精通类和对象
第 8 章“熟悉类和对象”开启了对类与对象的讨论。现在,是时候进一步掌握其中那些更微妙的部分,这样你才能把它们的能力发挥到极致。读完本章后,你将学会如何运用并驾驭 C++ 语言中一些最强大的特性,从而编写出安全、有效且实用的类。
本章中的许多概念都会出现在高级 C++ 编程里,尤其是在 C++ 标准库中。我们先从 C++ 世界中的友元概念开始。
C++ 允许一个类声明其他类、其他类的成员函数,或非成员函数为自己的友元(friend),从而让它们访问 protected 与 private 数据成员和成员函数。举例来说,假设你有两个类,分别叫做 Foo 和 Bar。你可以像下面这样指定 Bar 类是 Foo 的友元:
class Foo{ friend class Bar; // …};这样一来,Bar 的所有成员函数都可以访问 Foo 的 private 和 protected 数据成员与成员函数。
如果你只想让 Bar 的某个特定成员函数成为友元,也完全可以。假设 Bar 类有一个成员函数 processFoo(const Foo&)。要把这个成员函数声明为 Foo 的友元,可以使用如下语法:
class Foo{ friend void Bar::processFoo(const Foo&); // …};独立函数同样可以成为类的友元。比如,你可能想写一个函数,把某个 Foo 对象中的全部数据打印到控制台。你也许希望这个函数位于 Foo 类之外,因为打印并不是 Foo 的核心功能;但这个函数又需要访问对象内部的数据成员,才能把所有内容都打印出来。下面是把 printFoo() 声明为友元后的 Foo 类定义:
class Foo{ friend void printFoo(const Foo&); // …};类中的 friend 声明本身就充当了该函数的原型声明。你无需再在别处单独写出它的原型(当然,写了也无妨)。
下面是函数定义:
void printFoo(const Foo& foo){ // Print all data of foo to the console, including // private and protected data members.}这个函数写在类定义之外,方式与普通函数完全相同,不同之处仅在于它可以直接访问 Foo 的 private 和 protected 成员。注意,在函数定义中不需要再次写 friend 关键字。
需要注意的是,某个类必须主动知道哪些类、哪些成员函数或哪些函数想成为它的友元;一个类、成员函数或普通函数不能自行宣布“我要成为别的类的友元”,从而获取该类非 public 成员的访问权限。
friend 类和函数很容易被滥用;它们允许你打破封装原则,把类的内部细节暴露给其他类或函数。因此,只有在有限且合理的场景下才应该使用它们。本章后面会展示一些合适的用法。
对象中的动态内存分配
Section titled “对象中的动态内存分配”有时候,在程序真正运行之前,你并不知道自己需要多少内存。正如你在 第 7 章“内存管理”中读到的,解决办法就是在程序执行期间按需动态分配空间。类当然也不例外。有时,你在编写类时并不知道一个对象最终需要多少内存。这种情况下,对象就应该动态分配内存。对象中的动态分配内存会带来若干挑战,例如如何释放内存、如何处理对象拷贝,以及如何处理对象赋值。
Spreadsheet 类
Section titled “Spreadsheet 类”第 8 章 引入了 SpreadsheetCell 类。本章接下来会编写 Spreadsheet 类。和 SpreadsheetCell 类一样,Spreadsheet 类会在本章中不断演化。因此,不同阶段的实现并不一定都代表编写类时各方面的最佳做法。
先从最简单的版本开始:Spreadsheet 就是一个由 SpreadsheetCell 组成的二维数组,并提供若干成员函数,用于在特定位置设置和获取单元格。虽然大多数电子表格程序会在一个方向上用字母、另一个方向上用数字来引用单元格,但本例在两个方向上都使用数字。
Spreadsheet.cppm 模块接口文件的第一行定义了模块名称:
export module spreadsheet;Spreadsheet 类需要访问 SpreadsheetCell 类,因此它要导入 spreadsheet_cell 模块。另外,为了让 spreadsheet 模块的使用者也能看到 SpreadsheetCell 类,需要用下面这种看起来有点奇特的语法同时导入并导出 spreadsheet_cell 模块:
export import spreadsheet_cell;Spreadsheet 类使用了 std::size_t 类型,它定义在名为 <cstddef> 的 C 头文件中。可以通过下面的导入来访问它:
import std;下面给出 Spreadsheet 类定义的第一版尝试:
export class Spreadsheet{ public: Spreadsheet(std::size_t width, std::size_t height); void setCellAt(std::size_t x, std::size_t y, const SpreadsheetCell& cell); SpreadsheetCell& getCellAt(std::size_t x, std::size_t y); private: bool inRange(std::size_t value, std::size_t upper) const; std::size_t m_width { 0 }; std::size_t m_height { 0 }; SpreadsheetCell** m_cells { nullptr };};注意,Spreadsheet 类并没有包含一个标准的二维 SpreadsheetCell 数组。相反,它有一个 SpreadsheetCell** 数据成员,即“指向指针的指针”,用来表示“数组的数组”。之所以这样做,是因为每个 Spreadsheet 对象的尺寸都可能不同,因此类的构造函数必须根据客户端指定的宽度和高度来动态分配这个二维数组。
要动态分配一个二维数组,你需要编写如下代码。注意,在 C++ 中,不同于 Java,不能直接写成 new SpreadsheetCell[m_width][m_height]。
Spreadsheet::Spreadsheet(size_t width, size_t height) : m_width { width }, m_height { height }{ m_cells = new SpreadsheetCell*[m_width]; for (size_t i { 0 }; i < m_width; ++i) { m_cells[i] = new SpreadsheetCell[m_height]; }}图 9.1 展示了一个名为 s1、宽度为 4、高度为 3 的 Spreadsheet 在栈上时对应的内存布局。
inRange() 以及设置/获取单元格成员函数的实现都很直接:
bool Spreadsheet::inRange(size_t value, size_t upper) const{ return value < upper;}
void Spreadsheet::setCellAt(size_t x, size_t y, const SpreadsheetCell& cell){ if (!inRange(x, m_width)) { throw out_of_range { format("x ({}) must be less than width ({}).", x, m_width) }; } if (!inRange(y, m_height)) { throw out_of_range { format("y ({}) must be less than height ({}).", y, m_height) }; } m_cells[x][y] = cell;}
SpreadsheetCell& Spreadsheet::getCellAt(size_t x, size_t y){ if (!inRange(x, m_width)) { throw out_of_range { format("x ({}) must be less than width ({}).", x, m_width) }; } if (!inRange(y, m_height)) { throw out_of_range { format("y ({}) must be less than height ({}).", y, m_height) }; } return m_cells[x][y];}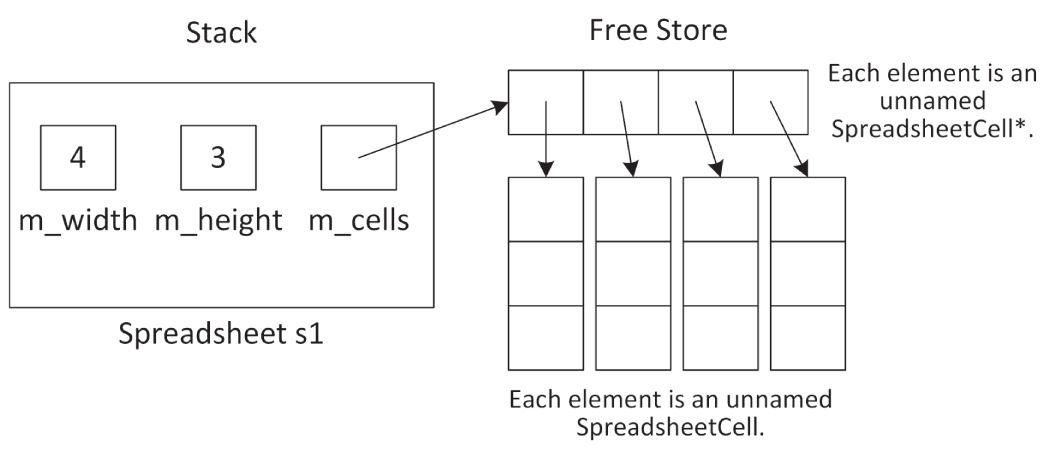
[^图 9.1]
setCellAt() 和 getCellAt() 都使用一个名为 inRange() 的辅助函数来检查 x 和 y 是否表示表格中的有效坐标。若试图访问超出范围的数组元素,程序就会出故障。本例使用了异常,它在 第 1 章“C++ 与标准库速成”中已做介绍,并会在 第 14 章“错误处理”中详细讲解。
如果你观察 setCellAt() 与 getCellAt() 的实现,会发现其中存在明显的重复代码。第 6 章“为复用而设计”解释过,代码重复应该尽可能避免。所以,我们遵循那条原则。与其使用一个名为 inRange() 的辅助函数,不如定义下面这个 verifyCoordinate() 成员函数:
void verifyCoordinate(std::size_t x, std::size_t y) const;它的实现会检查给定坐标,若坐标无效则抛出异常:
void Spreadsheet::verifyCoordinate(size_t x, size_t y) const{ if (x>= m_width) { throw out_of_range { format("x ({}) must be less than width ({}).", x, m_width) }; } if (y>= m_height) { throw out_of_range { format("y ({}) must be less than height ({}).", y, m_height) }; }}现在,setCellAt() 和 getCellAt() 的实现就可以简化为:
void Spreadsheet::setCellAt(size_t x, size_t y, const SpreadsheetCell& cell){ verifyCoordinate(x, y); m_cells[x][y] = cell;}
SpreadsheetCell& Spreadsheet::getCellAt(size_t x, size_t y){ verifyCoordinate(x, y); return m_cells[x][y];}用析构函数释放内存
Section titled “用析构函数释放内存”只要你不再需要动态分配的内存,就应该把它释放掉。如果你在对象中动态分配了内存,那么释放它的地方就是析构函数(destructor)。编译器会保证对象销毁时调用析构函数。下面是在 Spreadsheet 类定义中新增析构函数后的版本:
export class Spreadsheet{ public: Spreadsheet(std::size_t width, std::size_t height); ~Spreadsheet(); // Code omitted for brevity};析构函数的名字与类名(以及构造函数名)相同,只是在前面加一个波浪号(~)。析构函数不接受任何参数,而且一个类只能有一个析构函数。正如 第 14 章 会详细解释的那样,析构函数绝不应该抛出异常。
下面是 Spreadsheet 类析构函数的实现:
Spreadsheet::˜Spreadsheet(){ for (size_t i { 0 }; i < m_width; ++i) { delete[] m_cells[i]; } delete[] m_cells; m_cells = nullptr;}这个析构函数释放了构造函数中分配的内存。不过,并没有任何规则强制你必须在析构函数里释放内存。你完全可以在析构函数里写任何你想写的代码,但通常最好只把它用于释放内存或处置其他资源。
处理拷贝与赋值
Section titled “处理拷贝与赋值”回忆一下 第 8 章:如果你没有自己编写拷贝构造函数和拷贝赋值运算符,C++ 会为你自动生成。编译器生成的这些成员函数会递归地对对象的数据成员调用对应的拷贝构造或拷贝赋值操作。不过,对于 int、double 和指针这类基本类型,它们执行的是浅拷贝(shallow copy)或按位拷贝(bitwise copy):只是把源对象中的数据成员直接复制/赋值到目标对象中。当对象内部有动态分配内存时,这就会引发问题。例如,下面这段代码在把 s1 传给 printSpreadsheet() 时,会先拷贝 s1 来初始化参数 s:
import spreadsheet;
void printSpreadsheet(Spreadsheet s) { /* Code omitted for brevity. */ }
int main(){ Spreadsheet s1 { 4, 3 }; printSpreadsheet(s1);}Spreadsheet 内部包含一个指针变量:m_cells。对 Spreadsheet 做浅拷贝时,目标对象获得的是 m_cells 指针的副本,而不是其底层数据的副本。于是就会出现 s 和 s1 同时指向同一份数据的情况,如 图 9.2 所示。
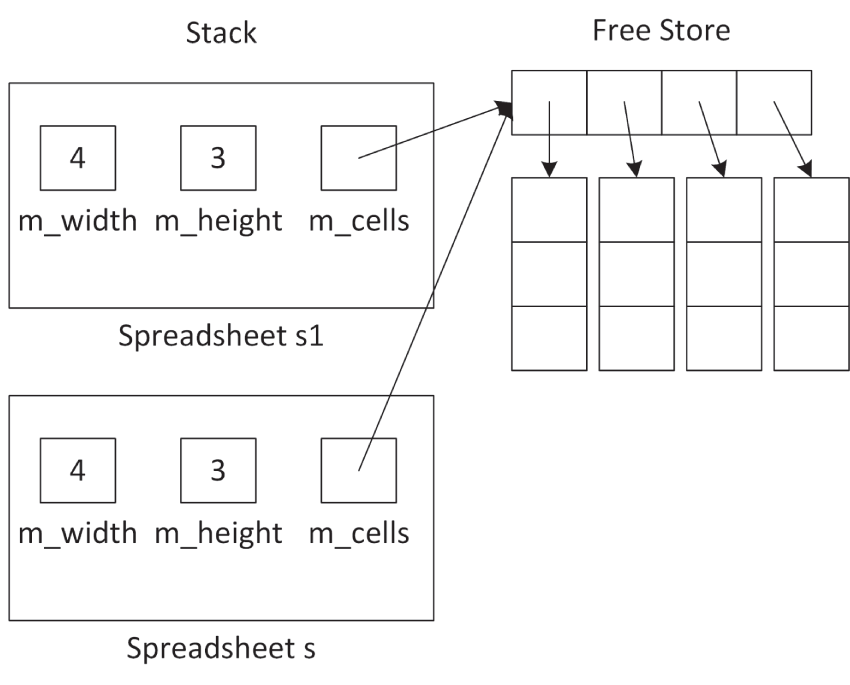
[^图 9.2]
如果 s 修改了 m_cells 所指向的内容,那么这个改动也会反映在 s1 上。更糟糕的是,当 printSpreadsheet() 退出时,s 的析构函数会被调用,从而释放 m_cells 指向的内存。这样就导致 s1 中的 m_cells 不再指向有效内存,如 图 9.3 所示。这种情况被称为悬空指针(dangling pointer)。
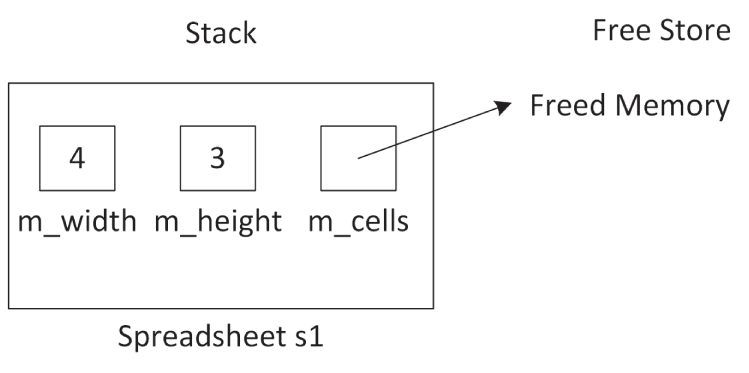
[^图 9.3]
令人难以置信的是,赋值时问题会更严重。假设你有如下代码:
Spreadsheet s1 { 2, 2 }, s2 { 4, 3 };s1 = s2;执行完第一行、即两个 Spreadsheet 对象 s1 与 s2 都构造完毕后,内存布局如 图 9.4 所示。
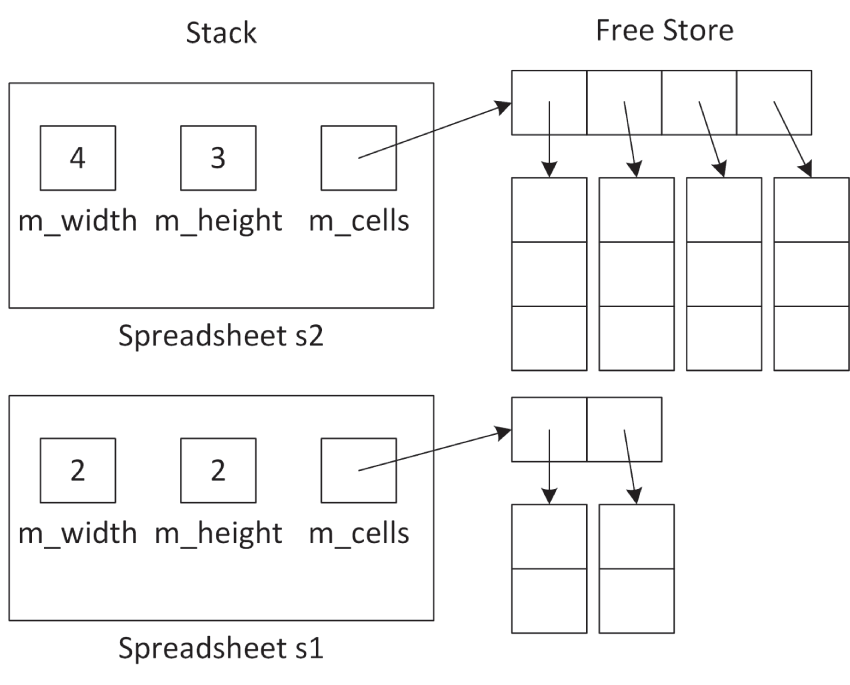
[^图 9.4]
执行赋值语句之后,布局会变成 图 9.5 所示的样子。
现在,不仅 s1 与 s2 中的 m_cells 指针指向了同一片内存,而且 s1 原先通过 m_cells 指向的那块内存也被遗弃(orphaned)了。这种情况称为内存泄漏(memory leak)。
到这里应该已经很清楚了:拷贝构造函数和拷贝赋值运算符必须执行深拷贝(deep copy);也就是说,它们不能只复制指针数据成员本身,而必须复制这些指针所指向的实际数据。
正如你所见,依赖 C++ 默认提供的拷贝构造函数和默认拷贝赋值运算符并不总是一个好主意。
只要类中拥有动态分配的资源,你就应该自己编写拷贝构造函数和拷贝赋值运算符,以便对内存执行深拷贝。
[^图 9.5]
Spreadsheet 拷贝构造函数
Section titled “Spreadsheet 拷贝构造函数”下面是在 Spreadsheet 类中声明拷贝构造函数的方式:
export class Spreadsheet{ public: Spreadsheet(const Spreadsheet& src); // Code omitted for brevity};定义如下:
Spreadsheet::Spreadsheet(const Spreadsheet& src) : Spreadsheet { src.m_width, src.m_height }{ for (size_t i { 0 }; i < m_width; ++i) { for (size_t j { 0 }; j < m_height; ++j) { m_cells[i][j] = src.m_cells[i][j]; } }}请注意这里使用了委托构造函数。这个拷贝构造函数的 ctor-initializer 首先委托给非拷贝构造函数,为对象分配正确大小的内存。随后,拷贝构造函数的函数体再复制实际值。两者配合起来,就为动态分配的二维数组 m_cells 实现了深拷贝。
这里不需要删除已有的 m_cells,因为这是拷贝构造函数,当前 this 对象里还不存在任何旧的 m_cells。
Spreadsheet 赋值运算符
Section titled “Spreadsheet 赋值运算符”下面给出带有赋值运算符的 Spreadsheet 类定义:
export class Spreadsheet{ public: Spreadsheet& operator=(const Spreadsheet& rhs); // Code omitted for brevity};一个天真的实现可能如下所示:
Spreadsheet& Spreadsheet::operator=(const Spreadsheet& rhs){ // Check for self-assignment if (this == &rhs) { return *this; }
// Free the old memory for (size_t i { 0 }; i < m_width; ++i) { delete[] m_cells[i]; } delete[] m_cells; m_cells = nullptr;
// Allocate new memory m_width = rhs.m_width; m_height = rhs.m_height;
m_cells = new SpreadsheetCell*[m_width]; for (size_t i { 0 }; i < m_width; ++i) { m_cells[i] = new SpreadsheetCell[m_height]; }
// Copy the data for (size_t i { 0 }; i < m_width; ++i) { for (size_t j { 0 }; j < m_height; ++j) { m_cells[i][j] = rhs.m_cells[i][j]; } }
return *this;}这段代码先检查自赋值,然后释放 this 对象当前持有的内存,再分配新内存,最后复制各个元素。这个函数里发生的事情很多,也意味着很多地方都可能出错! this 对象完全有可能进入无效状态。
例如,假设旧内存已经成功释放,m_width 与 m_height 也都正确设置了,但在分配新内存的循环中抛出了异常。此时,函数余下部分会被跳过并直接退出。结果就是 Spreadsheet 实例已经损坏:它的 m_width 与 m_height 声称对象有某个尺寸,但 m_cells 却没有指向正确数量的内存。简而言之,这段代码并不具备异常安全性!
我们真正需要的是一种“要么全部成功,要么一点都不动”的机制。为了实现这种异常安全的赋值运算符,可以使用 copy-and-swap 惯用法。为此,先给 Spreadsheet 类添加一个 swap() 成员函数。另外,还建议额外提供一个非成员 swap() 函数,这样标准库中的各种算法也能使用它。下面给出带赋值运算符、swap() 成员函数及非成员函数的 Spreadsheet 类定义:
export class Spreadsheet{ public: Spreadsheet& operator=(const Spreadsheet& rhs); void swap(Spreadsheet& other) noexcept; // Code omitted for brevity};export void swap(Spreadsheet& first, Spreadsheet& second) noexcept;实现异常安全的 copy-and-swap 惯用法有一个前提:swap() 绝不能抛出异常,因此它被标记为 noexcept。
swap() 成员函数的实现会使用标准库 <utility> 中提供的 std::swap() 工具函数来交换每个数据成员,它能高效交换两个值:
void Spreadsheet::swap(Spreadsheet& other) noexcept{ std::swap(m_width, other.m_width); std::swap(m_height, other.m_height); std::swap(m_cells, other.m_cells);}非成员 swap() 只是简单地转发给成员 swap():
void swap(Spreadsheet& first, Spreadsheet& second) noexcept{ first.swap(second);}现在我们已经有了异常安全的 swap(),就可以用它来实现赋值运算符:
Spreadsheet& Spreadsheet::operator=(const Spreadsheet& rhs){ Spreadsheet temp { rhs }; // Do all the work in a temporary instance swap(temp); // Commit the work with only non-throwing operations return *this;}这个实现使用了 copy-and-swap 惯用法。首先,创建右侧对象的一个副本,名为 temp。然后,把当前对象与这个副本交换。之所以推荐用这种模式实现赋值运算符,是因为它能保证强异常安全性(strong exception safety),也就是说,只要有任何异常发生,当前 Spreadsheet 对象的状态都保持不变。这个惯用法分三个阶段完成:
- 第一阶段创建一个临时副本。这一步不会修改当前
Spreadsheet对象的状态,因此即使在这一阶段抛出异常也没有问题。 - 第二阶段用
swap()把新创建的临时副本与当前对象交换。swap()必须保证绝不抛异常。 - 第三阶段销毁临时对象。由于交换之后临时对象里装的是原先的旧对象,因此它会在销毁时清理对应内存。
如果你没有使用 copy-and-swap 惯用法来实现赋值运算符,那么出于效率考虑,有时也是为了正确性,赋值运算符中的第一行代码通常都会先检查自赋值。如下所示:
Spreadsheet& Spreadsheet::operator=(const Spreadsheet& rhs){ // Check for self-assignment if (this == &rhs) { return *this; } // … return *this;}使用 copy-and-swap 惯用法时,这种自赋值检查就不再需要了。
实现赋值运算符时,请使用 copy-and-swap 惯用法,以避免代码重复并保证强异常安全性。
禁止赋值与按值传递
Section titled “禁止赋值与按值传递”有时,当类内部使用了动态分配内存时,最简单的做法就是直接禁止别人拷贝或赋值你的对象。你可以通过显式删除 operator= 和拷贝构造函数来实现。这样一来,如果有人试图按值传递该对象、从函数返回它,或者对其做赋值,编译器就会报错。下面是一个禁止赋值与按值传递的 Spreadsheet 类定义:
export class Spreadsheet{ public: Spreadsheet(std::size_t width, std::size_t height); Spreadsheet(const Spreadsheet& src) = delete; ˜Spreadsheet(); Spreadsheet& operator=(const Spreadsheet& rhs) = delete; // Code omitted for brevity};对于被删除的成员函数,你无需提供实现。链接器永远不会去查找它们,因为编译器根本不允许代码去调用这些函数。现在,如果你尝试编写代码去拷贝或赋值一个 Spreadsheet 对象,编译器就会报出类似下面的错误:
'Spreadsheet &Spreadsheet::operator =(const Spreadsheet &)': attempting to reference a deleted function用移动语义处理移动
Section titled “用移动语义处理移动”要让类支持移动语义(move semantics),就需要提供移动构造函数(move constructor)和移动赋值运算符(move assignment operator)。当源对象是一个在操作完成后即将销毁的临时对象时,或者像你稍后会看到的那样显式使用 std::move() 时,编译器就可以使用它们。移动的本质是把内存和其他资源的所有权转移给另一个对象。它基本上执行的是对数据成员的浅拷贝,再结合对已分配内存及其他资源所有权的切换,从而避免悬空指针、资源悬空以及内存泄漏。
移动构造函数和移动赋值运算符都会把数据成员从源对象移动到新对象中,同时把源对象留在某种有效但其余状态未指定的状态。通常会把源对象的数据成员重置为“空”值,虽然这并不是强制要求。不过,我仍然建议你在移动之后,尽量让源对象进入一个定义清晰的空状态。为了安全起见,不要再使用那些已经被 move 过的对象,因为那样可能触发未定义行为。标准库中的几个著名例外是 std::unique_ptr 和 shared_ptr。标准库明确规定,从这些智能指针中移动时,它们必须把内部指针重置为 nullptr,因此在 move 之后继续复用这类智能指针是安全的。
在真正实现移动语义之前,你需要先了解右值与右值引用。
在 C++ 中,左值(lvalue) 是指那些你可以对其取地址的东西,例如一个有名字的变量。这个名字的来源,是因为左值可以出现在赋值语句的左边。相对地,右值(rvalue) 指任何不是左值的东西,例如字面量、临时对象或临时值。1 通常,右值出现在赋值运算符的右边。例如,看看下面这条语句:
int a { 4 * 2 };在这条语句里,a 是左值,因为它有名字,你还能通过 &a 取得它的地址。而表达式 4*2 的结果则是一个右值。它是一个临时值,会在语句执行结束时销毁。在这个例子中,这个临时值的一个副本会被存入名为 a 的变量中。
如果某个函数按值返回结果,那么调用该函数得到的结果就是一个右值,也就是一个临时对象。如果函数返回的是“非 const 引用”,那么调用该函数得到的结果就是一个左值,因为你可以把它用在赋值语句的左侧。
右值引用(rvalue reference) 就是对右值的引用。更准确地说,这个概念主要适用于“临时对象”这种右值,或者显式通过 std::move() 转换得到的对象(后面会解释)。右值引用的目的,是让某个特定的函数重载在遇到右值时能够被选中。这样一来,一些原本需要复制大量数据的操作,就可以改为仅复制指向这些数据的指针。
函数可以通过在参数声明中使用 && 来声明右值引用参数,形式如 type&& name。通常,临时对象会被当作 const type&,但如果存在使用右值引用的重载,临时对象就可以匹配到那个重载。下面的例子演示了这一点。代码先定义两个 handleMessage() 函数:一个接收左值引用,一个接收右值引用:
void handleMessage(string& message) // lvalue reference parameter{ println("handleMessage with lvalue reference: {}", message);}
void handleMessage(string&& message) // rvalue reference parameter{ println("handleMessage with rvalue reference: {}", message);}你可以用一个具名变量作为参数来调用 handleMessage():
string a { "Hello " };handleMessage(a); // Calls handleMessage(string& value)因为 a 是一个具名变量,所以会调用接收左值引用的 handleMessage()。handleMessage() 通过其引用参数所做的任何修改,都会直接影响 a 的值。
你也可以用一个表达式作为参数来调用 handleMessage():
string b { "World" };handleMessage(a + b); // Calls handleMessage(string&& value)这里不能使用接收左值引用的 handleMessage(),因为表达式 a + b 的结果是一个临时对象,它不是左值。这种情况下会调用右值引用版本。由于参数本身是个临时量,handleMessage() 通过引用参数所做的任何改动,在调用返回后都会丢失。
字面量同样可以作为参数传给 handleMessage()。这种情况也会触发对右值引用重载的调用,因为字面量不可能是左值(当然,字面量可以绑定到“引用到 const”的参数):
handleMessage("Hello World"); // Calls handleMessage(string&& value)如果你把接收左值引用的那个 handleMessage() 删除掉,那么像 handleMessage(b) 这样用具名变量调用时就会出现编译错误,因为右值引用参数(string&&) 永远不会绑定到左值(b)上。你可以用 std::move() 强制编译器调用右值引用版本的 handleMessage()。move() 唯一做的事情,就是把一个左值转换成右值引用;也就是说,它本身并不执行真正的“移动”。不过,由于它返回的是右值引用,编译器就能找到接收右值引用的 handleMessage() 重载,随后由后者来执行真正的移动。使用 move() 的示例如下:
handleMessage(std::move(b)); // Calls handleMessage(string&& value)正如我前面说过、但值得再次强调的是:具名变量就是左值。因此,在 handleMessage(string&& message) 函数内部,右值引用参数 message 自身也是左值,因为它有名字! 如果你想把这个右值引用参数继续以右值身份转发给另一个函数,就必须使用 std::move() 把这个左值重新转换成右值引用。例如,假设你又添加了下面这个接收右值引用参数的函数:
void helper(string&& message) { }如果像下面这样调用,是无法编译的:
void handleMessage(string&& message) { helper(message); }helper() 需要的是右值引用,而 handleMessage() 传过去的 message 虽然类型是右值引用,但它有名字,因此是左值,从而导致编译错误。正确写法是使用 std::move():
void handleMessage(string&& message) { helper(std::move(message)); }一个具名右值引用(例如右值引用参数)本身仍然是左值,因为它有名字!
