余空间. 丢弃数据包. return false; } m_packets.push(packet); return true;}
template <typename T> T PacketBuffer<T>::getNextPacket(){ if (m_packets.empty()) { throw std::out_of_range { "Buffer is empty" }; } // 获取头部元素 T temp { m_packets.front() }; // 弹出头部元素 m_packets.pop(); // 返回头部元素 return temp;}该类的实际应用需要多线程. 然而,如果没有显式的同步,当至少有一个线程修改对象时,任何标准库对象都无法安全地在多线程中使用. C++ 提供了同步类来允许对共享对象进行线程安全访问. 这在第 27 章“使用 C++ 进行多线程编程”中讨论. 本例的重点是 queue 类,因此这里是一个使用 PacketBuffer 的单线程示例:
class IPPacket final{ public: explicit IPPacket(int id) : m_id { id } {} int getID() const { return m_id; } private: int m_id;};
int main(){ PacketBuffer<IPPacket> ipPackets { 3 };
// 添加 4 个数据包 for (int i { 1 }; i <= 4; ++i) { if (!ipPackets.bufferPacket(IPPacket { i })) { println("Packet {} dropped (queue is full).", i); } }
while (true) { try { IPPacket packet { ipPackets.getNextPacket() }; println("Processing packet {}", packet.getID()); } catch (const out_of_range&) { println("Queue is empty."); break; } }}该程序的输出如下:
Packet 4 dropped (queue is full).Processing packet 1Processing packet 2Processing packet 3Queue is empty.priority_queue
Section titled “priority_queue”优先队列(priority queue)是一种使其元素保持排序顺序的队列. 在任何给定时间,队列头部的元素不是严格的 FIFO 顺序,而是具有最高优先级的元素. 该元素可以是队列中最旧的,也可以是最新的. 如果两个元素具有相同的优先级,它们在队列中的相对顺序是未定义的.
priority_queue 容器适配器也定义在 <queue> 中. 其模板定义如下(略有简化):
template <typename T, typename Container = vector<T>, typename Compare = less<T>>;它并不像看起来那么复杂. 前两个参数你已经见过:T 是存储在 priority_queue 中的元素类型,Container 是 priority_queue 所适配的底层容器. priority_queue 默认使用 vector,但使用 deque 也可以. list 不行,因为 priority_queue 要求对其元素进行随机访问. 第三个参数 Compare 比较棘手. 你将在第 19 章中详细了解到,less 是一个类模板,支持使用 operator< 比较两个 T 类型的对象. 这意味着 priority_queue 中元素的优先级是根据 operator< 确定的. 你可以自定义所使用的比较逻辑,但这是第 19 章的主题. 目前,只需确保存储在 priority_queue 中的类型支持 operator< 即可. 当然,自 C++20 起,提供 operator<=> 就足够了,它会自动提供 operator<.
priority_queue 操作
Section titled “priority_queue 操作”priority_queue 提供的手法比 queue 还要少. push()、emplace() 和 push_range() (C++23) 成员函数允许你插入元素,pop() 允许你移除元素,top() 返回指向头部元素的 const 引用.
即使在非 const 对象上调用,top() 也会返回 const 引用,因为修改元素可能会改变其顺序,这是不允许的. priority_queue 不提供获取尾部元素的机制.
pop() 不返回弹出的元素. 如果你想保留副本,必须先通过 top() 获取它.
与 queue 一样,priority_queue 支持 size()、empty() 和 swap(). 但是,它不提供任何比较运算符.
priority_queue 示例:错误关联器
Section titled “priority_queue 示例:错误关联器”系统上的单一故障通常会导致不同组件产生多个错误. 一个好的错误处理系统使用错误关联(error correlation)来优先处理最重要的错误. 你可以使用 priority_queue 编写一个简单的错误关联器. 假设所有错误事件都对自己优先级进行编码. 错误关联器只需根据错误事件的优先级对其进行排序,以便始终首先处理优先级最高的错误. 以下是类定义:
// 示例 Error 类,仅包含优先级和字符串错误描述.export class Error final{ public: explicit Error(int priority, std::string errorString) : m_priority { priority }, m_errorString { std::move(errorString) } { } int getPriority() const { return m_priority; } const std::string& getErrorString() const { return m_errorString; } // 根据优先级比较 Error. auto operator<=>(const Error& rhs) const { return getPriority() <=> rhs.getPriority(); } private: int m_priority; std::string m_errorString;};
// Error 的流插入重载.export std::ostream& operator<<(std::ostream& os, const Error& err){ std::print(os, "{} (priority {})", err.getErrorString(), err.getPriority()); return os;}
// 简单的 ErrorCorrelator 类,首先返回优先级最高的错误.export class ErrorCorrelator final{ public: // 添加一个待关联的错误. void addError(const Error& error) { m_errors.push(error); } // 获取下一个待处理的错误. [[nodiscard]] Error getError() { // 如果没有更多错误,则抛出异常. if (m_errors.empty()) { throw std::out_of_range { "No more errors." }; } // 保存顶部元素. Error top { m_errors.top() }; // 移除顶部元素. m_errors.pop(); // 返回保存的元素. return top; } private: std::priority_queue<Error> m_errors;};下面是一个展示如何使用 ErrorCorrelator 的简单测试. 在实际应用中需要多线程,以便一个线程添加错误,另一个线程处理错误. 正如之前在 queue 示例中提到的,这需要显式同步,详见第 27 章.
ErrorCorrelator ec;ec.addError(Error { 3, "Unable to read file" });ec.addError(Error { 1, "Incorrect entry from user" });ec.addError(Error { 10, "Unable to allocate memory!" });
while (true) { try { Error e { ec.getError() }; cout << e << endl; } catch (const out_of_range&) { println("Finished processing errors"); break; }}该程序的输出如下:
Unable to allocate memory! (priority 10)Unable to read file (priority 3)Incorrect entry from user (priority 1)Finished processing errorsstack(栈)与 queue 几乎完全相同,不同之处在于它提供先进后出(FILO)语义(也称为后进先出,LIFO),而不是 FIFO. 它定义在 <stack> 中. 模板定义如下:
template <typename T, typename Container = deque<T>> class stack;你可以使用 vector、list 或 deque 作为 stack 的底层容器.
stack 操作
Section titled “stack 操作”与 queue 一样,C++23 增加了接受迭代器对 [begin, end) 的构造函数,它会构造一个包含给定迭代器范围内元素的 stack. 同样与 queue 类似,stack 提供 push()、emplace()、pop() 和 push_range() (C++23). 区别在于 push() 和 push_range() 向 stack 的顶部添加新元素,将之前插入的所有元素“向下推”,而 pop() 从 stack 的顶部移除元素,即移除最近插入的元素. top() 成员函数如果在 const 对象上调用,则返回 const 引用;如果在非 const 对象上调用,则返回非 const 引用.
pop() 不返回弹出的元素. 如果你想保留副本,必须先通过 top() 获取它.
stack 支持 empty()、size()、swap() 和标准比较运算符.
stack 示例:修订后的错误关联器
Section titled “stack 示例:修订后的错误关联器”你可以重写之前的 ErrorCorrelator 类,使其给出最近发生的错误,而不是优先级最高的错误. 唯一需要的更改是将 m_errors 从 priority_queue 更改为 stack. 通过这一更改,错误将按 LIFO 顺序而不是优先级顺序分发. 成员函数定义中的任何内容都不需要更改,因为 push()、pop()、top() 和 empty() 成员函数在 priority_queue 和 stack 上都存在.
C++ 标准库提供了几种不同类型的关联容器:
- 有序关联容器:
map、multimap、set和multiset. - 无序关联容器:
unordered_map、unordered_multimap、unordered_set和unordered_multiset. 这些也被称为哈希表(hash tables). 平面关联容器适配器: flat_map、flat_multimap、flat_set和flat_multiset. 这些适配序列容器使其表现得像有序关联容器.
有序关联容器
Section titled “有序关联容器”与序列容器不同,有序关联容器(ordered associative containers)不按线性配置存储元素. 相反,它们提供键(key)到值(value)的映射. 它们通常提供的插入、删除和查找时间彼此相当.
