定制与扩展标准库
第 16 章“C++ 标准库概览”、第 18 章“标准库容器”以及第 20 章“掌握标准库算法”已经展示过:标准库提供了一套功能强大、面向通用用途的容器和算法集合。到目前为止介绍的内容,对大多数应用来说已经足够。不过,那几章讨论的都是标准库“开箱即用”的能力。实际上,标准库还可以按你的需要进一步定制和扩展。比如,你可以编写自己符合标准库约定的容器、算法和迭代器,并让它们与现有标准库功能兼容使用;你甚至还能为容器指定自己的内存分配方案。本章会通过一个 find_all() 算法和一个 directed_graph 容器的开发过程,带你体验这些更高级的能力。
分配器 (ALLOCATORS)
Section titled “分配器 (ALLOCATORS)”每一个标准库容器都把 Allocator 类型作为模板类型参数之一,而默认值通常已经足够。例如,vector 模板的定义看起来是这样的:
template <class T, class Allocator = allocator<T>> class vector;container 的构造函数随后会允许你传入一个 Allocator 类型的对象。这样一来,你就可以定制 container 分配内存的方式。container 所做的每一次内存分配,最终都会调用该 Allocator 对象的 allocate() 成员函数;相应地,每一次释放内存都会调用其 deallocate() 成员函数。当某个 Standard Library container 接受 Allocator 参数时,如果你没有显式提供,它就总是默认使用 std::allocator<T>。而 std::allocator<T> 的 allocate() 与 deallocate(),本质上只是对 new 和 delete 的简单包装。
要注意,allocate() 只是分配一块足够大的、尚未初始化的内存,并不会调用任何对象构造函数。同样,deallocate() 只是释放这块内存,也不会调用任何析构函数。一旦内存块分配出来,就可以使用 placement new(见第 15 章)在那块地址上原地构造对象。下面这段代码展示了一个略显刻意的例子。第 29 章“编写高效 C++”会给出一个更贴近实际的 allocator 用例,用于实现对象池(object pool)。
class MyClass {};int main(){ // 创建一个要使用的分配器。 std::allocator<MyClass> alloc; // 为 MyClass 的 1 个实例分配一个未初始化的内存块。 auto* memory { alloc.allocate(1) }; // 使用 placement new 运算符在位构造 MyClass。 ::new (memory) MyClass{}; // 销毁 MyClass 实例。 std::destroy_at(memory); // 释放内存块。 alloc.deallocate(memory, 1); memory = nullptr;}如果你希望程序中的 container 使用自定义的内存分配与释放策略,那么可以自己编写 Allocator 类。之所以需要 custom allocator,原因可能有很多。比如,底层默认 allocator 的性能如果不能接受,就可以换别的方案;又或者,当你必须分配某些特定于 OS 的资源(例如 shared memory segment)时,custom allocator 可以让 Standard Library container 直接工作在这些共享内存中。custom allocator 的使用相当复杂,如果不够小心,很容易踩到很多坑,所以绝不适合轻率上手。
任何一个类,只要提供 allocate()、deallocate(),以及若干其他必需的成员函数和类型别名,都可以替代默认的 allocator 类。
此外,Standard Library 还提供了 polymorphic memory allocators 的概念。其核心问题在于:如果某个 container 的 allocator 是通过模板类型参数指定的,那么两个“内容相似但 allocator 类型不同”的 container,在类型系统里就是彻底不同的类型。例如,vector<int, A1> 和 vector<int, A2> 是不同类型,因此两者之间不能直接赋值。
定义在 <memory_resource> 中、位于 std::pmr 命名空间下的 polymorphic memory allocators,正是为了解决这个问题。std::pmr::polymorphic_allocator 是一个真正符合要求的 Allocator 类,因为它满足 allocator 的所有要求,例如提供 allocate() 和 deallocate() 成员函数。polymorphic_allocator 的分配行为取决于构造时传给它的 memory_resource,而不是任何模板类型参数。因此,虽然不同的 polymorphic_allocator 全都具有同一个类型——也就是 polymorphic_allocator——但它们在实际分配和释放内存时,完全可能表现得截然不同。标准还提供了若干内建 memory resource,可用来初始化 polymorphic memory allocator,例如:synchronized_pool_resource、unsynchronized_pool_resource 和 monotonic_buffer_resource。Standard Library 还提供了诸如 std::pmr::vector<T> 这样的模板类型别名,它对应 std::vector<T, std::pmr::polymorphic_allocator<T>>。需要注意的是,std::pmr::vector<T> 依然不同于 std::vector<T>,因此不能从 std::vector<T> 直接赋值。但某个绑定到一种 memory resource 的 std::pmr::vector<T>,与另一个绑定到不同 memory resource 的 std::pmr::vector<T> 仍然是同一种类型,两者之间可以赋值。
不过,就我的经验而言,无论是 custom allocators 还是 polymorphic memory allocators,都属于相当进阶、而且在日常编码中很少用到的特性。我自己也从未真正用过它们,因此更深入的讨论超出了本书范围。如果你想进一步了解,可以参考附录 B“带注释的参考书目”中那些专门讨论 C++ Standard Library 的书。
Standard Library 提供了大量实用的 container、algorithm 和 iterator,可供你在应用中直接使用。但再强的库,也不可能把所有潜在用户所需的所有工具都囊括进去。因此,最好的库往往都是可扩展的:它们允许使用者在基础能力之上自行适配、补充,最终得到自己真正需要的功能。Standard Library 之所以天生就适合扩展,正是因为它把“数据”与“作用于数据的算法”分离开来了。只要你提供符合 Standard Library 规范的 iterator,就可以编写自己的 container,并让它们与 Standard Library algorithm 协同工作;反过来,你也可以编写自己的 algorithm,使其适用于标准 container 的 iterator。不过要记住:你不能把自己的 container 和 algorithm 放进 std 命名空间。
为什么要扩展标准库?
Section titled “为什么要扩展标准库?”当你准备在 C++ 中编写一个 algorithm 或 container 时,可以选择遵守 Standard Library 的约定,也可以不遵守。对于一些简单的 container 与 algorithm 来说,额外去满足 Standard Library 的要求未必值得;但如果你写的是一段打算复用的、规模不小的代码,那么这份额外投入通常是值得的。首先,遵循成熟的接口约定,会让其他 C++ 程序员更容易理解你的代码。其次,你的 container 或 algorithm 能直接与 Standard Library 的其他部分(无论是 algorithm 还是 container)配合使用,而无需再额外提供各种 hack 或 adapter。最后,这种方式也会逼着你采用开发稳健代码所必需的严谨态度。
编写符合标准库约定的算法
Section titled “编写符合标准库约定的算法”第 16 章和第 20 章介绍了 Standard Library 中一整套非常有用的 algorithm。但在实际编程时,你迟早会遇到需要全新 algorithm 的场景。出现这种情况时,通常并不难写出一个像标准 algorithm 那样、能够直接与 Standard Library iterator 协同工作的自定义 algorithm。
find_all
Section titled “find_all”假设你想在一个给定区间中找出所有满足某个 predicate 的元素,并且还要保留它们的位置。find() 与 find_if() 看上去是最接近的候选者,但它们都只能返回一个指向单个匹配元素的 iterator。你可以使用 copy_if() 找出所有满足某个 predicate 的元素,但它输出的是这些元素的拷贝,于是它们原本所在的位置就丢失了。如果你想避免拷贝,可以把 copy_if() 与 back_insert_iterator(见第 17 章“理解 iterator 与 Ranges Library”)配合,输出到一个 vector<reference_wrapper<T>> 中;但这样依然拿不到这些元素的位置。事实上,标准里并没有一个 algorithm 能直接返回“所有满足某个 predicate 的元素所对应的 iterator”。不过,你完全可以自己写出这样一份功能,取名为 find_all()。
这一节我们先看一个按照 legacy unconstrained algorithms 模型来实现的 find_all()。等这个版本工作正常后,再看看如何扩展并改造它,使之符合现代 constrained algorithms 的风格,加入 projection 等支持。
第一步是定义函数原型。你可以参考 copy_if() 的模型:写成一个函数模板,包含三个模板类型参数——输入 iterator 类型、输出 iterator 类型,以及 predicate 类型。函数参数则包括:输入序列的起止 iterator、输出序列的起始 iterator,以及 predicate 对象。与 copy_if() 一样,这个 algorithm 会返回一个指向输出序列的 iterator,位置位于“最后一个写入元素之后的那个位置”。当然,在现代 C++ 代码里,推荐为模板类型参数加上适当约束,所以我们这里也照做。函数原型如下:
template <forward_iterator ForwardIterator, output_iterator<ForwardIterator> OutputIterator, indirect_unary_predicate<ForwardIterator> Predicate>OutputIterator find_all(ForwardIterator first, ForwardIterator last, OutputIterator dest, Predicate pred);forward_iterator concept 规定 iterator 必须至少支持解引用、递增等操作;output_iterator<ForwardIterator> concept 则要求该 iterator 是一个输出 iterator,并且它接受 ForwardIterator 类型的值。indirect_unary_predicate 是一组预定义要求,algorithm 可以借此来约束 unary predicate 参数。这里之所以叫 “indirect”,是因为这些要求并不是施加在模板参数 ForwardIterator 本身上,而是施加在它所引用的那个类型上。
另一种设计思路,是不提供输出 iterator,而改为返回一个作用于输入序列、可遍历所有匹配元素的 iterator。这就要求你自己写一个 iterator 类;本章后面会讨论这个方向。
下一步就是编写实现。find_all() algorithm 会遍历输入序列中的每一个元素,使用 invoke() 在每个元素上调用 predicate,并把所有匹配元素的 iterator 存入输出序列。实现如下:
template <forward_iterator ForwardIterator, output_iterator<ForwardIterator> OutputIterator, indirect_unary_predicate<ForwardIterator> Predicate>OutputIterator find_all(ForwardIterator first, ForwardIterator last, OutputIterator dest, Predicate pred){ while (first != last) { if (invoke(pred, *first)) { *dest = first; ++dest; } ++first; } return dest;}与 copy_if() 类似,这个 algorithm 只会覆盖输出序列中已有的元素,因此你要么确保输出序列本身足够大,能容纳结果;要么像下面示例那样,使用诸如 back_insert_iterator 之类的 iterator adapter。找到所有匹配元素之后,代码先统计匹配到的 iterator 个数,也就是 matches 中的元素数量;然后再遍历结果,把每个元素打印出来。
vector<int> vec { 5, 4, 5, 4, 10, 6, 5, 8, 10 };vector<vector<int>::iterator> matches;
