处理错误
你的 C++ 程序在运行过程中,几乎不可避免地会遇到错误。例如,程序可能无法打开文件,网络连接可能中断,或者用户输入了错误的值。C++ 语言提供了一项名为 异常(exceptions)的特性,用来处理这类“异常的”,但并非“不可预期的”情况。
到目前为止,本书中的大多数代码示例为了简洁起见,通常都忽略了错误条件。本章会纠正这种简化做法,教你从程序设计一开始就把错误处理纳入其中。本章聚焦于 C++ 异常,包括它们的语法细节,并讲解如何高效地使用异常来构建设计良好的错误处理程序。
本章还会讨论如何编写你自己的异常类。其中包括:如何自动把“异常发生时的精确源代码位置”以及“抛出异常瞬间的完整栈追踪”嵌入异常对象中。这两项信息对于诊断错误都非常有帮助。
没有任何程序是孤立存在的;它们都依赖于外部设施,例如操作系统接口、网络与文件系统、第三方库等外部代码,以及用户输入。这些方面中的每一项,都可能引入需要你响应的问题场景。我们可以用一个总称来指代这些潜在问题:异常情况(exceptional situations)。即使程序写得再完美,也依然会遇到错误和异常情况。因此,任何编写专业软件的人,都必须为程序加入错误处理能力。有些语言(例如 C)并没有提供太多专门的语言级错误处理设施,因此程序员通常依赖函数返回值以及各种临时拼凑的方法。另一些语言(例如 Java)则强制使用一种叫作 异常(exceptions)的语言机制来处理错误。C++ 介于两者之间。它提供了对异常的语言支持,但并不强制你使用它。不过,在 C++ 里你也不能完全忽略异常,因为有少数基础设施(例如内存分配例程)默认就会使用异常,标准库中的不少类同样如此。
异常到底是什么?
Section titled “异常到底是什么?”异常 是一种机制:某段代码可以在不沿着正常代码路径继续执行的情况下,通知另一段代码“出现了异常情况或错误条件”。发现错误的代码会 抛出(throw)异常,而负责处理错误的代码则会 捕获(catch)异常。异常并不遵循你所熟悉的那种“按部就班逐行执行”的基本规则。当一段代码抛出异常时,程序控制流会立刻停止正常的逐步执行,并跳转到某个异常处理器。这个处理器,可能就在同一函数的下一行附近,也可能位于调用栈上方的若干层函数调用之外。如果你喜欢体育类比,可以把“抛出异常”的代码想成外野手把棒球扔回内场,而最近的内野手(也就是最近的异常处理器)把它接住。图 14.1 展示了一个假想的三层函数调用栈。其中 A() 拥有异常处理器;它调用 B(),B() 再调用 C(),而 C() 则抛出了异常。
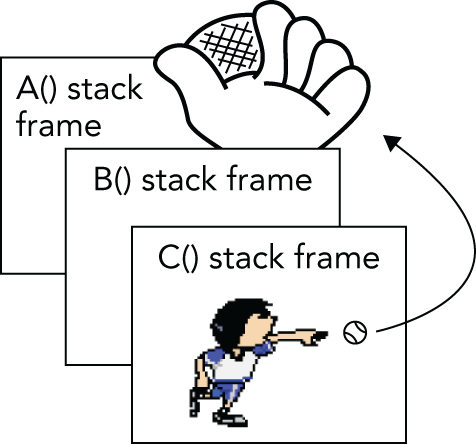
[^图 14.1]
图 14.2 展示了处理器捕获异常之后的状态。此时 C() 和 B() 的栈帧都已被移除,只剩下 A()。
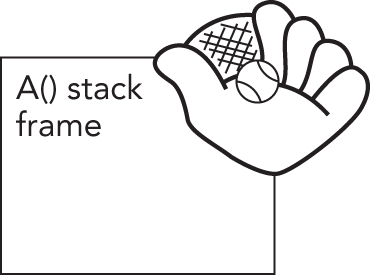
[^图 14.2]
像 C#、Java 这样的现代编程语言大多都支持异常,因此 C++ 具备完整的异常支持并不令人意外。不过,如果你来自 C 语言背景,那么异常对你来说会是全新的东西;但一旦习惯了它们,你大概就不想再回到没有异常的日子了。
为什么 C++ 中的异常是好东西
Section titled “为什么 C++ 中的异常是好东西”正如前面提到的,程序在运行时出现错误几乎不可避免。尽管如此,大多数 C 和 C++ 程序中的错误处理仍然显得杂乱而临时。C 语言事实上的错误处理标准——后来也被许多 C++ 程序沿用——主要依赖函数返回整数错误码,以及 errno 宏。每个线程都有自己独立的 errno 值。errno 本质上就像一个线程局部整数变量,供函数把错误信息传回给调用者。
不幸的是,整数返回码和 errno 的使用方式并不一致。有些函数把 0 视为成功,把 -1 视为出错;如果返回 -1,它们还会同时把 errno 设成某个错误码。另一些函数则把 0 视为成功,把非 0 视为失败,而且返回值本身就是错误码;这类函数又不使用 errno。还有一些函数甚至把 0 当作失败,而不是成功,理由大概只是因为在 C 和 C++ 中,0 总是会被当成 false。
这些不一致会带来问题,因为程序员在接触一个新函数时,往往会想当然地认为它的返回码语义与其他类似函数相同。而现实并非总是如此。举个例子:在 Solaris 11 操作系统上,有两套不同的同步对象库:POSIX 版本和 Solaris 自身版本。POSIX 版中初始化信号量的函数叫 sem_init(),而 Solaris 版中对应的函数叫 sema_init()。单看名字已经够让人头疼了,更糟的是,这两个函数连错误码处理方式都不同!sem_init() 出错时返回 -1 并设置 errno;sema_init() 则直接以正整数形式返回错误码,而且不会设置 errno。
另一个问题在于:函数在 C++ 中只能有一种返回类型。因此,如果你既需要返回一个结果值,又需要返回一个错误信息,就必须另找机制。一种办法是返回 std::pair 或 tuple,它们可以同时容纳两种或多种类型。第 1 章“C++ 与标准库速成”介绍了 pair,而 tuple 会在后续标准库章节中讨论。从 C++23 开始,你还可以从函数返回 std::expected,它既可以保存函数结果,也可以在出错时保存一个错误对象。第 24 章“附加词汇类型”会详细讨论 expected。另一种做法,是定义你自己的 struct 或 class,把多个值装进其中,再把这个对象作为返回值。你也可以通过引用参数返回结果或错误,或者把“错误码”设计成返回类型中的某个特殊值,例如返回 nullptr。但在所有这些方案中,调用者都必须显式检查返回结果里是否有错误;如果它不自己处理错误,就还得把错误继续往上传。更糟的是,这个过程中常常会丢失关于错误的关键信息。
C 程序员也许熟悉 setjmp()/longjmp() 这套机制。但在 C++ 中,它无法被正确使用,因为它会绕过栈上的作用域析构函数。即便是在 C 程序里,你也应当尽一切可能避免使用它;因此,本书不会讲它的具体用法。
异常提供了一种更容易、更一致、也更安全的错误处理机制。相较于 C 和 C++ 中那些临时拼凑的方案,异常有以下几个具体优势:
- 如果使用返回码来报告错误,你很可能会忘记检查返回值,也可能忘记在本地正确处理或向上传播错误。第 1 章介绍过的
[[nodiscard]]属性,确实能在一定程度上防止返回码被忽略,但它也不是万无一失。异常则不会被“忘记”或“忽略”:如果程序没有捕获某个异常,它就会终止。 - 当使用整数返回码时,能够传递的信息通常远远不够。异常则可以让你从发现错误的代码,一路把任意丰富的信息传给处理错误的代码。异常当然也可以被用来传递“不是错误”的信息,不过很多开发者——包括我自己——都认为那是在滥用异常机制。
- 异常处理可以跨越调用栈中的多个层级。也就是说,一个函数可以处理发生在调用栈下方若干层函数中的错误,而中间那些函数都不需要写显式错误处理中转逻辑。若使用返回码,则调用栈上的每一层都必须显式清理上一层遗留的状态,并显式继续传播错误。
在过去,一些编译器会让“带异常处理器的函数”付出一点点额外开销。对大多数现代编译器来说,更常见的权衡是:在不抛出异常的情况下,几乎没有甚至完全没有额外开销;只有当你真的抛出异常时,才会产生一些轻微的成本。这样的权衡并不坏。异常不应用来控制程序的正常执行流程,例如拿它来替代函数返回值。异常应仅用于处理那些在正常程序运行中通常不会发生的事件,例如从磁盘文件读取时失败。这也意味着,与使用错误返回码的实现相比,使用异常反而常常能让“无错路径”的代码更快。
在 C++ 中,异常处理并不是强制的。例如在 Java 中,它是强制机制:一个 Java 函数如果没有声明自己可能抛出的异常列表,就不允许抛出任何异常。而在 C++ 中,情况恰恰相反:一个函数默认可以抛出任意异常,除非它明确用 noexcept 关键字声明“不会抛出任何异常”——本章后面就会讲这个关键字!