标准库提供了四种有序关联容器:map、multimap、set 和 multiset. 这些容器中的每一个都将其元素存储在一个有序的、树状的数据结构中.
pair 实用类
Section titled “pair 实用类”在深入研究有序关联容器之前,让我们先回顾一下第 1 章中简要介绍过的 pair 类模板. 它定义在 <utility> 中,将两个可能具有不同类型的值组合在一起. 可以通过 first 和 second 公共数据成员访问这些值. 支持所有比较运算符,并同时比较 first 和 second 值. 示例如下:
// 双参数构造函数和默认构造函数pair<string, int> myPair { "hello", 5 };pair<string, int> myOtherPair;
// 可以直接对 first 和 second 赋值myOtherPair.first = "hello";myOtherPair.second = 6;
// 拷贝构造函数pair<string, int> myThirdPair { myOtherPair };
// operator<if (myPair < myOtherPair) { println("myPair is less than myOtherPair");} else { println("myPair is greater than or equal to myOtherPair");}
// operator==if (myOtherPair == myThirdPair) { println("myOtherPair is equal to myThirdPair");} else { println("myOtherPair is not equal to myThirdPair");}输出如下:
myPair is less than myOtherPairmyOtherPair is equal to myThirdPair有了类模板参数推导(CTAD),你可以省略模板类型参数. 示例如下. 注意标准字符串字面量 s 的使用.
pair myPair { "hello"s, 5 }; // 类型为 pair<string, int>.在 C++17 引入对 CTAD 的支持之前,可以使用 std::make_pair() 实用函数模板从两个值构造 pair. 以下是构造 int 和 double 的 pair 的三种方式:
pair<int, double> pair1 { make_pair(5, 10.10) };auto pair2 { make_pair(5, 10.10) };pair pair3 { 5, 10.10 }; // CTAD定义在 <map> 中的 map 存储键/值对,而不只是单个值. 插入、查找和删除都基于键;值只是“搭便车”. 术语 map 源于该容器将键“映射”到值的概念理解.
map 根据键使元素保持有序,从而使插入、删除和查找都花费对数时间. 由于这种顺序,当你枚举元素时,它们会按照类型的 operator< 或用户定义的比较器所强加的顺序出现. 它通常实现为某种形式的平衡树,如红黑树. 然而,树结构并不暴露给客户端.
每当你需要基于“键”存储和检索元素,并且希望它们按特定顺序排列时,都应该使用 map.
构造 map
Section titled “构造 map”map 类模板接受四个类型:键类型、值类型、比较器类型和分配器类型. 一如既往,本章忽略分配器. 比较器类似于前面描述的 priority_queue 的比较器. 它允许你更改默认的比较行为. 在本章中,仅使用默认的 less 比较器. 使用默认值时,请确保你的键都能对 operator< 做出适当响应. 如果你对更多细节感兴趣,第 19 章解释了如何编写自己的比较器.
如果忽略比较器和分配器参数,构造 map 就像构造 vector 或 list 一样,只是你在模板实例化中分别指定键和值的类型. 例如,以下代码构造了一个 map,它使用 int 作为键,将 Data 类的对象作为值:
class Data final{ public: explicit Data(int value = 0) : m_value { value } { } int getValue() const { return m_value; } void setValue(int value) { m_value = value; } private: int m_value;};…map<int, Data> dataMap;在内部,dataMap 为 map 中的每个元素存储一个 pair<int, Data>.
map 也支持统一初始化. 以下 map 在内部存储 pair<string, int> 实例:
map<string, int> m { { "Marc G.", 12 }, { "Warren B.", 34 }, { "Peter V.W.", 56 }};类模板参数推导不像通常那样工作. 例如,以下代码无法通过编译:
map m { { "Marc G."s, 12 }, { "Warren B."s, 34 }, { "Peter V.W."s, 56 }};这是因为编译器无法从 {"Marc G."s, 12} 等内容推导出 pair<string, int>. 如果你确实想这样做,可以按如下方式编写(注意字符串字面量的 s 后缀!):
map m { pair { "Marc G."s, 12 }, pair { "Warren B."s, 34 }, pair { "Peter V.W."s, 56 }};
Section titled “ 格式化与打印 Map”与 vector 一样,std::format() 和 print() 函数可以用单条语句格式化并打印整个 map. 对于 vector,输出用方括号括起来,每个元素用逗号分隔. 对于 map,输出略有不同:输出用花括号括起来,每个键/值对用逗号分隔,键和值之间用冒号分隔. 例如,打印上一节中的 map m 会得到以下输出:
{"Marc G.": 12, "Peter V.W.": 56, "Warren B.": 34}向 vector 和 list 等序列容器插入元素总是需要你指定添加元素的位置. map 以及其他有序关联容器则不同. map 的内部实现决定了存储新元素的位置;你只需要提供键和值.
在插入元素时,必须牢记 map 要求键是唯一的:map 中的每个元素必须具有不同的键. 如果你想支持具有相同键的多个元素,你有两个选择:要么使用 map 并存储另一个容器(如 vector)作为该键的值,要么使用稍后描述的 multimap.
insert() 成员函数
Section titled “insert() 成员函数”insert() 成员函数可用于向 map 添加元素,其优点是允许你检测键是否已存在. 你必须将键/值对指定为 pair 对象或 initializer_list. 基本形式的 insert() 的返回类型是 iterator 和 bool 的 pair. 之所以使用这种复杂的返回类型,是因为如果具有指定键的值已存在,insert() 不会覆盖该值. 返回的 pair 的 bool 元素指定 insert() 是否实际插入了新的键/值对. iterator 指向 map 中具有指定键的元素(具有新值或旧值,具体取决于插入是成功还是失败). map 迭代器将在下一节中详细讨论. 继续上一节的 map 示例,你可以像下面这样使用 insert():
map<int, Data> dataMap;
auto ret { dataMap.insert({ 1, Data { 4 } }) }; // 使用 initializer_listif (ret.second) { println("Insert succeeded!"); }else { println("Insert failed!"); }
ret = dataMap.insert(make_pair(1, Data { 6 })); // 使用 pair 对象if (ret.second) { println("Insert succeeded!"); }else { println("Insert failed!"); }ret 变量的类型是一个如下所示的 pair:
pair<map<int, Data>::iterator, bool> ret;pair 的第一个元素是键类型为 int 且值类型为 Data 的 map 的迭代器. pair 的第二个元素是一个布尔值.
该程序的输出如下:
Insert succeeded!Insert failed!通过 if 语句初始化器,可以将数据插入 map 并检查结果合并为单条语句,如下所示:
if (auto result { dataMap.insert({ 1, Data { 4 } }) }; result.second) { println("Insert succeeded!");} else { println("Insert failed!");}这还可以进一步与结构化绑定结合使用:
if (auto [iter, success] { dataMap.insert({ 1, Data { 4 } }) }; success) { println("Insert succeeded!");} else { println("Insert failed!");}insert_or_assign() 成员函数
Section titled “insert_or_assign() 成员函数”insert_or_assign() 具有与 insert() 类似的返回类型. 然而,如果具有给定键的元素已经存在,insert_or_assign() 会用新值覆盖旧值,而在这种情况下 insert() 不会覆盖旧值. 与 insert() 的另一个区别是,insert_or_assign() 有两个独立的参数:键和值. 示例如下:
auto ret { dataMap.insert_or_assign(1, Data { 7 }) };if (ret.second) { println("Inserted."); }else { println("Overwritten."); }
Section titled “ insert_range() 成员函数”C++23 为 map 增加了 insert_range(),可用于将给定范围的所有元素插入 map,并返回指向第一个添加元素的迭代器. 示例如下:
vector<pair<int, Data>> moreData { {2, Data{22}}, {3, Data{33}}, {4, Data{44}} };dataMap.insert_range(moreData);operator[]
Section titled “operator[]”向 map 插入元素的另一种成员函数是通过重载的 operator[]. 区别主要在于语法:你分别指定键和值. 此外,operator[] 总是成功的. 如果不存在具有给定键的值,它会使用该键和值创建一个新元素. 如果具有该键的元素已经存在,operator[] 会用新指定的值替换旧值. 下面是使用 operator[] 而非 insert() 的前一个示例的一部分:
map<int, Data> dataMap;dataMap[1] = Data { 4 };dataMap[1] = Data { 6 }; // 替换键为 1 的元素
然而,`operator[]` 有一个主要的注意事项:它总是构造一个新的值对象,即使不需要使用它。因此,它要求元素值具有默认构造函数,并且可能比 `insert()` 效率低。
如果请求的元素尚不存在,`operator[]` 会在 `map` 中创建一个新元素,这一事实意味着该操作符没有被标记为 `const`。这听起来很明显,但有时可能看起来违反直觉。例如,假设你有以下函数:
```cppvoid func(const map<int, int>& m){ println("{}", m[1]); // 错误}这无法编译,即使你看起来只是在读取值 m[1]。它失败是因为参数 m 是指向 map 的 const 引用,而 operator[] 没有被标记为 const。在这种情况下,你应该改用“查找元素”一节中描述的 find() 或 at() 成员函数。