find_all(begin(vec), end(vec), back_inserter(matches), [](int i){ return i == 10; });
println("Found {} matching elements: ", matches.size());for (const auto& it : matches) { println("{} at position {}", *it, distance(begin(vec), it));}输出如下:
Found 2 matching elements:10 at position 410 at position 8改进版 find_all
Section titled “改进版 find_all”正如第 17 章所解释的,大多数 constrained algorithms 都接受 projection 参数。find_all() 也可以现代化改写,以支持这类 projection 参数。此外,现代 constrained algorithms 通常不再要求 begin iterator 与 end iterator 必须是同一类型:begin iterator 依然如常,而 end marker 则可以是另一种类型,这种标记称为 sentinel。更新后的 algorithm 如下:
template <forward_iterator ForwardIterator, sentinel_for<ForwardIterator> Sentinel, output_iterator<ForwardIterator> OutputIterator, typename Projection = std::identity, indirect_unary_predicate<projected<ForwardIterator, Projection>> Predicate>OutputIterator find_all(ForwardIterator first, Sentinel last, OutputIterator dest, Predicate pred, Projection proj = {}){ while (first != last) { if (invoke(pred, invoke(proj, *first))) { *dest = first; ++dest; } ++first; } return dest;}sentinel_for 约束保证 first != last 这一表达式是合法的。Projection 是新增的模板类型参数,并带有默认值,即 identity 操作。indirect_unary_predicate 的模板实参也稍有变化,改成了 projected<ForwardIterator,Projection>,它表示“对解引用后的 ForwardIterator 应用 Projection 函数之后所得到的类型”。
现代化后的 find_all() 可以这样测试:
find_all(begin(vec), end(vec), back_inserter(matches), [](int i) { return i == 10; }, [](int i) { return i * 2; });这次对 find_all() 的调用,与前一节的例子几乎一样,区别在于现在加入了一个 projection。对于每个元素,algorithm 会先用该 projection 函数对其进行变换,再把变换后的结果传给给定的 predicate。在这个例子里,每个元素都会先被翻倍,然后再检查“变换后是否等于 10”。因此,这次输出会变成下面这样。你可以对比上一节的输出。
Found 3 matching elements:5 at position 05 at position 25 at position 6编写符合标准库约定的容器
Section titled “编写符合标准库约定的容器”C++ Standard Library 对任何想要被视为 Standard Library container 的类型,都规定了一整套要求。此外,如果你希望自己的 container 被归类为 sequential container(如 vector)、ordered associative container(如 map)或 unordered associative container(如 unordered_map),还必须满足额外的补充要求。
我对编写 custom container 的建议是:先把 container 的基础版本写出来,遵循一些通用的 Standard Library 规则,例如把它写成 class template,但暂时不要过早纠结于“是否已经完全符合 Standard Library 的全部细节要求”。当基础实现成形之后,再加上 iterator 支持,使其能够融入 Standard Library 框架;接着补齐所有基础 container 所需的成员函数和类型别名;最后再去满足那些额外的 container-specific 要求。本章就按这个思路,来开发一个 directed graph 数据结构,也叫 digraph。
基础版 directed_graph
Section titled “基础版 directed_graph”某些 C++ Standard Library container 的内部实现或许会用到 graph,但标准本身并没有直接提供任何 graph-like 数据结构给用户使用。因此,自己实现一个 graph,正好是“编写符合 Standard Library 约定的 custom container”的绝佳例子。
在真正写代码之前,先来看一下 directed graph 到底是一种什么样的数据结构,以及如何在内存中表达它。下图展示了一个 directed graph 的可视化示例。简单来说,directed graph 由一组 node(也叫 vertex)以及连接它们的 edge 组成。每条 edge 还带有方向,这一点通过箭头表示,这也是它被称为 directed graph 的原因。
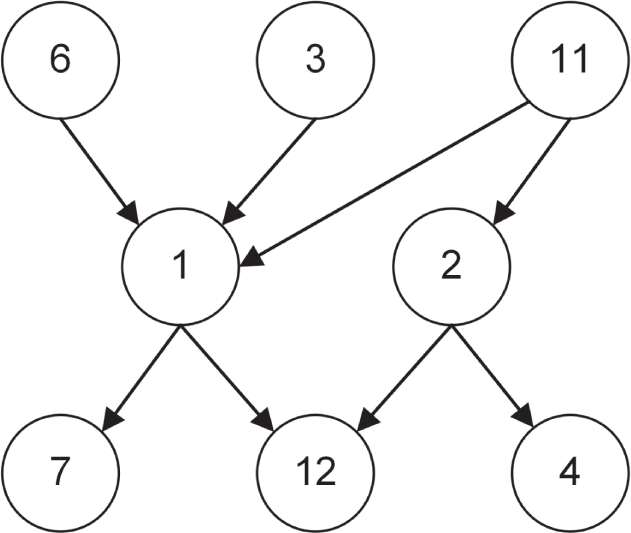
在内存中保存这种数据结构的方法有很多,例如 edge list、adjacency matrix 和 adjacency list。本实现采用的是 adjacency list。所有 node 保存在一个 vector 中,而每个 node 都携带一份 adjacency list,用来列出与它相邻的 node。来看一个小例子。假设你有下图中的这个 directed graph。
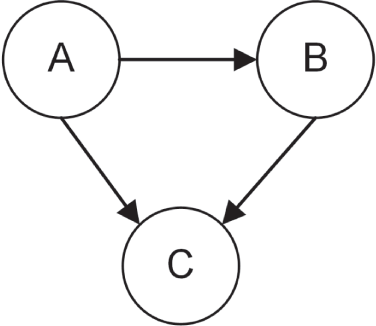
如果使用 adjacency list 来表示它,就会得到如下数据结构:
| NODE | ADJACENCY LIST |
|---|---|
| A | B, C |
| B | C |
| C |
这可以用一个 vector 来存储,其中 vector 的每个元素都代表表中的一行;也就是说,每个 vector 元素对应一个 node 以及它的 adjacency list。下面先从一个基础实现开始,不过暂时不要太在意它是否已经完全符合 Standard Library 的所有要求。这一节会实现一个简单但功能完整的 directed_graph<T>,其中 T 是单个 node 中存储值的类型。directed_graph 中保存的所有值都必须唯一。就实现质量和性能而言,这未必是 directed graph 的最佳方案,但这并不是本章重点。本章真正的重点,是带你走一遍“如何按 Standard Library 的思路来打造一个数据结构”的全过程。
graph_node 类模板
Section titled “graph_node 类模板”directed_graph 的实现基于 node 概念,因此第一段需要实现的代码,就是一个用来表示 graph 中单个 node 的数据结构。一个 node 持有一个值,以及一份相邻 node 的列表;这份相邻列表会保存为一个 set,其中存放的是相邻 node 的索引。使用 set 的好处在于,它能保证 adjacency list 中不会出现重复索引。这个类提供了一个构造函数,用于为给定值构造新的 graph_node,并提供 value() 成员函数用于读取 node 的值。这里只提供 const 版本的 value(),因为一旦值进入图中,就不应再被修改。它的定义位于名为 graph_node.cppm 的 directed_graph:node partition 文件中,位于名为 details 的命名空间内,而且不会从模块中导出,因为 directed_graph 的使用者不应直接操作 graph_node。下面是 graph_node 的接口。注意这里使用了第 1 章介绍过的 [[nodiscard]] attribute:
export module directed_graph:node;…namespace details{ template <typename T> class graph_node { public: // 为给定值构造一个 graph_node。 explicit graph_node(directed_graph<T>* graph, T t) : m_graph { graph }, m_data(std::move(t)) { }
// 返回对所存值的引用。 [[nodiscard]] const T& value() const noexcept { return m_data; }
// 用于存储邻接列表的容器类型的类型别名。 using adjacency_list_type = std::set<std::size_t>;
// 返回对邻接列表的引用。 [[nodiscard]] auto& get_adjacent_nodes_indices() { return m_adjacentNodeIndices; } [[nodiscard]] const auto& get_adjacent_nodes_indices() const { return m_adjacentNodeIndices; } private: // 指向此节点所属图的指针。 directed_graph<T>* m_graph;
T m_data; adjacency_list_type m_adjacentNodeIndices; };}在这份定义里,对模板类型参数 T 没有额外施加任何约束。原因在于:和 vector 一样,元素类型所需满足的要求,本来就应取决于 container 实际执行了哪些操作。
构造函数初始化列表中对 m_data 的初始化使用的是 m_data(std::move(t))。如果改用统一初始化语法 m_data{std::move(t)},则在 T 是 user-defined type 时,有可能无法编译通过。
现在我们已经有了 graph_node 的实现,接着来看看 directed_graph 类本身。
directed_graph 接口
Section titled “directed_graph 接口”directed_graph 支持三种基础操作:插入、删除和查找;此外,它还支持 swap。它定义在 directed_graph 模块中。下面是 directed_graph class template 的 public 部分:
export module directed_graph;…export template <typename T>class directed_graph{ public: // 为了使插入成功,该值不能已在图中。 // 如果已将具有给定值的新节点添加到图中,则返回 true; // 如果已存在具有给定值的节点,则返回 false。 bool insert(T node_value);
// 如果删除了给定的节点值,则返回 true,否则返回 false。 bool erase(const T& node_value);
// 如果成功创建了边,则返回 true,否则返回 false。 bool insert_edge(const T& from_node_value, const T& to_node_value);
// 如果删除了给定的边,则返回 true,否则返回 false。 bool erase_edge(const T& from_node_value, const T& to_node_value);
// 从图中移除所有节点。 void clear() noexcept;
// 返回对具有给定索引的节点中值的引用, // 不进行边界检查。 const T& operator[](std::size_t index) const;
// 如果两个有向图的节点集相等(其中 // 具有相同 T 值的节点被视为相等),并且每对对应节点 // 之间的边数相同,则这两个有向图相等。 // 添加节点和边的顺序不影响 // 相等性。 bool operator==(const directed_graph& rhs) const;
// 交换此图与给定图之间的所有节点。 void swap(directed_graph& other_graph) noexcept;
// 返回图中的节点数量。 [[nodiscard]] std::size_t size() const noexcept;
// 返回一个包含给定节点相邻节点值的集合。 // 如果给定节点不存在,则返回一个空集合。 [[nodiscard]] std::set<T> get_adjacent_nodes_values( const T& node_value) const; private: // 实现细节尚未展示。};元素类型 T 作为模板类型参数传入,这一点与 Standard Library 的 vector container 类似。这个接口本身并不难理解。需要注意的是,它没有定义任何 user-defined copy/move constructor、copy/move assignment operator 或 destructor;也就是说,这个类遵循第 9 章“精通类与对象”讨论过的 Rule of Zero。