我推荐把异常作为一种有用的错误处理机制。我认为,异常所提供的结构化能力和错误处理规范化程度,足以抵消它那些不那么理想的方面。因此,本章后续内容会把重点放在异常上。另外,标准库和 Boost 这类流行库也都使用异常,所以你必须做好处理它们的准备。
在文件输入和输出中,异常情况经常出现。下面这个函数用来打开一个文件,从文件中读取一个整数列表,并把整数放入 std::vector 数据结构中返回。完全缺乏错误处理的代码会让你立刻注意到:
vector<int> readIntegerFile(const string& filename){ ifstream inputStream { filename }; // 逐个读取整数并将其添加到 vector 中。 vector<int> integers; int temp; while (inputStream >> temp) { integers.push_back(temp); } return integers;}下面这行代码持续从 ifstream 中读取值,直到到达文件末尾或发生错误:
while (inputStream>> temp) {如果 >> 运算符遇到错误,它会设置 ifstream 对象的 fail 位。在这种情况下,bool() 转换运算符返回 false,while 循环终止。流在 第 13 章 “解密 C++ I/O” 中有更详细的讨论。
你可以这样使用 readIntegerFile():
const string filename { "IntegerFile.txt" };vector<int> myInts { readIntegerFile(filename) };println("{} ", myInts);本节的其余部分将展示如何使用异常添加错误处理,但首先,我们需要更深入地了解如何抛出和捕获异常。
抛出和捕获异常
Section titled “抛出和捕获异常”使用异常需要在程序中提供两个部分:一个用于处理异常的 try/catch 构造,以及一个抛出异常的 throw 语句。两者必须以某种形式存在才能使异常工作。然而,在许多情况下,throw 发生在某个库(包括 C++ 运行时)的深处,程序员永远看不到它,但仍需要使用 try/catch 构造来做出反应。
try/catch 构造看起来像这样:
try { // … 可能导致抛出异常的代码} catch (exception-type1 exception-name) { // … 响应类型 1 异常的代码} catch (exception-type2 exception-name) { // … 响应类型 2 异常的代码}// … 剩余代码可能导致抛出异常的代码可能直接包含 throw。它也可能调用一个直接抛出异常的函数,或者通过若干层未知调用来调用一个抛出异常的函数。
如果没有抛出异常,则不会执行任何 catch 块中的代码,“剩余代码”将紧随 try 块中最后执行的语句之后。
如果抛出异常,则 throw 后或导致 throw 的调用之后的任何代码都不会被执行;相反,控制立即转到正确的 catch 块,具体取决于抛出的异常类型。
如果 catch 块不执行控制转移——例如,通过从函数返回、抛出新异常或重新抛出捕获的异常——那么在该 catch 块的最后一条语句之后执行”剩余代码”。
演示异常处理的最简单示例是避免除以零。以下示例抛出 std::invalid_argument 类型的异常,定义于 <stdexcept>:
double safeDivide(double num, double den){ if (den == 0) { throw invalid_argument { "Divide by zero" }; } return num / den;}
int main(){ try { println("{}", safeDivide(5, 2)); println("{}", safeDivide(10, 0)); println("{}", safeDivide(3, 3)); } catch (const invalid_argument& e) { println("Caught exception: {}", e.what()); }}输出如下:
2.5Caught exception: Divide by zerothrow 是 C++ 中的关键字,是抛出异常的唯一方式。在代码片段中,我们抛出了 invalid_argument 的新实例。它是 C++ 标准库提供的标准异常之一。标准库中的所有异常都形成一个层次结构,本章稍后讨论。层次结构中的每个类都支持一个 what() 成员函数,返回描述异常的 const char* 字符串。这是你在异常构造函数中提供的字符串。
让我们回到 readIntegerFile() 函数。最可能发生的问题是打开文件失败。这是一个完美的抛出异常的场景。以下代码在文件无法打开时抛出 std::exception 类型的异常,定义于 <exception>:
vector<int> readIntegerFile(const string& filename){ ifstream inputStream { filename }; if (inputStream.fail()) { // 无法打开文件:抛出异常。 throw exception {}; }
// 逐个读取整数并将其添加到 vector 中。 vector<int> integers; int temp; while (inputStream >> temp) { integers.push_back(temp); } return integers;}如果函数无法打开文件并执行 throw exception{}; 语句,则跳过函数的其余部分,控制权转移到最近的异常处理器。
在你的代码中抛出异常最有用的地方,同时也写代码来处理它们。异常处理是一种”尝试”代码块的方式,并指定另一个代码块来对可能发生的问题做出反应。在下面的 main() 函数中,catch 语句对 try 块内抛出的任何 exception 类型的异常做出反应,即打印错误消息。如果 try 块在没有抛出异常的情况下完成,则跳过 catch 块。你可以把 try/catch 块看作是高级版的 if 语句:如果 try 块中抛出了异常,则执行一个 catch 块,否则跳过所有 catch 块。
int main(){ const string filename { "IntegerFile.txt" }; vector<int> myInts; try { myInts = readIntegerFile(filename); } catch (const exception& e) { println(cerr, "Unable to open file {}", filename); return 1; } println("{} ", myInts);}你可以抛出任何类型的异常。前面的示例抛出了 std::exception 类型的对象,但异常不必是对象。你也可以像这样抛出一个简单的 int:
vector<int> readIntegerFile(const string& filename){ ifstream inputStream { filename }; if (inputStream.fail()) { // 我们无法打开文件:抛出一个异常。 throw 5; } // 为简洁起见,此处省略}然后你需要像这样更改 catch 语句:
try { myInts = readIntegerFile(filename);} catch (int e) { println(cerr, "Unable to open file {} (Error Code {})", filename, e); return 1;}或者,你可以抛出一个 const char* C 风格字符串。这种技术有时很有用,因为字符串可以包含关于异常的信息:
vector<int> readIntegerFile(const string& filename){ ifstream inputStream { filename }; if (inputStream.fail()) { // 我们无法打开文件:抛出一个异常。 throw "Unable to open file"; } // 为简洁起见,此处省略}当你捕获 const char* 异常时,可以像这样打印结果:
try { myInts = readIntegerFile(filename);} catch (const char* e) { println(cerr, "{}", e); return 1;}尽管有前面的例子,请记住以下几点:
一般来说,你应该抛出对象而不是其他数据类型作为异常,原因有两个:
- 对象通过类名传递信息。
- 对象可以存储各种信息,包括描述异常的字符串。
C++ 标准库定义了许多预定义的异常类,它们以类层次结构组织,本章稍后讨论。此外,你还可以编写自己的异常类并将它们放入标准层次结构中,本章稍后也会讲到这个。
以引用常量捕获异常对象
Section titled “以引用常量捕获异常对象”在前面的示例中,readIntegerFile() 抛出了 exception 类型的对象,catch 处理程序如下:
} catch (const exception& e) {但是,没有要求必须将对象捕获为引用常量。你也可以像这样按值捕获对象:
} catch (exception e) {或者,你也可以将对象捕获为非 const 引用:
} catch (exception& e) {此外,正如你在前面的 const char* 示例中看到的,只要抛出了异常指针,你就可以捕获指向异常的指针。
不过,我仍然建议遵循以下建议:
抛出和捕获多个异常
Section titled “抛出和捕获多个异常”无法打开文件不是 readIntegerFile() 可能遇到的唯一问题。如果文件格式不正确,从文件读取数据也会导致错误。以下是 readIntegerFile() 的一个实现,如果无法打开文件或无法正确读取数据,它都会抛出异常。这次,它使用 runtime_error,派生自 exception,允许你在其构造函数中指定描述性字符串。runtime_error 异常类定义于 <stdexcept>。
vector<int> readIntegerFile(const string& filename){ ifstream inputStream { filename }; if (inputStream.fail()) { // 无法打开文件:抛出异常。 throw runtime_error { "Unable to open the file." }; }
// 逐个读取整数并将其添加到 vector 中。 vector<int> integers; int temp; while (inputStream >> temp) { integers.push_back(temp); }
if (!inputStream.eof()) { // 未到达文件末尾。 // 这意味着读取文件时发生了某些错误。 // 抛出异常。 throw runtime_error { "Error reading the file." }; }
return integers;}你的 main() 不需要太大改变,因为它已经捕获了 exception 类型的异常,而 runtime_error 派生自 exception。但是,这个异常现在可能在两种不同的情况下抛出,因此我们使用 what() 成员函数来获取所捕获异常的适当描述:
try { myInts = readIntegerFile(filename);} catch (const exception& e) { println(cerr, "{}", e.what()); return 1;}或者,你可以从 readIntegerFile() 抛出两种不同类型的异常。以下是 readIntegerFile() 的一个实现,如果文件无法打开,它抛出一个 invalid_argument 类的异常对象,如果无法读取整数,它抛出一个 runtime_error 类的异常对象。invalid_argument 和 runtime_error 都是 C++ 标准库中 <stdexcept> 定义的类。
vector<int> readIntegerFile(const string& filename){ ifstream inputStream { filename }; if (inputStream.fail()) { // 无法打开文件:抛出异常。 throw invalid_argument { "Unable to open the file." }; }
// 逐个读取整数并将其添加到 vector 中。 vector<int> integers; int temp; while (inputStream >> temp) { integers.push_back(temp); }
if (!inputStream.eof()) { // 未到达文件末尾。 // 这意味着读取文件时发生了某些错误。 // 抛出异常。 throw runtime_error { "Error reading the file." }; }
return integers;}invalid_argument 和 runtime_error 没有公共默认构造函数,只有字符串构造函数,因此你必须始终将字符串作为参数传递。
现在,main() 可以用两个 catch 语句捕获 invalid_argument 和 runtime_error 异常:
try { myInts = readIntegerFile(filename);} catch (const invalid_argument& e) { println(cerr, "{}", e.what()); return 1;} catch (const runtime_error& e) { println(cerr, "{}", e.what()); return 2;}如果 try 块内抛出了异常,编译器会将异常类型与正确的 catch 处理程序匹配。因此,如果 readIntegerFile() 无法打开文件并抛出一个 invalid_argument 对象,它会被第一个 catch 语句捕获。如果 readIntegerFile() 无法正确读取文件并抛出一个 runtime_error,那么第二个 catch 语句会捕获该异常。
匹配与 const
Section titled “匹配与 const”在你想要捕获的异常类型中指定的 const 对匹配没有影响。也就是说,以下代码匹配任何 runtime_error 类型的异常:
} catch (const runtime_error& e) {以下代码也匹配任何 runtime_error 类型的异常:
} catch (runtime_error& e) {不过,仍然建议始终将异常对象捕获为引用常量。
捕获任何异常
Section titled “捕获任何异常”你可以用下面例子中的特殊语法编写一个 catch-all 块,它可以匹配任何可能的异常:
try { myInts = readIntegerFile(filename);} catch (…) { println(cerr, "Error reading or opening file {}", filename); return 1;}这三个点不是拼写错误。它们是一个通配符,可以匹配任何异常类型。使用 catch-all 块的缺点是你无法获得所捕获异常的任何详细信息。当你在调用文档较差的代码时,这种技术可以确保你捕获所有可能的异常。但即使到那时,你怎么可能对一个未知的异常做出有效的恢复呢?