右值引用并不仅限于函数参数。你也可以声明一个右值引用类型的变量并给它赋值,虽然这种用法并不常见。来看下面这段在 C++ 中非法的代码:
int& i { 2 }; // Invalid: reference to a constantint a { 2 }, b { 3 };int& j { a + b }; // Invalid: reference to a temporary使用右值引用之后,下面的写法就是完全合法的:
int&& i { 2 };int a { 2 }, b { 3 };int&& j { a + b };不过,这种独立存在的右值引用通常很少这样使用。
Section titled “ Decay copy”如果你有一个对象 x,写出 auto y{x} 会创建 x 的一个副本,并给它起名为 y;因此它是左值。
C++23 引入了 auto(x) 或 auto{x} 语法,可以把对象 x 的副本创建为一个右值,而不是左值。
例如,假设你只有上一节中的右值引用版 handleMessage(string&&) 函数,而没有左值引用重载。此时你已经知道,下面的代码行不通:
string value { "Hello " };handleMessage(value); // Error你当然可以使用 std::move(),像这样:
handleMessage(std::move(value));但执行完这一步之后,你就不应再继续使用 value 对象了,因为它可能已经被 move 走了。
借助 C++23 的 decay-copy 语法,你可以写成:
handleMessage(auto { value });这会把对象 value 临时复制出一个右值副本,并把这个右值传给 handleMessage()。如果 handleMessage() 从这个副本中执行了 move,原始对象 value 仍然会被完整保留,不受影响。
实现移动语义
Section titled “实现移动语义”移动语义是借助右值引用来实现的。要让一个类支持移动语义,你需要实现移动构造函数和移动赋值运算符。移动构造函数和移动赋值运算符都应该标记为 noexcept,以告知编译器它们不会抛出异常。这一点对于与标准库兼容尤为重要;例如,要让标准库容器的完整实现愿意在内部对存储对象执行 move,不仅该对象要支持移动语义,还必须保证这些移动操作不会抛异常。这样标准库才能提供强异常安全保证。
下面是加入移动构造函数和移动赋值运算符后的 Spreadsheet 类定义。同时还引入了两个辅助成员函数:cleanup() 用于析构函数和移动赋值运算符;moveFrom() 则负责把数据成员从源对象移动到目标对象,随后重置源对象。
export class Spreadsheet{ public: Spreadsheet(Spreadsheet&& src) noexcept; // Move constructor Spreadsheet& operator=(Spreadsheet&& rhs) noexcept; // Move assignment // Remaining code omitted for brevity private: void cleanup() noexcept; void moveFrom(Spreadsheet& src) noexcept; // Remaining code omitted for brevity};对应实现如下:
void Spreadsheet::cleanup() noexcept{ for (size_t i { 0 }; i < m_width; ++i) { delete[] m_cells[i]; } delete[] m_cells; m_cells = nullptr; m_width = m_height = 0;}
void Spreadsheet::moveFrom(Spreadsheet& src) noexcept{ // Shallow copy of data m_width = src.m_width; m_height = src.m_height; m_cells = src.m_cells;
// Reset the source object, because ownership has been moved! src.m_width = 0; src.m_height = 0; src.m_cells = nullptr;}
// Move constructorSpreadsheet::Spreadsheet(Spreadsheet&& src) noexcept{ moveFrom(src);}
// Move assignment operatorSpreadsheet& Spreadsheet::operator=(Spreadsheet&& rhs) noexcept{ // Check for self-assignment if (this == &rhs) { return *this; }
// Free the old memory and move ownership cleanup(); moveFrom(rhs); return *this;}移动构造函数和移动赋值运算符都会把 m_cells 所持有那块内存的所有权从源对象转移到新对象中。它们会把源对象的 m_cells 指针重置为空指针,并把源对象的 m_width 与 m_height 设为 0,从而防止源对象的析构函数在之后错误地释放那块已经转移了所有权的内存。
显然,只有在你确定源对象之后不再需要时,移动语义才真正有价值。
注意,这个实现的移动赋值运算符中包含了自赋值检查。是否一定需要这一步,取决于你的类以及你打算如何把一个实例移动到另一个实例中。不过,就像 C++ Core Guidelines 所建议的那样,你始终都应该保留这项检查,2 以确保下面这样的代码永远不会在运行时导致崩溃:
sheet1 = std::move(sheet1);与拷贝构造函数和拷贝赋值运算符一样,移动构造函数和移动赋值运算符也可以被显式删除或显式默认化,正如 第 8 章 所解释的那样。
只有当类中没有用户声明的拷贝构造函数、拷贝赋值运算符、移动赋值运算符或析构函数时,编译器才会为该类自动生成默认的移动构造函数。类似地,只有当类中没有用户声明的拷贝构造函数、移动构造函数、拷贝赋值运算符或析构函数时,编译器才会自动生成默认的移动赋值运算符。
当你声明了一个或多个特殊成员函数(析构函数、拷贝构造函数、移动构造函数、拷贝赋值运算符和移动赋值运算符)时,通常建议把它们全部都声明出来。这就是“五法则”(rule of five)。你要么为它们提供显式实现,要么显式默认(=default)或删除(=delete)。
使用 std::exchange
Section titled “使用 std::exchange”你可以使用定义在 <utility> 中的 std::exchange(),把某个值替换为新值,并返回它原来的旧值,如下例所示:
int a { 11 };int b { 22 };println("Before exchange(): a = {}, b = {}", a, b);int returnedValue { exchange(a, b) };println("After exchange(): a = {}, b = {}", a, b);println("exchange() returned: {}", returnedValue);输出如下:
Before exchange(): a = 11, b = 22After exchange(): a = 22, b = 22exchange() returned: 11exchange() 在实现移动赋值运算符时非常有用。移动赋值运算符需要把数据从源对象移到目标对象中,之后源对象中的数据通常会被置空。上一节的做法如下:
void Spreadsheet::moveFrom(Spreadsheet& src) noexcept{ // Shallow copy of data m_width = src.m_width; m_height = src.m_height; m_cells = src.m_cells;
// Reset the source object, because ownership has been moved! src.m_width = 0; src.m_height = 0; src.m_cells = nullptr;}这个成员函数先复制源对象中的 m_width、m_height 与 m_cells,然后把它们设为 0 或 nullptr,因为所有权已经转移。借助 exchange(),这段代码可以更紧凑地写成:
void Spreadsheet::moveFrom(Spreadsheet& src) noexcept{ m_width = exchange(src.m_width, 0); m_height = exchange(src.m_height, 0); m_cells = exchange(src.m_cells, nullptr);}移动对象数据成员
Section titled “移动对象数据成员”moveFrom() 中之所以直接赋值那三个数据成员,是因为它们都是基本类型。如果对象的数据成员里还包含其他对象,那么你应使用 std::move() 来移动这些对象。假设 Spreadsheet 类额外有一个名为 m_name 的 std::string 数据成员,那么 moveFrom() 应这样实现:
void Spreadsheet::moveFrom(Spreadsheet& src) noexcept{ // Move object data members m_name = std::move(src.m_name);
// Move primitives: m_width = exchange(src.m_width, 0); m_height = exchange(src.m_height, 0); m_cells = exchange(src.m_cells, nullptr);}基于 swap 的移动构造与移动赋值
Section titled “基于 swap 的移动构造与移动赋值”前面的移动构造函数和移动赋值运算符实现,都依赖 moveFrom() 辅助函数来通过浅拷贝移动所有数据成员。这样做有个问题:如果你给 Spreadsheet 新增了一个数据成员,那你就必须同时修改 swap() 和 moveFrom()。一旦忘了更新其中之一,就会引入 bug。为了避免这类错误,你可以把移动构造函数和移动赋值运算符都建立在 swap() 之上。
首先,可以移除 cleanup() 和 moveFrom() 这两个辅助函数。cleanup() 中的代码直接搬到析构函数里即可。然后,移动构造函数和移动赋值运算符可以写成如下形式:
Spreadsheet::Spreadsheet(Spreadsheet&& src) noexcept{ swap(src);}
Spreadsheet& Spreadsheet::operator=(Spreadsheet&& rhs) noexcept{ auto moved { std::move(rhs) }; // Move rhs into moved (noexcept) swap(moved); // Commit the work with only non-throwing operations return *this;}移动构造函数只是把默认构造出的 *this 与给定源对象交换。移动赋值运算符使用的是 move-and-swap 惯用法,它与前面介绍的 copy-and-swap 很相似。
Spreadsheet 的移动赋值运算符也可以写成下面这样:
Spreadsheet& Spreadsheet::operator=(Spreadsheet&& rhs) noexcept{ swap(rhs); return *this;}不过,这样做并不能保证 this 原先持有的内容会立刻被清理掉。相反,this 的旧内容会通过 rhs “逃逸”回移动赋值运算符的调用者那里,从而可能比预期活得更久。
测试 Spreadsheet 的移动操作
Section titled “测试 Spreadsheet 的移动操作”可以用下面这段代码测试 Spreadsheet 的移动构造与移动赋值:
Spreadsheet createObject(){ return Spreadsheet { 3, 2 };}
int main(){ vector<Spreadsheet> vec; for (size_t i { 0 }; i < 2; ++i) { println("Iteration {}", i); vec.push_back(Spreadsheet { 100, 100 }); println(""); }
Spreadsheet s { 2, 3 }; s = createObject();
println("");
Spreadsheet s2 { 5, 6 }; s2 = s;}第 1 章 介绍过 vector。vector 会动态增长以容纳新对象。它的做法是分配一块更大的内存,再把旧 vector 中的对象拷贝或移动到新的、更大的 vector 中。如果编译器发现类提供了 noexcept 移动构造函数,对象就会被移动而不是被拷贝。由于发生的是 move,就无需做任何深拷贝,因此效率会高得多。
如果我们在 Spreadsheet 类的所有构造函数与赋值运算符中都加入打印语句,那么前面测试程序的输出可能如下所示。每行右侧的数字并不是程序真实输出的一部分,而是为了便于后续讨论而在书中额外加上的。这里的输出与后续讨论,基于的是“使用 move-and-swap 惯用法来实现移动操作”的 Spreadsheet 版本,以及 Microsoft Visual C++ 2022 编译器在发布版构建下的结果。C++ 标准并没有规定 vector 的初始容量以及它的增长策略,因此在不同编译器上输出可能会有所不同。
Iteration 0Normal constructor (1)Move constructor (2)
Iteration 1Normal constructor (3)Move constructor (4)Move constructor (5)
Normal constructor (6)Normal constructor (7)Move assignment operator (8)Move constructor (9)
Normal constructor (10)Copy assignment operator (11)Normal constructor (12)Copy constructor (13)在循环的第一次迭代中,vector 还是空的。看循环中的这一行代码:
vec.push_back(Spreadsheet { 100, 100 });执行这一行时,会先创建一个新的 Spreadsheet 对象,从而调用普通构造函数 (1)。随后 vector 调整自身大小,为新加入的对象腾出空间。刚创建出来的 Spreadsheet 对象随后被移动进 vector,因此调用移动构造函数 (2)。
在循环的第二次迭代中,又会通过普通构造函数创建第二个 Spreadsheet 对象 (3)。此时 vector 只能容纳一个元素,所以它又会扩容以容纳第二个对象。由于 vector 扩容,原先已经存进去的元素都必须从旧 vector 移动到新的、更大的 vector 中。这会对每个已有元素触发一次移动构造函数调用。因为旧 vector 里只有一个元素,所以移动构造函数被调用一次 (4)。最后,新创建的 Spreadsheet 对象又会用其移动构造函数被移入 vector 中 (5)。
接着,使用普通构造函数创建 Spreadsheet 对象 s (6)。createObject() 函数内部先通过普通构造函数创建一个临时 Spreadsheet 对象 (7),随后把它返回给调用点并赋值给变量 s。由于 createObject() 返回的这个临时对象在赋值之后就会消失,编译器会调用移动赋值运算符 (8),而不是拷贝赋值运算符。这个移动赋值运算符使用的是 move-and-swap 惯用法,因此它又把工作委托给移动构造函数 (9)。
随后再通过普通构造函数创建另一个 Spreadsheet 对象 s2 (10)。语句 s2 = s 会调用拷贝赋值运算符 (11),因为右侧对象不是临时对象,而是具名对象。这个拷贝赋值运算符使用的是 copy-and-swap 惯用法,因此会先创建一个临时副本,从而触发拷贝构造函数调用;而该拷贝构造函数又首先委托给普通构造函数,于是产生了 (12) 与 (13)。
如果 Spreadsheet 类没有实现移动语义,那么所有对移动构造函数和移动赋值运算符的调用,都会退化成对拷贝构造函数和拷贝赋值运算符的调用。前面的例子里,循环中的 Spreadsheet 对象各自有 10,000 个元素(100 × 100)。Spreadsheet 的移动构造函数和移动赋值运算符都不需要任何内存分配,而拷贝构造函数和拷贝赋值运算符却各需要 101 次分配。因此,在某些场景下,使用移动语义可以显著提升性能。
使用移动语义实现 swap
Section titled “使用移动语义实现 swap”再看一个“移动语义能提升性能”的例子:交换两个 Object 的 swap() 函数。下面这个 swapCopy() 实现并没有使用移动语义:
void swapCopy(Object& a, Object& b){ Object temp { a }; a = b; b = temp;}这里先把 a 拷贝到 temp,再把 b 拷贝给 a,最后再把 temp 拷贝给 b。如果 Object 的拷贝成本很高,这个实现就会拖慢性能。使用移动语义后,实现便可以完全避免这些拷贝:
void swapMove(Object& a, Object& b){ Object temp { std::move(a) }; a = std::move(b); b = std::move(temp);}标准库中的 std::swap() 就是这样实现的。
在 return 语句中使用 std::move()
