使用字符串与字符串视图
你写的每一个程序都会在某种程度上使用字符串。对于老式 C 语言来说,除了使用以空字符结尾的笨拙字符数组来表示字符串之外,几乎没有别的选择。不幸的是,这种做法会带来很多问题,例如缓冲区溢出,而这又可能演变成安全漏洞。C++ 标准库则提供了一个安全且易用的 std::string 类,它没有这些缺点。
正因为字符串如此重要,本书在靠前的位置就专门用一章来更详细地讨论它们。
在那些把字符串作为一等对象(first-class objects) 支持的语言中,字符串通常都拥有许多很吸引人的特性,例如可以扩展到任意大小,或者可以提取和替换子串。在另一些语言中,例如 C,字符串更像是一个事后补丁:并不存在真正优秀的字符串数据类型,只有固定大小的字节数组。C 字符串库也不过是一堆相当原始的函数集合,甚至连边界检查都没有。C++ 则把字符串作为一种一等数据类型正式提供出来。在讨论 C++ 对字符串提供了什么之前,我们先快速看一眼 C 风格字符串。
C 风格字符串
Section titled “C 风格字符串”在 C 语言中,字符串被表示成字符数组。字符串的最后一个字符是一个空字符(\0),这样对字符串进行操作的代码才能知道它在哪里结束。这个空字符的正式名字是 NUL,只有一个 L,不是两个。NUL 和 NULL 指针并不是一回事。即便 C++ 提供了更好的字符串抽象,理解 C 处理字符串的方式依然很重要,因为它在 C++ 编程中仍然会出现。最常见的情形之一,就是某个 C++ 程序需要调用第三方库或操作系统接口中基于 C 的 API。
到目前为止,程序员在使用 C 字符串时最常犯的错误,就是忘记给 \0 字符预留空间。例如,字符串 "hello" 看起来只有五个字符,但在内存中保存它实际上需要六个字符的空间,如 图 2.1 所示。
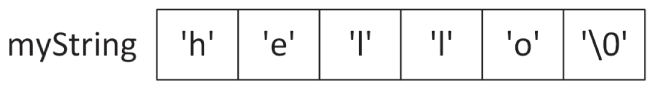
[^图 2.1]
C++ 继承了若干来自 C 语言的字符串处理函数,这些函数定义在 <cstring> 中。一般经验法则是:这些函数并不会替你处理内存分配。例如,strcpy() 函数接收两个字符串作为参数。它会把第二个字符串复制到第一个字符串中——无论能不能放得下。下面这段代码试图给 strcpy() 写一个包装函数:它自己分配正确大小的内存,并返回复制结果,而不是要求调用方事先传入一块已经分配好的字符串缓冲区。注意,下面这个最初版本其实是错的! 它用 strlen() 函数获取字符串长度。调用方要负责释放 copyString() 分配出来的内存。
char* copyString(const char* str){ char* result { new char[strlen(str)] }; // BUG!差一错误(Off by one)! strcpy(result, str); return result;}按现在这种写法,copyString() 函数是错误的。strlen() 返回的是“字符串长度”,而不是“容纳它所需的内存大小”。对于字符串 "hello",strlen() 返回的是 5,而不是 6。为字符串分配内存的正确方式,是为实际字符数额外再加 1,以容纳结尾的 \0。到处都写 +1 看起来很别扭,但现实就是如此,所以在你处理 C 风格字符串时一定要记住这一点。正确实现如下:
char* copyString(const char* str){ char* result { new char[strlen(str) + 1] }; strcpy(result, str); return result;}记住 strlen() 只返回“字符串中真正字符的个数”的一个方法,是想想如果你要为“由多个字符串拼起来的新字符串”分配空间会怎样。例如,假设你的函数接收三个字符串,并返回一个把它们串接起来的新字符串,那么它该有多大? 要刚好容纳下它,所需空间应当是三个字符串长度相加,再加 1 个字符的位置给结尾的 \0。如果 strlen() 把 \0 也算进长度,那最终分配出来的内存就会偏大。下面这段代码使用 strcpy() 和 strcat() 来完成这个操作。strcat() 里的 cat 是 concatenate(连接) 的意思。
char* appendStrings(const char* str1, const char* str2, const char* str3){ char* result { new char[strlen(str1) + strlen(str2) + strlen(str3) + 1] }; strcpy(result, str1); strcat(result, str2); strcat(result, str3); return result;}在 C 和 C++ 中,sizeof() 运算符可以用来获取某个数据类型或变量所占的大小。例如,sizeof(char) 返回 1,因为一个 char 占 1 字节。不过在 C 风格字符串的语境里,sizeof() 与 strlen() 并不一样。你绝不应该用 sizeof() 去尝试获取字符串长度。它返回的结果会取决于 C 风格字符串是怎样被存储的。如果它以 char[] 形式存储,那么 sizeof() 返回的是该字符串实际占用的内存大小,包括 \0 在内,如下例所示:
char text1[] { "abcdef" };size_t s1 { sizeof(text1) }; // 结果为 7size_t s2 { strlen(text1) }; // 结果为 6但如果 C 风格字符串被保存为 char*,那么 sizeof() 返回的就是“一个指针的大小”!
const char* text2 { "abcdef" };size_t s3 { sizeof(text2) }; // 取决于平台size_t s4 { strlen(text2) }; // 结果为 6这里的 s3 在 32 位模式下会是 4,在 64 位模式下会是 8,因为它返回的是 const char* 的大小,也就是一个指针本身的大小。
有关 C 风格字符串的完整函数列表,可查阅 <cstring> 头文件。
当你在 Microsoft Visual Studio 中使用这些 C 风格字符串函数时,编译器很可能会给出与安全性相关的警告,甚至错误,认为这些函数已经不推荐使用。你可以改用 strcpy_s()、strcat_s() 等其他 C 标准库函数来消除这些警告,它们属于“安全 C 库”标准(ISO/IEC TR 24731) 的一部分。不过,最佳解决方案仍然是切换到后面马上要讨论的 C++ std::string 类。但在进入 “C++ std::string 类” 那节之前,我们还得先多看一点字符串字面量相关内容。
字符串字面量
Section titled “字符串字面量”你大概已经见过 C++ 程序中用双引号包起来的字符串。例如,下面这段代码会直接输出字符串 hello,它在代码中写的就是这个字面量本身,而不是某个保存了它的变量:
println("hello");在上面这一行里,"hello" 是一个字符串字面量(string literal),因为它是作为值写出来的,而不是某个变量。字符串字面量实际上会被存储在内存中的只读区域。这使得编译器能够通过复用相同内容的字符串字面量来优化内存使用。也就是说,即使程序里用了 500 次字符串字面量 "hello",编译器也完全可以只在内存中保留一份 hello 实例,让所有引用都共享它。这被称为字面量池化(literal pooling)。
字符串字面量可以被赋给变量,但由于它们位于只读内存中,再加上字面量池化的存在,把它们赋给变量实际上是有风险的。C++ 标准正式规定:字符串字面量的类型是“由 n 个 const char 构成的数组”;不过,为了与旧的、不理解 const 的代码兼容,某些编译器并不会强制你把字符串字面量赋给 const char* 类型的变量。它们允许你把字符串字面量赋给一个不带 const 的 char*,而程序通常也能正常运行——直到你试图去修改这个字符串为止。一般来说,修改字符串字面量的行为是未定义的。它可能崩溃,也可能继续运行但带来莫名其妙的副作用,也可能静默忽略你的修改,甚至也可能“看上去就这么成功了”;这完全取决于编译器。例如,下面的代码就表现出未定义行为:
char* ptr { "hello" }; // 将字符串字面量赋给变量。ptr[1] = 'a'; // 未定义行为!一种安全得多的写法,是在引用字符串字面量时使用“指向 const 字符的指针”。下面这段代码里仍然存在同样的 bug,但因为它把字面量赋给了 const char*,所以编译器会直接拦住你试图写入只读内存的行为:
const char* ptr { "hello" }; // 将字符串字面量赋给变量。ptr[1] = 'a'; // 错误!尝试写入只读内存你还可以把字符串字面量作为字符数组(char[]) 的初值来使用。在这种情况下,编译器会创建一个足够容纳该字符串的数组,并把字面量内容拷贝进去。编译器不会把这个字面量放在只读内存中,也不会进行字面量池化。
char arr[] { "hello" }; // 编译器负责创建合适大小的 // 字符数组 arr。arr[1] = 'a'; // 内容可以被修改。原始字符串字面量
Section titled “原始字符串字面量”原始字符串字面量(raw string literals) 是一种字符串字面量,它可以跨越多行代码,不需要对内部双引号做转义,并且会把 \t、\n 这类转义序列当成普通文本处理,而不是当成真正的转义。转义序列会在 第 1 章“C++ 与标准库速成”中讲解。例如,如果你用普通字符串字面量写下面这句代码,编译器会报错,因为字符串内部包含了未经转义的双引号:
println("Hello "World"!"); // Error!通常你必须像这样对双引号进行转义:
println("Hello \"World\"!");而使用原始字符串字面量时,你就可以避免这种转义。原始字符串字面量以 R"( 开头,以 )" 结尾:
println(R"(Hello "World"!)");如果你需要一个由多行组成的字符串,在没有原始字符串字面量时,通常得在想要换行的地方手工嵌入 \n 转义序列。例如:
println("Line 1\nLine 2");输出如下:
Line 1Line 2而使用原始字符串字面量时,你无需再写 \n,直接在源代码中敲下回车,写成真正的物理换行即可。下面这段代码的输出与前一个嵌入 \n 的示例完全相同:
println(R"(Line 1Line 2)");在原始字符串字面量中,转义序列会被忽略。例如,在下面这个原始字符串字面量中,\t 不会被替换成一个制表符,而是会保留为“反斜杠 + 字母 t”这两个字符本身:
println(R"(Is the following a tab character? \t)");它会输出如下内容:
Is the following a tab character? \t由于原始字符串字面量是以 )" 作为结束标记的,因此你不能在这种基础语法中直接嵌入 )" 这段字符序列。例如,下面这段字符串就是非法的,因为它在字符串中间包含了 )":
println(R"(Embedded )" characters)"); // Error!如果你确实需要嵌入 )",那就要使用扩展版原始字符串字面量语法,其形式如下:
R"d-char-sequence(r-char-sequence)d-char-sequence"其中 r-char-sequence 才是真正的原始字符串内容。d-char-sequence 是可选的分隔符序列,并且它必须在原始字符串字面量开头和结尾处保持完全一致。这个分隔符序列最长不能超过 16 个字符。你应选择一段“不会出现在你的原始字符串正文中”的分隔符。
前面那个例子就可以借助一个独特分隔符改写为:
println(R"-(Embedded )" characters)-");原始字符串字面量非常适合处理数据库查询字符串、正则表达式、文件路径等等。正则表达式会在 第 21 章“字符串本地化与正则表达式”中讨论。
C++ std::string 类
Section titled “C++ std::string 类”C++ 作为标准库的一部分,提供了对“字符串”这一概念的大幅改进实现。在 C++ 中,std::string 是一个类(严格来说,它是 std::basic_string 类模板的一个实例化结果),它支持许多与 <cstring> 中函数相同的功能,但会替你处理内存分配。string 类定义在 <string> 中,位于 std 命名空间里。它在上一章中已经被简要介绍过,现在是时候更仔细地看看它了。
C 风格字符串到底有什么问题?
Section titled “C 风格字符串到底有什么问题?”要理解为什么需要 C++ 的 string 类,最好的办法就是先看一看 C 风格字符串的优缺点。
优点:
- 它们很简单,直接利用了底层最基础的字符类型和数组结构。
- 如果使用得当,它们很轻量,只占用自己真正需要的那部分内存。
- 它们非常底层,因此你可以很容易把它们当作原始内存来操作和复制。
- 如果你本来就是 C 程序员——那何必去学新东西?
缺点:
- 若想把它们模拟成“一等字符串数据类型”,你需要付出惊人的额外努力。
- 它们极其不宽容,并且非常容易引入难以定位的内存 bug。
- 它们没有利用 C++ 的面向对象特性。
- 它们要求程序员了解其底层表示方式。
上面这两张优缺点清单是刻意组织过的,目的是让你意识到:也许真的存在一种更好的方法。正如你接下来会看到的,C++ string 几乎解决了 C 风格字符串的所有问题,让“C 字符串相较于一等数据类型的优势”这种论点在大多数场景下都不再成立。
使用 std::string 类
Section titled “使用 std::string 类”尽管 string 是一个类,但在绝大多数情况下,你几乎可以像对待内建类型那样来使用它。事实上,你越是把它这么看待,通常就越容易写出自然的代码。借助运算符重载(operator overloading) 的魔法,C++ string 比 C 风格字符串好用得多。接下来的两个小节会先通过“拼接字符串”和“比较字符串”两个例子,展示运算符重载是如何让 string 使用起来非常轻松的。之后的各节还会继续讨论 C++ string 如何处理内存、它与 C 风格字符串的兼容方式,以及你可以在 string 上执行的一些内建操作。
对 string 来说,+ 运算符被重新定义为“字符串拼接”之意。下面这段代码会得到 1234:
string a { "12" };string b { "34" };string c { a + b }; // c 为 "1234"+= 运算符同样也被重载了,这样你就能方便地把一个字符串追加到另一个字符串之后:
a += b; // a 为 "1234"C 风格字符串的另一个麻烦在于,你不能直接用 == 去比较它们。假设你有下面两个字符串:
char* a { "12" };char b[] { "12" };像下面这样写比较,结果永远都是 false,因为它比较的是指针值,而不是字符串内容:
if (a == b) { /* … */ }需要注意的是,C 数组和指针有密切关系。你可以把这里示例中的数组 b 理解成“指向数组首元素的指针”。第 7 章“内存管理”会更深入讨论数组-指针二重性(array-pointer duality)。
要比较 C 字符串,你不得不写出下面这样的代码:
if (strcmp(a, b) == 0) { /* … */ }除此之外,你也无法使用 <、<=、>= 或 > 来比较 C 字符串,因此 strcmp() 还承担着“三路比较”的职责——根据字符串的字典序关系,返回一个小于 0、等于 0 或大于 0 的值。这就导致代码既笨拙、又难读,而且很容易出错。
而对于 C++ string,比较运算符(==、!=、< 等) 都已被重载,会基于字符串的实际字符内容进行比较。例如:
string a { "Hello" };string b { "World" };println("'{}' < '{}' = {}", a, b, a < b); // 'Hello' < 'World' = trueprintln("'{}' > '{}' = {}", a, b, a > b); // 'Hello' > 'World' = falseC++ string 类还额外提供了一个 compare() 成员函数,它的行为类似于 strcmp(),返回类型也相似。如下所示:
string a { "12" };string b { "34" };
auto result { a.compare(b) };if (result < 0) { println("更小"); }if (result > 0) { println("更大"); }if (result == 0) { println("相等"); }和 strcmp() 一样,这种写法使用起来也相当繁琐。你必须记住这个返回值到底意味着什么。而且,由于返回值只是一个整数,你也很容易忘记它的含义,从而写出下面这种错误代码来判断相等:
if (a.compare(b)) { println("相等"); }compare() 在“相等”时返回 0,在“不相等”时返回其他值。所以这行代码实际上做的恰好和作者本意相反——也就是说,它会在两个字符串不相等时输出 “相等”! 如果你只是想判断两个 string 是否相等,就不要用 compare(),直接用 ==。
从 C++20 开始,随着三路比较运算符(第 1 章中已经介绍过)的加入,这方面体验又有提升。string 类对这个运算符提供了完整支持。例如:
auto result { a <=> b };if (is_gt(result)) { println("更大"); }if (is_lt(result)) { println("更小"); }if (is_eq(result)) { println("相等"); }正如下面这段代码所示,一旦某个 string 操作需要扩展字符串内容,内存需求就会由 string 类自动处理,因此“内存越界”也就成了过去式。这段代码还顺便展示了:和 C 风格字符串一样,单个字符也可以通过方括号运算符 [] 来访问。
string myString { "hello" };myString += ", there";string myOtherString { myString };if (myString == myOtherString) { myOtherString[0] = 'H';}println("{}", myString);println("{}", myOtherString);输出如下:
hello, thereHello, there这个例子里有几点值得注意。其一,即便字符串在几个地方经历了分配和扩容,也没有出现内存泄漏。所有这些 string 对象都是作为栈变量创建的。虽然 string 类内部当然会完成一堆分配与扩容工作,但当 string 对象离开作用域时,它们的析构函数会自动把这些内存清理掉。析构函数到底如何工作,会在 第 8 章“熟悉类和对象”中详细解释。
另一个值得注意的点是,这些运算符的行为完全符合你的预期。例如,= 运算符会复制字符串,而这显然正是你大多数时候想要的行为。如果你以前习惯了基于数组的字符串,这要么会让你觉得“终于解放了”,要么一开始会让你有点不适应。别担心——一旦你学会信任 string 类会替你做对的事,生活就会轻松得多。
与 C 风格字符串的兼容性
Section titled “与 C 风格字符串的兼容性”为了兼容性,你可以在某个 string 上调用 c_str() 成员函数,从而得到一个表示 C 风格字符串的 const char 指针。不过,只要这个 string 发生了任何内存重分配,或者这个 string 对象被销毁,这个返回的 const 指针就会失效。因此,你应当在真正使用它之前再调用该成员函数,确保它反映的是字符串当前最新内容;并且绝对不要从函数中返回某个栈上 string 对象的 c_str() 结果。
另外还有一个 data() 成员函数,在 C++14 及以前,它和 c_str() 一样始终返回 const char*。但从 C++17 开始,当你在一个非 const 字符串对象上调用 data() 时,它会返回 char*。
对字符串的操作
Section titled “对字符串的操作”string 类还支持不少额外操作。下面这个列表重点列举其中几个。想了解完整支持列表,请查阅标准库参考资料(见 附录 B“带注释的参考书目”)。
substr(pos, len): 返回从给定位置开始、具有给定长度的子串find(str): 返回某个给定子串首次出现的位置;若未找到则返回string::nposreplace(pos, len, str): 用另一个字符串替换当前字符串中由位置和长度指定的一部分starts_with(str)/ends_with(str): 若字符串以某个给定子串开始/结束,则返回truecontains(str)/contains(ch): 若string中包含另一个string或字符,则返回true
下面是一段小代码,展示其中一些操作如何工作:
string strHello { "Hello!!" };string strWorld { "The World…" };auto position { strHello.find("!!") };if (position != string::npos) { // 找到了 "!!" 子串, 现在替换它。 strHello.replace(position, 2, strWorld.substr(3, 6));}println("{}", strHello);// 测试 contains()。string toFind { "World" };println(”{}”, strWorld.contains(toFind)); println(”{}”, strWorld.contains(’.’)); println(”{}”, strWorld.contains(“Hello”));