catch-all 块的一个有用用例是记录抛出了异常,然后重新抛出异常。以下示例展示了如何编写显式处理 invalid_argument 和 runtime_error 异常的 catch 处理程序,以及如何包含一个 catch-all 处理程序来处理所有其他异常。在任何 catch 块中,你都可以使用不带任何参数的 throw 关键字重新抛出当前捕获的异常。关于重新抛出异常还有很多要说的,但那得等到本章后面了。
try { // 可能抛出异常的代码。} catch (const invalid_argument& e) { // 处理 invalid_argument 异常。} catch (const runtime_error& e) { // 处理 runtime_error 异常。} catch (…) { // 处理所有其他异常。 // 记录异常发生… throw; // 重新抛出捕获的异常。}在你完全了解可能抛出的异常集合的情况下,不建议使用 catch-all 块,因为它对每种异常类型的处理方式都是相同的。最好显式匹配异常类型并采取适当的针对性行动。
未捕获的异常
Section titled “未捕获的异常”如果你的程序抛出了一个在任何地方都未被捕获的异常,程序就会终止。基本上,在调用你的 main() 函数的外面有一个 try/catch 构造,它会捕获所有未处理的异常,其行为类似于下面的伪代码:
try { main(argc, argv);} catch (…) { // 发布错误消息并终止程序。}// 正常终止代码。然而,这种行为通常不是你想要的。异常的目的是给你的程序一个处理和纠正不良或意外情况的机会。
你应该尽可能捕获并处理程序中抛出的所有异常。
你也可以更改程序在有未捕获异常时的行为。当程序遇到未捕获的异常时,它会调用内置的 terminate() 函数,该函数调用 <cstdlib> 中的 abort() 来终止程序。你可以通过调用 set_terminate() 并传递一个指向不接受任何参数且不返回任何值的函数的指针来设置你自己的 terminate_handler。terminate()、set_terminate() 和 terminate_handler 都在 <exception> 中声明。以下伪代码显示了它的工作原理:
try { main(argc, argv);} catch (…) { if (terminate_handler != nullptr) { terminate_handler(); } else { terminate(); }}// 正常终止代码。在你对这个功能过于兴奋之前,你应该知道你的回调函数仍然必须使用 abort() 或 _Exit() 来终止程序。它不能仅仅忽略错误。abort() 和 _Exit() 都定义在 <cstdlib> 中,它们在不清理资源的情况下终止应用程序。例如,对象的析构函数不会被调用。_Exit() 函数接受一个整数参数,该参数返回给操作系统,可用来确定进程如何退出。值为 0 或 EXIT_SUCCESS 表示程序正常退出;否则,程序异常终止。abort() 函数不接受任何参数。此外,还有一个 exit() 函数也接受一个返回给操作系统的整数,它确实会通过调用析构函数来清理资源,但不建议从 terminate_handler 调用 exit()。
terminate_handler 可用于在退出前打印有用的错误消息。以下是一个 main() 函数的例子,它不捕获 readIntegerFile() 抛出的异常,而是将 terminate_handler 设为自定义回调。该回调打印错误消息并通过调用 _Exit() 终止进程。注意使用 [[noreturn]] 属性,该属性在 第 1 章 中介绍过。
[[noreturn]] void myTerminate(){ println(cerr, "Uncaught exception!"); _Exit(1);}
int main(){ set_terminate(myTerminate);
const string filename { "IntegerFile.txt" }; vector<int> myInts { readIntegerFile(filename) }; println("{} ", myInts);}虽然在例子中没有显示,但 set_terminate() 在设置新的 terminate_handler 时会返回旧的 terminate_handler。terminate_handler 是程序范围的,因此在完成需要新 terminate_handler 的代码后,恢复旧的 terminate_handler 被认为是良好的风格。在这种情况下,整个程序都需要新的 terminate_handler,所以恢复它没有意义。
虽然了解 set_terminate() 很重要,但它并不是一种有效的异常处理方法。建议单独捕获和处理每个异常,以提供更精确的错误处理。
noexcept 说明符
Section titled “noexcept 说明符”默认情况下,函数可以抛出它想要的任何异常。但是,可以用 noexcept 说明符(一个 C++ 关键字)标记函数,声明它不会抛出任何异常。例如,以下函数被标记为 noexcept,因此不允许抛出任何异常:
void printValues(const vector<int>& values) noexcept;当一个被标记为 noexcept 的函数仍然抛出异常时,C++ 会调用 terminate() 来终止应用程序。
当你在派生类中覆盖 virtual 成员函数时,允许将被覆盖的成员函数标记为 noexcept,即使基类中的版本不是 noexcept。反之则不允许。
noexcept(expression) 说明符
Section titled “noexcept(expression) 说明符”noexcept(expression) 说明符在给定表达式返回 true 时将函数标记为 noexcept。换句话说,noexcept 等于 noexcept(true),而 noexcept(false) 与 noexcept(true) 相反;也就是说,用 noexcept(false) 标记的成员函数可以抛出任何异常,这是默认的。
noexcept(expression) 运算符
Section titled “noexcept(expression) 运算符”noexcept(expression) 运算符在给定表达式是 noexcept 时返回 true。这个评估在编译时发生。
例子如下:
void f1() noexcept {}void f2() noexcept(false) {}void f3() noexcept(noexcept(f1())) {}void f4() noexcept(noexcept(f2())) {}
int main(){ println("{} {} {} {}", noexcept(f1()), noexcept(f2()), noexcept(f3()), noexcept(f4()));}这段代码的输出是 true false true false:
noexcept(f1())为true,因为f1()被显式标记为noexcept说明符。noexcept(f2())为false,因为f2()使用noexcept(expression)说明符显式标记为这样。noexcept(f3())为true,因为f3()被标记为noexcept但前提是f1()是noexcept,而它是。noexcept(f4())为false,因为f4()被标记为noexcept但前提是f2()是noexcept,而它不是。
异常规范列表
Section titled “异常规范列表”旧版 C++ 允许你指定函数打算抛出的异常。这个规范称为异常规范列表或异常规范。
C++11 已弃用,C++17 已移除对异常规范列表的支持,除了 noexcept 和 throw()。后者等同于 noexcept。自 C++20 以来,对 throw() 的支持也已移除。
由于 C++17 正式移除了对异常规范列表的支持,本书不再进一步讨论它们。
如前所述,你实际上可以抛出任何类型的异常。但是,类是最有用的异常类型。事实上,异常类通常以层次结构编写,以便在捕获异常时可以采用多态方式处理。
标准异常层次结构
Section titled “标准异常层次结构”你已经看到了 C++ 标准异常层次结构中的几个异常:exception、runtime_error 和 invalid_argument。图 14.3 展示了完整的层次结构。为了完整起见,所有标准异常都显示在其中,包括标准库各部分抛出的异常,这些部分将在后续章节中讨论。
[^图 14.3]
C++ 标准库抛出的所有异常都是这个层次结构中类的对象。层次结构中的每个类都支持一个 what() 成员函数,返回描述异常的 const char* 字符串。你可以在错误消息中使用此字符串。
某些异常类要求你在构造函数中设置由 what() 返回的字符串。这就是为什么你必须在 runtime_error 和 invalid_argument 的构造函数中指定字符串的原因。本章中的例子已经演示了这一点。以下是另一个版本的 readIntegerFile(),它在错误消息中包含了文件名:
vector<int> readIntegerFile(const string& filename){ ifstream inputStream { filename }; if (inputStream.fail()) { // 无法打开文件:抛出异常。 const string error { format("Unable to open file {}.", filename) }; throw invalid_argument { error }; }
// 逐个读取整数并将其添加到 vector 中。 vector<int> integers; int temp; while (inputStream >> temp) { integers.push_back(temp); }
if (!inputStream.eof()) { // 未到达文件末尾。 // 这意味着读取文件时发生了某些错误。 // 抛出异常。 const string error { format("Unable to read file {}.", filename) }; throw runtime_error { error }; }
return integers;}在类层次结构中捕获异常
Section titled “在类层次结构中捕获异常”异常层次结构的一个特性是你可以多态地捕获异常。例如,如果你看一下下面两个 catch 语句,你会发现除了它们处理的异常类之外,它们是完全相同的:
try { myInts = readIntegerFile(filename);} catch (const invalid_argument& e) { println(cerr, "{}", e.what()); return 1;} catch (const runtime_error& e) { println(cerr, "{}", e.what()); return 1;}幸运的是,invalid_argument 和 runtime_error 都是 exception 的派生类,因此你可以用单个 catch 语句替换这两个 catch 语句来处理 exception:
try { myInts = readIntegerFile(filename);} catch (const exception& e) { println(cerr, "{}", e.what()); return 1;}用于 exception 引用的 catch 语句匹配 exception 的任何派生类,包括 invalid_argument 和 runtime_error。请注意,在异常层次结构中越高的地方捕获异常,你的错误处理就越不具体。你应该尽可能在最具体的级别捕获异常。
当你多态地捕获异常时,一定要通过引用捕获它们!如果你按值捕获异常,你可能会遇到切片情况,在这种情况下你会丢失对象中的信息。详情请参见 第 10 章。
当使用多个 catch 子句时,catch 子句按它们在代码中出现的语法顺序匹配;第一个匹配的获胜。如果一个 catch 比后面的更包容,它会先匹配,而限制性更强的那个(后面出现的)将永远不会被执行。因此,你应该按从最严格到最不严格的顺序放置你的 catch 子句。例如,假设你想显式捕获 readIntegerFile() 的 invalid_argument,但你也想为任何其他异常保留通用的 exception 处理程序。正确的做法如下:
try { myInts = readIntegerFile(filename);} catch (const invalid_argument& e) { // List the derived class first. // Take some special action for invalid filenames.} catch (const exception& e) { // Now list exception. println(cerr, "{}", e.what()); return 1;}第一个 catch 语句捕获 invalid_argument 异常,第二个捕获任何其他 exception 类型的异常。但是,如果调换 catch 语句的顺序,你不会得到相同的结果:
try { myInts = readIntegerFile(filename);} catch (const exception& e) { // BUG: catching base class first! println(cerr, "{}", e.what()); return 1;} catch (const invalid_argument& e) { // Take some special action for invalid filenames.}按照这个顺序,任何派生自 exception 的类的异常都会被第一个 catch 语句捕获;第二个 catch 永远不会被执行。有些编译器会在这种情况下发出警告,但你不应该依赖它。
编写你自己的异常类
Section titled “编写你自己的异常类”编写你自己的异常类有两个优势:
- C++ 标准库中的异常数量有限。与使用泛型名称(如
runtime_error)的异常类不同,你可以创建对你的程序中特定错误更有意义的类名的异常。 - 你可以向这些异常添加你自己的信息。标准层次结构中的大多数异常只允许你设置一个错误字符串。你可能希望在异常中传递不同的信息。
建议所有你编写的异常类都直接或间接地继承自标准的 exception 类。如果你项目中的每个人都遵循这条规则,你就会知道程序中的每个异常都派生自 exception(假设你使用的第三方库没有违反这一规则)。这条准则使得通过多态处理异常变得更加容易。
让我们来看一个例子。invalid_argument 和 runtime_error 在 readIntegerFile() 中无法很好地捕获文件打开和读取错误。你可以为文件错误定义你自己的错误层次结构,从一个通用的 FileError 类开始:
class FileError : public exception{ public: explicit FileError(string filename) : m_filename { move(filename) } {} const char* what() const noexcept override { return m_message.c_str(); } virtual const string& getFilename() const noexcept { return m_filename; } protected: virtual void setMessage(string message) { m_message = move(message); } private: string m_filename; string m_message;};作为一个好公民,你让 FileError 成为标准异常层次结构的一部分。把它集成为 exception 的子节点似乎是合适的。当你从 exception 派生时,你可以覆盖 what() 成员函数,它具有所示的原型,必须返回一个 const char* 字符串,该字符串在对象被销毁之前有效。在 FileError 的情况下,这个字符串来自 m_message 数据成员。FileError 的派生类可以使用受保护的 setMessage() 成员函数来设置消息。通用的 FileError 类还包含文件名和该文件名的公共访问器。
readIntegerFile() 中的第一个异常情况发生在文件无法打开时。因此,你可能希望编写一个从 FileError 派生的 FileOpenError 异常:
class FileOpenError : public FileError{ public: explicit FileOpenError(string filename) : FileError { move(filename) } { setMessage(format("Unable to open {}.", getFilename())); }};FileOpenError 异常调用 setMessage() 将 m_message 字符串更改为表示文件打开错误。注意,在构造函数体中,getFilename() 用于获取文件名。参数不能用于此,因为 ctor-initializer 已在调用 FileError 构造函数时将 filename 移到了其中。如你所知,在移动操作之后,你不应该再使用一个对象。
readIntegerFile() 中的第二个异常情况是文件无法正确读取。这个异常可能需要在错误消息字符串中包含发生错误的行号,以及文件名,这些来自 what()。这里有一个从 FileError 派生的 FileReadError 异常:
class FileReadError : public FileError{ public: explicit FileReadError(string filename, size_t lineNumber) : FileError { move(filename) }, m_lineNumber { lineNumber } { setMessage(format("Error reading {}, line {}.", getFilename(), lineNumber)); }
virtual size_t getLineNumber() const noexcept { return m_lineNumber; } private: size_t m_lineNumber { 0 };};当然,为了正确设置行号,readIntegerFile() 需要被修改为跟踪已读取的行数,而不是直接读取整数。以下是使用新异常的 readIntegerFile() 函数:
vector<int> readIntegerFile(const string& filename){ ifstream inputStream { filename }; if (inputStream.fail()) { // We failed to open the file: throw an exception. throw FileOpenError { filename }; }
vector<int> integers; size_t lineNumber { 0 }; while (!inputStream.eof()) { // Read one line from the file. string line; getline(inputStream, line); ++lineNumber;
// Create a string stream out of the line. istringstream lineStream { line };
// Read the integers one-by-one and add them to the vector. int temp; while (lineStream >> temp) { integers.push_back(temp); }
if (!lineStream.eof()) { // We did not reach the end of the string stream. // This means that some error occurred while reading this line. // Throw an exception. throw FileReadError { filename, lineNumber }; } }
return integers;}现在,调用 readIntegerFile() 的代码可以使用多态来捕获 FileError 类型的异常,如下所示:
try { myInts = readIntegerFile(filename);} catch (const FileError& e) { println(cerr, "{}", e.what()); return 1;}在编写将被用作异常的对象的类时,有一个注意事项。当一段代码抛出一个异常时,被抛出的对象或值会使用移动构造函数或复制构造函数被移动或复制。因此,如果你编写一个类,其对象将作为异常抛出,你必须确保这些对象是可复制和/或可移动的。这意味着,如果你的异常类中有动态分配的内存,你的类必须有一个析构函数,但还必须有复制构造函数和复制赋值运算符和/或移动构造函数和移动赋值运算符,参见 第 9 章 “类和对象精要”。
作为异常抛出的对象总是会被移动或复制至少一次。
异常可能被复制多次,但只有在你按值而不是按引用捕获异常时才会发生。
可能在处理第一个异常时,触发第二个异常情况需要抛出第二个异常。不幸的是,当你抛出第二个异常时,你正在处理的第一个异常的所有信息都会丢失。C++ 为这个问题提供的解决方案称为嵌套异常,它允许你将捕获的异常嵌套在新异常的上下文中。如果你调用一个第三方库的函数,它抛出一个某类型的异常 A,但你只想要你的代码中的另一种类型的异常 B,这也很有用。在这种情况下,你捕获库中的所有异常并将它们嵌套在类型 B 的异常中。
你可以使用 std::throw_with_nested() 抛出一个内部嵌套了另一个异常的异常。 catch 处理程序可以使用 dynamic_cast() 获取对表示第一个异常的 std::nested_exception 的访问。接下来的例子演示了这一点。它首先定义了一个 MyException 类,它从 exception 派生并在构造函数中接受一个字符串:
class MyException : public exception{ public: explicit MyException(string message) : m_message { move(message) } {} const char* what() const noexcept override { return m_message.c_str(); } private: string m_message;};以下 doSomething() 函数抛出一个 runtime_error,它立即在 catch 处理程序中被捕获。catch 处理程序写一条消息,然后使用 throw_with_nested() 函数抛出第二个异常,第一个异常嵌套在其中。注意,嵌套异常是自动发生的:
void doSomething(){ try { throw runtime_error { "A runtime_error exception" }; } catch (const runtime_error& e) { println("doSomething() caught a runtime_error"); println("doSomething() throwing MyException"); throw_with_nested( MyException { "MyException with nested runtime_error" }); }}throw_with_nested() 的工作原理是抛出一个未命名的新编译器生成的类型,它同时派生自 nested_exception 和(在这个例子中) MyException。因此,它是 C++ 中有用多重继承的另一个例子。nested_exception 基类的默认构造函数通过调用 std::current_exception() 自动捕获当前正在处理的异常,并将其存储在 std::exception_ptr 中。exception_ptr 是一个类似于指针的类型,能够存储空指针或指向使用 current_exception() 抛出并捕获的异常对象的指针。exception_ptr 实例可以传递给函数(通常按值)和跨不同线程传递。
最后,以下代码片段演示了如何处理带有嵌套异常的异常。代码调用 doSomething() 并有一个用于 MyException 类型异常的 catch 处理程序。当它捕获这样一个异常时,它写一条消息,然后使用 dynamic_cast() 获取对嵌套异常的访问。如果内部没有嵌套异常,结果将是一个空指针。如果内部有嵌套异常,则调用 nested_exception 上的 rethrow_nested() 成员函数。这会导致嵌套异常被重新抛出,你可以在另一个 try/catch 块中捕获它。