接下来看看这些 public 成员函数的具体实现。
在确定好 directed_graph 接口之后,下一步就是选择实现模型。如前所述,这里采用的实现方式是:用一组 node 组成的列表来表示 directed graph,而每个 node 内部又保存自己的值以及一组相邻 node 的索引。由于 adjacency list 里保存的是“其他 node 的索引”,因此 node 本身必须能按索引高效访问。基于这一点,用 vector 来保存所有 node 最合适。每个 node 又由一个 graph_node 实例表示。因此,最终的数据结构就是“一个由 graph_node 组成的 vector”。directed_graph 类中的前几个 private 成员如下:
private: using node_container_type = std::vector<details::graph_node<T>>; node_container_type m_nodes;graph 上的插入与删除操作,都需要先根据 node 的值去查找对应元素。因此,很自然地需要一个 private 辅助成员函数来完成这项工作。这里同时提供 const 和非 const 两个重载:
// 辅助成员函数,返回指向给定节点的迭代器,// 如果给定节点不在图中,则返回 end 迭代器。typename node_container_type::iterator find_node(const T& node_value);typename node_container_type::const_iterator find_node(const T& node_value) const;下面是非 const 版本 find_node() 的实现。const 版本实现完全相同。
template <typename T>typename directed_graph<T>::node_container_type::iterator directed_graph<T>::find_node(const T& node_value){ return std::find_if(std::begin(m_nodes), std::end(m_nodes), [&](const auto& node) { return node.value() == node_value; });}这个成员函数体本身并不复杂。它使用了 Standard Library 中的 find_if() algorithm(第 20 章有详细介绍),在 graph 的全部 node 中寻找一个值等于参数 node_value 的 node。如果找到了,就返回指向该 node 的 iterator;否则返回 end iterator。
函数头里的这段语法看起来可能有点绕,尤其是 typename 关键字的使用。只要你使用的是一个依赖模板参数的类型,就必须写上 typename。这里的 node_container_type::iterator——也就是 vector<details::graph_node<T>>::iterator——就依赖于模板类型参数 T。
insert() 首先必须检查:graph 中是否已经存在某个给定值的 node。如果还不存在,就可以为该值创建一个新 node。public 接口中的 insert() 成员函数按值接收一个 T,这种写法在这里是最优的,也符合第 9 章“向函数传递参数的最佳方式”一节中的建议。对 emplace_back() 的调用会原地构造一个新的 graph_node,并把指向 directed_graph 的指针以及 node 的值传给 graph_node 构造函数:
template <typename T>bool directed_graph<T>::insert(T node_value){ auto iter { find_node(node_value) }; if (iter != std::end(m_nodes)) { // 值已在图中,返回 false。 return false; } m_nodes.emplace_back(this, std::move(node_value)); // 值已成功添加到图中,返回 true。 return true;}一旦 graph 中已经添加了 node,就可以通过在这些 node 之间建立 edge,逐步构造出一个 directed graph。为此,接口提供了 insert_edge() 成员函数,它需要两个参数:一个是 edge 的起点 node 值,另一个是 edge 的终点 node 值。该成员函数首先在 graph 中查找这两个 node;如果任意一个不存在,就返回 false。如果两者都找到了,代码会调用 private 辅助函数 get_index_of_node(),计算出保存 to_node_value 的那个 node 的索引,然后把这个索引添加进保存 from_node_value 的 node 的 adjacency list 中。只有当这次调用真正改变了 graph 时,insert_edge() 才返回 true。还记得第 18 章里提到的:set 上的 insert() 会返回一个 pair<iterator, bool>,其中布尔值表示插入是否成功;正因为如此,这里的 return 语句才会使用 insert() 返回结果的 .second。
template <typename T>bool directed_graph<T>::insert_edge(const T& from_node_value, const T& to_node_value){ const auto from { find_node(from_node_value) }; const auto to { find_node(to_node_value) }; if (from == std::end(m_nodes) || to == std::end(m_nodes)) { return false; } const std::size_t to_index { get_index_of_node(to) }; return from->get_adjacent_nodes_indices().insert(to_index).second;}辅助成员函数 get_index_of_node() 的实现如下:
template <typename T>std::size_t directed_graph<T>::get_index_of_node( typename node_container_type::const_iterator node) const noexcept{ return node - std::cbegin(m_nodes);}erase() 的模式与 insert() 类似:它首先通过 find_node() 尝试查找给定 node;如果该 node 存在,就把它从 graph 中删除;否则什么都不做。删除现有 node 实际上分两步进行:
- 从所有其他 node 的 adjacency list 中移除这个待删除 node 的索引。
- 再把这个 node 本身从 node 列表中删除。
为了完成第一步,我们在 graph_node 中加入一个辅助成员函数 remove_node_index()。它负责从某个 node 的 adjacency list 中删除指定的 node 索引,并同步更新其余索引,以反映 node 删除后索引发生的偏移。它的实现如下。其中一个容易踩坑的点在于:adjacency list 是一个 set,而 set 不允许原地修改其值。因此,下面实现中的第二步会先把 set 转换为 vector,再用 for_each() algorithm 更新那些需要调整的索引,最后清空原来的 set,并把更新后的索引重新插回去。还是那句话,这不一定是最高性能的实现方式,但这并不是本章关注重点。
template <typename T>void graph_node<T>::remove_node_index(std::size_t node_index){ // 首先,移除对待删除节点的引用。 m_adjacentNodeIndices.erase(node_index);
// 其次,修改所有邻接索引,以反映节点的移除。 // std::set 不允许我们原地修改其元素, // 所以我们从头重建这个集合。 std::vector<std::size_t> indices(std::begin(m_adjacentNodeIndices), std::end(m_adjacentNodeIndices)); std::for_each(std::begin(indices), std::end(indices), [node_index](std::size_t& index) { if (index > node_index) { --index; } }); m_adjacentNodeIndices.clear(); m_adjacentNodeIndices.insert(std::begin(indices), std::end(indices));}接着,在 directed_graph 中加入辅助成员函数 remove_all_links_to()。它会在 graph 中删除某个 node 后,负责更新所有剩余 node 中的相邻索引。函数首先计算给定 node 在 node vector 中的索引 node_index,然后遍历所有 node,把各自 adjacency list 中的这个索引移除掉。
template <typename T>void directed_graph<T>::remove_all_links_to( typename node_container_type::const_iterator node_iter){ const std::size_t node_index { get_index_of_node(node_iter) }; for (auto&& node : m_nodes) { node.remove_node_index(node_index); }}有了这个辅助函数,真正的 erase() 成员函数实现就非常直接了:
template <typename T>bool directed_graph<T>::erase(const T& node_value){ auto iter { find_node(node_value) }; if (iter == std::end(m_nodes)) { return false; } remove_all_links_to(iter); m_nodes.erase(iter); return true;}删除 edge 的流程与添加它们非常相似。如果起点 node 或终点 node 任意一个不存在,则什么也不做;否则,就从保存 from_node_value 的 node 的 adjacency list 中移除值为 to_node_value 的那个 node 的索引:
template <typename T>bool directed_graph<T>::erase_edge(const T& from_node_value, const T& to_node_value){ const auto from { find_node(from_node_value) }; const auto to { find_node(to_node_value) }; if (from == std::end(m_nodes) || to == std::end(m_nodes)) { return false; // 没有什么可删除的 } const std::size_t to_index { get_index_of_node(to) }; from->get_adjacent_nodes_indices().erase(to_index); return true;}移除全部元素
Section titled “移除全部元素”clear() 只是简单地把整个 graph 清空:
template <typename T>void directed_graph<T>::clear() noexcept{ m_nodes.clear();}由于 directed_graph 只有一个数据成员,也就是一个 vector container,因此交换两个 directed_graph,本质上就是交换它们各自唯一的数据成员:
template <typename T>void directed_graph<T>::swap(directed_graph& other_graph) noexcept{ m_nodes.swap(other_graph.m_nodes);}此外还提供了一个独立导出的 swap() 函数,它只是简单地转发给 public swap() 成员函数:
export template <typename T>void swap(directed_graph<T>& first, directed_graph<T>& second) noexcept{ first.swap(second);}directed_graph 的 public 接口支持通过索引使用 operator[] 访问 node。实现非常直接。和 vector 一样,这个运算符不会对传入索引做任何边界检查:
template <typename T>const T& directed_graph<T>::operator[](std::size_t index) const{ return m_nodes[index].value();}两个 directed_graph 相等,当且仅当它们包含相同的一组 node,并且所有 node 之间的 edge 集合同样相同。这里有个小复杂点:两个 directed_graph 可能是按不同顺序向其中插入 node 构造出来的。因此,实现时不能只是简单比较它们的 m_nodes 数据成员,而需要多做一点工作。