输出如下:Hello World true true false
<cpp23></cpp23> 在 C++23 之前,你可以把 `nullptr` 传给 `string` 的构造函数,从而构造出一个 `string` 对象。不过这样会在运行时导致未定义行为。从 C++23 开始,试图用 `nullptr` 构造 `string` 会直接变成编译错误。
#### `std::string` 字面量
源代码中的字符串字面量通常会被解释为 `const char*` 或 `const char[]`。如果你想把某个字符串字面量直接解释成 `std::string`,就可以使用标准字面量后缀 `s`。
```cppauto string1 { "Hello World" }; // string1 是 const char*。auto& string2 { "Hello World" }; // string2 是 const char[12]。auto string3 { "Hello World"s }; // string3 是 std::string。标准字面量 s 定义在 std::literals::string_literals 命名空间中。不过,string_literals 和 literals 这两个命名空间都是内联命名空间(inline namespaces)。因此,你可以通过以下几种方式让这些字符串字面量在代码中可用:
using namespace std;using namespace std::literals;using namespace std::string_literals;using namespace std::literals::string_literals;基本上,凡是声明在某个内联命名空间中的内容,都会自动出现在其父命名空间中。如果你要自己定义一个内联命名空间,则需要使用 inline 关键字。例如,string_literals 这个内联命名空间是这样定义的:
namespace std { inline namespace literals { inline namespace string_literals { // … } }}在 std::vector 和字符串上使用 CTAD
Section titled “在 std::vector 和字符串上使用 CTAD”第 1 章 已经解释过,std::vector 支持类模板实参推导(CTAD),允许编译器根据初始化列表自动推导 vector 的元素类型。当你把 CTAD 用在字符串向量时,一定要小心。例如,看看下面这个 vector 声明:
vector names { "John", "Sam", "Joe" };这里推导出的类型会是 vector<const char*>,而不是 vector<string>! 这是一个非常容易犯的错误,而且会在你后续继续操作这个 vector 时造成各种奇怪行为,甚至直接导致崩溃。
如果你真正想要的是 vector<string>,那就应该像上一节那样使用 std::string 字面量。注意下面这个例子里,每个字符串字面量后面都加了 s:
vector names { "John"s, "Sam"s, "Joe"s };C++ 标准库同时提供了高层与底层两套数值转换函数,下面几节会分别介绍它们。
高层数值转换
Section titled “高层数值转换”std 命名空间中定义了一组帮助函数(位于 <string> 中),可以很方便地把数值转换成 string,或者把 string 转回数值。
下面这组函数可以把数值转换成 string,其中 T 可以是(无符号) int、(无符号) long、(无符号) long long、float、double 或 long double。所有这些函数都会创建并返回一个新的 string 对象,同时自动处理所需的所有内存分配。
string to_string(T val);这些函数使用起来非常直观。例如,下面这段代码就会把一个 long double 值转换成 string:
long double d { 3.14L };string s { to_string(d) }; // s 包含 3.140000从字符串转回数值
Section titled “从字符串转回数值”反方向的转换则由下面这组函数完成,它们同样定义在 std 命名空间中。在这些原型里,str 是你想转换的字符串,pos 是一个指针,用来接收“第一个未转换字符”的索引位置,base 则表示转换时应使用的数学进制。pos 可以是 nullptr,此时就会被忽略。这些函数会忽略前导空白字符;如果无法完成任何转换,则抛出 invalid_argument;如果转换后的值超出了返回类型的范围,则抛出 out_of_range。
int stoi(const string& str, size_t *pos = nullptr, int base = 10);long stol(const string& str, size_t *pos = nullptr, int base = 10);unsigned long stoul(const string& str, size_t *pos = nullptr, int base = 10);long long stoll(const string& str, size_t *pos = nullptr, int base = 10);unsigned long long stoull(const string& str, size_t *pos = nullptr, int base = 10);float stof(const string& str, size_t *pos = nullptr);double stod(const string& str, size_t *pos = nullptr);long double stold(const string& str, size_t *pos = nullptr);下面是一个例子:
const string toParse { " 123USD" };size_t index { 0 };int value { stoi(toParse, &index) };println("解析出的值: {}", value);println("第一个未解析字符: '{}'", toParse[index]);输出如下:
Parsed value: 123First non-parsed character: 'U'stoi()、stol()、stoul()、stoll() 和 stoull() 都用于处理整数值,并且带有一个叫 base 的参数,用来指明字符串里整数值所使用的进制。默认值 10 表示通常的十进制数字 0–9,而 16 则表示十六进制。如果 base 被设为 0,函数会自动按以下规则推断进制:
- 如果数字以
0x或0X开头,则按十六进制解析。 - 如果数字以
0开头,则按八进制解析。 - 否则,按十进制解析。
底层数值转换
Section titled “底层数值转换”标准库还提供了一组更底层的数值转换函数,都定义在 <charconv> 中。这些函数不会进行任何内存分配,也不会直接作用于 std::string,而是使用由调用方提供的原始缓冲区。此外,它们针对高性能进行了专门优化,同时与 locale 无关(关于 locale 的细节见 第 21 章)。最终效果是:这些函数相比其他高层数值转换函数,在速度上往往可以快出好几个数量级。它们还被设计成支持完美往返转换(perfect round-tripping),也就是说,如果你先把一个数值序列化成字符串表示,再把这个字符串反序列化回数值,得到的结果会与原值完全一致。
如果你需要高性能、支持完美往返、并且与 locale 无关的转换——例如,把数值数据序列化/反序列化到人类可读格式(JSON、XML 等)中——那么你就应使用这些函数。
对于把整数转换成字符序列,可使用下面这组函数:
to_chars_result to_chars(char* first, char* last, IntegerT value, int base = 10);这里 IntegerT 可以是任意有符号或无符号整数类型,或者 char。返回结果类型为 to_chars_result,它定义如下:
struct to_chars_result { char* ptr; errc ec;};其中成员 ptr 在转换成功时会等于“写入字符序列后一位”的指针;若转换失败,则等于 last(此时 ec == errc::value_too_large)。如果 ec 等于一个默认构造出来的 errc,那就表示转换成功。
下面是一个使用示例:
const size_t BufferSize { 50 };string out(BufferSize, ' '); // A string of BufferSize space characters.auto result { to_chars(out.data(), out.data() + out.size(), 12345) };if (result.ec == errc{}) { println("{}", out); /* Conversion successful. */ }借助 第 1 章 中介绍过的结构化绑定(structured bindings),你还可以把它写成下面这样:
string out(BufferSize, ' '); // A string of BufferSize space characters.auto [ptr, error] { to_chars(out.data(), out.data() + out.size(), 12345) };if (error == errc{}) { println("{}", out); /* Conversion successful. */ }类似地,对于浮点类型,还提供了下面这组转换函数:
to_chars_result to_chars(char* first, char* last, FloatT value);to_chars_result to_chars(char* first, char* last, FloatT value, chars_format format);to_chars_result to_chars(char* first, char* last, FloatT value, chars_format format, int precision);这里 FloatT 可以是任意浮点类型,例如 float、double 或 long double。格式控制通过一个或多个 chars_format 标志来指定。