try { doSomething();} catch (const MyException& e) { println("main() caught MyException: {}", e.what());
const auto* nested { dynamic_cast<const nested_exception*>(&e) }; if (nested) { try { nested->rethrow_nested(); } catch (const runtime_error& e) { // Handle nested exception. println(" Nested exception: {}", e.what()); } }}输出如下:
doSomething() caught a runtime_errordoSomething() throwing MyExceptionmain() caught MyException: MyException with nested runtime_error Nested exception: A runtime_error exception这段代码使用 dynamic_cast() 检查嵌套异常。因为如果你想检查嵌套异常总是必须执行这样的 dynamic_cast(),所以标准库提供了一个名为 std::rethrow_if_nested() 的辅助函数为你做这件事。这个辅助函数可以这样使用:
try { doSomething();} catch (const MyException& e) { println("main() caught MyException: {}", e.what()); try { rethrow_if_nested(e); } catch (const runtime_error& e) { // 处理嵌套异常。 println(" Nested exception: {}", e.what()); }}输出与前一个例子相同。
throw_with_nested()、nested_exception、rethrow_if_nested()、current_exception() 和 exception_ptr 都定义在 <exception> 中。
重新抛出异常
Section titled “重新抛出异常”throw 关键字也可以用于在不做任何复制的情况下重新抛出当前异常,如下例所示:
void g() { throw invalid_argument { "Some exception" }; }
void f(){ try { g(); } catch (const invalid_argument& e) { println("caught in f(): {}", e.what()); throw; // rethrow }}
int main(){ try { f(); } catch (const invalid_argument& e) { println("caught in main(): {}", e.what()); }}这个例子产生如下输出:
caught in f(): Some exceptioncaught in main(): Some exception你可能认为可以用 throw e; 重新抛出一个捕获的异常 e。但是,这是错误的,因为它可能导致你的异常对象切片。例如,假设修改 f() 捕获 std::exceptions,并修改 main() 同时捕获 exception 和 invalid_argument 异常:
void g() { throw invalid_argument { "Some exception" }; }
void f(){ try { g(); } catch (const exception& e) { println("caught in f(): {}", e.what()); throw; // rethrow }}
int main(){ try { f(); } catch (const invalid_argument& e) { println("invalid_argument caught in main(): {}", e.what()); } catch (const exception& e) { println("exception caught in main(): {}", e.what()); }}请记住 invalid_argument 派生自 exception,因此必须先被捕获。以下是输出,正如你所期望的:
caught in f(): Some exceptioninvalid_argument caught in main(): Some exception现在,尝试将 f() 中的 throw; 语句替换为 throw e;。输出变为:
caught in f(): Some exceptionexception caught in main(): Some exceptionmain() 似乎在捕获一个 exception 对象,而不是一个 invalid_argument 对象。这是因为 throw e; 语句导致了切片,将 invalid_argument 缩减为 exception。
始终使用 throw; 重新抛出异常。永远不要像 throw e; 那样重新抛出捕获的异常 e!
栈展开与清理
Section titled “栈展开与清理”当一段代码抛出一个异常时,它在栈上搜索一个 catch 处理程序。这个 catch 处理程序可能在调用栈的上方零个或多个函数调用处。当找到时,栈会被剥离到定义 catch 处理程序的栈级别,通过展开所有中间栈帧。栈展开意味着所有局部作用域变量的析构函数被调用,并且每个函数中当前执行点之后的所有代码都被跳过。
在栈展开期间,指针变量显然不会被释放,其他清理也不会执行。这种行为可能会引起问题。例如,以下代码会导致内存泄漏:
void funcOne();void funcTwo();
int main(){ try { funcOne(); } catch (const exception& e) { println(cerr, "Exception caught!"); return 1; }}
void funcOne(){ string str1; string* str2 { new string {} }; funcTwo(); delete str2;}
void funcTwo(){ ifstream fileStream; fileStream.open("filename"); throw exception {}; fileStream.close();}当 funcTwo() 抛出异常时,最近的异常处理器在 main() 中。然后控制立即从 funcTwo() 中的这一行:
throw exception {};跳转到 main() 中的这一行:
println(cerr, "Exception caught!");在 funcTwo() 中,控制权停留在抛出异常的那一行,因此以下后续代码永远没有机会运行:
fileStream.close();然而,幸运的是,由于 fileStream 是栈上的局部变量,ifstream 的析构函数会被调用。ifstream 的析构函数会为你关闭文件,所以这里没有资源泄漏。如果你动态分配了 fileStream,它就不会被销毁,文件也不会被关闭。
在 funcOne() 中,控制权在调用 funcTwo() 处,因此以下后续代码永远没有机会运行:
delete str2;在这种情况下,确实存在内存泄漏。栈展开不会自动为你调用 str2 上的 delete。另一方面,str1 被正确销毁,因为它是栈上的局部变量。栈展开正确地销毁所有局部变量。
粗心的异常处理会导致内存和资源泄漏。
这就是为什么你不应该将旧的 C 分配模型(即使你调用 new 看起来像 C++)与现代编程方法(如异常)混合使用的原因之一。在 C++ 中,这种情况应该通过使用基于栈的分配来处理,或者,如果不可能,则使用接下来两节中讨论的技术之一。
使用智能指针
Section titled “使用智能指针”如果无法使用基于栈的分配,请使用智能指针。它们允许你编写在异常处理期间自动防止内存或资源泄漏的代码。每当智能指针对象被销毁时,它会释放底层资源。以下是使用 <memory> 中定义的 unique_ptr 智能指针修改后的 funcOne() 实现,第 7 章 “内存管理” 中已介绍:
void funcOne(){ string str1; auto str2 { make_unique<string>("hello") }; funcTwo();}当你从 funcOne() 返回或抛出异常时,str2 指针会自动被删除。
当然,你只有在有充分理由时才应该动态分配某些东西。例如,在 funcOne() 中,没有充分理由让 str2 成为动态分配的字符串。它应该只是一个基于栈的 string 变量。这里只是为了展示抛出异常的后果而举的人为例子。
捕获、清理和重新抛出
Section titled “捕获、清理和重新抛出”避免内存和资源泄漏的另一种技术是让每个函数捕获任何可能的异常,执行必要的清理工作,然后向栈上方的函数重新抛出异常以进行处理。以下是使用此技术修改后的 funcOne():
void funcOne(){ string str1; string* str2 { new string {} }; try { funcTwo(); } catch (…) { delete str2; throw; // Rethrow the exception. } delete str2;}这个函数用异常处理器包装了对 funcTwo() 的调用,该处理器执行清理(在 str2 上调用 delete),然后重新抛出异常。throw 关键字本身会重新抛出最近捕获的异常。注意,catch 语句使用 … 语法来捕获所有异常。
这种方法工作得很好,但很混乱且容易出错。特别要注意,现在有两行相同的代码在 str2 上调用 delete:一个在处理异常时,另一个在函数正常退出时。
首选解决方案是使用基于栈的分配,或者,如果不可能,请使用智能指针或其他 RAII 类,而不要使用捕获、清理和重新抛出技术。
在 C++20 之前,你可以使用以下预处理器宏来获取有关源代码中位置的信息:
| 宏 | 描述 |
|---|---|
__FILE__ | 被替换为当前源代码文件名 |
__LINE__ | 被替换为源代码中的当前行号 |
此外,每个函数都有一个本地定义的名为 __func__ 的静态字符数组,包含函数的名称。
自 C++20 以来,一种名为 std::source_location 的适当的面向对象的替代品取代了 __func__ 和这些 C 风格的预处理器宏,该类定义在 <source_location> 中。source_location 实例具有以下公共访问器:
| 访问器 | 描述 |
|---|---|
file_name() | 包含当前源代码文件名 |
function_name() | 包含当前函数名称(如果当前位置在函数内) |
line() | 包含源代码中的当前行号 |
column() | 包含当前列号 |
提供了一个静态成员函数 current(),它根据调用成员函数的源代码位置创建一个 source_location 实例。
用于日志记录的 source_location
Section titled “用于日志记录的 source_location”source_location 类对日志记录目的很有用。以前,日志记录通常涉及编写 C 风格宏来自动收集当前文件名、函数名和行号,以便将它们包含在日志输出中。现在,使用 source_location,你可以编写一个纯 C++ 函数来执行日志记录,并自动收集你需要的位置数据。一个很好的技巧是像下面这样定义 logMessage() 函数。这次,代码加上了行号以便更好地解释发生了什么。
5. void logMessage(string_view message, 6. const source_location& location = source_location::current()) 7. { 8. println("{}({}): {}: {}", location.file_name(), 9. location.line(), location.function_name(), message);10. }11.12. void foo()13. {14. logMessage("Starting execution of foo().");15. }16.17. int main()18. {19. foo();20. }logMessage() 的第二个参数是一个 source_location,默认值为静态成员函数 current() 的结果。这里的技巧是 current() 的调用不在第 6 行发生,而实际上发生在调用 logMessage() 的位置,即第 14 行,这正是你感兴趣的位置。