Emplace 成员函数
Section titled “Emplace 成员函数”map 支持 emplace() 和 emplace_hint() 来原位构造元素,类似于 vector 的 emplace 成员函数。还有一个 try_emplace() 成员函数,如果给定的键尚不存在,它会原位插入一个元素;如果该键已存在于 map 中,则不执行任何操作。
map 迭代器
Section titled “map 迭代器”map 迭代器的工作方式与顺序容器上的迭代器类似。主要的区别在于迭代器引用的是键/值 pair,而不仅仅是值。要访问该值,你必须检索 pair 对象的 second 字段。map 迭代器是双向的,这意味着你可以双向遍历它们。下面是如何遍历前一个示例中的 map:
for (auto iter { cbegin(dataMap) }; iter != cend(dataMap); ++iter) { println("{}", iter->second.getValue());}再看一眼用于访问值的表达式:
iter->second.getValue()iter 指向一个键/值 pair,因此你可以使用 -> 运算符访问该 pair 的 second 字段,这是一个 Data 对象。然后你可以对该 Data 对象调用 getValue() 成员函数。
请注意,以下代码在功能上是等效的:
(*iter).second.getValue()使用基于范围的 for 循环(range-based for loop),该循环可以写得更具可读性且更不容易出错,如下所示:
for (const auto& p : dataMap) { println("{}", p.second.getValue());}结合使用基于范围的 for 循环和结构化绑定(structured bindings),可以实现得更加优雅:
for (const auto& [key, data] : dataMap) { println("{}", data.getValue());}你可以通过非 const 迭代器修改元素的值,但如果你尝试修改元素的键,即使是通过非 const 迭代器,编译器也会生成错误,因为这会破坏 map 中元素的排序顺序。
map 基于提供的键提供元素的对数级(logarithmic)查找。如果你已经知道具有给定键的元素在 map 中,查找它的最简单方法是通过 operator[],只要你在非 const map 或非 const map 的引用上调用它。operator[] 的优点在于它返回对值的引用,你可以直接使用和修改该值,而无需担心从 pair 对象中取出该值。下面是前一个示例的扩展,对键为 1 的 Data 对象值调用 setValue() 成员函数:
map<int, Data> dataMap;dataMap[1] = Data { 4 };dataMap[1] = Data { 6 };dataMap[1].setValue(100);作为替代方案,map 提供了一个 find() 成员函数,它返回一个指向具有所请求键的键/值 pair 的迭代器(如果存在),或者如果 map 中未找到该键,则返回 end() 迭代器。这在以下情况下很有用:
- 如果你不知道该元素是否存在,你可能不想使用
operator[],因为如果它没有找到已经存在的元素,它会插入一个具有该键的新元素。 - 如果你有一个
const或指向const map的引用,在这种情况下你不能使用operator[]。
下面是一个使用 find() 对键为 1 的 Data 对象执行相同修改的示例:
auto it { dataMap.find(1) };if (it != end(dataMap)) { it->second.setValue(100);}如你所见,使用 find() 稍微笨拙一些,但有时是必要的。
或者,你可以使用 at() 成员函数,就像 operator[] 一样,如果所请求键的元素存在,它会返回对 map 中该值的引用。如果 map 中未找到所请求的键,它会抛出 out_of_range 异常。at() 成员函数在 const 或指向 const map 的引用上也能正常工作。例如:
dataMap.at(1).setValue(200);如果你只想知道具有某个键的元素是否在 map 中,可以使用 count() 成员函数。它返回 map 中具有给定键的元素数量。对于 map,结果始终为 0 或 1,因为不能有重复键的元素。
此外,所有关联容器(有序、无序和 flat)都有一个名为 contains() 的成员函数。如果容器中存在给定的键,它返回 true,否则返回 false。有了这个函数,就不再需要使用 count() 来确定关联容器中是否存在某个键。下面是一个示例:
auto isKeyInMap { dataMap.contains(1) };map 允许你在特定的迭代器位置删除元素,或者删除给定迭代器范围内的所有元素,时间复杂度分别为摊销常数级和对数级。从客户端的角度来看,这两个 erase() 成员函数与顺序容器中的等效。然而,map 的一个强大特性是它还提供了一个版本的 erase() 来删除匹配某个键的元素。下面是一个示例:
map<int, Data> dataMap;dataMap[1] = Data { 4 };println("There are {} elements with key 1.", dataMap.count(1));dataMap.erase(1);println("There are {} elements with key 1.", dataMap.count(1));输出如下:
There are 1 elements with key 1.There are 0 elements with key 1.所有有序和无序关联容器都是基于节点的数据结构。标准库以节点句柄的形式提供对节点的直接访问。确切的类型未指定,但每个容器都有一个名为 node_type 的类型别名,它指定了该容器的节点句柄类型。节点句柄只能被移动,并且是存储在节点中的元素的拥有者。它提供对键和值的读/写访问。
可以使用 extract() 成员函数,根据给定的迭代器位置或给定的键,从关联容器中提取节点作为节点句柄。从容器中提取节点会将其从容器中移除,因为返回的节点句柄是提取元素的唯一拥有者。
还提供了新的 insert() 重载,允许你将节点句柄插入容器。
通过使用 extract() 提取节点句柄并使用 insert() 插入节点句柄,你可以有效地将数据从一个关联容器传输到另一个关联容器,而无需进行任何拷贝或移动。你甚至可以将节点从 map 传输到 multimap,以及从 set 传输到 multiset。延续上一节的示例,以下代码片段将键为 1 的节点从 dataMap 传输到第二个名为 dataMap2 的 map:
map<int, Data> dataMap2;auto extractedNode { dataMap.extract(1) };dataMap2.insert(move(extractedNode));最后两行可以合并为一行:
dataMap2.insert(dataMap.extract(1));还有一种操作可用于将所有节点从一个关联容器移动到另一个容器:merge()。由于会导致目标容器(不允许重复)中出现重复而无法移动的节点,将保留在源容器中。下面是一个示例:
map<int, int> src { {1, 11}, {2, 22} };map<int, int> dst { {2, 22}, {3, 33}, {4, 44}, {5, 55} };dst.merge(src);println("src = {}", src); // src = {2: 22}println("dst = {}", dst); // dst = {1: 11, 2: 22, 3: 33, 4: 44, 5: 55}合并操作后,src 仍包含一个元素 {2: 22},因为目标容器已包含此类元素,因此无法移动。
map 示例:银行账户
Section titled “map 示例:银行账户”你可以使用 map 实现一个简单的银行账户数据库。一种常见的模式是将键作为存储在 map 中的 class 或 struct 的一个字段。在这种情况下,键是账号。下面是简单的 BankAccount 和 BankDB 类:
export class BankAccount final{ public: explicit BankAccount(int accountNumber, std::string name) : m_accountNumber { accountNumber }, m_clientName { std::move(name) }{}
void setAccountNumber(int accountNumber) { m_accountNumber = accountNumber; } int getAccountNumber() const { return m_accountNumber; }
void setClientName(std::string name) { m_clientName = std::move(name); } const std::string& getClientName() const { return m_clientName; } private: int m_accountNumber; std::string m_clientName;};
export class BankDB final{ public: // 向银行数据库添加账户。如果该账号已存在账户,则不添加新账户。 // 如果账户已添加则返回 true,否则返回 false。 bool addAccount(const BankAccount& account);
// 从数据库中删除账号为 accountNumber 的账户。 void deleteAccount(int accountNumber);
// 返回由账号或客户姓名表示的账户引用。 // 如果未找到账户,则抛出 out_of_range 异常。 BankAccount& findAccount(int accountNumber); BankAccount& findAccount(std::string_view name);
// 将 db 中的所有账户添加到此数据库。 // 从 db 中删除所有账户。 void mergeDatabase(BankDB& db); private: std::map<int, BankAccount> m_accounts;};下面是 BankDB 成员函数的实现,并附有代码解释:
bool BankDB::addAccount(const BankAccount& account){ // 执行实际插入,使用账号作为键。 auto res { m_accounts.emplace(account.getAccountNumber(), account) }; // 或者:auto res { m_accounts.insert( // pair { account.getAccountNumber(), account }) };
// 返回 pair 的 bool 字段,指定成功或失败。 return res.second;}
void BankDB::deleteAccount(int accountNumber){ m_accounts.erase(accountNumber);}
BankAccount& BankDB::findAccount(int accountNumber){ // 可以通过 find() 通过键查找元素。 auto it { m_accounts.find(accountNumber) }; if (it == end(m_accounts)) { throw out_of_range { format("No account with number {}.", accountNumber) }; } // 记住,指向 map 的迭代器引用的是键/值 pair。 return it->second;}