Section titled “在 return 语句中使用 std::move()”正如 第 1 章 所说,自 C++17 起,对于形如 return object; 且 object 是一个无名临时对象的语句,编译器不允许再对对象执行任何拷贝或移动。这被称为强制性拷贝/移动消除(mandatory elision of copy/move operations),意味着按值返回这样的 object 完全没有性能损失。如果 object 是一个不是函数参数的局部变量,则允许编译器执行非强制性拷贝/移动消除(non-mandatory elision of copy/move operations),这项优化也被称为 named return value optimization(NRVO)。标准并不保证一定进行这种优化。有些编译器只会在发布构建中执行它,在调试构建中则不会。有了强制与非强制消除,编译器就可以避免对函数返回值做任何拷贝,从而实现零拷贝的按值传递(zero-copy pass-by-value)语义。
要注意,对于 NRVO 来说,即便拷贝/移动构造函数实际上不会被调用,它们也仍然必须是可访问的;否则根据标准,程序就是 ill-formed。
那么,如果在返回对象时使用 std::move() 会发生什么呢? 假设你写的是下面这样的代码:
return std::move(object);一旦这么写,编译器就不能再应用强制性或非强制性(NRVO)的拷贝/移动消除了,因为那些优化只适用于 return object; 这种形式。既然不能进行消除,编译器接下来的选择就是:如果对象支持移动语义,则退回到 move;否则再退回到 copy。
与 NRVO 相比,退回到移动语义只会带来一点点性能影响;但如果退回到拷贝语义,性能损失就可能很大! 所以请牢牢记住下面这条告诫:
当从函数返回一个局部变量或无名临时对象时,直接写 return object;,不要使用 std::move()。
需要注意的是,如果你想从类的某个成员函数里返回该类的某个数据成员,并且希望把它 move 出去而不是返回一个副本,那么就需要使用 std::move()。
另外,还要小心下面这类表达式:
return condition ? obj1 : obj2;它并不符合 return object; 的形式,因此编译器无法进行拷贝/移动消除。更糟的是,condition ? obj1 : obj2 这种表达式本身是一个左值,因此编译器会转而使用拷贝构造函数来返回其中一个对象。为了至少触发移动语义,你可以把 return 语句改写为:
return condition ? std::move(obj1) : std::move(obj2);或者:
return std::move(condition ? obj1 : obj2);不过,更清晰的写法是把 return 语句重写为如下形式,这样编译器就能自动使用移动语义,而无需显式写出 std::move():
if (condition) { return obj1;} else { return obj2;}把参数传给函数的最佳方式
Section titled “把参数传给函数的最佳方式”到目前为止,通常的建议一直是:对于非基本类型的函数参数,应使用“引用到 const”的参数形式,以避免把实参传给函数时发生不必要且昂贵的复制。然而,当右值也加入讨论之后,事情就会有一点变化。设想这样一种函数:它无论如何都会拷贝它接收到的某个参数。这种情况在类成员函数中很常见。下面是一个简单例子:
class DataHolder{ public: void setData(const vector<int>& data) { m_data = data; } private: vector<int> m_data;};setData() 会把传进来的数据复制一份。现在你已经熟悉右值和右值引用了,可能会想再加一个重载,在遇到右值时避免复制。如下所示:
class DataHolder{ public: void setData(const vector<int>& data) { m_data = data; } void setData(vector<int>&& data) { m_data = move(data); } private: vector<int> m_data;};这样一来,当 setData() 用临时对象调用时,就不会发生复制,而是直接 move 数据。
下面这段代码会触发对“引用到 const”版本 setData() 的调用,因此会复制一份数据:
DataHolder wrapper;vector myData { 11, 22, 33 };wrapper.setData(myData);而下面这段代码则用临时对象调用 setData(),因此会调用右值引用重载,数据会被 move 而不是被 copy:
wrapper.setData({ 22, 33, 44 });遗憾的是,为了同时为左值和右值优化 setData(),这种写法需要实现两个重载。幸运的是,还有一种更好的做法:只用一个成员函数,并采用按值传递(pass-by-value)。是的,按值传递! 前面我们一直建议用“引用到 const”来传对象,以避免不必要的复制;但现在,对于某一类场景,我们反而建议使用按值传递。这里需要澄清:如果参数并不会在函数内部被复制,那么“引用到 const”仍然是最佳选择。只有当函数本来就会复制这个参数时,按值传递的建议才适用。在那种情况下,按值传递对左值和右值都同样最优。如果传进来的是左值,它只会被复制一次,与“引用到 const”的做法一样;而如果传进来的是右值,则不会发生复制,与右值引用参数的做法一样。来看代码:
class DataHolder{ public: void setData(vector<int> data) { m_data = move(data); } private: vector<int> m_data;};如果向 setData() 传入左值,它会先被复制到参数 data 中,然后再被 move 到 m_data。如果传入右值,它会先被 move 到参数 data 中,随后再 move 到 m_data。
前面本章介绍了五法则(rule of five)。它的意思是:一旦你声明了五个特殊成员函数中的任意一个(析构函数、拷贝构造函数、移动构造函数、拷贝赋值运算符和移动赋值运算符),就应该把它们全部都声明出来,要么实现,要么默认化,要么删除。原因在于,编译器是否自动提供这些特殊成员函数,其判定规则相当复杂。你把它们全部自己声明出来,就不会把决定权留给编译器,从而让你的意图更清晰。
前面那些讨论,都是为了说明该如何编写这五个特殊成员函数。不过,在现代 C++ 中,你真正应该采纳的是零法则(rule of zero)。
零法则指出:你应该把类设计成根本不需要这五个特殊成员函数。怎么做到这一点呢? 对于非多态类型,只要避免使用老式的动态分配内存或其他资源即可。相反,应使用现代构造,例如标准库容器和智能指针。举例来说,你可以用 vector<vector<SpreadsheetCell>> 来替代 Spreadsheet 类里的 SpreadsheetCell** 数据成员。更进一步,甚至可以用一个 vector<SpreadsheetCell> 来存放电子表格的线性化表示。vector 会自动处理内存,因此你就完全不需要那五个特殊成员函数中的任何一个。
在现代 C++ 中,请践行零法则!
五法则应当只局限于自定义的 RAII(resource acquisition is initialization, 资源获取即初始化)类。RAII 类负责拥有某种资源,并在正确的时机释放它。vector 与 unique_ptr 就采用了这种设计技术,并会在 第 32 章“融入设计技术与框架”中进一步讨论。另外,第 10 章 还会解释:多态类型同样要求你遵守五法则。
关于成员函数的更多内容
Section titled “关于成员函数的更多内容”C++ 为成员函数提供了大量选择。本节将讲解其中所有容易踩坑的细节。
static 成员函数
Section titled “static 成员函数”和数据成员一样,成员函数有时也适用于整个类,而不是每个具体对象。你不仅可以编写 static 数据成员,也可以编写 static 成员函数。举例来说,考虑 第 8 章 中的 SpreadsheetCell 类。它有两个辅助成员函数:stringToDouble() 和 doubleToString()。这些成员函数并不访问某个具体对象的信息,因此它们完全可以被声明为 static。把它们改为 static 之后,类定义如下:
export class SpreadsheetCell{ // Omitted for brevity private: static std::string doubleToString(double value); static double stringToDouble(std::string_view value); // Omitted for brevity};这两个成员函数的实现与之前完全相同。你不需要在成员函数定义前再次写 static 关键字。注意,static 成员函数并不是针对某个具体对象调用的,因此它们没有 this 指针,也不是在某个特定对象上执行,所以无法直接访问该对象的非 static 成员。事实上,static 成员函数几乎就像普通函数一样。唯一的区别是,它可以访问该类的 private static 与 protected static 成员。此外,如果有同类型对象通过参数(例如引用或指针)传递给它,它也可以访问这些对象上的 private 和 protected 非 static 成员。
在类的任意成员函数内部,你都可以像调用普通成员函数一样调用 static 成员函数。因此,SpreadsheetCell 中所有成员函数的实现都可以保持不变。
在类外部,则需要通过作用域解析运算符,使用类名限定 static 成员函数名。访问控制照常生效。例如,若有类 Foo 定义了一个名为 bar() 的 public static 成员函数,那么你可以在代码的任何位置这样调用它:
Foo::bar();const 成员函数
Section titled “const 成员函数”const 对象是指其值不能被修改的对象。如果你手里拿着的是一个 const 对象、对 const 的引用,或指向 const 对象的指针,那么除非某个成员函数保证自己不会修改任何数据成员,否则编译器不会允许你在这个对象上调用它。要做出这种保证,就需要把成员函数本身标记为 const。在 第 8 章 构建 SpreadsheetCell 类的过程中,我们已经一直这样做了。为了便于回忆,下面给出 SpreadsheetCell 类的一部分定义,其中那些不会修改任何数据成员的成员函数都被标记为 const:
export class SpreadsheetCell{ public: double getValue() const; std::string getString() const; // Omitted for brevity};const 说明符是成员函数原型的一部分,因此在定义中也必须带上它:
double SpreadsheetCell::getValue() const{ return m_value;}
string SpreadsheetCell::getString() const{ return doubleToString(m_value);}把某个成员函数标记为 const,就等于向调用方签下了一份契约:保证你不会在该成员函数内部修改对象的内部值。如果你试图把一个实际上会修改数据成员的成员函数声明为 const,编译器就会报错。const 成员函数之所以能做到这一点,是因为在成员函数内部,编译器会把每个数据成员都视为“对 const 的引用”。因此,只要你尝试去改动某个数据成员,编译器就会把它标成错误。
你不能把 static 成员函数声明为 const,因为这毫无意义。static 成员函数并不作用于某个具体类实例,因此谈不上修改其内部状态。
你可以在一个非 const 对象上调用 const 与非 const 成员函数。但对于 const 对象,你只能调用 const 成员函数。下面是一些示例:
SpreadsheetCell myCell { 5 };println("{}", myCell.getValue()); // OKmyCell.setString("6"); // OK
const SpreadsheetCell& myCellConstRef { myCell };println("{}", myCellConstRef.getValue()); // OKmyCellConstRef.setString("6"); // Compilation Error!你应该养成这样的习惯:凡是不会修改对象的成员函数,都尽量声明为 const,这样你就能在程序中更广泛地使用指向 const 对象的引用。
注意,const 对象仍然可以被销毁,其析构函数仍然可以被调用。不过,析构函数本身不能声明为 const。
mutable 数据成员
Section titled “mutable 数据成员”有时你会编写一个在“逻辑上”是 const 的成员函数,但它恰好需要修改对象中的某个数据成员。这个修改不会影响任何用户可见的数据,但从技术上讲它确实修改了对象,因此编译器不允许你把这个成员函数声明为 const。例如,假设你想对电子表格程序做性能分析,了解数据被读取的频率。一种粗糙但有效的方法,是给 SpreadsheetCell 类加一个计数器,统计 getValue() 或 getString() 被调用了多少次。可惜这会让这两个成员函数在编译器看来都变成非 const,这显然不是你的本意。解决办法就是把这个计数器变量声明为 mutable,它告诉编译器:即使在 const 成员函数里修改它也没关系。修改后的 SpreadsheetCell 类定义如下:
export class SpreadsheetCell{ // Omitted for brevity private: double m_value { 0 }; mutable unsigned m_numAccesses { 0 };};下面是 getValue() 和 getString() 的定义:
double SpreadsheetCell::getValue() const{ ++m_numAccesses; return m_value;}
string SpreadsheetCell::getString() const{ ++m_numAccesses; return doubleToString(m_value);}成员函数重载
Section titled “成员函数重载”你已经注意到,在一个类中可以写多个构造函数,它们名字相同,只是在参数的数量和/或类型上有所不同。对于 C++ 中的任何成员函数或普通函数,你也都可以这样做。具体来说,只要参数的数量和/或类型不同,你就可以使用同一个函数名去重载(overload)多个函数或成员函数。例如,在 SpreadsheetCell 类中,你可以把 setString() 和 setValue() 都改名为 set()。此时类定义看起来像这样:
export class SpreadsheetCell{ public: void set(double value); void set(std::string_view value); // Omitted for brevity};这两个 set() 成员函数的实现保持不变。当你在代码中调用 set() 时,编译器会根据你传入的实参来决定调用哪一个版本:如果传的是 string_view,就调用 string_view 版本;如果传的是 double,就调用 double 版本。这称为重载决议(overload resolution)。
你也许会想对 getValue() 和 getString() 做同样的事情,把它们都改成 get()。但这行不通。C++ 不允许只根据返回类型来重载成员函数名,因为在很多情况下,编译器根本无法判断你究竟想调用哪个版本。例如,若成员函数的返回值没有被接收,编译器就无法知道你到底想调用哪一个版本。
基于 const 的重载
Section titled “基于 const 的重载”你可以基于 const 对成员函数做重载。也就是说,你可以编写两个名字和参数都相同的成员函数,其中一个声明为 const,另一个则不是。若对象是 const,编译器就会调用 const 成员函数;若对象是非 const,编译器就会调用非 const 版本。编写这两个重载成员函数时,往往容易引入代码重复,因为 const 与非 const 版本的实现常常是完全相同的。正如你已经知道的,哪怕只有几行代码,重复也应尽量避免。这样做符合 第 6 章 讨论过的 DRY(Don’t Repeat Yourself) 原则,也能让未来维护更轻松。比如,几个月甚至几年后,如果你需要对一段重复代码做一个小修改,你就必须记得把同样的修改同步到所有副本中。
接下来的几小节会给出两种办法,帮助你在编写这种重载成员函数时避免代码重复。
Scott Meyers 的 const_cast() 模式
Section titled “Scott Meyers 的 const_cast() 模式”为避免代码重复,你可以使用 Scott Meyers 的 const_cast() 模式。例如,Spreadsheet 类有一个成员函数 getCellAt(),它返回一个指向 SpreadsheetCell 的非 const 引用。你可以再添加一个 const 重载,让它返回对 SpreadsheetCell 的“引用到 const”,如下所示:
export class Spreadsheet{ public: SpreadsheetCell& getCellAt(std::size_t x, std::size_t y); const SpreadsheetCell& getCellAt(std::size_t x, std::size_t y) const; // Code omitted for brevity.};Scott Meyers 的 const_cast() 模式的做法是:把 const 版本按正常方式实现,而把非 const 版本通过适当的类型转换转发给 const 版本,如下:
const SpreadsheetCell& Spreadsheet::getCellAt(size_t x, size_t y) const{ verifyCoordinate(x, y); return m_cells[x][y];}