enum class chars_format { scientific, // Style: (-)d.ddde±dd fixed, // Style: (-)ddd.ddd hex, // Style: (-)h.hhhp±d (Note: no 0x!) general = fixed | scientific // See next paragraph.};默认格式是 chars_format::general,这会让 to_chars() 在 (-)ddd.ddd 样式的十进制记法和 (-)d.ddde±dd 样式的十进制指数记法之间自动选择,哪种表示更短、且若存在小数点则至少在小数点前保留一位数字,就选哪种。如果指定了格式但没有指定精度,那么精度会自动推导为“在该格式下得到最短表示所需的最小精度”,上限为 6 位。示例如下:
double value { 0.314 };string out(BufferSize, ' '); // A string of BufferSize space characters.auto [ptr, error] { to_chars(out.data(), out.data() + out.size(), value) };if (error == errc{}) { println("{}", out); /* Conversion successful. */ }从字符串转回数值
Section titled “从字符串转回数值”对于相反方向的转换——也就是把字符序列转换成数值——可使用下面这组函数1:
from_chars_result from_chars(const char* first, const char* last, IntegerT& value, int base = 10);from_chars_result from_chars(const char* first, const char* last, FloatT& value, chars_format format = chars_format::general);这里,from_chars_result 是一个定义如下的类型:
struct from_chars_result { const char* ptr; errc ec;};结果对象中的 ptr 成员,会指向“第一个未被转换的字符”;如果所有字符都成功转换,它就等于 last。如果一个字符都无法转换,那么 ptr 会等于 first,同时错误码将是 errc::invalid_argument。如果解析出的值太大,超出了给定类型可表示的范围,则错误码会是 errc::result_out_of_range。还要注意,from_chars() 不会跳过任何前导空白字符。
to_chars() 与 from_chars() 的完美往返能力,可以通过下面这段代码演示出来:
double value1 { 0.314 };string out(BufferSize, ' '); // A string of BufferSize space characters.auto [ptr1, error1] { to_chars(out.data(), out.data() + out.size(), value1) };if (error1 == errc{}) { println("{}", out); /* Conversion successful. */ }
double value2;auto [ptr2, error2] { from_chars(out.data(), out.data() + out.size(), value2) };if (error2 == errc{}) { if (value1 == value2) { println("Perfect roundtrip"); } else { println("No perfect roundtrip?!?"); }}std::string_view 类
Section titled “std::string_view 类”在 C++17 之前,只要函数接收“只读字符串”,就总会面临一个参数类型选择困境。是该用 const char* 吗? 如果这样,那么一旦调用方手头持有的是 std::string,就不得不先对它调用 c_str() 或 data() 来取得一个 const char*。更糟的是,函数接口会因此丢掉 string 那些优雅的面向对象特性和各种好用的辅助成员函数。那改用 const string& 呢? 如果这么做,那就意味着你总得准备一个 string。例如,如果你传入的是字符串字面量,编译器就会悄悄构造一个临时 string 对象,把字面量拷贝进去,然后再把这个临时对象的引用传给函数,也就引入了额外开销。有时,人们会为同一个函数写多个重载——一个接收 const char*,另一个接收 const string&——但这显然算不上优雅。
从 C++17 开始,随着 std::string_view 类的引入,这些问题就都被解决了。string_view 是 std::basic_string_view 类模板的一个实例化,定义在 <string_view> 中。可以把 string_view 理解成一种“没有开销的 const string& 替代品”。它永远不会复制字符串! string_view 提供的是一个对字符串的只读视图,并且它的接口与 string 很相似,甚至也支持 C++23 引入的 contains() 成员函数。一个例外是它没有 c_str(),但 data() 是有的。另一方面,string_view 还额外提供了 remove_prefix(size_t) 和 remove_suffix(size_t) 成员函数,分别通过向前推进起始指针或向后收缩结束指针,来缩短视图覆盖的字符串范围。与 string 一样,从 C++23 开始,试图用 nullptr 构造 string_view 会直接导致编译错误。
如果你已经会用 std::string,那用 string_view 也非常直接。下面这段示例代码展示了这一点。extractExtension() 函数会从给定文件名中提取并返回其扩展名,包括点号本身。需要注意的是,string_view 通常按值传递,因为它的复制成本极低。它本质上只包含“指向字符串的指针 + 长度”这两样东西。成员函数 rfind() 会从字符串尾部开始搜索某个给定的子串或字符。作用在 string_view 上的 substr() 返回的还是一个 string_view,随后它会被传给 string 构造函数,显式转成一个 string,并作为函数返回值返回。
string extractExtension(string_view filename){ // Return a copy of the extension. return string { filename.substr(filename.rfind('.')) };}这个函数可以和各种不同形式的字符串搭配使用:
string filename { R"(c:\temp\my file.ext)" };println("C++ string: {}", extractExtension(filename));
const char* cString { R"(c:\temp\my file.ext)" };println("C string: {}", extractExtension(cString));
println("Literal: {}", extractExtension(R"(c:\temp\my file.ext)"));在这些对 extractExtension() 的调用中,参数本身没有发生哪怕一次拷贝。extractExtension() 中的参数 filename 只是一个“指针 + 长度”的视图而已,效率非常高。
string_view 还提供了一个接收“任意原始缓冲区 + 长度”的构造函数。这可以用来从一个未以 NUL (\0) 结尾的字符串缓冲区中构造出 string_view。即使你手里的缓冲区本身是 NUL 结尾的,但如果你已经事先知道字符串长度,那么这种构造方式依然很有用,因为这样 string_view 构造函数就无需再次去数一遍字符个数了。例如:
const char* raw { /* … */ };size_t length { /* … */ };println("Raw: {}", extractExtension({ raw, length }));最后这一行也可以写得更显式一些:
println("Raw: {}", extractExtension(string_view { raw, length }));此外,你还可以从 common range,以及从 C++23 起的 modern range 中构造 string_view。迭代器、common ranges 和 modern ranges 会在 第 17 章“理解迭代器与 Ranges 库”中讲解。
你不能把一个 string_view 隐式构造成 string。这样设计是为了防止你在不经意间把 string_view 中的内容复制出来,因为从 string_view 构造 string 永远都会涉及一次数据拷贝。若要把 string_view 转成 string,必须显式调用 string 构造函数。前面 extractExtension() 的 return 语句做的正是这件事:
return string { filename.substr(filename.rfind('.')) };出于同样原因,你也不能直接把 string 和 string_view 拼接起来。下面这段代码是不能编译的:
string str { "Hello" };string_view sv { " world" };auto result { str + sv }; // Error, does not compile!正确做法是先用 string 构造函数把 string_view 转成 string:
auto result1 { str + string { sv } };或者,使用 append():
string result2 { str };result2.append(sv.data(), sv.size());返回字符串的函数应返回 const string& 或 string,而不是 string_view。返回 string_view 会引入风险:一旦它所引用的字符串发生了内存重分配,返回的 string_view 就会失效。
如果把 const string& 或 string_view 作为类的数据成员保存下来,你就必须保证:它们所引用的那个字符串,在整个对象生命周期内始终有效。强烈建议直接保存 std::string 本身。
std::string_view 与临时字符串