使用 Microsoft Visual C++ 执行此程序时,输出如下:
./01_Logging.cpp(14): void __cdecl foo(void): Starting execution of foo().第 14 行确实对应于调用 logMessage() 的行。函数的确切名称(在本例中为 void __cdecl foo(void))取决于编译器。
在自定义异常中自动嵌入源代码位置
Section titled “在自定义异常中自动嵌入源代码位置”source_location 的另一个有趣用例是在你自己的异常类中自动存储抛出异常的位置。以下是一个例子:
class MyException : public exception{ public: explicit MyException(string message, source_location location = source_location::current()) : m_message { move(message) } , m_location { move(location) } { }
const char* what() const noexcept override { return m_message.c_str(); } virtual const source_location& where() const noexcept{ return m_location; } private: string m_message; source_location m_location;};
void doSomething(){ throw MyException { "Throwing MyException." };}
int main(){ try { doSomething(); } catch (const MyException& e) { const auto& location { e.where() }; println(cerr, "Caught: '{}' at line {} in {}.", e.what(), location.line(), location.function_name()); }}使用 Microsoft Visual C++ 的输出类似于以下内容:
Caught: 'Throwing MyException.' at line 26 in void __cdecl doSomething(void).每当函数 A() 调用另一个函数 B() 时,传递给 B() 的参数会被记录,以及函数完成时返回到的位置的信息也会被记录。B() 的执行可以再次调用另一个函数 C() 等等。所有这些信息都记录在栈追踪(调用栈)的帧中。对于每个函数调用,栈追踪中都会添加一个新帧。当函数的执行完成时,其帧会从栈追踪中移除。在程序执行的任何给定时刻,栈追踪会准确告诉你通过哪些函数调用到达当前正在执行的函数。这些信息对于在你的程序中查找和修复错误至关重要。第 31 章 “征服调试” 详细讨论了调试。本节讨论标准库提供的用于处理栈追踪的功能,以及如何将其与自定义异常结合使用。本节讨论的所有内容都是 C++23 新增的。
栈追踪库定义在 <stacktrace> 中。你可以使用静态成员函数 std::stacktrace::current() 在任何时刻获取栈追踪。如果你想跳过一定数量的顶部帧,可以向 current() 传递一个整数。下一节会给出一个例子。一旦你有了栈追踪,你可以使用 print() 或 println() 轻松将其打印到控制台。你也可以使用 std::to_string() 将栈追踪转换为字符串。以下是一个例子,栈追踪相关的语句已突出显示:
void handleStackTrace(const stacktrace& trace){ println(" Stack trace information:"); println(" There are {} frames in the stack trace.", trace.size()); println(" Here are all the frames:"); println("---------------------------------------------------------"); println("{}", trace); // If the above statement doesn't work yet, you can use the following: //println("{}", to_string(trace)); println("---------------------------------------------------------");}
void C(){ println("Entered C()."); handleStackTrace(stacktrace::current());}
void B() { println("Entered B()."); C(); }void A() { println("Entered A()."); B(); }
int main(){ A();}使用 Microsoft Visual C++ 编译并在 Windows 上运行时,输出类似于以下内容。长路径名已被修剪以防止换行。01_stacktrace.cpp 文件是我们的代码。exe_common.inl 和 exe_main.cpp 文件属于 Visual C++ 运行时。最后两个帧 kernel32 和 ntdll 是 Windows 内核的一部分。为便于阅读,函数名已突出显示。
Entered A().Entered B().Entered C(). Stack trace information: There are 10 frames in the stack trace. Here are all the frames:---------------------------------------------------------0> D:\…\01_stacktrace.cpp(20): TestApp!C+0x771> D:\…\01_stacktrace.cpp(27): TestApp!B+0x612> D:\…\01_stacktrace.cpp(33): TestApp!A+0x613> D:\…\01_stacktrace.cpp(38): TestApp!main+0x204> D:\…\exe_common.inl(79): TestApp!invoke_main+0x395> D:\…\exe_common.inl(288): TestApp!__scrt_common_main_seh+0x12E6> D:\…\exe_common.inl(331): TestApp!__scrt_common_main+0xE7> D:\…\exe_main.cpp(17): TestApp!mainCRTStartup+0xE8> KERNEL32!BaseThreadInitThunk+0x1D9> ntdll!RtlUserThreadStart+0x28---------------------------------------------------------你可以遍历栈追踪的各个帧并查询每个帧的信息。帧由 std::stacktrace_entry 类表示,它支持以下成员函数:
description(): 返回帧的描述source_file()和source_line(): 包含帧所表示的语句的源文件名和其中的行号
例如,以下 handleStackTrace() 的实现不只是一次打印整个栈追踪,而是遍历各个帧并只打印每个的描述。
void handleStackTrace(const stacktrace& trace){ println(" Stack trace information:"); println(" There are {} frames in the stack trace.", trace.size()); println(" Here are the descriptions of all the frames:"); for (unsigned index { 0 }; auto&& frame : trace) { println(" {} -> {}", index++, frame.description()); }}现在的输出如下:
Entered A().Entered B().Entered C(). Stack trace information: There are 10 frames in the stack trace. Here are the descriptions of all the frames: 0 -> TestApp!C+0x77 1 -> TestApp!B+0x61 2 -> TestApp!A+0x61 3 -> TestApp!main+0x20 4 -> TestApp!invoke_main+0x39 … <snip> …在自定义异常中自动嵌入栈追踪
Section titled “在自定义异常中自动嵌入栈追踪”我们可以扩展前面关于 source_location 一节中的 MyException 类,使其除了源代码位置之外还包括栈追踪。
class MyException : public exception{ public: explicit MyException(string message, source_location location = source_location::current()) : m_message { move(message) } , m_location { move(location) } , m_stackTrace { stacktrace::current(1) } // 1 表示跳过顶部帧。 { }
const char* what() const noexcept override { return m_message.c_str(); } virtual const source_location& where() const noexcept{ return m_location; } virtual const stacktrace& how() const noexcept { return m_stackTrace; } private: string m_message; source_location m_location; stacktrace m_stackTrace;};请注意,构造函数将 1 传递给 stacktrace::current() 以跳过栈追踪的顶部帧。这个顶部帧将是 MyException 的构造函数,我们对它不感兴趣。我们只对导致构造此 MyException 实例之前的栈追踪感兴趣。这个新的异常类可以如下测试:
void doSomething(){ throw MyException { "Throwing MyException." };}
int main(){ try { doSomething(); } catch (const MyException& e) { // Print exception description + location where exception was raised. const auto& location { e.where() }; println(cerr, "Caught: '{}' at line {} in {}.", e.what(), location.line(), location.function_name());
// Print the stack trace at the point where the exception was raised. println(cerr, " Stack trace:"); for (unsigned index { 0 }; auto&& frame : e.how()) { const string& fileName { frame.source_file() }; println(cerr, " {}> {}, {}({})", index++, frame.description(), (fileName.empty() ? "n/a" : fileName), frame.source_line()); } }}使用 Microsoft Visual C++ 编译并在 Windows 上运行时,输出类似于以下内容。仅显示栈追踪的前两个相关条目。为简洁起见,省略了 Visual C++ 运行时内部或 Windows 本身内部的栈条目。