代码首先检查两个 directed_graph 的大小。如果大小不同,它们肯定不可能相同。如果大小相同,代码就遍历其中一个 graph 的全部 node。对每个 node,它都会尝试在另一个 graph 中找到值相同的 node。如果找不到,那么两个 graph 不相等;如果找到了,就通过辅助成员函数 get_adjacent_nodes_values() 把 adjacency node 索引转换成 adjacency node 的值,然后再比较这些值集合是否相等。
template <typename T>bool directed_graph<T>::operator==(const directed_graph& rhs) const{ if (m_nodes.size() != rhs.m_nodes.size()) { return false; }
for (auto&& node : m_nodes) { const auto rhsNodeIter { rhs.find_node(node.value()) }; if (rhsNodeIter == std::end(rhs.m_nodes)) { return false; }
const auto adjacent_values_lhs { get_adjacent_nodes_values( node.get_adjacent_nodes_indices()) }; const auto adjacent_values_rhs { rhs.get_adjacent_nodes_values( rhsNodeIter->get_adjacent_nodes_indices()) }; if (adjacent_values_lhs != adjacent_values_rhs) { return false; } } return true;}
template <typename T>std::set<T> directed_graph<T>::get_adjacent_nodes_values( const typename details::graph_node<T>::adjacency_list_type& indices) const{ std::set<T> values; for (auto&& index : indices) { values.insert(m_nodes[index].value()); } return values;}获取相邻节点
Section titled “获取相邻节点”public 接口提供了一个 get_adjacent_nodes_values() 成员函数,它接收一个“reference-to-const T” 类型的 node_value 参数,并返回一个 set,其中包含与该 node 相邻的所有 node 的值。如果给定的 node 并不存在,则返回一个空的 set。其实现只是复用了上一节中那个接收“索引列表”的 get_adjacent_nodes_values() 重载:
template <typename T>std::set<T> directed_graph<T>::get_adjacent_nodes_values(const T& node_value) const{ auto iter { find_node(node_value) }; if (iter == std::end(m_nodes)) { return {}; } return get_adjacent_nodes_values(iter->get_adjacent_nodes_indices());}查询图的大小
Section titled “查询图的大小”最后,size() 成员函数会返回 graph 中 node 的数量:
template <typename T>std::size_t directed_graph<T>::size() const noexcept{ return m_nodes.size();}graph 可以输出为一种标准格式,叫作 DOT,它是一种 graph description language。有不少工具能够理解 DOT 格式的 graph,并把它们转换成图形表示。为了让 directed_graph 更容易测试,可以使用下面这个 to_dot() 转换函数。下一节会给出它的使用示例。
// 返回 DOT 格式的给定图。export template <typename T>std::string to_dot(const directed_graph<T>& graph, std::string_view graph_name){ std::ostringstream output; std::println(output, "digraph {} {{", graph_name); for (std::size_t index { 0 }; index < graph.size(); ++index) { const auto& node_value { graph[index] }; const auto adjacent_values { graph.get_adjacent_nodes_values(node_value) }; if (adjacent_values.empty()) { std::println(output, "{}", node_value); } else { for (auto&& neighbor : adjacent_values) { std::println(output, "{} -> {}", node_value, neighbor); } } } std::println(output, "}}"); return std::move(output).str();}使用基础版有向图
Section titled “使用基础版有向图”到这里,我们已经完成了一个基础版 directed graph class 的完整实现。现在很适合真正跑一下,看看它的表现。下面这个小程序展示了基础版 directed_graph class template 的用法:
directed_graph<int> graph;// 插入一些节点和边。graph.insert(11);graph.insert(22);graph.insert(33);graph.insert(44);graph.insert(55);graph.insert_edge(11, 33);graph.insert_edge(22, 33);graph.insert_edge(22, 44);graph.insert_edge(22, 55);graph.insert_edge(33, 44);graph.insert_edge(44, 55);println("{}", to_dot(graph, "Graph1"));
// 移除一条边和一个节点。graph.erase_edge(22, 44);graph.erase(44);println("{}", to_dot(graph, "Graph1"));
// 打印图的大小。println("Size: {}", graph.size());输出如下:
digraph Graph1 {11 -> 3322 -> 3322 -> 4422 -> 5533 -> 4444 -> 5555}digraph Graph1 {11 -> 3322 -> 3322 -> 553355}Size: 4让 directed_graph 成为符合标准库约定的容器
Section titled “让 directed_graph 成为符合标准库约定的容器”前面几节实现的基础版 directed_graph,已经在精神上接近 Standard Library,但从严格意义上说,它还不完全满足 Standard Library 的要求。对大多数用途来说,前面的实现其实已经足够好了。不过,如果你想让自己的 directed_graph 真正可以和 Standard Library algorithms 一起工作,那么还需要再补一点功夫。C++ 标准明确规定:一个 class template 若想被视为 Standard Library container,就必须提供一组特定的成员函数和类型别名。
必需的类型别名
Section titled “必需的类型别名”C++ 标准要求每一个 Standard Library container 都要在 public 部分提供以下类型别名:
| TYPE NAME | DESCRIPTION |
|---|---|
| value_type | container 中保存的元素类型 |
| reference | 对 container 中元素类型的引用 |
| const_reference | 对 container 中元素类型的引用到 const 形式 |
| iterator | 用于遍历 container 元素的 iterator 类型 |
| const_iterator | 用于遍历 const 元素的 iterator 版本 |
| size_type | 能表示 container 中元素个数的类型;通常就是 size_t(来自 <cstddef>) |
| difference_type | 能表示该 container 中两个 iterator 差值的类型;通常就是 ptrdiff_t(来自 <cstddef>) |
下面给出 directed_graph class template 中这些类型别名的定义,其中 iterator 和 const_iterator 暂时先不展示;因为编写 iterator 的内容会在本章后面单独展开。
export template <typename T>class directed_graph{ public: using value_type = T; using reference = value_type&; using const_reference = const value_type&; using size_type = std::size_t; using difference_type = std::ptrdiff_t; // 为简洁起见,省略了类的其余定义。};有了这些类型别名之后,某些成员函数就可以写得更贴近 Standard Library 风格。例如,前面 operator[] 的定义是:
const T& operator[](std::size_t index) const;有了新的类型别名后,它就可以写成:
const_reference operator[](size_type index) const;必需的成员函数
Section titled “必需的成员函数”除了必须提供的类型别名之外,每个 container 还必须提供下列成员函数:
| MEMBER FUNCTION | DESCRIPTION | WORST-CASE COMPLEXITY |
|---|---|---|
| Default constructor | 构造一个空 container | Constant |
| Copy constructor | 对 container 做深拷贝 | Linear |
| Move constructor | 执行 move construction | Constant |
| Copy assignment operator | 对 container 做深拷贝赋值 | Linear |
| Move assignment operator | 执行 move assignment | Constant |
| Destructor | 销毁 container 中剩余元素,并释放其占用的 heap memory(如果有) | Linear |
iterator begin();const_iterator begin() const; | 返回指向 container 首元素的 iterator 或 const iterator | Constant |
iterator end();const_iterator end() const; | 返回指向“尾后位置”的 iterator 或 const iterator | Constant |
const_iterator cbegin() const; | 等价于 begin() const | Constant |
const_iterator cend() const; | 等价于 end() const | Constant |
operator== | 比较两个 container 是否相等 | Linear |
void swap(Container&) noexcept; | 交换当前对象与传入 container 的内容 | Constant |
size_type size() const; | 返回 container 中元素个数 | Constant |
size_type max_size() const; | 返回 container 可容纳的最大元素数量 | Constant |
bool empty() const; | 返回 container 是否为空 | Constant |
如前所述,directed_graph 的实现遵循 Rule of Zero(见第 9 章);也就是说,它不需要显式定义 copy/move constructor、copy/move assignment operator 或 destructor。
下面这段代码给出了 size()、max_size() 和 empty() 成员函数的声明。与 iterator 相关的成员函数——begin()、end()、cbegin() 和 cend()——会在下一节关于 iterator 的内容中介绍。