Section titled “std::string_view 与临时字符串”绝不应使用 string_view 去保存对临时字符串的视图。看下面这个例子:
string s { "Hello" };string_view sv { s + " World!" };println("{}", sv);这段代码表现为未定义行为,也就是说,它运行时到底会发生什么,完全取决于你的编译器及其配置。它可能崩溃,也可能打印出 “ello World!”(少了字母 H),等等。为什么这是未定义行为? 因为 sv 的初始化表达式会先产生一个内容为 “Hello World!” 的临时字符串。随后,string_view 把指向这个临时字符串的指针保存了起来。而在第二行代码结束时,这个临时字符串就被销毁了,于是 string_view 中剩下的只是一个悬空指针。
绝不要用 std::string_view 去保存对临时字符串的视图。
std::string_view 字面量
Section titled “std::string_view 字面量”你可以用标准字面量后缀 sv 把某个字符串字面量直接解释为 std::string_view。例如:
auto sv { "My string_view"sv };标准字面量 sv 需要以下任意一种 using 指令:
using namespace std::literals::string_view_literals;using namespace std::string_view_literals;using namespace std::literals;using namespace std;非标准字符串
Section titled “非标准字符串”许多 C++ 程序员不用 C++ 风格字符串,原因有很多。有些程序员仅仅是不知道 string 这种类型,因为它并不是从一开始就属于 C++ 规范的一部分。另一些人则在多年实践中发现,C++ string 并不能完全提供他们所需的行为,或者他们不喜欢 std::string 对字符编码完全中立的设计,于是便开发了自己的字符串类型。第 21 章 还会回到字符编码这个主题上来。
不过最常见的原因,大概还是开发框架和操作系统往往都有自己表示字符串的方式,例如 Microsoft MFC 框架中的 CString 类。很多时候,这些做法都是为了向后兼容或解决遗留问题。开始一个 C++ 项目时,一个非常重要的前期决策,就是提前决定团队将如何表示字符串。有几件事是可以明确的:
- 绝不要选择 C 风格字符串作为统一方案。
- 你可以统一采用所使用框架中提供的字符串功能,例如 MFC、Qt 等框架自带的字符串能力。
- 如果你使用
std::string作为字符串类型,那么就应使用std::string_view给函数传只读字符串;如果不是,那就看看你的框架是否提供了类似string_view的机制。
字符串的格式化与打印
Section titled “字符串的格式化与打印”直到 C++20 为止,字符串格式化通常都是通过 C 风格函数(printf()) 或 C++ I/O 流(std::cout) 来完成的:
- C 风格函数:
- 不推荐使用,因为它们不是类型安全的,也不能优雅地扩展到自定义类型
- 可读性较好,因为格式字符串与参数是分离的,因此也更容易翻译成不同语言
- 例如:
printf("x has value %d and y has value %d.\n", x, y);- C++ I/O 流:
- 在 C++20 之前属于推荐方式,因为它们是类型安全且可扩展的
- 但可读性较差,因为字符串和参数交织在一起,因此也更难翻译
- 例如:
cout << "x has value " << x << " and y has value " << y << '.' << endl;C++20 引入了定义在 <format> 中的 std::format(),用来格式化字符串。它基本上把 C 风格函数和 C++ I/O 流各自的优点都结合了起来:既类型安全,又可扩展。例如:
cout << format("x has value {} and y has value {}.", x, y) << endl;到了 C++23,随着 std::print() 和 println() 的加入,事情又变得更容易了。例如:
println("x has value {} and y has value {}.", x, y);此外,std::print() 和 println() 对向支持 Unicode 的控制台输出 UTF-8 文本也提供了更好的支持。Unicode 会在 第 21 章 讨论,不过先看个小例子:
println("こんにちは世界");这会把字符串 “こんにちは世界”(日语的 “Hello World”) 正确打印到控制台。2 如果你改用 C++ I/O 流打印,像下面这样,那么输出结果就可能取决于控制台设置,并变成类似 “πüôπéôπü½πüíπü»Σ╕ûτòî” 这样的乱码:
cout << "こんにちは世界" << endl;受益于 Unicode 支持,你甚至还可以打印 emoji。如果你的输出控制台支持 Unicode,下面这行代码就会打印一个笑脸。而若使用 cout,往往就只会得到乱码。
println("😀");std::print() 和 println() 现在已是向控制台写文本的推荐方式;因此本书所有示例都统一使用它们。它们类型安全,可扩展支持用户自定义类型,可读性好,支持 Unicode 输出,支持不同语言本地化,等等。除了这些好处之外,print() 和 println() 的性能通常也明显优于直接用 C++ I/O 流实现同样事情的方式,尽管在底层,它们其实仍然是在使用这类流。
std::format()、print() 和 println() 都使用一种格式字符串(format string),也就是一个字符串,用于指定“给定参数应如何被格式化到输出字符串中”。这种最基础的形式在前一章已经介绍过,而且前面的示例里也一直在使用。现在是时候深入看看这些格式字符串到底有多强大了。
格式字符串通常是 format()、print() 和 println() 的第一个参数。格式字符串中可以包含一对花括号 {},它代表一个替换字段(replacement field)。你可以按需要写任意多个替换字段。随后传给 format()、print() 和 println() 的参数值,会依次用来填充这些替换字段。如果你真的想把 { 和 } 本身输出出来,就必须把它们写成 {{ 和 }}。
到目前为止,替换字段一直只是空花括号 {},但这只是开始。在花括号内部,其实可以写成 [index][:specifier] 这样的形式:
- 可选的
index叫做参数索引(argument index),下一节会讨论。 - 可选的
specifier叫做格式说明符(format specifier),它用来规定某个值在输出中应如何格式化,后面的“格式说明符”一节会详细解释。
把格式字符串传给 format()、print() 和 println() 是强制要求。例如,你不能像下面这样直接打印一个值:
int x { 42 };println(x);你必须写成这样:
println("{}", x);同理,你也不能单纯写下面这样来输出一个换行:
println();正确做法是:
println("");你可以在所有替换字段中都省略 index,也可以在所有替换字段中都显式指定它们对应的零基参数索引。这里的参数索引指的是:传给 format()、print() 或 println() 的第二个及后续参数中,到底要拿哪一个值来填充当前替换字段。某个 index 是允许重复使用的;这样你就可以在输出中多次打印同一个值。如果省略了 index,那么第二个及之后的参数就会按它们出现的顺序,依次用于填充所有替换字段。
下面这次对 println() 的调用,在替换字段中就没有显式指定索引:
int n { 42 };println("Read {} bytes from {}", n, "file1.txt");如果你想手动指定索引,可以写成这样:
println("Read {0} bytes from {1}", n, "file1.txt");手动索引和自动索引不能混用。下面这段使用的是非法格式字符串:
println("Read {0} bytes from {}", n, "file1.txt");格式字符串里输出值的顺序,可以在不改动参数实际顺序的前提下重新排列。如果你要把软件中的字符串翻译成其他语言,这就是个非常实用的功能。不同语言的句子内部,词序常常不同。例如,前面的格式字符串翻译成中文后就可能变成下面这样。在中文里,替换字段在句中的顺序发生了变化,但由于格式字符串里使用了参数索引,所以传给 println() 的参数顺序完全无需改变。
println("从{1}中读取{0}个字节。", n, "file1.txt");输出到不同目标
Section titled “输出到不同目标”到目前为止,每一次对 print() 和 println() 的调用,其第一个参数都是格式字符串,后面跟着若干额外参数。例如:
println("x has value {} and y has value {}.", x, y);这会把字符串输出到标准输出流,也就是和 std::cout 同一个目标。
正如 第 1 章 所解释的,还有一个 std::cerr,它会写向标准错误控制台。你也可以用 print() 和 println() 向错误控制台输出:
println(cerr, "x has value {} and y has value {}.", x, y);
Section titled “ 对格式字符串的编译期验证”从 C++23 起,format()、3 print() 和 println() 的格式字符串必须是一个编译期常量,这样编译器才能在编译期检查其中是否存在语法错误。这意味着下面这样的代码将无法编译:
string s { "Hello World!" };println(s); // Error! Does not compile.具体报错信息依赖编译器,而且在写作本书时,这些错误提示往往都相当晦涩,并不总是能立即帮助你定位真正原因。例如,下面就是 Microsoft Visual C++ 2022 编译器给出的错误:
error C7595: 'std::basic_format_string<char>::basic_format_string': call to immediate function is not a constant expression正确用法应如下:
string s { "Hello World!" };println("{}", s);constexpr 格式字符串自然也同样是合法的,因为它们本来就是编译期常量。第 9 章“精通类和对象”会详细讨论 constexpr 关键字。