BankAccount& BankDB::findAccount(string_view name){ // 通过非键属性查找元素需要对元素进行线性搜索。 // 以下使用了结构化绑定(structured bindings)。 for (auto& [accountNumber, account] : m_accounts) { if (account.getClientName() == name) { return account; // 找到了! } } throw out_of_range { format("No account with name '{}'.", name) };}
void BankDB::mergeDatabase(BankDB& db){ // 使用 merge()。 m_accounts.merge(db.m_accounts); // 或者:m_accounts.insert(begin(db.m_accounts), end(db.m_accounts));
// 现在清空源数据库。 db.m_accounts.clear();}你可以使用以下代码测试 BankDB 类:
BankDB db;db.addAccount(BankAccount { 100, "Nicholas Solter" });db.addAccount(BankAccount { 200, "Scott Kleper" });
try { auto& account { db.findAccount(100) }; println("Found account 100"); account.setClientName("Nicholas A Solter");
auto& account2 { db.findAccount("Scott Kleper") }; println("Found account of Scott Kleper");
auto& account3 { db.findAccount(1000) };} catch (const out_of_range& caughtException) { println("Unable to find account: {}", caughtException.what());}输出如下:
Found account 100Found account of Scott KleperUnable to find account: No account with number 1000.multimap
Section titled “multimap”multimap 是一种允许具有相同键的多个元素的 map。与 map 一样,multimap 支持统一初始化。其接口与 map 接口几乎完全相同,但有以下区别:
multimap不提供operator[]和at()。如果一个键可以对应多个元素,这些操作符的语义就没有意义。- 在
multimap上插入总是成功的。因此,添加单个元素的multimap::insert()成员函数仅返回一个迭代器,而不是pair。 map支持的insert_or_assign()和try_emplace()成员函数在multimap中不支持。
multimap 最棘手的方面是查找元素。你不能使用 operator[],因为它未提供。find() 不是很有用,因为它返回指向具有给定键的任何一个元素的迭代器(不一定是该键的第一个元素)。
然而,multimap 将具有相同键的所有元素存储在一起,并提供成员函数来获取容器中具有相同键的该子范围元素的迭代器。lower_bound() 和 upper_bound() 成员函数各返回一个迭代器,分别指向匹配给定键的第一个元素和最后一个元素之后的一个位置。如果没有匹配该键的元素,lower_bound() 和 upper_bound() 返回的迭代器将相等。
如果你需要获取限定具有给定键元素的两个迭代器,使用 equal_range() 比先调用 lower_bound() 再调用 upper_bound() 更有效。equal_range() 成员函数返回这两个迭代器的 pair,它们与 lower_bound() 和 upper_bound() 返回的迭代器相同。
multimap 示例:好友列表
Section titled “multimap 示例:好友列表”许多在线聊天程序都允许用户拥有“好友列表”(buddy list)或朋友列表。聊天程序赋予好友列表中的用户特殊特权,例如允许他们向该用户发送未经请求的消息。
为在线聊天程序实现好友列表的一种方法是将信息存储在 multimap 中。一个 multimap 可以存储每个用户的好友列表。容器中的每个条目为一个用户存储一个好友。键是用户,值是好友。例如,如果 Harry Potter 和 Ron Weasley 各自在彼此的好友列表中,则会有两个条目,形式为 “Harry Potter” 映射到 “Ron Weasley” 和 “Ron Weasley” 映射到 “Harry Potter”。multimap 允许同一个键有多个值,因此同一个用户允许有多个好友。下面是 BuddyList 类定义:
export class BuddyList final{ public: // 将 buddy 添加为 name 的朋友。 void addBuddy(const std::string& name, const std::string& buddy); // 将 buddy 从 name 的朋友列表中移除。 void removeBuddy(const std::string& name, const std::string& buddy); // 如果 buddy 是 name 的朋友,返回 true,否则返回 false。 bool isBuddy(const std::string& name, const std::string& buddy) const; // 检索 name 的所有朋友列表。 std::vector<std::string> getBuddies(const std::string& name) const; private: std::multimap<std::string, std::string> m_buddies;};下面是实现,并附有代码解释。它演示了 lower_bound()、upper_bound() 和 equal_range() 的用法。
void BuddyList::addBuddy(const string& name, const string& buddy){ // 确保这个好友尚未存在。我们不想插入键/值 pair 的完全相同的副本。 if (!isBuddy(name, buddy)) { m_buddies.insert({ name, buddy }); // 使用 initializer_list }}
void BuddyList::removeBuddy(const string& name, const string& buddy){ // 获取键为 'name' 的元素范围的开始和结束。 // 同时使用 lower_bound() 和 upper_bound() 以演示其用法。 // 否则,调用 equal_range() 会更高效。 auto begin { m_buddies.lower_bound(name) }; // 范围开始 auto end { m_buddies.upper_bound(name) }; // 范围结束
// 遍历键为 'name' 的元素,寻找值为 'buddy' 的元素。 // 如果没有键为 'name' 的元素,begin 等于 end,因此循环体不会执行。 for (auto iter { begin }; iter != end; ++iter) { if (iter->second == buddy) { // 找到了匹配项!将其从 map 中移除。 m_buddies.erase(iter); break; } }}
bool BuddyList::isBuddy(const string& name, const string& buddy) const{ // 使用 equal_range() 和结构化绑定(structured bindings)获取键为 'name' 的元素范围。 auto [begin, end] { m_buddies.equal_range(name) };
// 遍历键为 'name' 的元素,寻找值为 'buddy' 的元素。 for (auto iter { begin }; iter != end; ++iter) { if (iter->second == buddy) { // 找到了匹配项! return true; } } // 未找到匹配项 return false;}
vector<string> BuddyList::getBuddies(const string& name) const{ // 使用 equal_range() 和结构化绑定(structured bindings)获取键为 'name' 的元素范围。 auto [begin, end] { m_buddies.equal_range(name) };
// 创建一个包含范围内所有姓名(name 的所有好友)的 vector。 vector<string> buddies; for (auto iter { begin }; iter != end; ++iter) { buddies.push_back(iter->second); } return buddies;}请 note,removeBuddy() 不能简单地使用删除给定键的所有元素的 erase() 版本,因为它应该只删除具有该键的一个元素,而不是全部。另请 note,getBuddies() 不能在 vector 上使用 insert() 来插入 equal_range() 返回的范围内的元素,因为 multimap 迭代器引用的元素是键/值 pair,而不是 string。getBuddies() 成员函数必须显式遍历该范围,从每个键/值 pair 中提取 string,并将其推入要返回的新 vector 中。
或者,利用 第 17 章 讨论的 C++23 ranges 功能,getBuddies() 可以如下实现,而无需任何显式循环:
vector<string> BuddyList::getBuddies(const string& name) const{ auto [begin, end] { m_buddies.equal_range(name) }; return ranges::subrange { begin, end } | views::values | ranges::to<vector>();}下面是对 BuddyList 的测试:
BuddyList buddies;buddies.addBuddy("Harry Potter", "Ron Weasley");buddies.addBuddy("Harry Potter", "Hermione Granger");buddies.addBuddy("Harry Potter", "Hagrid");buddies.addBuddy("Harry Potter", "Draco Malfoy");// 那不对!移除 Draco。buddies.removeBuddy("Harry Potter", "Draco Malfoy");buddies.addBuddy("Hagrid", "Harry Potter");buddies.addBuddy("Hagrid", "Ron Weasley");buddies.addBuddy("Hagrid", "Hermione Granger");
auto harrysFriends { buddies.getBuddies("Harry Potter") };
println("Harry's friends: ");for (const auto& name : harrysFriends) { println("\t{}", name);}输出如下:
Harry's friends: Ron Weasley Hermione Granger Hagridset(在 <set> 中定义)类似于 map。区别在于,set 不存储键/值对,而是将值作为键。set 对于存储没有显式键,但你希望保持排序顺序且无重复,并具有快速插入、查找和删除的信息非常有用。
set 提供的接口与 map 几乎完全相同。主要区别在于 set 不提供 operator[]、insert_or_assign() 和 try_emplace()。
你不能更改 set 中元素的值,因为在元素位于容器中时对其进行修改会破坏顺序。
set 示例:访问控制列表
Section titled “set 示例:访问控制列表”在计算机系统上实现基本安全的一种方法是通过访问控制列表。系统上的每个实体(如文件或设备)都有一个有权访问该实体的用户列表。通常,只有具有特殊权限的用户才能向实体的权限列表中添加或从中删除用户。在内部,set 提供了一种表示访问控制列表的绝佳方式。你可以为每个实体使用一个 set,其中包含允许访问该实体的所有用户名。下面是一个简单访问控制列表的类定义:
export class AccessList final{ public: // 默认构造函数 AccessList() = default; // 支持统一初始化的构造函数。 AccessList(std::initializer_list<std::string_view> users) { m_allowed.insert(begin(users), end(users)); } // 将用户添加到权限列表。 void addUser(std::string user) { m_allowed.emplace(std::move(user)); } // 从权限列表中删除用户。 void removeUser(const std::string& user) { m_allowed.erase(user); } // 如果用户在权限列表中,则返回 true。 bool isAllowed(const std::string& user) const { return m_allowed.contains(user); } // 返回所有具有权限的用户。 const std::set<std::string>& getAllUsers() const { return m_allowed; } // 返回所有具有权限的用户的 vector。 std::vector<std::string> getAllUsersAsVector() const { return { begin(m_allowed), end(m_allowed) }; } private: std::set<std::string> m_allowed;};看看 getAllUsersAsVector() 有趣的一行实现。这一行通过将 m_allowed 的开始和结束迭代器传递给 vector 构造函数,构造了一个要返回的 vector<string>。如果你愿意,可以将其拆分为两行:
std::vector<std::string> users { begin(m_allowed), end(m_allowed) };return users;最后,这是一个简单的测试程序:
AccessList fileX { "mgregoire", "baduser" };fileX.addUser("pvw");fileX.removeUser("baduser");
if (fileX.isAllowed("mgregoire")) { println("mgregoire has permissions"); }if (fileX.isAllowed("baduser")) { println("baduser has permissions"); }
// C++23 支持范围的格式化/打印,见第 2 章。println("Users with access: {:n:}", fileX.getAllUsers());
// 遍历 set 的元素。print("Users with access: ");for (const auto& user : fileX.getAllUsers()) { print("{} ", user); }println("");
// 遍历 vector 的元素。print("Users with access: ");for (const auto& user : fileX.getAllUsersAsVector()) { print("{} ", user); }println("");AccessList 的其中一个构造函数使用 initializer_list 作为参数,以便你可以使用统一初始化语法,如测试程序中初始化 fileX 所示。
该程序的输出如下:
mgregoire has permissionsUsers with access: mgregoire, pvwUsers with access: mgregoire pvwUsers with access: mgregoire pvw请注意,m_allowed 数据成员需要是 std::string 的 set,而不是 string_view 的 set。将其更改为 string_view 的 set 会引入悬空指针的问题。例如,假设你有以下代码:
AccessList fileX;{ string user { "someuser" }; fileX.addUser(user);}这段代码片段创建了一个名为 user 的 string,然后将其添加到 fileX 访问控制列表中。然而,string 和对 addUser() 的调用都在一对花括号内;也就是说,该 string 的生命周期比 fileX 短。在闭花括号处,string 离开作用域并被销毁。这将使 fileX 访问控制列表中的 string_view 指向一个已销毁的 string,即悬空指针!通过使用 string 的 set 可以避免这个问题。
multiset
Section titled “multiset”multiset 之于 set 就像 multimap 之于 map。multiset 支持 set 的所有操作,但它允许在容器中同时存储多个相等的元素。这里没有展示 multiset 的示例,因为它与 set 和 multimap 非常相似。
无序关联容器或哈希表
Section titled “无序关联容器或哈希表”标准库支持无序关联容器或哈希表。共有四种:unordered_map、unordered_multimap、unordered_set 和 unordered_multiset。前面讨论的 map、multimap、set 和 multiset 容器会对其元素进行排序,而这些无序变体则不会。
无序关联容器是哈希表。这是因为它们的实现利用了哈希函数。其实现通常由某种数组组成,数组中的每个元素称为桶(bucket)。每个桶都有一个特定的数字索引,如 0、1、2,直到最后一个桶。哈希函数将键转换为哈希值,然后哈希值再转换为桶索引。与该键关联的值随后存储在该桶中。
哈希函数的结果并不总是唯一的。两个或多个键散列到同一个桶索引的情况称为冲突(collision)。当不同的键产生相同的哈希值,或者不同的哈希值转换到同一个桶索引时,就会发生冲突。处理冲突的方法有很多,包括二次探测和拉链法等。如果你感兴趣,可以参考 附录 B 中“算法与数据结构”部分。标准库没有规定必须使用哪种冲突处理算法,但目前大多数实现都选择通过拉链法解决冲突。使用拉链法时,桶并不直接包含与键关联的数据值,而是包含一个指向链表的指针。该链表包含该特定桶的所有数据值。图 18.1 展示了其工作原理。
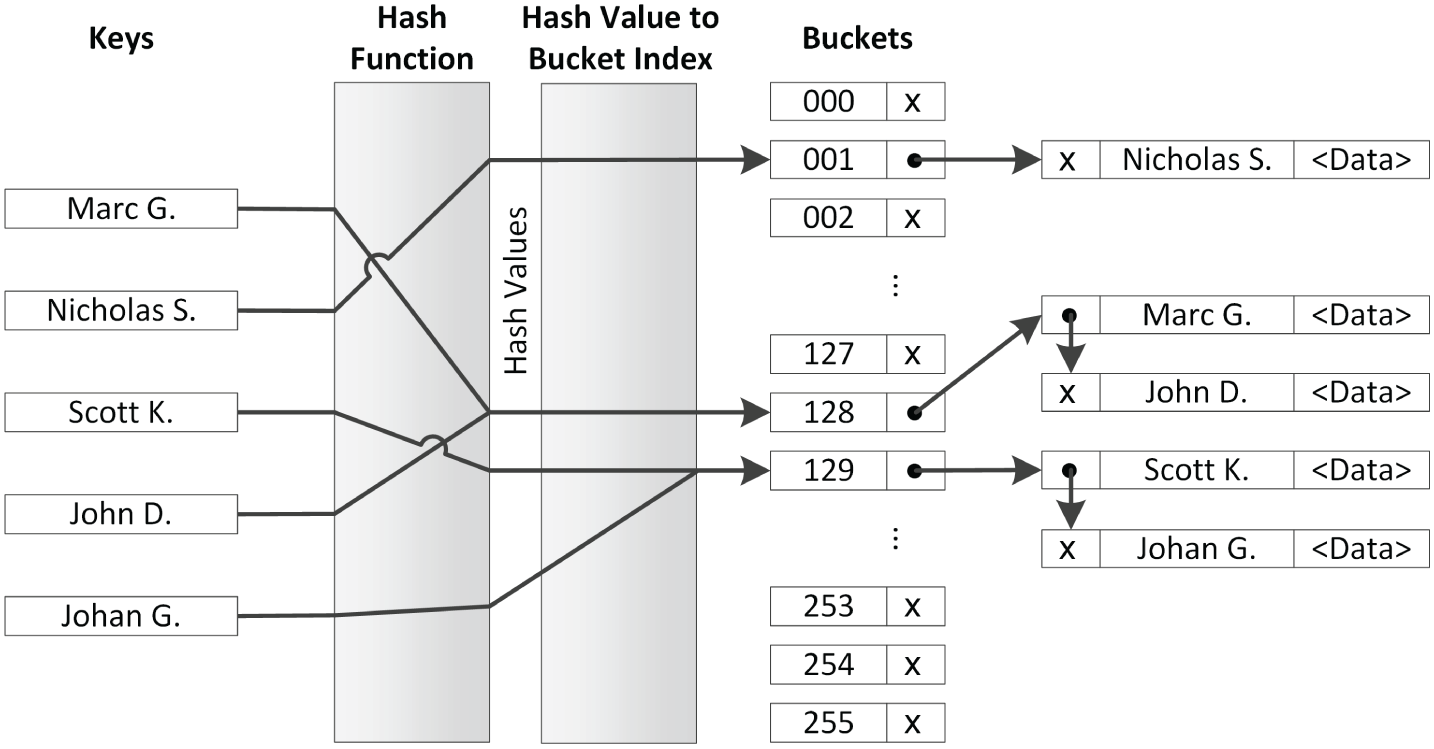
[^FIGURE 18.1]
在 图 18.1 中,发生了两次冲突。第一次冲突是因为对键“Marc G.”和“John D.”应用哈希函数得到了相同的哈希值,映射到桶索引 128。该桶随后指向一个包含键“Marc G.”和“John D.”及其关联数据值的链表。第二次冲突是由“Scott K.”和“Johan G.”的哈希值映射到同一个桶索引 129 引起的。
从 图 18.1 中,也可以清楚地看到基于键的查找是如何工作的以及复杂度是多少。查找涉及单次哈希函数调用以计算哈希值。该哈希值随后转换为桶索引。一旦桶索引已知,就需要一次或多次相等操作来在链表中找到正确的键。这表明,与普通的 map 相比,查找速度可以快得多,但这完全取决于有多少冲突。
哈希函数的选择非常重要。不产生冲突的哈希函数被称为完美哈希。完美哈希的查找时间是常数级的;普通的哈希查找时间平均接近 1,与元素数量无关。随着冲突数量的增加,查找时间也会增加,从而降低性能。可以通过增加基本哈希表的大小来减少冲突,但你需要考虑缓存大小。
C++ 标准为指针和所有原始数据类型(如 bool、char、int、float、double 等)提供了哈希函数。还为几个标准库类提供了哈希函数,如 optional、bitset、unique_ptr、shared_ptr、string、string_view、vector<bool> 等。如果你想使用的键类型没有标准的哈希函数可用,那么你必须实现自己的哈希函数。即使键集是固定且已知的,创建完美哈希也是一项不简单的任务,需要深厚的数学分析。即使是创建一个非完美但足够好且具有体面性能的哈希函数,也仍然具有挑战性。详细解释哈希函数背后的数学原理超出了本书的范围。相反,这里仅给出一个简单哈希函数的示例。
以下代码演示了如何编写自定义哈希函数。代码定义了一个类 IntWrapper,它只包装了一个整数。提供了一个 operator==,因为这是无序关联容器中使用的键的要求。
class IntWrapper{ public: explicit IntWrapper(int i) : m_wrappedInt { i } {} int getValue() const { return m_wrappedInt; } bool operator==(const IntWrapper&) const = default; // 自 C++20 起使用 = default private: int m_wrappedInt;};要为 IntWrapper 编写实际的哈希函数,你需要为 IntWrapper 编写 std::hash 类模板的特化。std::hash 类模板定义在 <functional> 中。该特化需要实现函数调用操作符,用于计算并返回给定 IntWrapper 实例的哈希值。在本例中,请求只是简单地转发给整数的标准哈希函数:
namespace std{ template<> struct hash<IntWrapper> { size_t operator()(const IntWrapper& x) const { return std::hash<int>{}(x.getValue()); } };}请注意,通常不允许在 std 命名空间中放入任何内容;但是,std 类模板特化是此规则的一个例外。函数调用操作符的实现只有一行。它创建了一个整数标准哈希函数的实例——std::hash<int>{},然后以 x.getValue() 作为参数调用其函数调用操作符。请注意,这种转发在本示例中之所以有效,是因为 IntWrapper 仅包含一个数据成员,即一个整数。如果该类包含多个数据成员,则需要考虑所有这些数据成员来计算哈希值;然而,这些细节超出了本书的范围。
unordered_map
Section titled “unordered_map”unordered_map 在 <unordered_map> 中定义为类模板:
template <typename Key, typename T, typename Hash = hash<Key>, typename Pred = std::equal_to<Key>, typename Alloc = std::allocator<std::pair<const Key, T>>> class unordered_map;共有五个模板类型参数:键类型、值类型、哈希类型、相等比较器类型和分配器类型。最后三个参数具有默认值。最重要的参数是前两个。与 map 一样,可以使用统一初始化来初始化 unordered_map。遍历元素也与 map 类似,如以下示例所示。