export template <typename T>class directed_graph{ public: [[nodiscard]] size_type size() const noexcept; [[nodiscard]] size_type max_size() const noexcept; [[nodiscard]] bool empty() const noexcept; // 为简洁起见,省略了其他成员函数。};这三个成员函数的实现都非常简单,因为它们都只是把调用转发给 m_nodes container 上对应的同名成员函数即可。注意,size_type 是在 class template 中定义的类型别名。由于它是 class template 的成员,因此在实现中使用这种返回类型时,必须通过 typename directed_graph<T> 进行完整限定。
template <typename T>typename directed_graph<T>::size_type directed_graph<T>::size() const noexcept{ return m_nodes.size();}
template <typename T>typename directed_graph<T>::size_type directed_graph<T>::max_size() const noexcept{ return m_nodes.max_size();}
template <typename T>bool directed_graph<T>::empty() const noexcept{ return m_nodes.empty();}当前实现中的 directed_graph 提供了 operator[],允许按索引访问 node。这个运算符和 vector 上的 operator[] 一样,不做边界检查;如果传入越界索引,程序就可能崩溃。与 vector 类似,directed_graph 也可以补充一个带边界检查的 at() 成员函数:如果传入索引越界,就抛出 std::out_of_range 异常。其定义如下:
const_reference at(size_type index) const;实现只需要直接转发给 m_nodes vector:
template <typename T>typename directed_graph<T>::const_reference directed_graph<T>::at(size_type index) const{ return m_nodes.at(index).value();}对 container 来说,最重要的要求之一就是 iterator 支持。要想与泛型 algorithms 配合使用,每个 container 都必须提供一种 iterator 类型,用来访问其中元素。通常你的 iterator 至少要提供重载的 operator++、*、-> 和 ==,以及若干其他与其行为相关的操作。只要 iterator 提供了基础迭代能力,一切通常都会正常工作。
关于 iterator,首先要做的第一个决定是:它属于哪一种 iterator?是 forward、bidirectional、random access,还是 contiguous?对于 directed_graph 来说,支持 bidirectional iterator 看起来是个不错的选择。这意味着你还需要额外提供 operator--。另一种方案是为 directed_graph 实现 random-access iterator,那就需要再额外支持 +、-、+=、-=、<、>、<=、>= 和 []。如果你想练习编写 iterator,这其实是个不错的扩展题。关于 random-access iterator 的要求,可以参考第 17 章。
第二个要决定的问题是:container 中元素的遍历顺序应该是什么?directed_graph 本身并不排序,因此若强行按某种有序方式迭代,效率并不好。对于符合 Standard Library 约定的 container 来说,真正重要的是:从 begin() 迭代到 end() 时,应该能恰好访问到每一个元素一次;至于它是以哪种具体顺序访问,并不那么重要。因此,directed_graph iterator 完全可以简单地按照 node 被插入 graph 时的顺序逐个遍历。这一点与 std::unordered_set 的迭代方式类似。
第三个要决定的问题,是 iterator 在内部该如何表示。通常,iterator 的内部表示会与 container 的内部实现高度相关。iterator 的首要职责,是指向 container 中某个具体元素。在 directed_graph 的实现中,所有 node 都保存在 m_nodes 这个 vector 中。因此,一个很自然的想法是:directed_graph iterator 可以包装一个 vector iterator,让它指向当前所需的元素。
一旦实现方式定下来,你还要为 end iterator 决定一个一致的表示方式。要记住,end iterator 真正表示的是“尾后位置”:也就是对一个指向最后元素的 iterator 再执行一次 ++ 后得到的位置。对 directed_graph 来说,可以直接把 m_nodes vector 的 end iterator 当作自身的 end iterator。
最后,container 还必须同时提供 iterator 和 const_iterator 类型别名。本实现把这两者都定义为 const_directed_graph_iterator_impl class template 的别名。原因在于:一旦某个值进入 graph,就不应该再被修改。这与 std::set 所遵循的原则完全一致。
如果你在实现自己的数据结构时,确实需要分别提供独立的 iterator 和 const_iterator 类型,那么请记住:iterator 必须能够隐式转换成 const_iterator。
const_directed_graph_iterator_impl 类模板
Section titled “const_directed_graph_iterator_impl 类模板”基于上一节做出的这些决定,现在就可以正式定义 const_directed_graph_iterator_impl class template 了。首先要注意的是:每一个 const_directed_graph_iterator_impl 对象,都是针对某个特定 directed_graph 实例化类型的 iterator。为了维持这种一一对应关系,const_directed_graph_iterator_impl 自己也必须是一个 class template,并把对应的 graph 类型作为模板类型参数传入,这个参数名叫 DirectedGraph。
接下来的核心问题是:如何让它满足 bidirectional iterator 的要求?请记住,只要某个对象“行为上像 iterator”,它就是 iterator。你的 iterator 不需要继承自某个基类,才能被视为 bidirectional iterator。但如果你希望它能被 generic algorithms 使用,就必须正确提供它的 traits。第 17 章介绍过:iterator_traits 是一个 class template,它会为每种 iterator 类型定义五个类型别名:value_type、difference_type、iterator_category、pointer 和 reference。而 iterator_traits 的默认实现,实际上只是直接从 iterator 本身抓取这五个类型别名。因此,你只需要直接在 iterator 类中定义这些类型别名即可。const_directed_graph_iterator_impl 是一个 bidirectional iterator,所以它的 iterator category 应设为 bidirectional_iterator_tag。其他合法的 iterator category 还包括 input_iterator_tag、output_iterator_tag、forward_iterator_tag、random_access_iterator_tag 和 contiguous_iterator_tag。其中 contiguous iterator 是一种特殊的 random-access iterator,它要求逻辑上相邻的元素在内存里也真正相邻。对 const_directed_graph_iterator_impl 而言,其元素类型(value_type)就是 typename DirectedGraph::value_type。
下面是 const_directed_graph_iterator_impl class template 的定义:
template <typename DirectedGraph>class const_directed_graph_iterator_impl{ public: using value_type = typename DirectedGraph::value_type; using difference_type = std::ptrdiff_t; using iterator_category = std::bidirectional_iterator_tag; using pointer = const value_type*; using reference = const value_type&; using node_container_iterator = typename DirectedGraph::node_container_type::const_iterator;
// 双向迭代器必须提供一个默认构造函数。 const_directed_graph_iterator_impl() = default;
explicit const_directed_graph_iterator_impl(node_container_iterator it);
reference operator*() const;
// 返回类型必须是可以应用 -> 的某种东西。 // 因此,返回一个指针。 pointer operator->() const;
const_directed_graph_iterator_impl& operator++(); const_directed_graph_iterator_impl operator++(int);
const_directed_graph_iterator_impl& operator--(); const_directed_graph_iterator_impl operator--(int);
// 默认的 operator==。 bool operator==(const const_directed_graph_iterator_impl&) const = default;
private: friend class directed_graph<value_type>;
node_container_iterator m_nodeIterator;};如果你对重载运算符这些定义与后面实现看得有点晕,可以回顾一下第 15 章的 operator overloading。const_directed_graph_iterator_impl 不需要自定义 copy/move constructor,也不需要自定义 copy/move assignment operator,因为默认行为正是我们想要的。它也不需要显式 destructor,因为没有任何额外资源需要清理。因此,这个类同样遵循 Rule of Zero。
const_directed_graph_iterator_impl 成员函数实现
Section titled “const_directed_graph_iterator_impl 成员函数实现”const_directed_graph_iterator_impl 的构造函数只是初始化其数据成员:
template <typename DirectedGraph>const_directed_graph_iterator_impl<DirectedGraph>:: const_directed_graph_iterator_impl(node_container_iterator it) : m_nodeIterator { it } { }默认构造函数被显式 default 掉,这样使用者就可以声明 const_directed_graph_iterator_impl 变量而暂时不初始化。一个通过默认构造函数构造出来的 iterator,不必指向任何有效值;而对它执行任何操作,都允许产生未定义结果。
解引用运算符的实现非常简洁,但看起来可能稍微有点绕。第 15 章解释过:operator* 和 operator-> 是不对称的:
operator*返回的是对实际底层值的引用;在这里,也就是 iterator 当前所指向元素的引用。operator->则必须返回某个“还可以继续应用箭头运算符”的东西,因此它返回的是指向元素的指针。编译器随后再对这个指针应用->,从而访问元素的字段或成员函数。
// 返回对实际元素的引用。template <typename DirectedGraph>typename const_directed_graph_iterator_impl<DirectedGraph>::reference const_directed_graph_iterator_impl<DirectedGraph>::operator*() const{ return m_nodeIterator->value();}