SpreadsheetCell& Spreadsheet::getCellAt(size_t x, size_t y){ return const_cast<SpreadsheetCell&>(as_const(*this).getCellAt(x, y));}这个模式首先使用 std::as_const()(定义在 <utility> 中)把 *this(类型为 Spreadsheet&) 转成 const Spreadsheet&。接着调用 const 版本的 getCellAt(),它会返回一个 const SpreadsheetCell&。最后再通过 const_cast() 把它转换成非 const SpreadsheetCell&。
有了这两个 getCellAt() 重载后,你就可以分别在 const 与非 const 的 Spreadsheet 对象上调用它:
Spreadsheet sheet1 { 5, 6 };SpreadsheetCell& cell1 { sheet1.getCellAt(1, 1) };
const Spreadsheet sheet2 { 5, 6 };const SpreadsheetCell& cell2 { sheet2.getCellAt(1, 1) };private 辅助成员函数
Section titled “private 辅助成员函数”另一种在同时实现 const 与非 const 重载时避免重复代码的办法,是增加一个 private const 辅助成员函数,但让它返回非 const 类型。随后,const 与非 const 的重载成员函数都去调用这个辅助函数。例如,对于前一节里的 getCellAt() 重载,可以加入一个 getCellAtHelper(),如下:
export class Spreadsheet{ public: SpreadsheetCell& getCellAt(std::size_t x, std::size_t y); const SpreadsheetCell& getCellAt(std::size_t x, std::size_t y) const; // Code omitted for brevity. private: SpreadsheetCell& getCellAtHelper(std::size_t x, std::size_t y) const;};对应实现如下:
SpreadsheetCell& Spreadsheet::getCellAt(size_t x, size_t y){ return getCellAtHelper(x, y);}
const SpreadsheetCell& Spreadsheet::getCellAt(size_t x, size_t y) const{ return getCellAtHelper(x, y);}
SpreadsheetCell& Spreadsheet::getCellAtHelper(size_t x, size_t y) const{ verifyCoordinate(x, y); return m_cells[x][y];}显式删除某些重载
Section titled “显式删除某些重载”重载成员函数也可以被显式删除,从而让你禁止别人用特定参数调用某个成员函数。例如,SpreadsheetCell 类有一个成员函数 setValue(double),可以这样调用:
SpreadsheetCell cell;cell.setValue(1.23);cell.setValue(123);对于第三行,编译器会先把整数值 123 转换成 double,再调用 setValue(double)。如果出于某种原因,你不希望 setValue() 接受整数参数,那么就可以显式删除一个整型版本的重载:
export class SpreadsheetCell{ public: void setValue(double value); void setValue(int) = delete;};这样一改,任何试图用整数来调用 setValue() 的代码,都会被编译器标记为错误。
带引用限定符的成员函数
Section titled “带引用限定符的成员函数”普通类成员函数既可以在非临时对象上调用,也可以在临时对象上调用。假设你有下面这样一个类,它只是简单记住构造函数接收到的那个 string:
class TextHolder{ public: explicit TextHolder(string text) : m_text { move(text) } {} const string& getText() const { return m_text; } private: string m_text;};当然,毫无疑问,你可以在 TextHolder 的非临时实例上调用 getText()。如下所示:
TextHolder textHolder { "Hello world!" };println("{}", textHolder.getText());不过,getText() 同样可以在临时实例上调用:
println("{}", TextHolder{ "Hello world!" }.getText());实际上,你可以显式规定某个成员函数只能在哪类实例上调用——是临时对象还是非临时对象。这是通过给成员函数加上引用限定符(ref-qualifier)来实现的。如果一个成员函数只能在非临时对象上调用,就在其函数头后面加上 & 限定符。类似地,如果只能在临时对象上调用,则加上 &&。
下面修改后的 TextHolder 类中,& 限定的 getText() 返回对 m_text 的“引用到 const”;而 && 限定的 getText() 则返回指向 m_text 的右值引用,这样就能把 m_text 从一个 TextHolder 中 move 出去。比如,如果你想从一个临时的 TextHolder 实例中取出文本,这种做法就会更高效。
class TextHolder{ public: explicit TextHolder(string text) : m_text { move(text) } {} const string& getText() const & { return m_text; } string&& getText() && { return move(m_text); } private: string m_text;};假设你有下面这些调用:
TextHolder textHolder { "Hello world!" };println("{}", textHolder.getText());println("{}", TextHolder{ "Hello world!" }.getText());那么第一次对 getText() 的调用会命中 & 限定版本,而第二次调用则会命中 && 限定版本。
引用限定符的第二个应用场景,是阻止用户给某个临时对象赋值。例如,你可以给 TextHolder 添加一个赋值运算符:
class TextHolder{ public: TextHolder& operator=(const string& rhs) { m_text = rhs; return *this; } // Remainder of the class definition omitted for brevity};一旦给 TextHolder 增加了这样一个赋值运算符,就会允许人们写出下面这样的代码,给一个临时 TextHolder 实例赋新值,但这其实没什么意义,因为该对象很快就会消失:
TextHolder makeTextHolder() { return TextHolder { "Hello World!" }; }
int main(){ makeTextHolder() = "Pointless!"; // Pointless, object is a temporary.}可以通过给赋值运算符添加引用限定符,让它只对左值生效,从而阻止这种毫无意义的操作:
TextHolder& operator=(const string& rhs) & { m_text = rhs; return *this; }有了这个赋值运算符之后,前面 main() 中那条 "Pointless!" 语句就无法通过编译了。此时你只能给左值赋新值:
auto text { makeTextHolder() };text = "Ok";
Section titled “ 使用显式对象参数实现引用限定”正如 第 8 章 所解释的,C++23 引入了显式对象参数(explicit object parameters)这一概念。有了它,你就可以用稍微不同的语法,重写前面 TextHolder 类中的那些带引用限定符的成员函数:
class TextHolder{ public: const string& getText(this const TextHolder& self) { return self.m_text; } string&& getText(this TextHolder&& self) { return move(self.m_text); }
TextHolder& operator=(this TextHolder& self, const string& rhs) { self.m_text = rhs; return self; } // Remainder of the class definition omitted for brevity};这种写法当然比前一节的语法更啰唆,但它把“引用限定”的意图表达得更明显。在前一节里,函数签名末尾只是多了一个 & 或 &&,这在同事做代码审查时很容易被忽略。
inline 成员函数
Section titled “inline 成员函数”C++ 允许你向编译器建议:某个函数调用不必在生成的代码里表现为“跳转到另一段代码去执行”,而是直接把该函数的函数体插入到调用点。这一过程称为内联(inlining),希望获得这种行为的函数就叫内联函数(inline functions)。
你可以通过在成员函数定义中的函数名前加上 inline 关键字,把它声明为内联成员函数。例如,你可能想把 SpreadsheetCell 类中的几个访问器成员函数都设为 inline,此时定义可以写成:
inline double SpreadsheetCell::getValue() const{ ++m_numAccesses; return m_value;}
inline std::string SpreadsheetCell::getString() const{ ++m_numAccesses; return doubleToString(m_value);}这相当于给编译器一个提示:在调用 getValue() 与 getString() 的地方,用函数体本身替换函数调用,而不是生成真正的调用代码。需要注意的是,inline 关键字只是给编译器的一个提示。如果编译器认为内联会损害性能,它完全可以忽略这个提示。
不过有一个注意点:内联函数的定义必须在每个调用它的源文件中都可见。稍微想一下就会明白为什么:如果编译器看不到函数定义,它怎么把函数体替换到调用点中去呢? 因此,如果你编写 inline 成员函数,就应该把这些成员函数的定义放在与类定义相同的文件中。
在 C++ 模块之外,如果某个成员函数定义直接写在类定义内部,那么即使没有写 inline 关键字,它也会被隐式视为 inline。但对于从模块中导出的类,情况并非如此。如果你希望这类成员函数真正成为内联函数,就必须显式写出 inline 关键字。示例如下:
export class SpreadsheetCell{ public: inline double getValue() const { ++m_numAccesses; return m_value; }
inline std::string getString() const { ++m_numAccesses; return doubleToString(m_value); } // Omitted for brevity};很多 C++ 程序员在发现 inline 语法之后就开始到处使用,却没有真正理解其影响。把函数标记为 inline 只是在向编译器提出建议。编译器通常只会内联最简单的函数。如果你定义了一个编译器并不想内联的 inline 函数,编译器只会默默忽略你的提示。现代编译器在决定是否内联时,还会考虑代码膨胀等指标,任何不划算的内联都不会被执行。
C++ 中有一个与函数重载有些相似的特性,叫做默认参数(default arguments)。你可以在函数原型中为某些参数指定默认值。如果调用者显式提供了这些参数,默认值就会被忽略;如果调用者省略了这些参数,就会使用默认值。不过这里有个限制:你只能为从最右侧参数开始的一串连续参数指定默认值。否则,编译器就无法把缺失的实参与相应的默认参数对应起来。默认参数可以用于普通函数、成员函数和构造函数。举例来说,你可以像下面这样给 Spreadsheet 构造函数的宽度与高度指定默认值:
export class Spreadsheet{ public: explicit Spreadsheet(std::size_t width = 100, std::size_t height = 100); // Omitted for brevity};Spreadsheet 构造函数的实现保持不变。注意,默认参数只能出现在函数声明中,不能再次写在定义里。
这样一来,即使只有一个非拷贝构造函数,你现在也能用 0 个、1 个或 2 个参数来构造 Spreadsheet:
Spreadsheet s1;Spreadsheet s2 { 5 };Spreadsheet s3 { 5, 6 };如果某个构造函数对它的所有参数都提供了默认值,那么它就可以充当默认构造函数。也就是说,你可以在不传任何实参的情况下构造该类对象。如果你同时声明了一个默认构造函数,又声明了一个“对所有参数都给了默认值”的多参数构造函数,编译器就会抱怨,因为当你不传任何参数时,它根本不知道该调用哪一个构造函数。
constexpr 与 consteval
Section titled “constexpr 与 consteval”在现代 C++ 中,你可以很方便地把一些计算放到编译期执行,而不是等到运行期。这样能够提升代码的运行时性能。实现这一点主要依赖两个重要关键字:constexpr 与 consteval。
constexpr 关键字
Section titled “constexpr 关键字”C++ 从很早开始就有常量表达式(constant expressions)的概念,即在编译期求值的表达式。在某些场景下,常量表达式是强制要求。例如,定义数组时,数组大小必须是常量表达式。由于有这个限制,下面这段代码在 C++ 中就是不合法的:
const int getArraySize() { return 32; }
int main(){ int myArray[getArraySize()]; // ERROR: Invalid in C++ println("Size of array = {}", size(myArray));}使用 constexpr 关键字后,可以把 getArraySize() 改写成允许在常量表达式中调用的函数:
constexpr int getArraySize() { return 32; }
int main(){ int myArray[getArraySize()]; // OK println("Size of array = {}", size(myArray));}你甚至还可以这样写:
int myArray[getArraySize() + 1]; // OK常量表达式只能使用 constexpr 实体,以及整型、布尔型、字符型和枚举型常量。
把函数声明为 constexpr 会限制该函数可以做什么,因为编译器必须有能力在编译期对其求值。例如,constexpr 函数不能产生任何副作用,也不能让任何异常逃出函数。不过,在函数内部抛出异常并在 try 代码块中捕获它们是允许的。constexpr 函数可以无条件调用其他 constexpr 函数。它也可以调用非 constexpr 函数,但前提是这些调用只会在运行期求值时触发,而不会在常量求值期间触发。例如:
void log(string_view message) { print("{}", message); }
constexpr int computeSomething(bool someFlag){ if (someFlag) { log("someFlag is true"); return 42; } else { return 84; }}computeSomething() 是一个 constexpr 函数,其中还调用了非 constexpr 的 log()。但该调用只会在 someFlag 为 true 时执行。只要用 someFlag == false 去调用 computeSomething(),它就仍然可以出现在常量表达式中,例如:
constexpr auto value1 { computeSomething(false) };若用 someFlag == true 去调用它,则不能出现在常量表达式里。下面这段代码无法编译:
constexpr auto value2 { computeSomething(true) };而下面这段就完全没问题,因为此时求值发生在运行期而非编译期:
const auto value3 { computeSomething(true) };constexpr 函数的限制:现在 goto 语句、标签(除了 case 标签),以及 static 和 static constexpr 变量,都可以出现在 constexpr 函数中,而在之前的标准中这些都是不允许的。
consteval 关键字
Section titled “consteval 关键字”constexpr 关键字表达的是:某个函数可以在编译期执行,但它并不保证一定在编译期执行。看下面这个 constexpr 函数:
constexpr double inchToMm(double inch) { return inch * 25.4; }如果像下面这样调用,它就会如你所愿在编译期求值:
constexpr double const_inch { 6.0 };constexpr double mm1 { inchToMm(const_inch) }; // at compile time但是,如果像下面这样调用,它就不会在编译期求值,而是在运行期执行!