unordered_map<int, string> m { {1, "Item 1"}, {2, "Item 2"}, {3, "Item 3"}, {4, "Item 4"}};// 使用 C++23 对格式化/打印范围的支持。println("{}", m);// 使用结构化绑定(structured bindings)。for (const auto& [key, value] : m) { print("{} = {}, ", key, value); }println("");// 不使用结构化绑定。for (const auto& p : m) { print("{} = {}, ", p.first, p.second); }输出如下:
{4: "Item 4", 3: "Item 3", 2: "Item 2", 1: "Item 1"}4 = Item 4, 3 = Item 3, 2 = Item 2, 1 = Item 1,4 = Item 4, 3 = Item 3, 2 = Item 2, 1 = Item 1,下表总结了 map 和 unordered_map 之间的区别。实心方框()表示容器支持该操作,而空方框()表示不支持。
| 操作 | map | unordered_map |
|---|---|---|
| at() | | |
| begin() | | |
| begin(n) | | |
| bucket() | | |
| bucket_count() | | |
| bucket_size() | | |
| cbegin() | | |
| cbegin(n) | | |
| cend() | | |
| cend(n) | | |
| clear() | | |
| contains() | | |
| count() | | |
| crbegin() | | |
| crend() | | |
| emplace() | | |
| emplace_hint() | | |
| empty() | | |
| end() | | |
| end(n) | | |
| equal_range() | | |
| erase() | | |
| extract() | | |
| find() | | |
| insert() | | |
| insert_or_assign() | | |
| insert_range() (C++23) | | |
| iterator / const_iterator | | |
| load_factor() | | |
| local_iterator / const_local_iterator | | |
| lower_bound() | | |
| max_bucket_count() | | |
| max_load_factor() | | |
| max_size() | | |
| merge() | | |
| operator[] | | |
| rbegin() | | |
| rehash() | | |
| rend() | | |
| reserve() | | |
| reverse_iterator / const_reverse_iterator | | |
| size() | | |
| swap() | | |
| try_emplace() | | |
| upper_bound() | | |
与 map 一样,unordered_map 中的所有键必须是唯一的。上表包括了一些哈希特定的成员函数。例如,load_factor() 返回每个桶的平均元素数量,以指示冲突的数量。bucket_count() 成员函数返回容器中的桶数。它还提供了 local_iterator 和 const_local_iterator,允许你遍历单个桶中的元素;但是,这些迭代器不能用于跨桶遍历。bucket(key) 成员函数返回包含给定键的桶的索引;begin(n) 返回一个指向索引为 n 的桶中第一个元素的 local_iterator,end(n) 返回一个指向索引为 n 的桶中最后一个元素之后一个位置的 local_iterator。下一节中的示例演示了如何使用其中的一些成员函数。
unordered_map 示例:电话簿
Section titled “unordered_map 示例:电话簿”以下示例使用 unordered_map 来表示电话簿。人的名字是键,而电话号码是与该键关联的值。
void printMap(const auto& m) // 简写函数模板{ for (auto& [key, value] : m) { println("{} (Phone: {})", key, value); } println("-------");}
int main(){ // 创建一个哈希表。 unordered_map<string, string> phoneBook { { "Marc G.", "123-456789" }, { "Scott K.", "654-987321" } }; printMap(phoneBook);
// 添加/移除一些电话号码。 phoneBook.insert(make_pair("John D.", "321-987654")); phoneBook["Johan G."] = "963-258147"; phoneBook["Freddy K."] = "999-256256"; phoneBook.erase("Freddy K."); printMap(phoneBook);
// 查找特定键的桶索引。 const size_t bucket { phoneBook.bucket("Marc G.") }; println("Marc G. is in bucket {} containing the following {} names:", bucket, phoneBook.bucket_size(bucket)); // 获取该桶中元素的 begin 和 end 迭代器。 // 这里使用了 'auto'。编译器将两者的类型推导为 // unordered_map<string, string>::const_local_iterator auto localBegin { phoneBook.cbegin(bucket) }; auto localEnd { phoneBook.cend(bucket) }; for (auto iter { localBegin }; iter != localEnd; ++iter) { println("\t{} (Phone: {})", iter->first, iter->second); } println("-------");
// 打印一些关于哈希表的统计信息 println("There are {} buckets.", phoneBook.bucket_count()); println("Average number of elements in a bucket is {}.", phoneBook.load_factor());}可能的输出如下。请注意,不同系统上的输出可能不同,因为这取决于哈希函数的实现以及所使用的 unordered_map 本身。
Scott K. (Phone: 654-987321)Marc G. (Phone: 123-456789)-------Scott K. (Phone: 654-987321)Marc G. (Phone: 123-456789)Johan G. (Phone: 963-258147)John D. (Phone: 321-987654)-------Marc G. is in bucket 1 containing the following 2 names: Scott K. (Phone: 654-987321) Marc G. (Phone: 123-456789)-------There are 8 buckets.Average number of elements in a bucket is 0.5unordered_multimap
Section titled “unordered_multimap”unordered_multimap 是一种允许具有相同键的多个元素的 unordered_map。它们的接口几乎完全相同,但有以下区别:
unordered_multimap不提供operator[]和at()。如果一个键可以对应多个元素,这些操作符的语义就没有意义。- 在
unordered_multimap上的插入总是成功的。因此,添加单个元素的unordered_multimap::insert()成员函数仅返回一个迭代器,而不是pair。 unordered_map支持的insert_or_assign()和try_emplace()成员函数在unordered_multimap中不支持。
如前所述,查找 unordered_multimap 中的元素不能使用 operator[],因为它未提供。你可以使用 find(),但它返回指向具有给定键的任何一个元素的迭代器(不一定是该键的第一个元素)。相反,最好使用 equal_range() 成员函数,它返回一对迭代器:一个指向匹配给定键的第一个元素,另一个指向匹配该键的最后一个元素之后一个位置。equal_range() 的用法与前面讨论的 multimap 相同,因此你可以参考 multimap 的示例来了解它是如何工作的。
unordered_set/unordered_multiset
Section titled “unordered_set/unordered_multiset”<unordered_set> 定义了 unordered_set 和 unordered_multiset,它们分别类似于 set 和 multiset,不同之处在于它们不对键进行排序,而是使用哈希函数。unordered_set 和 unordered_map 之间的区别类似于本章前面讨论的 set 和 map 之间的区别,因此这里不详细讨论。请参阅标准库参考手册以获取 unordered_set 和 unordered_multiset 操作的完整摘要。
Section titled “ Flat Set 和 Flat Map 关联容器适配器”C++23 引入了以下新的容器适配器:
std::flat_set和flat_multiset,定义在<flat_set>中std::flat_map和flat_multimap,定义在<flat_map>中
这些适配器在顺序容器之上提供了关联容器接口。flat_set 和 flat_map 要求键是唯一的,就像 set 和 map 一样,而 flat_multiset 和 flat_multimap 支持重复键,就像 multiset 和 multimap 一样。它们都使用 std::less 作为默认比较器对数据进行排序存储。flat_set 和 flat_multiset 提供对键的快速检索,而 flat_map 和 flat_multimap 提供基于键的值的快速检索。flat_set 和 flat_multiset 需要一个底层顺序容器来存储它们的键。flat_map 和 flat_multimap 需要两个底层容器,一个存储键,另一个存储值。底层容器必须支持随机访问迭代器,如 vector 和 deque。默认情况下使用 vector。
所有 flat 关联容器适配器的接口都与其有序版本相似,不同之处在于 flat 容器适配器不是基于节点的数据结构,因此没有本章前面在讨论有序关联容器时提到的节点句柄(node handle)概念。另一个区别是 flat 变体提供随机访问迭代器,而有序版本仅提供双向迭代器。