// 返回指向实际元素的指针,以便编译器可以// 对其应用 -> 来访问实际所需的字段。template <typename DirectedGraph>typename const_directed_graph_iterator_impl<DirectedGraph>::pointer const_directed_graph_iterator_impl<DirectedGraph>::operator->() const{ return &m_nodeIterator->value();}下面是递增运算符的实现。递减运算符与之完全类似,因此不再展开。
template <typename DirectedGraph>const_directed_graph_iterator_impl<DirectedGraph>& const_directed_graph_iterator_impl<DirectedGraph>::operator++(){ ++m_nodeIterator; return *this;}
template <typename DirectedGraph>const_directed_graph_iterator_impl<DirectedGraph> const_directed_graph_iterator_impl<DirectedGraph>::operator++(int){ auto oldIt { *this }; ++*this; return oldIt;}iterator 并不要求比原始指针更安全,因此像“对已经到达末尾的 iterator 继续执行递增”这种错误情况,不要求额外做防御性检查。
const_directed_graph_iterator_impl 中的类型别名 node_container_iterator,用到了 directed_graph 的私有类型别名 node_container_type。因此,directed_graph class template 必须把 const_directed_graph_iterator_impl 声明为 friend:
export template <typename T>class directed_graph{ // 为简洁起见,省略了其他成员函数。 private: friend class const_directed_graph_iterator_impl<directed_graph>;};迭代器类型别名与访问成员函数
Section titled “迭代器类型别名与访问成员函数”为 directed_graph 提供 iterator 支持的最后一块拼图,就是在 directed_graph class template 中补齐必要的类型别名,并实现 begin()、end()、cbegin() 和 cend() 成员函数。对应的类型别名和函数原型如下:
export template <typename T>class directed_graph{ public: // 为简洁起见,省略了其他类型别名。 using iterator = const_directed_graph_iterator_impl<directed_graph>; using const_iterator = const_directed_graph_iterator_impl<directed_graph>;
// 迭代器成员函数。 iterator begin() noexcept; iterator end() noexcept; const_iterator begin() const noexcept; const_iterator end() const noexcept; const_iterator cbegin() const noexcept; const_iterator cend() const noexcept; // 为简洁起见,省略了类的其余定义。};iterator 与 const_iterator 都是 const_directed_graph_iterator_impl 的类型别名。这意味着:通过 directed_graph iterator 引用到的值,用户是无法修改的。由于 directed_graph 中的 node 值必须唯一,如果允许用户通过 iterator 修改 node 的值,就有可能引入重复值。这与 std::set 的原则完全一致——你同样不能通过 std::set 的 iterator 修改元素值。
由于 iterator 和 const_iterator 都是 const_directed_graph_iterator_impl 的别名,所以从严格意义上讲,返回 iterator 的非 const begin() 和 end() 并不是必须的;只保留 const 版本就够了。但 Standard Library 的要求规定,container 必须同时提供非 const begin() 与 end() 重载。
directed_graph class template 内部用一个简单的 vector 保存所有 node。因此,begin() 和 end() 完全可以直接把工作转发给 vector 上同名成员函数,然后再把结果包装成 const_directed_graph_iterator_impl:
template <typename T>typename directed_graph<T>::iterator directed_graph<T>::begin() noexcept { return iterator{ std::begin(m_nodes) }; }
template <typename T>typename directed_graph<T>::iterator directed_graph<T>::end() noexcept { return iterator { std::end(m_nodes) }; }
template <typename T>typename directed_graph<T>::const_iterator directed_graph<T>::begin() const noexcept{ return const_iterator { std::begin(m_nodes) }; }
template <typename T>typename directed_graph<T>::const_iterator directed_graph<T>::end() const noexcept{ return const_iterator { std::end(m_nodes) }; }cbegin() 和 cend() 则只是把请求转发给 begin() 和 end() 的 const 重载:
template <typename T>typename directed_graph<T>::const_iterator directed_graph<T>::cbegin() const noexcept { return begin(); }
template <typename T>typename directed_graph<T>::const_iterator directed_graph<T>::cend() const noexcept { return end(); }修改其他成员函数以使用迭代器
Section titled “修改其他成员函数以使用迭代器”现在 directed_graph 已经支持 iterator 了,因此其他一些成员函数也可以稍作调整,以便更贴近 Standard Library 风格。先来看 insert()。在前面那个基础实现中,它的定义如下:
// For an insert to be successful, the value shall not be in the graph yet.// 如果已将具有给定值的新节点添加到图中,则返回 true;// 如果已存在具有给定值的节点,则返回 false。bool insert(T node_value);为了更符合 Standard Library 的精神,我们可以把它改为返回 std::pair<iterator, bool>:其中布尔值为 true 表示元素被成功加入 graph,false 表示该元素原本就已经存在;而 pair 中的 iterator,则会指向“新插入的元素”或者“原本就存在的元素”。
std::pair<iterator, bool> insert(T node_value);实现如下。与之前那个只返回 bool 的版本相比,变化处都比较明显:
template <typename T>std::pair<typename directed_graph<T>::iterator, bool> directed_graph<T>::insert(T node_value){ auto iter { find_node(node_value) }; if (iter != std::end(m_nodes)) { // 值已在图中。 return { iterator { iter }, false }; } m_nodes.emplace_back(this, std::move(node_value)); // 值已成功添加到图中。 return { iterator { std::prev(std::end(m_nodes)) }, true };}此外,还可以提供一个带 iterator hint 的 insert() 重载。对 directed_graph 来说,这个 hint 实际上没有意义;但为了与其他 Standard Library container(比如 std::vector)在接口上保持对称,它依然被提供出来。这里会直接忽略这个 hint,然后转发给不带 hint 的 insert() 重载。
template <typename T>typename directed_graph<T>::iterator directed_graph<T>::insert(const_iterator hint, T node_value){ // 忽略提示,直接转发给另一个 insert()。 return insert(std::move(node_value)).first;}最后一个 insert() 重载接受一个 iterator range。这个重载是成员函数模板,因此它不仅能接收来自其他 directed_graph 的 iterator range,也能接收来自任意 container 的 iterator range。具体实现使用了前面提到过的 insert_iterator。
template <typename T>template <std::input_iterator Iter>void directed_graph<T>::insert(Iter first, Iter last){ // 使用 insert_iterator 适配器复制范围内的每个元素。 // 提供 end() 作为虚拟位置——无论如何 insert 都会忽略它。 std::copy(first, last, std::insert_iterator { *this, end() });}erase() 这一组成员函数也应改成与 iterator 协作的风格。前面那个版本的定义是:它以 node 值作为参数,并返回一个 bool:
// 如果删除了给定的节点值,则返回 true,否则返回 false。bool erase(const T& node_value);为了符合 Standard Library 的习惯,directed_graph 现在会提供两个 erase() 成员函数:一个删除某个 iterator 所指向的 node,另一个删除由 iterator range 指定的一整段 node。它们都会返回一个 iterator,指向“最后一个被删除元素之后的那个元素”:
// 返回指向最后一个被删除元素之后的元素的迭代器。iterator erase(const_iterator pos);iterator erase(const_iterator first, const_iterator last);实现如下:
template <typename T>typename directed_graph<T>::iterator directed_graph<T>::erase(const_iterator pos){ if (pos.m_nodeIterator == std::end(m_nodes)) { return end(); } remove_all_links_to(pos.m_nodeIterator); return iterator { m_nodes.erase(pos.m_nodeIterator) };}
template <typename T>typename directed_graph<T>::iterator directed_graph<T>::erase(const_iterator first, const_iterator last){ for (auto iter { first }; iter != last; ++iter) { remove_all_links_to(iter.m_nodeIterator); } return iterator { m_nodes.erase(first.m_nodeIterator, last.m_nodeIterator) };}最后,还可以实现下面这个 public find() 成员函数,它返回一个 iterator。具体实现留作本章末尾练习。
const_iterator find(const T& node_value) const;使用 directed_graph 迭代器
Section titled “使用 directed_graph 迭代器”现在 directed_graph 已经支持 iterator 了,因此你可以像使用其他 Standard Library container 一样遍历它的元素,也可以把这些 iterator 直接传给成员函数或普通函数。下面是一些示例:
directed_graph<int> graph;// 填充图,已省略(参见可下载的源代码存档)…