double dynamic_inch { 8.0 };double mm2 { inchToMm(dynamic_inch) }; // at run time如果你真的希望函数始终在编译期执行,就必须使用 consteval 关键字把它变成一个即时函数(immediate function)。inchToMm() 可以改成这样:
consteval double inchToMm(double inch) { return inch * 25.4; }此时,前面 mm1 那个定义中的 inchToMm() 调用仍然能正常编译,并且会在编译期求值。但 mm2 定义中的那个调用现在就会变成编译错误,因为它无法在编译期执行。
consteval int f(int i) { return i; }这个即时函数可以从某个 constexpr 函数中调用,但只有当那个 constexpr 函数本身也正在进行常量求值时才可以。例如,下面这个函数使用 if consteval 语句来检查当前是否正在进行常量求值;如果是,它就可以调用 f()。而在 else 分支里则不能调用 f()。
constexpr int g(int i){ if consteval { return f(i); } else { return 42; }}constexpr 与 consteval 类
Section titled “constexpr 与 consteval 类”通过定义 constexpr 或 consteval 构造函数,你可以创建用户自定义类型的常量表达式变量。与 constexpr 函数一样,constexpr 类的求值可能发生在编译期,也可能发生在运行期;而 consteval 类则保证在编译期求值。
下面这个 Matrix 类定义了一个 constexpr 构造函数,同时还定义了一个会执行某些计算的 constexpr getSize() 成员函数。
class Matrix{ public: Matrix() = default; // Implicitly constexpr
constexpr explicit Matrix(unsigned rows, unsigned columns) : m_rows { rows }, m_columns { columns } { }
constexpr unsigned getSize() const { return m_rows * m_columns; } private: unsigned m_rows { 0 }, m_columns { 0 };};用这个类来声明 constexpr 对象非常直接:
constexpr Matrix matrix { 8, 2 };constexpr Matrix matrixDefault;这样一个 constexpr 对象现在就可以被拿来做很多事情,例如创建一个足够大的数组,用来线性存放这个矩阵:
int linearizedMatrix[matrix.getSize()]; // OK由编译器生成的成员函数(无论是隐式生成,还是通过 =default 显式默认化),例如默认构造函数、析构函数、赋值运算符等,都会自动是 constexpr,除非类中包含某些数据成员,使得这些成员函数本身无法成为 constexpr。
constexpr 与 consteval 成员函数的定义必须对编译器可见,编译器才能在编译期对它们求值。这意味着,如果类定义在某个模块中,此类成员函数必须定义在模块接口文件里,而不能放在模块实现文件中。
数据成员的不同形式
Section titled “数据成员的不同形式”C++ 在数据成员方面也给了你很多选择。除了在类中声明普通数据成员之外,你还可以创建由整个类共享的 static 数据成员、const 成员、引用成员、对 const 的引用成员,等等。本节将详细解释这些不同种类数据成员的细节。
static 数据成员
Section titled “static 数据成员”有时候,让类的每个对象都各自持有某个变量的一份副本,不但浪费,甚至根本不可行。某个数据成员也许本质上是“属于这个类”的,但又不适合让每个对象都保留自己的副本。例如,你可能想给每个电子表格对象分配一个唯一的数字标识符。那你就需要一个从 0 开始的计数器,让每个新创建的对象从中获取自己的 ID。这个计数器显然属于 Spreadsheet 类,但让每个 Spreadsheet 对象都复制一份它又毫无意义,因为那样你还得想办法让所有计数器始终同步。C++ 通过*static 数据成员*(static data members)提供了解决方案。static 数据成员是与类关联,而不是与对象关联的数据成员。你可以把 static 数据成员理解为“某个类专属的全局变量”。下面是加入新 static 计数器数据成员后的 Spreadsheet 类定义:
export class Spreadsheet{ // Omitted for brevity private: static std::size_t ms_counter;};除了在类定义中列出 static 类成员,你还需要在某个源文件里为它们分配实际存储空间,通常就是你放置类成员函数定义的那个源文件。你可以同时对其进行初始化,不过要注意:与普通变量和普通数据成员不同,static 数据成员默认会被初始化为 0。static 指针则默认初始化为 nullptr。下面这段代码用于为 ms_counter 分配空间,并进行零初始化:
size_t Spreadsheet::ms_counter;static 数据成员默认就是零初始化的,不过如果你愿意,也可以显式写出 0 初始化:
size_t Spreadsheet::ms_counter { 0 };这段代码写在所有函数或成员函数体之外。它很像在声明一个全局变量,只不过通过 Spreadsheet:: 这个作用域限定,指出它属于 Spreadsheet 类。
与普通数据成员一样,访问控制说明符同样适用于 static 数据成员。你当然可以把 ms_counter 声明为 public,但正如你已经知道的,一般不推荐暴露 public 数据成员(const static 数据成员会在后文提到,它算是一个例外)。更好的做法是通过 public 的 getter 和 setter 成员函数来访问数据成员。如果你想暴露 static 数据成员,也可以提供 public static 的 get/set 成员函数。
你可以把 static 数据成员声明为内联(inline)。这样做的好处是,不再需要在源文件里为它们单独分配存储空间。示例如下:
export class Spreadsheet{ // Omitted for brevity private: static inline std::size_t ms_counter { 0 };};注意这里的 inline 关键字。有了这样的类定义后,源文件中的这一行就可以删掉了:
size_t Spreadsheet::ms_counter;在类成员函数内部访问 static 数据成员
Section titled “在类成员函数内部访问 static 数据成员”在类成员函数内部,你可以像使用普通数据成员那样使用 static 数据成员。例如,你可能想为 Spreadsheet 类添加一个 m_id 数据成员,并在 Spreadsheet 构造函数里用 ms_counter 对它进行初始化。带有 m_id 成员的 Spreadsheet 类定义如下:
export class Spreadsheet{ public: // Omitted for brevity std::size_t getId() const; private: // Omitted for brevity static inline std::size_t ms_counter { 0 }; std::size_t m_id { 0 };};下面是一个为对象分配初始 ID 的 Spreadsheet 构造函数实现:
Spreadsheet::Spreadsheet(size_t width, size_t height) : m_id { ms_counter++ }, m_width { width }, m_height { height }{ // Omitted for brevity}如你所见,构造函数可以像访问普通成员一样访问 ms_counter。拷贝构造函数也应该分配一个新的 ID。这里之所以会自动做到,是因为 Spreadsheet 的拷贝构造函数委托给了非拷贝构造函数,而后者会创建新的 ID。
在这个例子里,假定对象一旦拿到 ID,就永远不会改变。因此,在拷贝赋值运算符中就不应该去复制这个 ID。也正因如此,更推荐把 m_id 定义为一个 const 数据成员:
export class Spreadsheet{ private: // Omitted for brevity const std::size_t m_id { 0 };};由于 const 数据成员一旦创建后就不能修改,因此你不能在构造函数体内部再去给它赋值。这类成员必须要么直接在类定义中初始化,要么在构造函数的 ctor-initializer 中初始化。这也意味着,你不能在赋值运算符里再给它们赋新值。对 m_id 来说这不成问题,因为 Spreadsheet 一旦获得 ID,就永远不会变。不过,具体到你的场景,如果这会导致类无法赋值,通常就应显式删除赋值运算符。
constexpr static 数据成员
Section titled “constexpr static 数据成员”类中的数据成员也可以声明为 const 或 constexpr,意味着它们在创建并初始化之后就不能再被修改。当某些常量只适用于某个类时,你应该使用 static constexpr(或 constexpr static) 数据成员来代替全局常量;这类常量也叫类常量(class constants)。整型和枚举类型的 static constexpr 数据成员,即便没有声明为内联变量,也可以直接在类定义内部定义并初始化。例如,你可能想为电子表格规定一个最大宽度和最大高度。如果用户试图构造一个宽度或高度超过上限的电子表格,程序就自动使用最大值。你可以把这些最大值做成 Spreadsheet 类的 static constexpr 成员:
export class Spreadsheet{ public: // Omitted for brevity static constexpr std::size_t MaxHeight { 100 }; static constexpr std::size_t MaxWidth { 100 };};你可以在构造函数中像下面这样使用这些新常量:
Spreadsheet::Spreadsheet(size_t width, size_t height) : m_id { ms_counter++ } , m_width { std::min(width, MaxWidth) } // std::min() defined in <algorithm> , m_height { std::min(height, MaxHeight) }{ // Omitted for brevity}这类常量还可以用作参数的默认值。别忘了,你只能从最右侧参数开始,为一串连续参数提供默认值。示例如下:
export class Spreadsheet{ public: explicit Spreadsheet( std::size_t width = MaxWidth, std::size_t height = MaxHeight); // Omitted for brevity};在类成员函数之外访问 static 数据成员
Section titled “在类成员函数之外访问 static 数据成员”如前所述,访问控制说明符同样适用于 static 数据成员:MaxWidth 和 MaxHeight 是 public,因此可以在类成员函数之外访问,方式是用 :: 作用域解析运算符指明它们属于 Spreadsheet 类。例如:
println("Maximum height is: {}", Spreadsheet::MaxHeight);引用数据成员
Section titled “引用数据成员”Spreadsheet 与 SpreadsheetCell 固然很不错,但它们本身还不足以构成一个真正有用的应用程序。你还需要有代码来控制整个电子表格程序,而你可以把这些控制逻辑封装进一个 SpreadsheetApplication 类中。进一步假设,我们希望每个 Spreadsheet 都保存一份对应用对象的引用。此刻 SpreadsheetApplication 类的确切定义并不重要,所以下面的代码只把它简单地定义成一个空类。Spreadsheet 类则被修改为包含一个新的引用数据成员 m_theApp:
export class SpreadsheetApplication { };
export class Spreadsheet{ public: Spreadsheet(std::size_t width, std::size_t height, SpreadsheetApplication& theApp); // Code omitted for brevity. private: // Code omitted for brevity. SpreadsheetApplication& m_theApp;};这个定义给 Spreadsheet 增加了一个 SpreadsheetApplication 引用数据成员。在这种场景下,推荐使用引用而不是指针,因为 Spreadsheet 理应始终关联着某个 SpreadsheetApplication。若用指针,这一点就无法得到保证。
需要注意的是,这里让 Spreadsheet 保存对应用对象的引用,只是为了演示“引用作为数据成员”的用法。并不推荐用这种方式把 Spreadsheet 与 SpreadsheetApplication 紧耦合在一起。更好的选择,是使用诸如 Model-View-Controller(MVC) 这样的范式,它在 第 4 章“设计专业级 C++ 程序”中有介绍。
应用对象的引用会在每个 Spreadsheet 的构造函数中传入。引用不能脱离被引用对象而单独存在,因此 m_theApp 必须在构造函数的 ctor-initializer 中被初始化。
Spreadsheet::Spreadsheet(size_t width, size_t height, SpreadsheetApplication& theApp) : m_id { ms_counter++ } , m_width { std::min(width, MaxWidth) } , m_height { std::min(height, MaxHeight) } , m_theApp { theApp }{ // Code omitted for brevity.}你还必须在拷贝构造函数中初始化这个引用成员。这里之所以会自动完成,是因为 Spreadsheet 的拷贝构造函数委托给了非拷贝构造函数,而后者会负责初始化这个引用数据成员。
请记住:引用一旦初始化之后,就不能再改为引用别的对象。因此,在赋值运算符中不可能“给引用重新赋值”。根据具体场景,这可能意味着你的类一旦包含引用数据成员,就根本无法提供赋值运算符。若确实如此,通常应把赋值运算符显式标记为 deleted。
最后,引用数据成员本身也可以是对 const 的引用。例如,你也许会决定 Spreadsheet 只保留对应用对象的“引用到 const”。此时只需把类定义改成让 m_theApp 成为“引用到 const”即可:
export class Spreadsheet{ public: Spreadsheet(std::size_t width, std::size_t height, const SpreadsheetApplication& theApp); // Code omitted for brevity. private: // Code omitted for brevity. const SpreadsheetApplication& m_theApp;};类定义中包含的内容并不仅限于成员函数和数据成员。它还可以包含嵌套的类和 struct、类型别名以及枚举。凡是在类内部声明的内容,都位于该类的作用域之内。如果它是 public,那么在类外部就可以通过 ClassName:: 这种作用域限定语法访问它。
你可以在一个类定义内部再提供另一个类定义。例如,你可能会决定 SpreadsheetCell 类其实本来就属于 Spreadsheet 类的一部分。既然它已经成了 Spreadsheet 的组成部分,不妨把它重命名为 Cell。你可以像下面这样定义这两个类:
export class Spreadsheet{ public: class Cell { public: Cell() = default; Cell(double initialValue); // Remainder omitted for brevity };
Spreadsheet(std::size_t width, std::size_t height, const SpreadsheetApplication& theApp); // Remainder of Spreadsheet declarations omitted for brevity};现在,Cell 类是定义在 Spreadsheet 类内部的,因此在 Spreadsheet 类外部,任何引用 Cell 的地方都必须带上 Spreadsheet:: 作用域限定。即便是成员函数定义也不例外。例如,此时 Cell 的那个 double 构造函数就必须写成:
Spreadsheet::Cell::Cell(double initialValue) : m_value { initialValue }{}就连 Spreadsheet 类自身成员函数的返回类型(但参数类型不用)也必须使用这种语法:
const Spreadsheet::Cell& Spreadsheet::getCellAt(size_t x, size_t y) const{ verifyCoordinate(x, y); return m_cells[x][y];}如果把嵌套的 Cell 类完整定义直接写在 Spreadsheet 类内部,那么 Spreadsheet 类定义看上去会显得有点臃肿。你可以只在 Spreadsheet 类中保留 Cell 的前向声明,再把 Cell 类单独定义在后面,这样可以缓解这种臃肿感:
export class Spreadsheet{ public: class Cell;
Spreadsheet(std::size_t width, std::size_t height, const SpreadsheetApplication& theApp); // Remainder of Spreadsheet declarations omitted for brevity};class Spreadsheet::Cell{ public: Cell() = default; Cell(double initialValue); // Omitted for brevity};普通的访问控制规则同样适用于嵌套类定义。如果你把嵌套类声明为 private 或 protected,那么它就只能在外层类内部使用。嵌套类可以访问外层类的全部 protected 和 private 成员。反过来,外层类却只能访问嵌套类中的 public 成员。
枚举也可以成为类的数据成员。例如,你可以像下面这样为 SpreadsheetCell 类添加单元格着色支持:
export class SpreadsheetCell{ public: // Omitted for brevity enum class Color { Red = 1, Green, Blue, Yellow }; void setColor(Color color); Color getColor() const; private: // Omitted for brevity Color m_color { Color::Red };};setColor() 和 getColor() 的实现都很直接:
void SpreadsheetCell::setColor(Color color) { m_color = color; }SpreadsheetCell::Color SpreadsheetCell::getColor() const { return m_color; }这些新成员函数可以像下面这样使用:
SpreadsheetCell myCell { 5 };myCell.setColor(SpreadsheetCell::Color::Blue);auto color { myCell.getColor() };你经常会想对对象执行各种操作,例如把它们相加、进行比较,或者把它们写入/读出文件。举例来说,只有当你能对电子表格执行算术操作(例如对一整行单元格求和)时,它才真正有用。而这些事情都可以通过重载运算符来完成。
很多人初次接触运算符重载时,都会觉得它的语法既拗口又让人困惑。讽刺的是,它原本是为了让事情更简单而设计的。正如本节会展示的那样,它并不是让编写类的人更简单,而是让使用类的人更简单。其核心目的,就是让你定义的新类尽可能像 int、double 这样的内建类型:用 + 去相加对象,显然比记住到底该调用 add() 还是 sum() 这样的成员函数名字更容易。
说到这里,你也许会好奇:到底哪些运算符可以重载? 答案是几乎全部,甚至包括一些你可能从没听说过的运算符。本章只会触及表面:赋值运算符前面已经解释过了;本节则会介绍基本算术运算符、简写算术运算符以及比较运算符。重载流插入与提取运算符同样也很有用。此外,运算符重载还有一些微妙但有趣的用法,可能是你一开始想不到的。标准库大量使用运算符重载。第 15 章 会解释其余运算符该如何以及何时重载。第 16 章 到 第 24 章 则会讲解标准库。
示例:为 SpreadsheetCell 实现加法
Section titled “示例:为 SpreadsheetCell 实现加法”按照真正面向对象的思路,SpreadsheetCell 对象应该能够把自己与另一个 SpreadsheetCell 对象相加。一个单元格与另一个单元格相加,会生成第三个单元格作为结果,而不会修改原先那两个单元格。在 SpreadsheetCell 的语义里,加法表示“把两个单元格中的值相加”。
第一次尝试:add 成员函数
Section titled “第一次尝试:add 成员函数”你可以为 SpreadsheetCell 类声明并定义一个 add() 成员函数,如下:
export class SpreadsheetCell{ public: SpreadsheetCell add(const SpreadsheetCell& cell) const; // Omitted for brevity};这个成员函数把两个单元格相加,返回一个全新的第三个单元格,其值等于前两个单元格值之和。它被声明为 const,并接收一个指向 const SpreadsheetCell 的引用,因为 add() 不会修改任何一个源单元格。实现如下:
SpreadsheetCell SpreadsheetCell::add(const SpreadsheetCell& cell) const{ return SpreadsheetCell { getValue() + cell.getValue() };}你可以这样使用 add():
SpreadsheetCell myCell { 4 }, anotherCell { 5 };SpreadsheetCell aThirdCell { myCell.add(anotherCell) };auto aFourthCell { aThirdCell.add(anotherCell) };这确实可行,但用起来有点笨拙。我们完全可以做得更好。
第二次尝试:把 operator+ 重载成成员函数
Section titled “第二次尝试:把 operator+ 重载成成员函数”如果能像给两个 int 或两个 double 相加那样,直接用加号把两个单元格加起来,显然会方便得多。也就是说,最好能写成这样:
SpreadsheetCell myCell { 4 }, anotherCell { 5 };SpreadsheetCell aThirdCell { myCell + anotherCell };auto aFourthCell { aThirdCell + anotherCell };C++ 允许你为自己的类定义“加号”运算符(也就是加法运算符)的专属版本。做法是编写一个名为 operator+ 的成员函数,如下:
export class SpreadsheetCell{ public: SpreadsheetCell operator+(const SpreadsheetCell& cell) const; // Omitted for brevity};这个重载后的 operator+ 成员函数定义,与前面的 add() 实现完全一致:
SpreadsheetCell SpreadsheetCell::operator+(const SpreadsheetCell& cell) const{ return SpreadsheetCell { getValue() + cell.getValue() };}现在,你就可以像前面展示的那样,用加号把两个单元格相加了。
这种语法需要一点适应时间。别太纠结于 operator+ 这个看起来古怪的成员函数名——它本质上也不过是一个名字,就像 foo 或 add 一样。要理解剩下的语法细节,有助于先弄清楚背后实际发生了什么:当 C++ 编译器解析程序并遇到 +、-、=、<< 这样的运算符时,它会尝试寻找名为 operator+、operator-、operator=、operator<< 的函数或成员函数,并检查它们的参数是否匹配。例如,当编译器看到下面这行代码时,它会尝试在 SpreadsheetCell 类中找到一个名为 operator+、且接受另一个 SpreadsheetCell 作为参数的成员函数(或者,正如本章后面会讲到的,一个接收两个 SpreadsheetCell 参数的全局 operator+ 函数):
SpreadsheetCell aThirdCell { myCell + anotherCell };如果 SpreadsheetCell 类中确实有这样一个 operator+ 成员函数,那么上面那一行就等价于:
SpreadsheetCell aThirdCell { myCell.operator+(anotherCell) };注意,operator+ 并不要求它的参数一定和所属类是同一种类型。你完全可以为 SpreadsheetCell 编写一个 operator+,让它接收一个 Spreadsheet 作为参数去和 SpreadsheetCell 相加。从程序员角度看这毫无意义,但编译器并不会阻止你这样做。下一节就会给出一个例子,展示 SpreadsheetCell 的 operator+ 如何接收 double 值。
还要注意的是,operator+ 的返回类型也没有任何硬性要求。你可以返回任何类型。不过,你应该遵循“最小惊讶原则”(principle of least astonishment),也就是说,operator+ 的返回类型通常应符合使用者的直觉预期。
令人惊讶的是,一旦你写出了前面那个 operator+,不仅可以把两个单元格相加,还可以把一个单元格与 string_view、double 甚至 int 相加! 例如:
SpreadsheetCell myCell { 4 }, aThirdCell;string str { "hello" };aThirdCell = myCell + string_view{ str };aThirdCell = myCell + 5.6;aThirdCell = myCell + 4;这段代码之所以能工作,是因为编译器为了找到一个合适的 operator+,所做的事情不止是“找完全匹配的类型”。它还会尝试看看,能否对参与运算的类型做适当的转换,从而找到一个可用的 operator+。SpreadsheetCell 类里有把 double 或 string_view 转成 SpreadsheetCell 的转换构造函数(见 第 8 章)。在前面的例子中,当编译器看到某个 SpreadsheetCell 试图把自己与 double 相加时,它会找到那个接收 double 的 SpreadsheetCell 构造函数,构造出一个临时 SpreadsheetCell 对象,再把它传给 operator+。同理,当编译器看到要把一个 SpreadsheetCell 与 string_view 相加时,它会调用那个 string_view 版本的 SpreadsheetCell 构造函数,创建一个临时 SpreadsheetCell 再传给 operator+。
不过也要记住,使用隐式转换构造函数可能会有效率问题,因为它会创建临时对象。在这个例子里,如果你想避免为了和 double 相加而进行隐式构造,就可以再写一个专门的 operator+:
SpreadsheetCell SpreadsheetCell::operator+(double rhs) const{ return SpreadsheetCell { getValue() + rhs };}第三次尝试:全局 operator+
Section titled “第三次尝试:全局 operator+”隐式转换让你可以使用 operator+ 成员函数,把 SpreadsheetCell 与 int 或 double 相加。不过,这个运算符并不满足交换律,如下所示:
aThirdCell = myCell + 5.6; // Works fine.aThirdCell = myCell + 4; // Works fine.aThirdCell = 5.6 + myCell; // FAILS TO COMPILE!aThirdCell = 4 + myCell; // FAILS TO COMPILE!当 SpreadsheetCell 在运算符左边时,隐式转换一切正常;但当它出现在右边时,就不行了。加法本应满足交换律,这显然不合理。问题在于,operator+ 成员函数必须在某个 SpreadsheetCell 对象上被调用,而这个对象就必须位于 operator+ 的左边。这就是 C++ 语言规则的定义方式。因此,只靠 operator+ 成员函数,你永远无法让这段代码工作。
不过,如果你把类内的 operator+ 成员函数改写成一个不依附于任何具体对象的全局 operator+ 函数,问题就迎刃而解了。函数如下:
SpreadsheetCell operator+(const SpreadsheetCell& lhs, const SpreadsheetCell& rhs){ return SpreadsheetCell { lhs.getValue() + rhs.getValue() };}你需要在模块接口文件中声明并导出这个运算符:
export class SpreadsheetCell { /* Omitted for brevity */ };
export SpreadsheetCell operator+(const SpreadsheetCell& lhs, const SpreadsheetCell& rhs);现在,前面那四种加法写法就都能按预期工作了。
aThirdCell = myCell + 5.6; // Works fine.aThirdCell = myCell + 4; // Works fine.aThirdCell = 5.6 + myCell; // Works fine.aThirdCell = 4 + myCell; // Works fine.你也许会想:如果我写下面这段代码会怎样?