随着这些 flat 容器适配器的加入,标准库现在为每种关联容器类型提供了三种变体;例如,现在有三种 map 容器:map、unordered_map 和 flat_map。这三种容器的基本工作方式相似,但它们在存储数据时使用了截然不同的数据结构,因此具有不同的时间效率和空间效率。因为 flat 关联容器适配器在顺序容器中排序存储数据,所以添加和删除元素具有线性时间复杂度,这可能比从有序和无序容器中添加和删除元素慢。查找具有对数复杂度,与有序关联容器相同。然而,对于 flat 变体,查找尤其是对元素的遍历比有序版本更高效,因为前者在顺序容器中存储数据,因此具有更高效且缓存友好的内存布局。与有序或无序变体相比,它们每个元素所需的内存也更少。在特定用例中选择哪一种取决于你的具体需求。如果性能很重要,那么我建议对这三种变体都进行性能分析(profiling),以找出最适合特定用途的一种。性能分析在 第 29 章“编写高效的 C++”中讲解。
flat 关联容器适配器通常只是其有序版本的直接替代。例如,前面的访问控制列表示例中有一个名为 m_allowed 的数据成员,类型为 set<string>,这是一个有序关联容器。代码可以很容易地改为使用 flat_set。需要进行两处更改。首先,将 m_allowed 的类型更改为:
std::flat_set<std::string> m_allowed;其次,将 getAllUsers() 的返回类型更改为 flat_set:
const std::flat_set<std::string>& getAllUsers() const { return m_allowed; }其他一切保持不变。
关联容器的性能
Section titled “关联容器的性能”从本节可以清楚地看出,C++ 标准库包含几种不同的关联容器。你如何知道针对某项任务使用哪一种?如果遍历关联容器的内容对你的用例很重要,那么 flat 关联容器适配器性能最好,因为它们在连续内存中存储数据。如果其他操作对你更重要,那么无序关联容器通常比有序版本更快。然而,如果性能确实至关重要,那么决定正确容器的唯一方法是针对你的具体用例对所有容器进行基准测试。不过,通常你只需选择更易于使用的那一种。要将有序版本与你自己的类类型一起使用,你必须为你的类实现比较操作;而对于无序版本,你需要编写一个哈希函数。后者通常更难实现。
C++ 语言和标准库中还有其他一些特性在某种程度上与容器相关,包括标准 C 风格数组、string、流和 bitset。
标准 C 风格数组
Section titled “标准 C 风格数组”回想一下,原始指针是名副其实的迭代器,因为它们支持所需的操作。这一点不仅仅是一个琐碎的知识点。这意味着你可以通过使用指向其元素的指针作为迭代器,将标准 C 风格数组视为标准库容器。当然,标准 C 风格数组不提供 size()、empty()、insert() 和 erase() 等成员函数,因此它们不是真正的标准库容器。尽管如此,因为它们确实通过指针支持迭代器,所以你可以在 第 20 章 描述的算法以及本章描述的一些成员函数中使用它们。
例如,你可以使用 vector 的 insert() 成员函数将标准 C 风格数组的所有元素复制到 vector 中,该函数接受来自任何容器的迭代器范围。这个 insert() 成员函数的原型如下所示:
template <typename InputIterator> iterator insert(const_iterator position, InputIterator first, InputIterator last);如果你想使用标准 C 风格的 int 数组作为源,那么模板类型参数 InputIterator 变为 int*。这是一个完整的示例:
const size_t count { 10 };int values[count]; // 标准 C 风格数组// 将数组的每个元素初始化为其索引值。for (int i { 0 }; i < count; ++i) { values[i] = i; }
// 在 vector 的末尾插入数组的内容。vector<int> vec;vec.insert(end(vec), values, values + count);
// 打印 vector 的内容。println("{:n} ", vec);请注意,指向数组第一个元素的迭代器是第一个元素的地址,在本例中即为 values。仅数组名本身就被解释为第一个元素的地址。指向末尾的迭代器必须是最后一个元素之后的一个位置,因此它是第一个元素的地址加上 count,即 values+count。
使用 std::begin() 或 cbegin() 获取不通过指针访问的静态分配 C 风格数组的第一个元素的迭代器,并使用 std::end() 或 cend() 获取该数组最后一个元素之后位置的迭代器会更容易。例如,前一个示例中对 insert() 的调用可以写成如下形式:
vec.insert(end(vec), cbegin(values), cend(values));从 C++23 开始,这可以使用 append_range() 写得更优雅:
vec.append_range(values);像 std::begin() 和 end() 这样的函数仅适用于不通过指针访问的静态分配 C 风格数组。如果涉及指针或动态分配的 C 风格数组,它们将无法工作。
你可以将 string 视为字符的顺序容器。因此,了解到 C++ string 是一个功能齐全的顺序容器也就不足为奇了。它具有返回 string 迭代器的 begin() 和 end() 成员函数;它还有 insert()、push_back()、erase()、size() 和 empty() 成员函数,以及顺序容器的所有其他基础功能。它与 vector 非常相似,甚至提供了 reserve() 和 capacity() 成员函数。
你可以像使用 vector 一样将 string 用作标准库容器。这是一个示例:
string myString;myString.insert(cend(myString), 'h');myString.insert(cend(myString), 'e');myString.push_back('l');myString.push_back('l');myString.push_back('o');
for (const auto& letter : myString) { print("{}", letter);}println("");
for (auto it { cbegin(myString) }; it != cend(myString); ++it) { print("{}", *it);}println("");除了标准库顺序容器的成员函数外,string 还提供了一系列有用的成员函数和 friend 函数。事实上,string 接口是杂乱接口的一个很好的例子,这是 第 6 章“为复用而设计”中讨论的设计陷阱之一。string 类在 第 2 章 中有详细讨论。
输入和输出流不是传统意义上的容器,因为它们不存储元素。然而,它们可以被视为元素序列,因此与标准库容器具有某些共同特征。C++ 流不直接提供任何与标准库相关的成员函数,但标准库提供了名为 istream_iterator 和 ostream_iterator 的特殊迭代器,允许你分别“遍历”输入流和输出流。第 17 章 解释了如何使用它们。
bitset
Section titled “bitset”bitset 是对位序列的固定长度抽象。一个位只能表示两个值:1 和 0,可以被称为开/关、真/假等。bitset 也使用术语 set(置位)和 unset(复位)。你可以将一个位从一个值 toggle(切换)或 flip(翻转)到另一个值。
bitset 并不是真正的标准库容器:它的尺寸是固定的,不是基于元素类型参数化的,且不支持迭代。然而,它是一个有用的工具类,经常与容器放在一起讨论,因此这里提供一个简要介绍。请参阅标准库参考手册以获取 bitset 操作的完整摘要。
bitset 基础
Section titled “bitset 基础”bitset(在 <bitset> 中定义)根据它存储的位数进行参数化。默认构造函数将 bitset 的所有字段初始化为 0。另一个构造函数根据 0 和 1 字符组成的 string 创建 bitset。
你可以使用 set()、reset() 和 flip() 成员函数调整单个位的值,并可以使用重载的 operator[] 访问和设置单个字段。请注意,在非 const 对象上使用 operator[] 会返回一个代理对象,你可以对其分配布尔值、调用 flip() 或使用 operator~ 求补。你还可以使用 test() 成员函数访问单个字段。位是使用从零开始的索引访问的。最后,你可以使用 to_string() 将 bitset 转换为 0 和 1 字符组成的 string。
下面是一个小示例:
bitset<10> myBitset;
myBitset.set(3);myBitset.set(6);myBitset[8] = true;myBitset[9] = myBitset[3];
if (myBitset.test(3)) { println("Bit 3 is set!"); }println("{}", myBitset.to_string());输出如下:
Bit 3 is set!1101001000请注意,输出 string 中最左边的字符是编号最高的位。这符合我们对二进制数表示的直觉,即代表 2^0 = 1 的低阶位是打印表示中最右边的位。
除了基础的位操作程序外,bitset 还提供了所有位运算符的实现:&、|、^、~、<<、>>、&=、|=、^=、<<= 和 >>=。它们的行为与在“真实”位序列上的行为完全一致。这是一个示例:
auto str1 { "0011001100" };auto str2 { "0000111100" };bitset<10> bitsOne { str1 };bitset<10> bitsTwo { str2 };
auto bitsThree { bitsOne & bitsTwo };println("{}", bitsThree.to_string());bitsThree <<= 4;println("{}", bitsThree.to_string());该程序的输出如下:
00000011000011000000bitset 示例:表示电视频道
Section titled “bitset 示例:表示电视频道”bitset 的一种可能用途是跟踪有线电视订户的频道。每个订户可以有一个与其订阅关联的频道 bitset,其中置位的位表示他们实际订阅的频道。该系统还可以支持频道的“套餐”(packages),同样表示为 bitset,代表常见的频道订阅组合。
下面的 CableCompany 类是该模型的一个简单示例。它使用了两个 map,都将 string 映射到 bitset。一个存储电视频道套餐,另一个存储订户信息。