constexpr auto formatString { "Value: {}" };println(formatString, 11); // Value: 11非编译期常量格式字符串
Section titled “非编译期常量格式字符串”格式字符串必须是编译期常量这一点,在你需要把格式字符串本地化/翻译成不同语言时,会显得有些麻烦。在这种场景下,你可以使用 std::vprint_unicode() 或 std::vprint_nonunicode() 来代替 std::print()。只是这样用起来会稍微复杂一点。你不能像调用 print() 那样直接把参数传进去,而必须借助 std::make_format_args()。例如:
enum class Language { English, Dutch };
string_view GetLocalizedFormat(Language language){ switch (language) { case Language::English: return "Numbers: {0} and {1}."; case Language::Dutch: return "Getallen: {0} en {1}."; }}
int main(){ Language language { Language::English }; vprint_unicode(GetLocalizedFormat(language), make_format_args(1, 2)); println(""); language = Language::Dutch; vprint_unicode(GetLocalizedFormat(language), make_format_args(1, 2));}输出如下:
Numbers: 1 and 2.Getallen: 1 en 2.如果改成下面这种使用 print() 的调用,就无法通过编译,因为 print() 要求格式字符串必须是编译期常量:
print(GetLocalizedFormat(language), 1, 2);处理非编译期常量格式字符串中的错误
Section titled “处理非编译期常量格式字符串中的错误”当格式字符串是在运行期而不是编译期验证时,一旦格式字符串有错误,就会抛出 std::format_error 异常。正如前面解释的那样,std::format()、print() 和 println() 这类函数都不会抛出这样的异常,因为它们的格式字符串会在编译期完成验证。而像 std::vformat() 和 vprint_unicode()(见上一节) 这类函数则不要求格式字符串是常量,因此它们不会在编译期验证格式字符串,而是在运行期检查。于是,这些函数就可能抛出 format_error 异常。示例如下:
try { vprint_unicode("An integer: {5}", make_format_args(42));} catch (const format_error& caught_exception) { println("{}", caught_exception.what()); // "Argument not found."}现在,让我们来进一步看看格式说明符究竟有多强大。
前面已经提到,格式字符串可以包含由花括号包围的替换字段。花括号内部的形式可以写成 [index][:specifier]。本节专门讨论替换字段中的 specifier 部分。至于 index,前面已经讲过了。
格式说明符(format specifier) 用来控制某个值在输出中的具体格式。它由一个冒号 : 引出。格式说明符的一般形式如下:
[[fill]align][sign][#][0][width][.precision][L][type]方括号中的所有部分都是可选的。接下来几个小节会分别讨论这些组成部分。
width 指定“用于格式化某个值的字段”至少应有多宽。它也可以是另一组花括号,此时就叫做动态宽度(dynamic width)。若花括号里显式写了索引,例如 {3},则动态宽度取自对应索引的那个参数值。否则,若花括号中没有写索引,例如 {},则宽度取自参数列表中的下一个参数。
例如:
int i { 42 };println("|{:5}|", i); // | 42|println("|{:{}}|", i, 7); // | 42|println("|{1:{0}}|", 7, i); // | 42|[fill]align
Section titled “[fill]align”[fill]align 部分可以指定要使用什么填充字符,以及值应如何在字段中对齐:
<表示左对齐(默认用于非整数和非浮点数)>表示右对齐(默认用于整数和浮点数)^表示居中对齐
填充字符会插入到输出中,从而保证输出字段至少达到 [width] 所要求的最小宽度。如果没有指定 [width],[fill]align 就不会产生任何效果。
使用居中对齐时,填充字符会尽量在格式化值左右两边数量相同。如果总填充数是奇数,则额外的那个填充字符会放在右边。
示例如下:
int i { 42 };println("|{:7}|", i); // | 42|println("|{:<7}|", i); // |42 |println("|{:_>7}|", i); // |_____42|println("|{:_^7}|", i); // |__42___|下面这个例子是一个很有趣的小技巧:它可以让你把某个字符输出指定次数。你不再需要自己手写一个包含正确字符数量的字符串字面量,而只需在格式说明符里明确写出你要的数量:
println("|{:=>16}|", ""); // |================|sign 部分可以取以下几种值之一:
-表示只对负数显示符号(默认)+表示对正数和负数都显示符号space表示对负数显示减号,对正数则显示一个空格
示例如下:
int i { 42 };println("|{:<5}|", i); // |42 |println("|{:<+5}|", i); // |+42 |println("|{:< 5}|", i); // | 42 |println("|{:< 5}|", -i); // |-42 |#
# 部分用于启用替代格式规则(alternate formatting)。如果它作用于整数类型,并且同时指定了十六进制、二进制或八进制格式,那么替代格式会在格式化结果前面分别加上 0x、0X、0b、0B 或 0。如果它作用于浮点类型,则替代格式会始终输出小数点,即便后面没有任何数字。
接下来两个小节会给出带替代格式的示例。
type 用于指定某个值应按什么类型格式输出。它有多种选项:
- 整数类型:
b(二进制),B(二进制,若指定#则使用0B而非0b),d(十进制),o(八进制),x(十六进制,使用小写a、b、c、d、e、f),X(十六进制,使用大写A、B、C、D、E、F,并且若指定#,则前缀使用0X而不是0x)。若未指定type,整数默认使用d。 - 浮点类型: 支持以下几种浮点格式。scientific、fixed、general 和 hexadecimal 的结果,与本章前面讨论
std::chars_format::scientific、fixed、general和hex时一致。e,E: 科学计数法,指数部分分别使用小写e或大写E,若未指定精度则默认用 6 位精度。f,F: 定点格式,若未指定精度则默认使用 6 位。g,G: 通用格式,自动在“无指数的定点表示”和“带指数表示(小写e或大写E)”之间选择;若未指定精度则默认使用 6 位。a,A: 十六进制浮点表示,分别使用小写或大写字母。- 若未指定
type,浮点类型默认使用g。
- 布尔值:
s(以文本形式输出true或false),b、B、c、d、o、x、X(以整数形式输出1或0)。若未指定type,布尔值默认使用s。 - 字符:
c(直接输出字符),?(输出转义后的字符;见“格式化转义字符与字符串”一节),b、B、d、o、x、X(以整数表示输出)。若未指定type,字符默认使用c。 - 字符串:
s(直接输出字符串),?(输出转义后的字符串;见“格式化转义字符与字符串”一节)。若未指定type,字符串默认使用s。 - 指针:
p(以带0x前缀的十六进制形式输出指针)。若未指定type,指针默认使用p。只有void*类型指针可以直接被格式化。其他类型的指针必须先转换成void*,例如通过static_cast<void*>(myPointer)。
下面是一些整数类型的示例:
int i { 42 };println("|{:10d}|", i); // | 42|println("|{:10b}|", i); // | 101010|println("|{:#10b}|", i); // | 0b101010|println("|{:10X}|", i); // | 2A|println("|{:#10X}|", i); // | 0X2A|下面是一个字符串类型的示例:
string s { "ProCpp" };println("|{:_^10}|", s); // |__ProCpp__|关于浮点类型的例子,下一节 “precision” 中会继续给出。
precision
Section titled “precision”precision 只能用于浮点类型和字符串类型。它的写法是一个点号后跟数字,表示:对浮点类型输出多少位数字,或对字符串输出多少个字符。对于浮点类型,除非使用定点格式(f 或 F),否则这里的“数字个数”包括小数点前后的全部数字;若使用定点格式,则 precision 表示小数点后数字位数。
和 width 一样,precision 也可以写成另一组花括号,此时就叫做动态精度(dynamic precision)。其值要么来自参数列表中的下一个参数,要么来自某个显式索引指定的参数。
下面是一些浮点类型示例:
double d { 3.1415 / 2.3 };println("|{:12g}|", d); // | 1.36587|println("|{:12.2}|", d); // | 1.4|println("|{:12e}|", d); // |1.365870e+00|
int width { 12 };int precision { 3 };println("|{2:{0}.{1}f}|", width, precision, d); // | 1.366|println("|{2:{0}.{1}}|", width, precision, d); // | 1.37|说明符中的 0 表示:对于数值类型,在格式化结果中插入前导零,从而达到 [width] 指定的最小宽度(前面已经讨论过)。这些零会被插入在数字最前面,但位于符号后面,同时也位于任何 0x、0X、0b 或 0B 前缀之后。如果同时指定了对齐方式,那么 0 说明符就会被忽略。
示例如下:
int i { 42 };println("|{:06d}|", i); // |000042|println("|{:+06d}|", i); // |+00042|println("|{:06X}|", i); // |00002A|println("|{:#06X}|", i); // |0X002A|可选说明符 L 用于启用与 locale 相关的格式化。这个选项只对算术类型有效,例如整数、浮点数和布尔值。对整数使用时,L 表示应使用 locale 对应的数字分组分隔符。对浮点类型而言,它表示应使用 locale 对应的数字分组符和小数分隔符。对以文本形式输出的布尔值而言,则表示应使用 locale 对应的 true / false 表示。
使用 L 说明符时,你必须把一个 std::locale 实例作为 std::format() 的第一个参数传入。这只对 format() 有效,不适用于 print() 和 println()。例如,下面这段代码使用 nl locale 来格式化一个浮点数:
float f { 1.2f };cout << format(std::locale{ "nl" }, "|{:Lg}|\n", f); // |1,2|locale 会在 第 21 章 中讲解。
Section titled “ 格式化转义字符与字符串”C++23 允许你通过 ? 类型说明符来格式化“带转义”的字符串和字符。这类用法并不算常见,但在日志和调试场景中会很有帮助。输出结果会类似你在代码里书写字符串和字符字面量的方式:它们会带有双引号或单引号,并且使用转义字符序列。下表展示了若干字符在“转义格式化”时的输出形式:
| 字符 | 转义输出 |
|---|---|
| 水平制表符 | \t |
| 换行 | \n |
| 回车 | \r |
| 反斜杠 | \\ |
| 双引号 | \" |
| 单引号 | \' |
对双引号的转义只会发生在“带双引号的字符串输出”中;而对单引号的转义只会发生在“带单引号的字符输出”中。对于不可打印字符,转义输出形式为 \u{hex-code-point}。
例如:
println("|{:?}|", "Hello\tWorld!\n"); // |Hello\tWorld!\n|println("|{:?}|", "\""); // |"\""|println("|{:?}|", '\''); // |'\''|println("|{:?}|", '"'); // |'"'|
Section titled “ 格式化区间(range)”第 1 章 已经介绍了 std::vector、array 和 pair,它们都可以用来存储多个元素。第 18 章“标准库容器”还会进一步介绍标准库中更多容器。从 C++23 开始,你已经可以直接格式化这类元素区间了。对于 vector、array 这样的区间,默认输出会被方括号包裹,各个元素之间用逗号分隔。如果区间中的元素本身是字符串,那么默认会以转义形式输出。
区间的格式化可以通过嵌套格式说明符来控制。其一般形式如下:
[[fill]align][width][n][range-type][:range-underlying-spec]方括号中的每一项都是可选的。和其他格式说明符一样,fill 表示填充字符,align 表示对齐方式,width 表示输出字段宽度。如果指定了 n,输出中就不会带区间的起止括号。range-type 可以取以下值之一:
| RANGE-TYPE | 说明 |
|---|---|
m | 仅适用于 pair 或拥有两个元素的 tuple。默认情况下,它们会被圆括号包围,并用逗号分隔。如果指定 m,则不再带任何括号,同时两个元素之间用 ": " 分隔。 |
s | 把整个区间按字符串格式输出(不能与 n 或 range-underlying-spec 结合使用)。 |
?s | 把整个区间按转义字符串格式输出(不能与 n 或 range-underlying-spec 结合使用)。 |
range-underlying-spec 是一个可选的“区间中各个元素”的格式说明符。如果元素本身仍然是区间(例如 vector<vector<...>>),那么 range-underlying-spec 还可以继续是另一个区间格式说明符,因此可以多层嵌套。
先看一些例子。首先,格式化一个数字 vector:
vector values { 11, 22, 33 };println("{}", values); // [11, 22, 33]println("{:n}", values); // 11, 22, 33如果你想替换默认的方括号,也可以结合 n 说明符,再在格式字符串外层自己补上想要的起止字符。例如,下面这个例子就把输出包在花括号中。要想让花括号真的出现在输出中,必须写成 {{ 与 }}。
println("{{{:n}}}", values); // {11, 22, 33}下面这个例子为“整个区间”指定了格式。两条语句都会把区间内容居中放到一个宽度为 16、填充字符为 * 的字段里。第二条中的 n 表示不要输出区间的起止括号:
println("{:*^16}", values); // **[11, 22, 33]**println("{:*^16n}", values); // ***11, 22, 33***接下来这个例子没有给整个区间显式指定格式,而是指定了“每个元素”应如何格式化。在这里,每个元素都会被放到一个宽度为 6、填充字符为 * 的字段中央:
println("{::*^6}", values); // [**11**, **22**, **33**]这同样可以和 n 说明符结合使用:
println("{:n:*^6}", values); // **11**, **22**, **33**下面是一些格式化字符串 vector 的例子:
vector strings { "Hello"s, "World!\t2023"s };println("{}", strings); // ["Hello", "World!\t2023"]println("{:}", strings); // ["Hello", "World!\t2023"]println("{::}", strings); // [Hello, World! 2023]println("{:n:}", strings); // Hello, World! 2023如果你有一个字符 vector,既可以把它们按单个字符来格式化,也可以利用 s 或 ?s 这个 range type,把整个 vector 当成字符串来看待:
vector chars { 'W', 'o', 'r', 'l', 'd', '\t', '!' };println("{}", chars); // ['W', 'o', 'r', 'l', 'd', '\t', '!']println("{::#x}", chars); // [0x57, 0x6f, 0x72, 0x6c, 0x64, 0x9, 0x21]println("{:s}", chars); // World !println("{:?s}", chars); // "World\t!"下面是一些输出 pair 的例子。默认情况下,pair 会被圆括号包围,并且两个元素之间用逗号分隔。使用 n 说明符会移除外层圆括号。使用 m 说明符也会移除圆括号,并改为用 ": " 分隔两个元素。
pair p { 11, 22 };println("{}", p); // (11, 22)println("{:n}", p); // 11, 22println("{:m}", p); // 11: 22最后再看一个输出 vector<vector<int>> 的例子:
vector<vector<int>> vv { {11, 22}, {33, 44, 55} };println("{}", vv); // [[11, 22], [33, 44, 55]]println("{:n}", vv); // [11, 22], [33, 44, 55]println("{:n:n}", vv); // 11, 22, 33, 44, 55println("{:n:n:*^4}", vv); // *11*, *22*, *33*, *44*, *55*支持自定义类型
Section titled “支持自定义类型”格式化库还能被扩展,以支持自定义类型。这需要为 std::formatter 类模板编写一个特化(specialization),其中包含两个成员函数模板:parse() 和 format()。我知道,在本书当前进度下,你还看不懂这个示例中的全部语法,因为它同时用到了下面这些技术:
constexpr函数,会在 第 9 章 讨论- 模板特化、成员函数模板以及缩写函数模板语法,会在 第 12 章“使用模板编写泛型代码”中解释
- 异常,会在 第 14 章“错误处理”中讨论
- 迭代器,会在 第 17 章“理解迭代器与 Ranges 库”中讲解
尽管如此,为了完整性,也为了让你先感受一下“未来能做到什么”,我们还是先看一眼。等你在后续章节中学到这些知识之后,完全可以再回头重读这个例子。
假设你有这样一个类,用来保存一个键值对:
class KeyValue{ public: KeyValue(string_view key, int value) : m_key { key }, m_value { value } {}
const string& getKey() const { return m_key; } int getValue() const { return m_value; }
private: string m_key; int m_value { 0 };};若想为 KeyValue 对象提供自定义 formatter,可以写出下面这个类模板特化。这个 KeyValue formatter 支持:
- 自定义格式说明符:
{:k}只输出 key,{:v}只输出 value,而{:b}和{}则同时输出 key 和 value。 - 嵌套格式说明符:用于分别为 key 和 / 或 value 指定可选格式。语法形式如下:
{:b:KeyFormat:ValueFormat}。
template <>class std::formatter<KeyValue>{ public: constexpr auto parse(auto& context) { string keyFormat, valueFormat; size_t numberOfParsedColons { 0 }; auto iter { begin(context) }; for (; iter != end(context); ++iter) { if (*iter == '}') { break; }