aThirdCell = 4.5 + 5.5;它确实可以编译运行,但调用的并不是你自己写的那个 operator+。编译器会先对 4.5 与 5.5 做普通的 double 加法,得到如下这条中间语句:
aThirdCell = 10;要让这条赋值语句成立,右侧本来应该是一个 SpreadsheetCell 对象。编译器会发现 SpreadsheetCell 里有一个接收 double 的非 explicit 用户自定义构造函数,于是用它把这个 double 值隐式转换成一个临时 SpreadsheetCell 对象,然后再调用赋值运算符。
重载算术运算符
Section titled “重载算术运算符”既然你已经了解了如何编写 operator+,其余基础算术运算符也就很直接了。下面给出 +、-、* 和 / 的声明,你只需把 % 也可以重载,但对于 SpreadsheetCell 中保存的 double 值而言,这并没有意义。
export class SpreadsheetCell { /* Omitted for brevity */ };
export SpreadsheetCell operator<op>(const SpreadsheetCell& lhs, const SpreadsheetCell& rhs);operator- 和 operator* 的实现都与 operator+ 类似,这里就不再赘述了。对于 operator/,唯一需要特别留意的是别忘了检查除零。这份实现会在检测到除零时抛出异常:
SpreadsheetCell operator/(const SpreadsheetCell& lhs, const SpreadsheetCell& rhs){ if (rhs.getValue() == 0) { throw invalid_argument { "Divide by zero." }; } return SpreadsheetCell { lhs.getValue() / rhs.getValue() };}C++ 并不要求你必须在 operator* 里真的实现乘法,或在 operator/ 里真的实现除法。你完全可以在 operator/ 中写乘法、在 operator+ 中写除法,等等。但那样会让代码极度令人困惑,而且毫无正当理由。只要可能,就应让你所实现的运算符含义与大家熟悉的常规语义保持一致。
重载算术简写运算符
Section titled “重载算术简写运算符”除了基本算术运算符之外,C++ 还提供了 +=、-= 这样的简写运算符。你也许会以为,只要给类写了 operator+,就会自动得到 operator+=。很遗憾,并不会。你必须显式重载这些算术简写运算符。它们与基本算术运算符有两个不同点:第一,它们会修改运算符左侧的对象,而不是创建一个新对象;第二,更细微的一点是,和赋值运算符一样,它们返回的是“对被修改对象的引用”。
算术简写运算符的左侧必须始终是你这个类的对象,因此它们应写成成员函数,而不是全局函数。下面是 SpreadsheetCell 类中的声明:
export class SpreadsheetCell{ public: SpreadsheetCell& operator+=(const SpreadsheetCell& rhs); SpreadsheetCell& operator-=(const SpreadsheetCell& rhs); SpreadsheetCell& operator*=(const SpreadsheetCell& rhs); SpreadsheetCell& operator/=(const SpreadsheetCell& rhs); // Omitted for brevity};下面给出 operator+= 的实现。其他几个运算符完全类似。
SpreadsheetCell& SpreadsheetCell::operator+=(const SpreadsheetCell& rhs){ set(getValue() + rhs.getValue()); return *this;}这些简写算术运算符本质上就是“基础算术运算 + 赋值运算”的组合。有了前面的定义之后,你现在就能写出这样的代码:
SpreadsheetCell myCell { 4 }, aThirdCell { 2 };aThirdCell -= myCell;aThirdCell += 5.4;不过,你仍然不能写下面这种代码(这其实是件好事!):
5.4 += aThirdCell;例如:
SpreadsheetCell operator+(const SpreadsheetCell& lhs, const SpreadsheetCell& rhs){ auto result { lhs }; // Local copy result += rhs; // Forward to +=() return result;}重载比较运算符
Section titled “重载比较运算符”比较运算符 >、<、<=、>=、== 与 != 也是一组非常值得为类定义的运算符。C++20 在这方面带来了不少变化,并引入了三路比较运算符,也就是所谓的“太空船运算符”<=>,它已在 第 1 章 中介绍过。为了更体会 C++20 之后的变化有多大,我们先看看在 C++20 之前你必须做些什么,以及当你的编译器暂时还不支持三路比较运算符时,你仍然需要怎么做。
C++20 之前的比较运算符重载
Section titled “C++20 之前的比较运算符重载”与基础算术运算符一样,C++20 之前的六个比较运算符最好也写成全局函数,这样编译器才能在运算符左右两边都执行隐式转换。这些比较运算符都返回 bool。当然,你也可以改成别的返回类型,但并不推荐。
下面是声明形式。把 ==、<、>、!=、<= 和 >=,就得到六个函数:
class SpreadsheetCell { /* Omitted for brevity */ };
bool operator<op>(const SpreadsheetCell& lhs, const SpreadsheetCell& rhs);下面给出 operator== 的定义。其他几个完全类似。
bool operator==(const SpreadsheetCell& lhs, const SpreadsheetCell& rhs){ return (lhs.getValue() == rhs.getValue());}如果一个类里有更多数据成员,逐个比较所有数据成员就会很痛苦。不过,一旦你实现了 == 和 <,剩下的比较运算符都可以建立在这两个之上。例如,下面是利用 operator< 实现 operator>= 的写法:
bool operator>=(const SpreadsheetCell& lhs, const SpreadsheetCell& rhs){ return !(lhs < rhs);}有了这些运算符之后,你不仅可以比较 SpreadsheetCell 与 SpreadsheetCell,还可以把 SpreadsheetCell 与 double、int 做比较:
if (myCell> aThirdCell || myCell < 10) { cout << myCell.getValue() << endl;}如你所见,仅仅是为了支持这六个比较运算符,你就得写出六个独立的函数——而这还只是用来比较两个 SpreadsheetCell 对象。凭借当前这六个比较函数,之所以也能拿 SpreadsheetCell 与 double 比较,是因为 double 参数会被隐式转换成 SpreadsheetCell。但正如前面讨论过的,这种隐式转换可能有效率问题,因为会创建临时对象。与前文的 operator+ 一样,你也可以通过为 double 单独实现比较函数来避免这点。对于每个运算符
bool operator<op>(const SpreadsheetCell& lhs, const SpreadsheetCell& rhs);bool operator<op>(double lhs, const SpreadsheetCell& rhs);bool operator<op>(const SpreadsheetCell& lhs, double rhs);如果你想支持全部比较运算符,那就意味着要写海量重复代码!