export class CableCompany final{ public: // 支持的频道数量。 static constexpr std::size_t NumChannels { 10 }; // 将指定为 bitset 的频道的套餐添加到数据库。 void addPackage(const std::string& packageName, const std::bitset<NumChannels>& channels); // 将指定为 string 的频道的套餐添加到数据库。 void addPackage(const std::string& packageName, const std::string& channels); // 从数据库中移除指定的套餐。 void removePackage(const std::string& packageName); // 检索给定套餐的频道。 // 如果套餐名称无效,则抛出 out_of_range 异常。 const std::bitset<NumChannels>& getPackage( const std::string& packageName) const; // 将客户添加到数据库,其初始频道由套餐确定。 // 如果套餐名称无效,则抛出 out_of_range 异常。 // 如果客户已存在,则抛出 invalid_argument 异常。 void newCustomer(const std::string& name, const std::string& package); // 使用给定的初始频道将客户添加到数据库。 // 如果客户已存在,则抛出 invalid_argument 异常。 void newCustomer(const std::string& name, const std::bitset<NumChannels>& channels); // 将频道添加到客户的档案中。 // 如果客户未知,则抛出 invalid_argument 异常。 void addChannel(const std::string& name, int channel); // 从客户的档案中移除频道。 // 如果客户未知,则抛出 invalid_argument 异常。 void removeChannel(const std::string& name, int channel); // 将指定的套餐添加到客户的档案中。 // 如果套餐名称无效,则抛出 out_of_range 异常。 // 如果客户未知,则抛出 invalid_argument 异常。 void addPackageToCustomer(const std::string& name, const std::string& package); // 从数据库中删除指定的客户。 void deleteCustomer(const std::string& name); // 检索客户订阅的频道。 // 如果客户未知,则抛出 invalid_argument 异常。 const std::bitset<NumChannels>& getCustomerChannels( const std::string& name) const; private: // 检索客户的频道。(非 const) // 如果客户未知,则抛出 invalid_argument 异常。 std::bitset<NumChannels>& getCustomerChannelsHelper( const std::string& name);
using MapType = std::map<std::string, std::bitset<NumChannels>>; MapType m_packages, m_customers;};下面是所有成员函数的实现,并附有代码解释:
void CableCompany::addPackage(const string& packageName, const bitset<NumChannels>& channels){ m_packages.emplace(packageName, channels);}
void CableCompany::addPackage(const string& packageName, const string& channels){ addPackage(packageName, bitset<NumChannels> { channels });}
void CableCompany::removePackage(const string& packageName){ m_packages.erase(packageName);}
const bitset<CableCompany::NumChannels>& CableCompany::getPackage( const string& packageName) const{ // 获取指定套餐的迭代器。 if (auto it { m_packages.find(packageName) }; it != end(m_packages)) { // 找到了套餐。请注意,'it' 是指向名称/bitset pair 的迭代器。 // bitset 是第二个字段。 return it->second; } throw out_of_range { format("Invalid package '{}'.", packageName) };}
void CableCompany::newCustomer(const string& name, const string& package){ // 获取给定套餐的频道。 auto& packageChannels { getPackage(package) }; // 使用代表该套餐的 bitset 创建账户。 newCustomer(name, packageChannels);}
void CableCompany::newCustomer(const string& name, const bitset<NumChannels>& channels){ // 将客户添加到 customers map 中。 if (auto [iter, success] { m_customers.emplace(name, channels) }; !success) { // 客户已在数据库中。未发生任何更改。 throw invalid_argument { format("Duplicate customer '{}'.", name) }; }}
void CableCompany::addChannel(const string& name, int channel){ // 获取客户当前的频道。 auto& customerChannels { getCustomerChannelsHelper(name) }; // 找到了客户;设置频道。 customerChannels.set(channel);}
void CableCompany::removeChannel(const string& name, int channel){ // 获取客户当前的频道。 auto& customerChannels { getCustomerChannelsHelper(name) }; // 找到了该客户;移除频道。 customerChannels.reset(channel);}
void CableCompany::addPackageToCustomer(const string& name, const string& package){ // 获取给定套餐的频道。 auto& packageChannels { getPackage(package) }; // 获取客户当前的频道。 auto& customerChannels { getCustomerChannelsHelper(name) }; // 将套餐“或”运算到客户现有的频道中。 customerChannels |= packageChannels;}
void CableCompany::deleteCustomer(const string& name){ m_customers.erase(name);}
const bitset<CableCompany::NumChannels>& CableCompany::getCustomerChannels( const string& name) const{ // 查找客户的迭代器。 if (auto it { m_customers.find(name) }; it != end(m_customers)) { // 找到了客户。请注意,'it' 是指向名称/bitset pair 的迭代器。 // bitset 是第二个字段。 return it->second; } throw invalid_argument { format("Unknown customer '{}'.", name) };}
bitset<CableCompany::NumChannels>& CableCompany::getCustomerChannelsHelper( const string& name){ // 转发给 const 版本的 getCustomerChannels() 以避免代码重复。 return const_cast<bitset<NumChannels>&>(getCustomerChannels(name));}最后,这是一个演示如何使用 CableCompany 类的简单程序:
CableCompany myCC;myCC.addPackage("basic", "1111000000");myCC.addPackage("premium", "1111111111");myCC.addPackage("sports", "0000100111");
myCC.newCustomer("Marc G.", "basic");myCC.addPackageToCustomer("Marc G.", "sports");println("{}", myCC.getCustomerChannels("Marc G.").to_string());
try { println("{}", myCC.getCustomerChannels("John").to_string()); }catch (const exception& e) { println("Error: {}", e.what()); }输出如下:
1111100111Error: Unknown customer 'John'.本章介绍了标准库容器。它还通过示例代码演示了这些容器的各种用途。理想情况下,你应该已经领略到了 vector、deque、list、forward_list、array、span、mdspan、stack、queue、priority_queue、map、multimap、set、multiset、unordered_map、unordered_multimap、unordered_set、unordered_multiset、flat_map、flat_multimap、flat_set、flat_multiset、string 和 bitset 的强大之处。我建议尽可能使用这些容器,而不是自己编写。
在讨论泛型算法及其如何与本章讨论的容器配合使用,以深入挖掘标准库的真正潜力之前,我们必须先解释函数指针、函数对象和 lambda 表达式。这些是下一章的主题。
通过解决以下练习,你可以练习本章讨论的内容。所有练习的解答均可在该书的网站 www.wiley.com/go/proc++6e 上的代码下载中找到。但是,如果你在某个练习上卡住了,请先重新阅读本章的部分内容,尝试自己寻找答案,然后再去网站查看解答。
- 练习 18-1: 这个练习是为了练习使用
vector。创建一个程序,包含一个名为values的intvector,初始化为数字 2 和 5。接着,实现以下操作:- 使用
insert()在values的正确位置插入数字 3 和 4。 - 创建第二个初始化为 0 和 1 的
intvector,然后将这个新vector的内容插入到values的开头。 - 创建第三个
intvector。反向遍历values的元素,并将它们插入到这第三个vector中。 - 使用
println()打印第三个vector的内容。 - 使用基于范围的
for循环打印第三个vector的内容。
- 使用
- 练习 18-2: 采用练习 15-4 中
Person类的实现。添加一个名为phone_book的新模块,定义一个PhoneBook类,为一个人存储一个或多个字符串形式的电话号码。提供向电话簿添加和从电话簿移除人的电话号码的成员函数。还提供一个返回包含给定人所有电话号码的vector的成员函数。在main()函数中测试你的实现。在测试中,使用练习 15-4 中开发的自定义人字面量。 - 练习 18-3: 在练习 15-1 中,你开发了自己的
AssociativeArray。修改该练习中main()里的测试代码,改用标准库容器之一。 - 练习 18-4: 编写一个
average()函数(不是函数模板)来计算一系列double值的平均值。确保它能处理来自vector或array的序列或子序列。在main()函数中分别使用vector和array测试你的代码。 - 加分练习: 你能将你的
average()函数转换为函数模板吗?该函数模板应该只能由整型或浮点型实例化。这对你main()中的测试代码有什么影响?