if (numberOfParsedColons == 0) { // Parsing output type switch (*iter) { case 'k': case 'K': // {:k format specifier m_outputType = OutputType::KeyOnly; break; case 'v': case 'V': // {:v format specifier m_outputType = OutputType::ValueOnly; break; case 'b': case 'B': // {:b format specifier m_outputType = OutputType::KeyAndValue; break; case ':': ++numberOfParsedColons; break; default: throw format_error { "Invalid KeyValue format." }; } } else if (numberOfParsedColons == 1) { // Parsing key format if (*iter == ':') { ++numberOfParsedColons; } else { keyFormat += *iter; } } else if (numberOfParsedColons == 2) { // Parsing value format valueFormat += *iter; } } // Validate key format specifier. if (!keyFormat.empty()) { format_parse_context keyFormatterContext { keyFormat }; m_keyFormatter.parse(keyFormatterContext); } // Validate value format specifier. if (!valueFormat.empty()) { format_parse_context valueFormatterContext { valueFormat }; m_valueFormatter.parse(valueFormatterContext); } if (iter != end(context) && *iter != '}') { throw format_error { "Invalid KeyValue format." }; } return iter; }
auto format(const KeyValue& kv, auto& ctx) const { switch (m_outputType) { using enum OutputType; case KeyOnly: ctx.advance:to(m_keyFormatter.format(kv.getKey(), ctx)); break; case ValueOnly: ctx.advance:to(m_valueFormatter.format(kv.getValue(), ctx)); break; default: ctx.advance:to(m_keyFormatter.format(kv.getKey(), ctx)); ctx.advance:to(format_to(ctx.out(), " - ")); ctx.advance:to(m_valueFormatter.format(kv.getValue(), ctx)); break; } return ctx.out(); } private: enum class OutputType { KeyOnly, ValueOnly, KeyAndValue }; OutputType m_outputType { OutputType::KeyAndValue }; formatter<string> m_keyFormatter; formatter<int> m_valueFormatter;};parse() 成员函数负责解析格式说明符。它把给定的字符区间 [begin(context), end(context)) 解析后,把结果保存进 formatter 类自身的数据成员中,并返回一个迭代器,指向“已解析说明符字符串之后的那个字符”。其中两个数据成员分别是 m_keyFormatter(类型为 formatter<string>) 和 m_valueFormatter(类型为 formatter<int>),它们分别用于解析格式说明符中的 KeyFormat 和 ValueFormat 部分。
format() 成员函数则负责按照 parse() 解析出来的格式规则,把第一个参数中的值格式化到 ctx.out() 中,并返回一个指向输出结尾的迭代器。该函数使用了 std::format_to(),它与 std::format() 类似,但区别在于它接收一个输出迭代器,从而明确指出输出内容要写到哪里去。
这个 KeyValue formatter 可以像下面这样测试:
const size_t len { 34 }; // Label field lengthKeyValue kv { "Key 1", 255 };println("{:>{}} {}", "Default:", len, kv);println("{:>{}} {:k}", "Key only:", len, kv);println("{:>{}} {:v}", "Value only:", len, kv);println("{:>{}} {:b}", "Key and value with default format:", len, kv);println("{:>{}} {:k:*^11}", "Key only with special format:", len, kv);println("{:>{}} {:v::#06X}", "Value only with special format:", len, kv);println("{:>{}} {::*^11:#06X}", "Key and value with special format:", len, kv);try { auto formatted { vformat("{:cd}", make_format_args(kv)) }; println("{}", formatted);} catch (const format_error& caught_exception) { println("{}", caught_exception.what());}输出如下:
Default: Key 1 - 255 Key only: Key 1 Value only: 255Key and value with default format: Key 1 - 255 Key only with special format: ***Key 1*** Value only with special format: 0X00FFKey and value with special format: ***Key 1*** - 0X00FFInvalid KeyValue format.作为练习,你可以尝试为 key 和 value 之间加入不同分隔符的支持。借助自定义 formatter,可做的事情几乎没有边界,而且这一切仍然是类型安全的!
本章讨论了 C++ 的 string 和 string_view 类,并说明了它们相较于老式 C 风格字符数组的优势。你还看到了若干辅助函数如何简化“数值 ↔ 字符串”的双向转换,以及原始字符串字面量(raw string literals) 的概念。
本章最后还讨论了字符串格式化库,本书所有示例都会大量使用它。它是一种非常强大的机制,能够以细粒度方式控制格式化输出最终长什么样。
下一章将讨论“良好编码风格”的一些准则,包括代码文档化、分解、命名、代码格式化以及其他技巧。
通过完成下面这些练习,你可以巩固本章讨论的内容。所有练习的参考解答都包含在本书网站 www.wiley.com/go/proc++6e 的代码下载包中。不过,如果你在某道题上卡住了,请先回头重读本章相关部分,尝试自己找到答案,再去查看网站上的解答。
-
练习 2-1: 编写一个程序,要求用户输入两个字符串,然后使用三路比较运算符把它们按字母序输出。若要从用户那里读取字符串,可以使用 第 1 章 中简要介绍过的
std::cin流。第 13 章“揭秘 C++ I/O”会详细讲解输入输出,但现在你只需知道,从控制台读取字符串的方式如下。要结束一行输入,只需按 Enter。std::string s;getline(cin, s1); -
练习 2-2: 编写一个程序,要求用户输入一个源字符串(即 haystack)、一个要在源字符串中查找的字符串(即 needle),以及一个替换字符串。写一个接收这三个参数——haystack、needle 和 replacement——的函数,它返回一个 haystack 的副本,其中所有 needle 都被替换成 replacement。只使用
std::string,不要使用string_view。你会为这些参数选择什么类型,为什么? 在main()中调用这个函数,并把所有字符串打印出来以便验证。 -
练习 2-3: 修改练习 2-2 中的程序,尽可能多地在合理之处使用
std::string_view。 -
练习 2-4: 编写一个程序,要求用户输入若干个浮点数,数量未知,并把这些数字全部保存进一个
vector。每个数字后面都应跟一个换行。当用户输入数字 0 时,停止继续读取。要从控制台读取浮点数,像 第 1 章 中读取整数那样使用cin即可。然后把所有数字格式化输出成一个带若干列的表格,每一列使用一种不同的格式来显示数字。表格中的每一行都对应一个输入数字。 -
练习 2-5: 编写一个程序,要求用户输入若干个单词,数量未知。当用户输入
*时停止输入。把所有单词分别保存进一个vector中。你可以通过下面这种方式读取单个单词:std::string word;cin >> word;当输入结束后,计算最长单词的长度。最后,把所有单词按列输出,每行输出五个。每列的宽度应基于最长单词的长度来确定。单词应在各自列中居中对齐,并用
|字符分隔各列。
Footnotes
Section titled “Footnotes”-
从 C++23 起,to_chars() 和 from_chars() 的整数重载都被标记为了
constexpr。这意味着它们可以在其他constexpr函数和类中于编译期求值。关于constexpr,可参见第 9 章“精通类和对象”。 ↩ -
若要编译包含 Unicode 字符的源代码,你可能需要传递编译器开关。对于 Visual C++,必须传入
/utf-8编译选项。对于 GCC,使用命令行选项-finput-charset=UTF-8。Clang 默认假定所有文件都是 UTF-8。具体请查阅你的编译器文档。 ↩ -
这对
std::format()来说是一个 breaking change。在 C++23 之前,format()的格式字符串并不要求必须是编译期常量。 ↩