C++20 之后的比较运算符重载
Section titled “C++20 之后的比较运算符重载”现在,让我们切换视角,看看 C++20 及后续标准带来了什么。从 C++20 开始,给类添加比较运算符支持变得简单得多。首先,现在实际上更推荐把 operator== 实现为类的成员函数,而不是全局函数。同时,最好为它加上 [[nodiscard]] 属性,以防比较结果被忽略。示例如下:
[[nodiscard]] bool operator==(const SpreadsheetCell& rhs) const;从 C++20 起,仅仅实现这一个 operator== 重载,就足以让下面这些比较都成立:
if (myCell == 10) { println("myCell == 10"); }if (10 == myCell) { println("10 == myCell"); }像 10 == myCell 这样的表达式,编译器现在会把它重写成 myCell == 10,从而就能调用 operator== 成员函数。另外,只要实现了 operator==,编译器还会自动支持 !=;使用 != 的表达式会被重写为基于 == 的形式。
接下来,若要让类完整支持全部比较运算符,你只需要再实现一个额外的重载:operator<=>。一旦类同时拥有 operator== 和 <=>,编译器就会自动为你提供全部六个比较运算符! 对于 SpreadsheetCell,operator<=> 的声明如下:
[[nodiscard]] std::partial_ordering operator<=>(const SpreadsheetCell& rhs) const;SpreadsheetCell 中存储的值是 double。还记得 第 1 章 说过,浮点类型只具备偏序(partial order),这也正是这个重载返回 std::partial_ordering 的原因。其实现非常直接:
partial_ordering SpreadsheetCell::operator<=>(const SpreadsheetCell& rhs) const{ return getValue() <=> rhs.getValue();}一旦实现了 operator<=>,编译器就会自动支持 >、<、<= 与 >=,方法是把这些表达式重写为基于 <=> 的形式。例如,像 myCell < aThirdCell 这样的表达式,会被自动重写为类似 std::is_lt(myCell <=> aThirdCell) 的形式,其中 is_lt() 是一个具名比较函数;见 第 1 章。
因此,只需实现 operator== 与 operator<=>,SpreadsheetCell 就能支持完整的一套比较运算符:
if (myCell < aThirdCell) { println("myCell < aThirdCell"); }if (aThirdCell < myCell) { println("aThirdCell < myCell"); }
if (myCell <= aThirdCell) { println("myCell <= aThirdCell"); }if (aThirdCell <= myCell) { println("aThirdCell <= myCell"); }
if (myCell> aThirdCell) { println("myCell> aThirdCell"); }if (aThirdCell> myCell) { println("aThirdCell> myCell"); }
if (myCell>= aThirdCell) { println("myCell>= aThirdCell"); }if (aThirdCell>= myCell) { println("aThirdCell>= myCell"); }
if (myCell == aThirdCell) { println("myCell == aThirdCell"); }if (aThirdCell == myCell) { println("aThirdCell == myCell"); }
if (myCell != aThirdCell) { println("myCell != aThirdCell"); }if (aThirdCell != myCell) { println("aThirdCell != myCell"); }由于 SpreadsheetCell 支持从 double 到 SpreadsheetCell 的隐式转换,下面这类比较同样也被支持:
if (myCell < 10) { println("myCell < 10"); }if (10 < myCell) { println("10 < myCell"); }if (10 != myCell) { println("10 != myCell"); }就像比较两个 SpreadsheetCell 对象时一样,编译器会把这类表达式重写成基于 operator== 与 <=> 的形式,并在必要时交换左右参数顺序。例如,10 < myCell 会先被重写成类似 is_lt(10 <=> myCell) 的形式,但这并不能工作,因为我们只把 <=> 实现成了成员函数,这意味着左侧参数必须是 SpreadsheetCell。编译器注意到这一点后,会继续尝试把表达式改写为类似 is_gt(myCell <=> 10) 的形式,这样就能顺利工作。
和前面一样,如果你想避免隐式转换带来的那一点性能损失,也可以专门为 double 提供重载。而从 C++20 开始,这件事的工作量也不大。你只需再添加下面这两个成员函数重载即可:
[[nodiscard]] bool operator==(double rhs) const;[[nodiscard]] std::partial_ordering operator<=>(double rhs) const;它们的实现如下:
bool SpreadsheetCell::operator==(double rhs) const{ return getValue() == rhs;}partial_ordering SpreadsheetCell::operator<=>(double rhs) const{ return getValue() <=> rhs;}编译器生成的比较运算符
Section titled “编译器生成的比较运算符”观察 SpreadsheetCell 中 operator== 与 <=> 的实现会发现,它们做的只是“依次比较所有数据成员”。对于这种情况,C++20(及以后版本)还能让你把代码再进一步精简——它可以直接替你生成这些运算符。就像拷贝构造函数可以显式默认化一样,operator== 与 <=> 也都可以默认化。这样一来,编译器会帮你编写它们,并按照类定义中数据成员的声明顺序逐个比较所有成员,这也称为按成员逐项的词典序比较(member-wise lexicographical comparison)。
另外,如果你只显式默认 operator<=>,编译器还会自动把默认化的 operator== 一并生成出来。因此,对于不包含针对 double 的显式 operator== 与 <=> 重载的那版 SpreadsheetCell(我后面马上会回到这一点),你完全可以只写下面这一行代码,就让 SpreadsheetCell 支持比较两个对象时所需的全部六个比较运算符:
[[nodiscard]] std::partial_ordering operator<=> (const SpreadsheetCell&) const = default;进一步地,你还可以让 operator<=> 的返回类型使用 auto,此时编译器会根据数据成员自身 <=> 运算符的返回类型自动推导返回类型:
[[nodiscard]] auto operator<=>(const SpreadsheetCell&) const = default;如果类中的某些数据成员没有可访问的 operator==,那么这个类的默认化 operator== 就会被隐式删除。
如果类里某些数据成员不支持 operator<=>,那么默认化的 operator<=> 会回退到使用这些成员的 operator< 与 ==。此时,返回类型推导将失效,你必须显式把返回类型写成 strong_ordering、partial_ordering 或 weak_ordering 之一。如果这些数据成员甚至连可访问的 operator< 与 == 都没有,那么默认化的 operator<=> 同样会被隐式删除。
总结一下:若要让编译器为你的类生成默认化的 <=> 运算符,类中的所有数据成员要么都支持 operator<=>(此时返回类型可写为 auto),要么都至少支持 operator< 和 ==(此时返回类型不能写 auto)。由于 SpreadsheetCell 只有一个 double 数据成员,因此编译器会自动推导返回类型为 partial_ordering。
在本节开头我提到,那条“只显式默认一个 operator<=>”的写法适用于“没有针对 double 提供显式 operator== 与 <=> 重载”的 SpreadsheetCell 版本。如果你后来又加上了针对 double 的显式版本,那么你就等于自己声明了一个 operator==(double)。由于有了这个用户声明的 operator==,编译器就不会再自动生成 operator==(const SpreadsheetCell&) 了,于是你必须显式再默认一个,如下:
export class SpreadsheetCell{ public: // Omitted for brevity [[nodiscard]] auto operator<=>(const SpreadsheetCell&) const = default; [[nodiscard]] bool operator==(const SpreadsheetCell&) const = default;
[[nodiscard]] bool operator==(double rhs) const; [[nodiscard]] std::partial_ordering operator<=>(double rhs) const; // Omitted for brevity};如果你的类允许显式默认 operator<=>,我建议你优先这么做,而不是手写实现。让编译器替你生成,它就会随着新增或修改的数据成员自动保持同步。如果由你自己实现,那么每次添加新成员或修改现有成员时,都必须记得更新 operator<=> 的实现。同样地,若 operator== 不能被编译器自动生成,你也得自己记得同步更新。
只有当 operator== 与 <=> 的参数是“对当前类类型的 const 引用”时,它们才能被显式默认化。例如,下面这种写法是无效的:
[[nodiscard]] auto operator<=>(double) const = default; // Does not work!构建稳定接口
Section titled “构建稳定接口”现在你已经理解了在 C++ 中编写类所需的各种语法细节,是时候回头再看看 第 5 章“用类进行设计”和 第 6 章“为复用而设计”中讨论过的设计原则了。类是 C++ 中最主要的抽象单元。你应当把抽象原则应用到类上,尽可能把接口与实现分离开来。具体来说,你应该把所有数据成员都设为 private,并根据需要提供 getter 与 setter 成员函数。这正是 SpreadsheetCell 类的实现方式:m_value 是 private,而 public 的 set() 成员函数负责设置值,public 的 getValue() 与 getString() 则负责读取值。
使用接口类与实现类
Section titled “使用接口类与实现类”即便你遵循了前面的做法以及最好的设计原则,C++ 语言在本质上仍然不太友好于抽象原则。它的语法要求你把 public 接口与 private(或 protected) 数据成员和成员函数放在同一个类定义里,从而不可避免地把类的一部分内部实现细节暴露给客户端。其缺点在于:一旦你需要给类增加新的非 public 成员函数或数据成员,所有用到该类的客户端代码都必须重新编译。在大型项目中,这可能会成为一种负担。
好消息是:你完全可以把接口做得干净得多,把所有实现细节都隐藏起来,从而获得稳定接口。坏消息是:这需要多写一点代码。基本原则是,对于你想编写的每个类,都定义两个类:接口类(interface class) 与 实现类(implementation class)。实现类与“如果不采用这种做法时你本来会写出的那个类”完全一样。接口类则只暴露与实现类相同的 public 成员函数,但它自己只有一个数据成员:一个指向实现类对象的指针。这种方式被称为 pimpl idiom、private implementation idiom 或 bridge pattern。接口类的成员函数实现只是简单地把调用转发给实现类对象上的对应成员函数。最终效果是:无论实现细节如何变化,只要 public 接口类不变,客户端就不受影响。这能显著减少重新编译的需要。只使用接口类的客户端,在实现细节发生变化时无需重新编译。注意,这种惯用法只有在那个唯一的数据成员是“指向实现类的指针”时才成立。如果它是一个按值存储的实现类成员,那么一旦实现类定义发生变化,客户端仍然必须重新编译。
要把这种思路应用到 Spreadsheet 类上,先定义如下 public 接口类,名字仍然叫 Spreadsheet。关键部分如下所示:
export module spreadsheet;
export import spreadsheet_cell;import std;
export class Spreadsheet{ public: explicit Spreadsheet( std::size_t width = MaxWidth, std::size_t height = MaxHeight); Spreadsheet(const Spreadsheet& src); Spreadsheet(Spreadsheet&&) noexcept; ˜Spreadsheet();
Spreadsheet& operator=(const Spreadsheet& rhs); Spreadsheet& operator=(Spreadsheet&&) noexcept;
void setCellAt(std::size_t x, std::size_t y, const SpreadsheetCell& cell); SpreadsheetCell& getCellAt(std::size_t x, std::size_t y); const SpreadsheetCell& getCellAt(std::size_t x, std::size_t y) const;
std::size_t getId() const;
static constexpr std::size_t MaxHeight { 100 }; static constexpr std::size_t MaxWidth { 100 };
void swap(Spreadsheet& other) noexcept;
private: class Impl; std::unique_ptr<Impl> m_impl;};export void swap(Spreadsheet& first, Spreadsheet& second) noexcept;实现类 Impl 是一个 private 的嵌套类,因为除了 Spreadsheet 本身之外,不需要让任何其他人知道这个实现类的存在。现在 Spreadsheet 类只包含一个数据成员:指向 Impl 实例的指针。而它的 public 成员函数与旧版 Spreadsheet 完全相同。
嵌套类 Spreadsheet::Impl 会定义在 spreadsheet 模块实现文件中。它应该对客户端隐藏,因此不会被导出。Spreadsheet.cpp 模块实现文件可以像下面这样开头:
module spreadsheet;import std;using namespace std;
// Spreadsheet::Impl class definition.class Spreadsheet::Impl{ public: Impl(size_t width, size_t height); // Remainder omitted for brevity.};这个 Impl 类的接口几乎与原始 Spreadsheet 类相同。完整定义可在可下载源码中找到。至于成员函数实现,你需要记住 Impl 是一个嵌套类,因此作用域必须写成 Spreadsheet::Impl。所以,构造函数会变成 Spreadsheet::Impl::Impl(…):
// Spreadsheet::Impl member function definitions.Spreadsheet::Impl::Impl(size_t width, size_t height) : m_id { ms_counter++ } , m_width { min(width, Spreadsheet::MaxWidth) } , m_height { min(height, Spreadsheet::MaxHeight) }{ m_cells = new SpreadsheetCell*[m_width]; for (size_t i { 0 }; i < m_width; ++i) { m_cells[i] = new SpreadsheetCell[m_height]; }}// Other member function definitions omitted for brevity.现在 Spreadsheet 类通过 unique_ptr 持有一个 Impl 实例,因此 Spreadsheet 类必须显式声明析构函数。由于我们在这个析构函数里无需手动做任何事情,它可以在实现文件中按如下方式默认化:
Spreadsheet::˜Spreadsheet() = default;事实上,它必须在实现文件中默认化,而不能直接在类定义里默认。原因在于,在 Spreadsheet 类定义中,Impl 只是被前向声明了;也就是说,编译器知道未来某处会有一个 Spreadsheet::Impl 类,但此时还不知道它的完整定义。因此,你不能在类定义里直接默认析构函数,否则编译器会试图使用那个尚未定义出来的 Impl 类的析构函数。对于本场景中的其他默认化成员函数,例如移动构造函数和移动赋值运算符,同样也有这个限制。
Spreadsheet 的成员函数实现,例如 setCellAt() 和 getCellAt(),只需把请求转发给底层 Impl 对象:
void Spreadsheet::setCellAt(size_t x, size_t y, const SpreadsheetCell& cell){ m_impl->setCellAt(x, y, cell);}
const SpreadsheetCell& Spreadsheet::getCellAt(size_t x, size_t y) const{ return m_impl->getCellAt(x, y);}
SpreadsheetCell& Spreadsheet::getCellAt(size_t x, size_t y){ return m_impl->getCellAt(x, y);}Spreadsheet 的构造函数则必须创建一个新的 Impl 来完成真正的工作:
Spreadsheet::Spreadsheet(size_t width, size_t height){ : m_impl { make_unique<Impl>(width, height) }}}
Spreadsheet::Spreadsheet(const Spreadsheet& src) : m_impl { make_unique<Impl>(*src.m_impl) }{}这个拷贝构造函数看起来有点奇怪,因为它需要把源 Spreadsheet 底层的 Impl 拷贝出来。拷贝构造函数接受的是对 Impl 的引用,而不是指针,因此你必须先解引用 m_impl 指针,才能拿到那个对象本身。
类似地,Spreadsheet 的赋值运算符也必须把赋值操作转发给底层 Impl:
Spreadsheet& Spreadsheet::operator=(const Spreadsheet& rhs){ *m_impl = *rhs.m_impl; return *this;}赋值运算符里的第一行看起来也有点怪。Spreadsheet 的赋值运算符需要把调用转发给 Impl 的赋值运算符,而后者只会在你对实际对象赋值时运行。通过解引用 m_impl 指针,你强制进行了“直接对象赋值”,于是 Impl 的赋值运算符就会被调用。
swap() 成员函数则只需要交换这唯一一个数据成员:
void Spreadsheet::swap(Spreadsheet& other) noexcept{ std::swap(m_impl, other.m_impl);}这种真正把接口和实现分离开的技术非常强大。虽然刚开始用起来会有点笨拙,但一旦习惯之后,你会觉得这种工作方式相当自然。不过,在大多数实际工作环境中,它并不是特别常见的做法,因此你可能会遭遇同事对其抵触。支持这种做法最有说服力的理由,并不是“接口看起来更漂亮”这种审美上的原因,而是它能显著加快实现变化后的构建速度。当一个类没有使用 pimpl 惯用法时,它实现细节上的改动可能会触发漫长的整项目重编译。例如,给类定义增加一个新的数据成员,就会导致所有使用该类定义的源文件重新构建。而在使用 pimpl 惯用法时,你可以随意修改实现类定义;只要公共接口类保持不变,就不会触发那种大规模重编译。
与把实现和接口彻底拆开相比,另一种办法是使用抽象接口——也就是只包含纯虚成员函数的接口——然后再让某个实现类去实现这个接口。这个主题会在下一章讲解。
本章连同 第 8 章,一起为你提供了编写扎实、设计良好的类,以及有效使用对象所需的全部工具。
你已经了解到,对象中的动态内存分配会带来新的挑战:你需要实现析构函数、拷贝构造函数、拷贝赋值运算符、移动构造函数和移动赋值运算符,以便正确地拷贝、移动和释放内存。你也学会了如何通过显式删除拷贝构造函数和赋值运算符,来阻止按值传递和赋值。你还了解了用来实现拷贝赋值运算符的 copy-and-swap 惯用法、用来实现移动赋值运算符的 move-and-swap 惯用法,以及零法则。
你还进一步认识了不同类型的数据成员,包括 static、const、“引用到 const”以及 mutable 成员。你也学到了 static、inline 与 const 成员函数、成员函数重载以及默认参数的更多细节。本章还介绍了嵌套类定义,以及 friend 类、函数和成员函数。
你接触了运算符重载,并学会了如何以全局函数或类成员函数的形式重载算术运算符与比较运算符。你还发现,三路比较运算符让为类添加比较支持这件事变得容易了太多。
最后,你学到了如何把抽象推向极致:通过分离的接口类与实现类来构建稳定接口。
既然你已经熟练掌握面向对象编程的语言,下一步就该进入继承了,它会在接下来的 第 10 章“理解继承技术”中展开。
通过完成下面这些练习,你可以巩固本章讨论的内容。所有练习的参考解答都包含在本书网站 www.wiley.com/go/proc++6e 的代码下载包中。不过,如果你在某道题上卡住了,请先回过头来重读本章的相关部分,尝试自己找出答案,再去查看网站上的解答。
- 练习 9-1: 取你在练习 8-3 中实现的
Person类,把其中字符串参数的传递方式改造成你能想到的最优方式。另外,为它添加移动构造函数和移动赋值运算符,并在这两个成员函数中向控制台输出消息,以便观察它们何时被调用。请实现为支持这些移动成员函数所需的其他成员函数,并顺便改进练习 8-3 中其他成员函数的实现,避免重复代码。最后修改main(),测试这些成员函数。 - 练习 9-2: 以练习 8-4 中的
Person类为基础。和练习 9-1 一样,先把字符串参数传递方式优化到尽可能好。然后为Person添加完整的六个比较运算符支持,用于比较两个Person对象。尽量用尽可能少的代码完成这一支持。随后在main()中执行各种比较来测试你的实现。Person的排序依据是什么? 是按名字、按姓氏,还是两者组合? - 练习 9-3: 在 C++20 之前,支持全部六个比较运算符需要多写不少代码。以练习 9-2 的
Person类为起点,去掉operator<=>,并添加必要代码,在不使用<=>的前提下支持两个Person对象之间的全部比较运算符。完成与练习 9-2 相同的一组测试。 - 练习 9-4: 本练习用于实践稳定接口。取你在练习 8-4 中写的
Person类,把它拆分成一个稳定的公共接口类和一个独立的实现类。 - 练习 9-5: 以你在练习 9-2 中的解答为起点,优化
getFirstName()、getLastName()和getInitials()这几个成员函数,使它们在对右值调用时也能高效工作。