Caught: 'Throwing MyException.' at line 30 in void __cdecl doSomething(void). Stack trace: 0 > TestApp!doSomething+0xD2, D:\…\03_CustomExceptionWithStackTrace.cpp(30) 1 > TestApp!main+0x4D, D:\…\03_CustomExceptionWithStackTrace.cpp(36) … <snip> …常见的错误处理场景
Section titled “常见的错误处理场景”无论你在程序中使用异常与否,都取决于你和你的同事。但是,强烈建议你为你的程序制定一个错误处理计划,无论你是否使用异常。如果你使用异常,通常更容易想出一个统一的错误处理方案,但没有异常也不是不可能。一个好的计划最重要的方面是在程序的所有模块中统一错误处理。确保项目中的每个程序员都理解和遵循错误处理规则。
本节讨论异常情况下最常见的错误处理问题,但这些问题也与不使用异常的程序相关。
内存分配错误
Section titled “内存分配错误”尽管本书中到目前为止的所有例子都忽略了这种可能性,但内存分配可能会失败。在当前的 64 位平台上,这几乎永远不会发生,但在移动设备或旧系统上,内存分配可能会失败。在这样的系统上,你必须考虑内存分配失败的情况。C++ 提供了几种不同的方法来处理内存错误。
new 和 new[] 的默认行为是,如果无法分配内存,则抛出类型为 bad_alloc 的异常,定义在 <new> 中。你的代码可以捕获这些异常并适当处理。
将所有对 new 和 new[] 的调用用 try/catch 包装起来是不切实际的,但至少当你尝试分配一大块内存时应该这样做。以下示例演示了如何捕获内存分配异常:
int* ptr { nullptr };size_t integerCount { numeric_limits<size_t>::max() };println("Trying to allocate memory for {} integers.", integerCount);try { ptr = new int[integerCount];} catch (const bad_alloc& e) { auto location { source_location::current() }; println(cerr, "{}({}): Unable to allocate memory: {}", location.file_name(), location.line(), e.what()); // Handle memory allocation failure. return;}// Proceed with function that assumes memory has been allocated.注意,这段代码使用 source_location 在错误消息中包含文件名和当前行号。这会让调试更容易。
当然,如果这对你的程序有效,你可以在程序中更高的地方用单个 try/catch 块批量处理许多可能的 new 失败。
另一点需要考虑的是,记录错误可能会尝试分配内存。如果 new 失败,可能没有足够的内存来记录错误消息。
非抛出的 new
Section titled “非抛出的 new”如果你不喜欢异常,你可以恢复到旧的 C 模型,在该模型中,如果内存分配例程无法分配内存,则返回空指针。C++ 提供了 new 和 new[] 的nothrow 重载,如果它们无法分配内存,它们会返回 nullptr 而不是抛出异常。这是通过使用 new(nothrow) 而不是 new 的语法来完成的,如以下示例所示:
int* ptr { new(nothrow) int[integerCount] };if (ptr == nullptr) { auto location { source_location::current() }; println(cerr, "{}({}): Unable to allocate memory!", location.file_name(), location.line()); // Handle memory allocation failure. return;}// Proceed with function that assumes memory has been allocated.自定义内存分配失败行为
Section titled “自定义内存分配失败行为”C++ 允许你指定一个 new handler 回调函数。默认情况下,没有 new handler,因此 new 和 new[] 只是抛出 bad_alloc 异常。但是,如果有一个 new handler,内存分配例程在内存分配失败时调用 new handler 而不是抛出异常。如果 new handler 返回,内存分配例程会再次尝试分配内存,如果失败则再次调用 new handler。除非你的 new handler 用三种替代方案之一改变这种情况,否则这个循环可能会变成无限循环。实际上,有些选项比其他选项更好。
- 提供更多内存。 一个暴露空间的技巧是在程序启动时分配一大块内存,然后在 new handler 中释放它。一个实用的例子是当你遇到分配错误并且需要保存用户状态以免丢失工作时。关键是在程序启动时分配一块足够大的内存,以允许完整的文档保存操作。当 new handler 被触发时,你释放这个块,保存文档,重启应用程序,并让它重新加载保存的文档。
- 抛出一个异常。 C++ 标准要求如果你从 new handler 抛出异常,它必须是一个
bad_alloc异常或派生自bad_alloc的异常。以下是一些例子:- 编写并抛出一个从
bad_alloc派生的document_recovery_alloc异常。 这个异常可以在你的应用程序中的某个地方被捕获,以触发文档保存操作和应用程序重启。 - 编写并抛出一个从
bad_alloc派生的please_terminate_me异常。 在你的顶层函数(例如main())中,你捕获这个异常并通过从顶层函数返回来处理它。建议通过从顶层函数返回来终止程序,而不是通过调用exit()之类的函数。
- 编写并抛出一个从
- 设置不同的 new handler。 理论上,你可能有一系列 new handler,每个都尝试创建内存,如果失败则设置不同的 new handler。然而,这种场景通常比有用更复杂。
如果你不在你的 new handler 中做这些事情之一,任何内存分配失败都会导致无限循环。
如果有一些可能失败但你不想调用 new handler 的内存分配,你可以在这种情况下在调用 new 之前暂时将 new handler 设置回其默认的 nullptr。
你可以通过调用 <new> 中声明的 set_new_handler() 来设置 new handler。以下是一个记录错误消息并抛出异常的新 handler 示例:
class please_terminate_me : public bad_alloc { };
void myNewHandler(){ println(cerr, "Unable to allocate memory."); throw please_terminate_me {};}new handler 必须不接受任何参数且不返回任何值。这个新 handler 抛出 please_terminate_me 异常,如前一个列表中建议的那样。你可以像这样激活这个新 handler:
int main(){ try { // 设置新的 new_handler 并保存旧的。 new_handler oldHandler { set_new_handler(myNewHandler) };
// 生成分配错误。 size_t numInts { numeric_limits<size_t>::max() }; int* ptr { new int[numInts] };
// 重置旧的 new_handler。 set_new_handler(oldHandler); } catch (const please_terminate_me&) { auto location { source_location::current() }; println(cerr, "{}({}): Terminating program.", location.file_name(), location.line()); return 1; }}new_handler 是 set_new_handler() 所接受的函数指针类型的类型别名。
构造函数中的错误
Section titled “构造函数中的错误”在 C++ 程序员了解异常之前,他们常常会被构造函数中的错误处理问题难住。如果构造函数无法正确构造对象怎么办?构造函数没有返回值,所以标准的异常前错误处理机制不起作用。没有异常,你所能做的最好的是在对象中设置一个标志,指定它没有正确构造。你可以提供一个名为 checkConstructionStatus() 的成员函数,该函数返回该标志的值,并希望客户端在构造对象后记得对该对象调用此成员函数。
异常提供了一个更好的解决方案。你可以从构造函数中抛出异常,即使你不能返回值1。使用异常,你可以轻松地告诉客户端对象构造是否成功。然而,有一个主要问题:如果异常离开构造函数,该对象的析构函数永远不会被调用!因此,你必须小心在允许异常离开构造函数之前清理任何资源并释放任何分配的内存。
本节描述了一个 Matrix 类模板作为示例,其中构造函数正确处理异常。请注意,这个例子使用了一个名为 m_matrix 的原始指针来演示问题。在生产质量的代码中,你应该避免使用原始指针,例如,使用标准库容器!Matrix 类模板的定义如下:
export template <typename T>class Matrix final{ public: explicit Matrix(std::size_t width, std::size_t height); ~Matrix(); // Copy/move ctors and copy/move assignment operators deleted (omitted). private: void cleanup();
std::size_t m_width { 0 }; std::size_t m_height { 0 }; T** m_matrix { nullptr };};Matrix 类的实现如下。第一个 new 调用没有用 try/catch 块保护。如果第一个 new 抛出异常,这无所谓,因为构造函数还没有分配任何需要释放的其他东西。但是,如果后续的任何 new 调用抛出异常,构造函数必须清理已分配的所有内存。构造函数不知道 T 构造函数本身可能抛出什么异常,因此它通过 … 捕获所有异常,然后将捕获的异常嵌套在 bad_alloc 异常中。第一次调用 new 分配的数组使用 {} 语法进行零初始化;也就是说,每个元素都将是 nullptr。这使得 cleanup() 成员函数更容易,因为它可以对 nullptr 调用 delete。
template <typename T>Matrix<T>::Matrix(std::size_t width, std::size_t height){ m_matrix = new T*[width] {}; // 数组已零初始化!
// 不要在构造函数初始化列表中初始化 m_width 和 m_height 成员。 // 只有在上述 m_matrix 分配成功时才应初始化它们! m_width = width; m_height = height;
try { for (std::size_t i { 0 }; i < width; ++i) { m_matrix[i] = new T[height]; } } catch (…) { std::println(std::cerr, "Exception caught in constructor, cleaning up…"); cleanup(); // 将任何捕获的异常嵌套在 bad_alloc 异常中。 std::throw_with_nested(std::bad_alloc {}); }}
template <typename T>Matrix<T>::~Matrix(){ cleanup();}
template <typename T>void Matrix<T>::cleanup(){ for (std::size_t i { 0 }; i < m_width; ++i) { delete[] m_matrix[i]; } delete[] m_matrix; m_matrix = nullptr; m_width = m_height = 0;}请记住,如果异常离开构造函数,该对象的析构函数永远不会被调用!