// 尝试插入一个重复项,并使用结构化绑定接收结果。auto [iter22, inserted] { graph.insert(22) };if (!inserted) { println("Duplicate element."); }
// 使用 for 循环和迭代器打印节点。for (auto iter { graph.cbegin() }; iter != graph.cend(); ++iter) { print("{} ", *iter);}println("");
// 使用非成员函数 cbegin() 和 cend() 获取的迭代器,// 通过 for 循环打印节点。for (auto iter { cbegin(graph) }; iter != cend(graph); ++iter) { print("{} ", *iter);}println("");
// 使用基于范围的 for 循环打印节点。for (auto& node : graph) { print("{} ", node); }println("");
// 使用 find() 标准库算法搜索节点。auto result { find(begin(graph), end(graph), 22) };if (result != end(graph)) { println("Node 22 found.");} else { println("Node 22 NOT found.");}
// 统计所有值 > 22 的节点。auto count { count_if(begin(graph), end(graph), [](const auto& node) { return node > 22; }) };println("{} nodes > 22", count);
// 结合使用 find() 和基于迭代器的 erase() 成员函数。graph.erase(find(begin(graph), end(graph), 44));这段代码同时也说明:由于有了 iterator 支持,directed_graph 现在可以直接与 Standard Library algorithm 配合使用。不过,因为 directed_graph 只支持 const iterator,所以它只支持“不修改元素”的 Standard Library algorithm,这一点与 std::set 相同。例如,下面使用 remove-erase idiom 的代码片段就无法编译:
graph.erase(remove_if(begin(graph), end(graph), [](const auto& node) { return node > 22; }), end(graph));加入对反向迭代器的支持
Section titled “加入对反向迭代器的支持”如果某个 container 提供 bidirectional iterator,它就被视为 reversible。reversible container 还应额外提供两个类型别名:
| TYPE NAME | DESCRIPTION |
|---|---|
| reverse_iterator | 用于按逆序遍历 container 元素的 iterator 类型 |
| const_reverse_iterator | reverse_iterator 的 const 版本 |
此外,这类 container 还应提供与 begin() / end() 对称的 rbegin() / rend(),以及与 cbegin() / cend() 对称的 crbegin() / crend()。
directed_graph 的 iterator 属于 bidirectional iterator,因此它理应支持 reverse iteration。下面的代码片段展示了所需的改动。新增的两个类型别名使用了 Standard Library 中由第 17 章介绍过的 std::reverse_iterator adapter,用于把 directed_graph iterator 转换成 reverse iterator 行为。
export template <typename T>class directed_graph{ public: // 为简洁起见,省略了其他类型别名。 using reverse_iterator = std::reverse_iterator<iterator>; using const_reverse_iterator = std::reverse_iterator<const_iterator>;
// 反向迭代器成员函数。 reverse_iterator rbegin() noexcept; reverse_iterator rend() noexcept; const_reverse_iterator rbegin() const noexcept; const_reverse_iterator rend() const noexcept; const_reverse_iterator crbegin() const noexcept; const_reverse_iterator crend() const noexcept; // 为简洁起见,省略了类的其余定义。};这些 reverse iterator 成员函数的实现如下:
template <typename T>typename directed_graph<T>::reverse_iterator directed_graph<T>::rbegin() noexcept { return reverse_iterator { end() }; }
template <typename T>typename directed_graph<T>::reverse_iterator directed_graph<T>::rend() noexcept { return reverse_iterator { begin() }; }
template <typename T>typename directed_graph<T>::const_reverse_iterator directed_graph<T>::rbegin() const noexcept{ return const_reverse_iterator { end() }; }
template <typename T>typename directed_graph<T>::const_reverse_iterator directed_graph<T>::rend() const noexcept{ return const_reverse_iterator { begin() }; }
template <typename T>typename directed_graph<T>::const_reverse_iterator directed_graph<T>::crbegin() const noexcept { return rbegin(); }
template <typename T>typename directed_graph<T>::const_reverse_iterator directed_graph<T>::crend() const noexcept { return rend(); }下面这段代码展示了如何按逆序打印 graph 中的全部 node:
for (auto iter { graph.rbegin() }; iter != graph.rend(); ++iter) { print("{} ", *iter);}遍历相邻节点
Section titled “遍历相邻节点”directed_graph 内部保存了一个 node vector,其中每个 node 都包含 node 自己的值以及一份相邻 node 列表。接下来我们来改进 directed_graph 的接口,使它能直接遍历某个 node 的相邻 node,而不需要像前面 get_adjacent_nodes_values() 那样,先把这些 node 复制进另一个 container。首先要添加的是一个 const_adjacent_nodes_iterator_impl class template,它遵循与 const_directed_graph_iterator_impl 相同的原则,因此这里不再重复展开,完整代码可参考下载源码包。
下一步,就是扩展 directed_graph 接口,新增一个类型别名、一个用于表示“相邻 node 区间”的辅助结构,以及一个用于获取给定 node 值之相邻 node 的成员函数。如果给定 node 值找不到,nodes_adjacent_to() 成员函数会返回空的 optional。
export template <typename T>class directed_graph{ public: // 为简洁起见,省略了其他类型别名。 using const_adjacent_nodes_iterator = const_adjacent_nodes_iterator_impl<directed_graph>;
// 用于表示相邻节点范围的辅助结构。 struct nodes_adjacent_to_result { const_adjacent_nodes_iterator m_begin; const_adjacent_nodes_iterator m_end; const_adjacent_nodes_iterator begin() const noexcept{ return m_begin; } const_adjacent_nodes_iterator end() const noexcept { return m_end; } };
// 返回给定节点值的相邻节点范围。 std::optional<nodes_adjacent_to_result> nodes_adjacent_to( const T& node_value) const noexcept; // 为简洁起见,省略了类的其余定义。};nodes_adjacent_to() 的实现如下:
template <typename T>std::optional<typename directed_graph<T>::nodes_adjacent_to_result> directed_graph<T>::nodes_adjacent_to(const T& node_value) const noexcept{ auto iter { find_node(node_value) }; if (iter == std::end(m_nodes)) { return {}; } return nodes_adjacent_to_result { const_adjacent_nodes_iterator { std::cbegin(iter->get_adjacent_nodes_indices()), this }, const_adjacent_nodes_iterator { std::cend(iter->get_adjacent_nodes_indices()), this } };}有了 nodes_adjacent_to(),访问某个 node 的所有相邻 node 就变得非常直接了。下面这个例子会打印值为 22 的 node 的全部相邻 node:
print("Adjacency list for node 22: ");auto nodesAdjacentTo22 { graph.nodes_adjacent_to(22) };if (!nodesAdjacentTo22.has_value()) { println("Value 22 not found.");} else { for (const auto& node : *nodesAdjacentTo22) { print("{} ", node); }}Printing Graphs
Section titled “Printing Graphs”现在 directed_graph 已经支持 nodes_adjacent_to(),因此用于打印 graph 的 to_dot() 辅助函数模板也可以进一步简化:
export template <typename T>std::string to_dot(const directed_graph<T>& graph, std::string_view graph_name){ std::ostringstream output; std::println(output, "digraph {} {{", graph_name); for (auto&& node : graph) { auto adjacent_nodes { graph.nodes_adjacent_to(node) }; if (adjacent_nodes->begin() == adjacent_nodes->end()) { std::println(output, "{}", node); } else { for (const auto& adjacent_node : *adjacent_nodes) { std::println(output, "{} -> {}", node, adjacent_node); } } } std::println(output, "}}"); return std::move(output).str();}补充更多类标准库功能
Section titled “补充更多类标准库功能”还可以继续为 directed_graph class template 增加更多接近 Standard Library 风格的功能。首先,我们可以像 vector 那样加入 assign() 成员函数。接收 iterator range 的那个 assign() 仍然是成员函数模板,这和本章前面讲过的“接收 iterator range 的 insert()”是一样的:
template <std::input_iterator Iter>void assign(Iter first, Iter last);
void assign(std::initializer_list<T> il);它们允许你把某个 iterator range 或某个 initializer_list 中的全部元素赋给一个 directed graph。所谓 assignment,就是先清空当前 graph,再插入新的 node。尽管定义看上去复杂,具体实现其实很简单:
template <typename T>template <std::input_iterator Iter>void directed_graph<T>::assign(Iter first, Iter last){ clear(); for (auto iter { first }; iter != last; ++iter) { insert(*iter); }}
template <typename T>void directed_graph<T>::assign(std::initializer_list<T> il){ assign(std::begin(il), std::end(il));}与此同时,也可以给 insert() 增加 initializer_list 重载:
template <typename T>void directed_graph<T>::insert(std::initializer_list<T> il){ insert(std::begin(il), std::end(il));}有了这个 insert() 重载后,向 graph 中添加 node 就可以这样写:
graph.insert({ 66, 77, 88 });接下来,还可以继续加入 initializer_list constructor 和 assignment operator。由于这是 directed_graph 第一次显式定义 constructor 与 assignment operator,因此默认 constructor、copy constructor、move constructor,以及 copy/move assignment operator 也都必须显式 default 掉。
// 默认、拷贝和移动构造函数。directed_graph() = default;directed_graph(const directed_graph&) = default;directed_graph(directed_graph&&) noexcept = default;
// initializer_list 构造函数。directed_graph(std::initializer_list<T> il);
// 拷贝和移动赋值运算符。directed_graph& operator=(const directed_graph&) = default;directed_graph& operator=(directed_graph&&) noexcept = default;
// initializer_list 赋值运算符。directed_graph& operator=(std::initializer_list<T> il);下面是 initializer_list constructor 和 assignment operator 的实现:
template <typename T>directed_graph<T>::directed_graph(std::initializer_list<T> il){ assign(std::begin(il), std::end(il));}
template <typename T>directed_graph<T>& directed_graph<T>::operator=( std::initializer_list<T> il){ // 使用类似 copy-and-swap 的算法来保证强异常安全性。 // 在临时实例中完成所有工作。 directed_graph new_graph { il }; swap(new_graph); // 仅使用不抛出异常的操作提交工作。 return *this;}有了这些支持后,就可以像下面这样,用统一初始化来构造一个 directed_graph:
directed_graph<int> graph { 11, 22, 33 };而不必再写成:
directed_graph<int> graph;graph.insert(11);graph.insert(22);graph.insert(33);同样,你也可以这样给 graph 赋值:
graph = { 66, 77, 88 };借助 initializer_list constructor 和 class template argument deduction(CTAD),你甚至还可以像使用 vector 一样,在构造 directed_graph 时省略元素类型:
directed_graph graph { 11, 22, 33 };还可以再增加一个接收“元素 iterator range”的 constructor。它同样是成员函数模板,和前面接收 iterator range 的 assign() 十分类似。实现也非常简单,只需要把工作转发给 assign():
template <typename T>template <std::input_iterator Iter>directed_graph<T>::directed_graph(Iter first, Iter last){ assign(first, last);}C++23 为大多数 Standard Library container 增加了 insert_range() 成员函数,directed_graph 当然也可以补上。下面这个实现使用 std::ranges::input_range concept 来约束模板类型参数 Range:
template <typename T>template <std::ranges::input_range Range>void directed_graph<T>::insert_range(Range&& range){ insert(std::ranges::begin(range), std::ranges::end(range));}有了 insert_range(),就可以很方便地从任意 range 中插入元素,例如从一个 vector 中插入:
vector moreNodes { 66, 77 };graph.insert_range(moreNodes);最后,还可以再增加一个接收 node 值的 erase() 重载。和 std::set 类似,它返回被删除 node 的数量;对 directed_graph 来说,这个数量只能是 0 或 1。
template <typename T>typename directed_graph<T>::size_type directed_graph<T>::erase( const T& node_value){ const auto iter { find_node(node_value) }; if (iter != std::end(m_nodes)) { remove_all_links_to(iter); m_nodes.erase(iter); return 1; } return 0;}directed_graph class template 还可以继续做不少改进。举几个例子:
- 当前实现不会检查 graph 中是否存在 cycle。你完全可以加入这项检查,让它变成一个 directed acyclic graph。
- 当前实现支持的是 bidirectional iterator,也可以继续扩展成 random-access iterator。
- Standard Library associative containers 支持一系列与 node 相关的功能,详见第 18 章。
directed_graphclass template 也可以进一步扩展,引入node_type类型别名,以及诸如extract()等成员函数。 - 更复杂的一种改进,是像所有 Standard Library container 一样,为它加入 custom allocator 支持。这就要求使用
std::allocator_traits<A>中的 Standard Library 能力,例如construct()、destroy()、propagate_on_container_move_assignment、propagate_on_container_copy_assignment、propagate_on_container_swap等等。
其他容器类型
Section titled “其他容器类型”directed_graph class template 从本质上看更接近 sequential container,但由于 graph 这种结构的性质,它也实现了一些 associative container 的接口风格,例如 insert() 成员函数的返回类型。
当然,你也完全可以去实现纯粹的 sequential container、unordered associative container 或 ordered associative container。如果走那条路,你就必须遵守 Standard Library 对相应类别 container 的一整套具体要求。与其在这里逐条罗列,不如指出几个现成参照物:deque 几乎完整体现了标准规定的 sequential container 要求,唯一额外的区别是它还多提供了一个 resize() 成员函数(这并非标准强制要求);ordered associative container 的一个典型例子是 map,你可以照着它来设计自己的 ordered associative container;而 unordered_map 则是 unordered associative container 的代表例子。
本章介绍了 allocator 的概念,它让你能够定制 container 分配与释放内存的方式。本章也展示了如何编写自己的 algorithm,并让它们能够与 Standard Library container 中的数据配合工作。最后,本章的主体部分几乎完整演示了一个符合 Standard Library 约定的 directed_graph container 的开发过程。得益于 iterator 支持,directed_graph 可以与 Standard Library algorithm 协同工作。
理想情况下,在阅读本章的过程中,你已经对“开发 algorithm 与 container 需要经历哪些步骤”建立起了更深的直觉。即使你今后再也不会自己写一个 Standard Library algorithm 或 container,你也会更理解 Standard Library 的设计心态和能力边界,从而更好地利用它。
本章到这里也结束了整个 C++ Standard Library 的巡礼。即便本书已经涵盖了大量细节,仍有一些特性不得不略去。如果这些内容激起了你的兴趣,并且你还想了解更多,可以参考附录 B中的一些资料。当然,不要觉得必须把这些章节提到的全部特性都强行塞进自己的程序里;如果没有真正需要,硬用只会让代码变得更复杂。不过我仍然鼓励你:在合适的地方,尽量把 Standard Library 的设计思路带入你的程序中。可以先从 container 开始,再逐步加入一两个 algorithm;不知不觉间,你就会成为它的坚定拥护者。
通过完成下面这些练习,你可以巩固本章讨论的内容。所有练习的参考解答都包含在本书网站 www.wiley.com/go/proc++6e 提供的代码下载包中。不过,如果你在某道题上卡住了,建议先回过头重读本章相关部分,尽量自己找到答案,再去看网站上的解答。
- 练习 25-1: 编写一个名为
transform_if()的 algorithm,它与 Standard Library 中第 20 章介绍过的transform()类似。不同之处在于,transform_if()额外接受一个 predicate,并且只对 predicate 返回true的元素进行转换;其余元素保持不变。为了测试你的 algorithm,请创建一个装有整数的array,然后使用transform_if()把这些整数复制到一个vector中,同时把所有奇数值乘以 2。 - 练习 25-2: 编写一个名为
generate_fibonacci()的 algorithm,用于向给定区间填入一段 Fibonacci 数列。1 Fibonacci 数列以 0 和 1 开始,后续每一项都是前两项之和,因此序列为:0、1、1、2、3、5、8、13、21、34、55、89,等等。你的实现中不允许包含手写循环,也不能用递归算法来实现;相反,请使用 Standard Library 的generate()algorithm 来完成主要工作。 - 练习 25-3: 为
directed_graphclass template 实现一个find(const T&)成员函数。 - 练习 25-4: 所有 associative container 都有一个
contains()成员函数:如果给定元素在 container 中,则返回true,否则返回false。既然这对directed_graph也很有用,请为directed_graph加入一个contains()实现。
Footnotes
Section titled “Footnotes”-
两个相邻 Fibonacci 数的比值会逐渐收敛到黄金比例,也就是 1.618034… Fibonacci 数列与黄金比例在自然界中经常出现,例如树木分枝、朝鲜蓟开花、花瓣数量、贝壳形态等等。黄金比例在审美上也很讨人喜欢,因此建筑师常用它来设计房间比例,园林设计中植物布局也经常会借助它。 ↩