Matrix 类模板可以如下测试。为简洁起见,省略了在 main() 中捕获 bad_alloc 异常的代码。
class Element{ // 保持最小,但实际上,这个 Element 类 // 可能在其构造函数中抛出异常。 private: int m_value;};
int main(){ Matrix<Element> m { 10, 10 };}你可能想知道当你加入继承时会发生什么。基类构造函数在派生类构造函数之前运行。如果派生类构造函数抛出异常,C++ 将执行完全构造的基类的析构函数。
构造函数的函数 try 块
Section titled “构造函数的函数 try 块”本章到目前为止讨论的异常机制非常适合处理函数内的异常。但是,你应该如何处理从构造函数的 ctor-initializer 内部抛出的异常呢?本节解释了一个称为 函数 try 块的功能,它能够捕获这些异常。函数 try 块也适用于普通函数和构造函数。本节重点介绍与构造函数一起使用。大多数 C++ 程序员,即使是有经验的 C++ 程序员,也不知道这个功能的存在,尽管它已经引入很长时间了。
以下伪代码显示了构造函数函数 try 块的基本语法:
MyClass::MyClass()try : <ctor-initializer>{ /* … 构造函数体 … */}catch (const exception& e){ /* … */}如你所见,try 关键字应该在 ctor-initializer 的开始处。catch 语句应该放在构造函数的闭括号之后,实际上是把它们放在构造函数体之外。在将函数 try 块与构造函数一起使用时,你应该记住一些限制和指南:
catch语句捕获 ctor-initializer 或构造函数体直接或间接抛出的任何异常。catch语句必须重新抛出当前异常或抛出新异常。如果catch语句不这样做,运行时会自动重新抛出当前异常。catch语句可以访问传递给构造函数的参数。- 当
catch语句在函数 try 块中捕获异常时,在catch语句开始执行之前,所有完全构造的基类和对象的成员都会被销毁。 - 在
catch语句内你不应该访问作为对象的数据成员,因为这些成员在执行catch语句之前会被销毁(请参阅上一条)。但是,如果你的对象包含非类数据成员——例如,原始指针——你可以访问它们,如果它们在异常被抛出之前已被初始化。如果你有这样的原始资源,也称为裸资源,你必须通过在catch语句中释放它们来照顾它们,如以下示例所示。 - 构造函数的函数 try 块中的 catch 语句不能使用 return 关键字。
基于这一限制列表,构造函数的函数 try 块只在有限的情况下有用:
- 将 ctor-initializer 抛出的异常转换为另一个异常
- 向日志文件记录消息
- 释放异常被抛出之前在 ctor-initializer 中分配的原始资源
以下示例演示了如何使用函数 try 块。代码定义了一个名为 SubObject 的类。它只有一个构造函数,抛出类型为 runtime_error 的异常:
class SubObject{ public: explicit SubObject(int i) { throw runtime_error { "Exception by SubObject ctor" }; }};接下来,MyClass 类有一个类型为 int* 的数据成员和另一个类型为 SubObject 的数据成员:
class MyClass{ public: MyClass(); private: int* m_data { nullptr }; SubObject m_subObject;};SubObject 类没有默认构造函数。这意味着你需要在 MyClass ctor-initializer 中初始化 m_subObject。MyClass 的构造函数使用函数 try 块来捕获其 ctor-initializer 中抛出的异常,如下所示:
MyClass::MyClass()try : m_data { new int[42]{ 1, 2, 3 } }, m_subObject { 42 }{ /* … 构造函数体 … */}catch (const exception& e){ // 清理内存。 delete[] m_data; m_data = nullptr; println(cerr, "function-try-block caught: '{}'", e.what());}请记住,构造函数的函数 try 块中的 catch 语句必须重新抛出当前异常或抛出新异常。前面 catch 语句没有抛出任何东西,所以 C++ 运行时自动重新抛出当前异常。以下是一个使用 MyClass 的简单函数:
int main(){ try { MyClass m; } catch (const exception& e) { println(cerr, "main() caught: '{}'", e.what()); }}输出如下:
function-try-block caught: 'Exception by SubObject ctor'main() caught: 'Exception by SubObject ctor'请注意,这个例子中的代码容易出错,不推荐使用。这个例子的正确解决方案是让 m_data 成员成为一个容器,如 std::vector,或一个智能指针,如 unique_ptr,并删除函数 try 块。
函数 try 块不仅限于构造函数。它们也可以与普通函数一起使用。但是,对于普通函数,使用函数 try 块没有有用的原因,因为它们可以很容易地转换为函数体内的简单 try/catch 块。与构造函数相比,在普通函数上使用函数 try 块时有一个显著的区别:在 catch 语句中重新抛出当前异常或抛出新异常不是必需的,C++ 运行时不会自动重新抛出异常。在这样的 catch 语句中允许使用 return 关键字。
避免使用函数 try 块!
析构函数中的错误
Section titled “析构函数中的错误”你应该处理析构函数本身中出现的所有错误情况。你不应该让任何异常从析构函数中抛出,原因有几个:
- 客户端会采取什么行动?客户端不会显式调用析构函数;析构函数会为他们自动调用。如果从析构函数抛出异常,客户端应该做什么?客户端无法采取合理的行动,所以没有理由用异常处理来负担那段代码。
- 析构函数是你释放对象中使用的内存和资源的唯一机会。如果你因为异常而提前退出函数而浪费了你的机会,你将永远无法回去释放内存或资源。
- 析构函数被隐式标记为
noexcept,除非它们被显式标记为noexcept(false)或者该类有任何noexcept(false)析构函数的子对象。如果从noexcept析构函数抛出异常,C++ 运行时调用std::terminate()来终止应用程序。 - 析构函数可以在栈展开过程中运行,而此时正在处理另一个异常。如果在栈展开过程中从析构函数抛出异常,C++ 运行时调用
std::terminate()来终止应用程序。对于勇敢和好奇的人,C++ 确实提供了在析构函数中确定你是由于正常函数退出或 delete 调用还是由于栈展开而执行的能力。函数uncaught_exceptions(),声明在<exception>中,返回未捕获异常的数量,即已抛出但尚未到达匹配catch的异常。如果uncaught_exceptions()的结果大于零,那么你正处于栈展开的中间。然而,正确使用这个函数是复杂的、混乱的,应该避免。请注意,在 C++17 之前,该函数名为uncaught_exception()(单数形式),返回一个bool,如果正处于栈展开中间则返回true。这个单数版本自 C++17 起已弃用,并自 C++20 起被移除。
注意不要让任何异常从析构函数中逃脱。
异常安全保证
Section titled “异常安全保证”既然你已经熟练掌握异常的使用,是时候讨论异常安全保证了。对于你编写的代码,你可以提供几个级别的保证,以便代码的用户知道在抛出异常时可以期待什么。可以为函数指定以下异常安全保证:
- 不抛出(或无失败)异常保证: 函数永远不会抛出任何异常。
- 强异常保证: 如果抛出异常,所有涉及的对象都会回滚到函数调用之前它们所处的状态。提供此保证的代码示例是 第 9 章 中介绍的拷贝并交换惯用法。
- 基本异常保证: 如果抛出异常,所有涉及的对象都保持在有效状态,并且没有资源泄漏。然而,对象可能处于与函数调用之前它们所处的状态不同的另一种状态。
- 无保证: 当抛出异常时,应用程序可能处于任何无效状态,资源可能泄漏,内存可能损坏,等等。
本章描述了与 C++ 程序中的错误处理相关的问题,并强调了你必须为程序设计和编码错误处理计划。通过阅读本章,你学习了 C++ 异常语法和行为的细节。你学会了如何编写自定义异常类,自动嵌入异常被抛出的位置以及那一刻的完整栈追踪。本章还介绍了错误处理发挥很大作用的一些领域,包括 I/O 流、内存分配、构造函数和析构函数。本章以函数可以提供的不同类型的异常安全保证结束。
通过解决以下练习,你可以练习本章中讨论的材料。所有练习的解决方案都包含在本书网站 www.wiley.com/go/proc++6e 的代码下载中。但是,如果你卡在某个练习上,首先重读本章的部分内容,在查看网站上的解决方案之前尝试自己找到答案。
-
练习 14-1: 不编译和执行,找出并纠正以下代码中的错误:
// 如果给定数据集中的元素数量不是偶数,则抛出 logic_error 异常。void verifyDataSize(const vector<int>& data){if (data.size() % 2 != 0)throw logic_error { "Number of data points must be even." };}// 如果给定数据集中的元素数量不是偶数,则抛出 logic_error 异常。// 如果其中一个数据点为负,则抛出 domain_error 异常。void processData(const vector<int>& data){// 验证给定数据集的大小。try {verifyDataSize(data);} catch (const logic_error& caughtException) {// 在标准输出上写消息。println(cerr, "Invalid number of data points in dataset. Aborting.");// 重新抛出异常。throw caughtException;}// 验证负数据点。for (auto& value : data) {if (value < 0)throw domain_error { "Negative datapoints not allowed." };}// 处理数据 …}int main(){try {vector data { 1, 2, 3, -5, 6, 9 };processData(data);} catch (const logic_error& caughtException) {println(cerr, "logic_error: {}", caughtException.what());} catch (const domain_error& caughtException) {println(cerr, "domain_error: {}", caughtException.what());}} -
练习 14-2: 采用 第 13 章 双向 I/O 示例中的代码。你可以在可下载源代码档案的
Ch13\22_Bidirectional文件夹中找到它。该示例实现了一个changeNumberForID()函数。重构代码在你认为合适的所有地方使用异常。一旦你的代码使用异常,你是否看到可以对changeNumberForID()函数头进行的可能更改? -
练习 14-3: 为练习 13-3 的人员数据库解决方案添加适当的异常错误处理。
-
练习 14-4: 查看 第 9 章 中包含使用
swap()的移动语义支持的Spreadsheet示例代码。你可以在可下载源代码档案的文件夹Ch09\07_SpreadsheetMoveSemantics–WithSwap中找到完整代码。为代码添加适当的错误处理,包括处理内存分配失败。向类添加最大宽度和高度,并包含适当的验证检查。编写你自己的异常类InvalidCoordinate,它存储无效坐标和允许的坐标范围。将其用在verifyCoordinate()成员函数中。在main()中编写一些测试来测试各种错误条件。
Footnotes
Section titled “Footnotes”-
有一个注意事项,不要从全局对象的构造函数中抛出异常。这样的异常无法被捕获,因为这些对象在 main() 开始执行之前就已经被构造了。 ↩