理解继承技术
如果没有继承,类就只会是带有相关行为的数据结构。仅这一点相较于过程式语言就已经是巨大的改进了,但继承又为其增加了一个全新的维度。通过继承,你可以基于现有类构建新类。这样一来,你的类就会成为可复用且可扩展的组件。本章将讲解多种利用继承威力的方法。你将学习继承的具体语法,以及如何最大化发挥继承作用的一些高级技巧。
本章中与多态相关的部分会大量借助 第 8 章“熟悉类和对象”和 第 9 章“精通类和对象”中讨论过的电子表格示例。本章还会引用 第 5 章“用类进行设计”中介绍的面向对象方法论。如果你还没有读过那一章,或者对继承背后的理论并不熟悉,那么在继续之前应先回顾 第 5 章。
通过继承构建类
Section titled “通过继承构建类”在 第 5 章 中,你已经学过,is-a 关系抓住了现实世界对象往往以层次结构存在这一模式。在编程中,当你需要编写一个建立在另一个类之上,或者对另一个类做轻微修改的新类时,这种模式就变得尤为重要。实现这一目标的一种方法,是把一个类中的代码复制出来并粘贴到另一个类中。再通过修改相关部分或补充代码,你就能得到一个与原类略有不同的新类。然而,这种做法会让一个 OOP 程序员感到沮丧且烦躁,原因如下:
- 对原始类所做的 bug 修复不会自动反映到新类中,因为这两个类实际上拥有的是两份完全独立的代码。
- 编译器并不知道这两个类之间存在任何关系,因此它们不是多态的(见 第 5 章)——它们并不是“同一类事物的不同变体”。
- 这种做法并没有建立真正的 is-a 关系。新类之所以和原类相似,只是因为它拥有相似的代码,而不是因为它真的就是同一种对象。
- 原始代码也许根本拿不到。它可能只以预编译二进制形式存在,因此复制粘贴代码甚至都不可能。
不出所料,C++ 内建支持定义真正的 is-a 关系。下一节将介绍 C++ 中 is-a 关系的特征。
在 C++ 中编写类定义时,你可以告诉编译器,你的类正在继承自(inherit from)、派生自(derive from),或者说扩展(extend)某个已有类。这样一来,你的类就会自动拥有原始类中的数据成员和成员函数。原始类称为父类(parent class)、基类(base class)或超类(superclass)。扩展现有类的好处在于,你的类(此时称为子类(child class)、派生类(derived class)或子类(subclass))只需要描述它与父类不同的地方即可。
在 C++ 中扩展一个类时,你只需在写类定义时指明要扩展的那个类。为了展示继承语法,下面使用两个类:Base 和 Derived。别担心——后面还会有更有意思的例子。首先,先看一下 Base 类的定义:
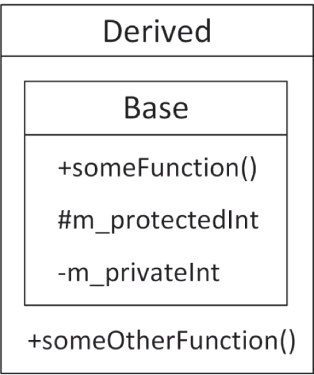
class Base{ public: void someFunction() {} protected: int m_protectedInt { 0 }; private: int m_privateInt { 0 };};如果你想构建一个名为 Derived 的新类,并让它继承自 Base,那么语法如下:
class Derived : public Base{ public: void someOtherFunction() {}};Derived 是一个完整的类,只不过它恰好共享了 Base 类的特征。现在先不用在意这里的 public 一词——其含义会在本章后面解释。图 10.1 展示了 Derived 与 Base 之间的简单关系。你可以像声明其他对象一样声明 Derived 类型对象。你甚至还可以定义第三个类,让它继承自 Derived,从而形成一条类链,如 图 10.2 所示。
[^图 10.1]
[^图 10.2]
Derived 并不一定是 Base 唯一的派生类。其他类也可以继承自 Base,从而与 Derived 成为兄弟类(siblings),如 图 10.3 所示。
[^图 10.3]
从内部实现上看,派生类会把基类实例作为一个子对象(subobject)包含在内。图示上可以表示为 图 10.4 那样。
[^图 10.4]
从客户端视角看继承
Section titled “从客户端视角看继承”对于客户端代码,也就是你程序中的其他部分而言,一个 Derived 类型对象同时也是一个 Base 类型对象,因为 Derived 继承自 Base。这意味着,Base 的所有 public 成员函数和数据成员,再加上 Derived 自己的所有 public 成员函数和数据成员,都可以使用。
使用派生类的代码在调用某个成员函数时,不需要知道这个成员函数究竟是继承链中的哪一个类定义出来的。例如,下面这段代码调用了一个 Derived 对象的两个成员函数,尽管其中一个实际上是由 Base 类定义的:
Derived myDerived;myDerived.someFunction();myDerived.someOtherFunction();必须理解的一点是,继承只在一个方向上成立。Derived 类与 Base 类之间有明确关系,但就当前的定义而言,Base 类对 Derived 类一无所知。这意味着,Base 类型对象无法访问 Derived 的成员函数和数据成员,因为 Base 不是 Derived。
下面这段代码无法编译,因为 Base 类并没有名为 someOtherFunction() 的 public 成员函数:
Base myBase;myBase.someOtherFunction(); // Error! Base doesn't have a someOtherFunction().一个指向类类型的指针或引用,既可以指向该声明类类型的对象,也可以指向其任意派生类对象。这个稍显复杂的话题会在本章后面详细解释。此刻你需要理解的概念是: 一个指向 Base 的指针,实际上可能指向的是一个 Derived 对象。引用也同样如此。客户端仍然只能访问 Base 中存在的那些成员函数和数据成员,但通过这种机制,任何针对 Base 编写的代码,也都可以作用于 Derived。
例如,下面这段代码可以顺利编译并正常运行,尽管它乍看之下像是发生了类型不匹配:
Base* base { new Derived {} }; // Create Derived, store in Base pointer.不过,你不能通过这个 Base 指针去调用 Derived 类中的成员函数。下面这段代码是行不通的:
base->someOtherFunction();编译器会把它标记为错误。因为尽管该对象的实际类型是 Derived,因而确实拥有 someOtherFunction(),但编译器只能把它视为 Base 类型,而 Base 并没有定义 someOtherFunction()。
从派生类视角看继承
Section titled “从派生类视角看继承”对于派生类本身来说,在编写方式和行为方式上并没有发生太多变化。你依然可以像为普通类那样,在派生类中定义成员函数和数据成员。前面 Derived 的定义就声明了一个名为 someOtherFunction() 的成员函数。因此,Derived 类通过新增一个成员函数,扩展了 Base 类。
派生类可以像访问自己的成员一样,访问其基类中声明的 public 和 protected 成员函数及数据成员,因为从技术上讲,它们确实是派生类的一部分。例如,Derived 上的 someOtherFunction() 实现就可以使用在 Base 中声明的数据成员 m_protectedInt。下面的代码展示了这一点。访问基类成员与访问声明在派生类自身中的成员并没有区别。
void Derived::someOtherFunction(){ println("I can access base class data member m_protectedInt."); println("Its value is {}", m_protectedInt);}如果某个类把成员声明为 protected,那么派生类就可以访问它们。如果成员被声明为 private,派生类则无权访问。下面这个 someOtherFunction() 实现无法编译,因为派生类试图访问基类中的一个 private 数据成员:
void Derived::someOtherFunction(){ println("I can access base class data member m_protectedInt."); println("Its value is {}", m_protectedInt); println("The value of m_privateInt is {}", m_privateInt); // Error!}private 访问说明符让你可以控制潜在派生类将如何与你的类交互。
第 4 章“设计专业级 C++ 程序”给出过这样一条规则: 所有数据成员都应当是 private; 如果你希望类外部代码能够访问这些数据成员,则应提供 public 的 getter 和 setter。现在,我们可以把这条规则扩展到 protected 访问说明符上。
所有数据成员都应当是 private。如果你希望类外部代码能访问它们,请提供 public 的 getter 和 setter; 如果你只希望派生类能访问它们,请提供 protected 的 getter 和 setter。
默认将数据成员设为 private 的原因在于,这样可以提供最高级别的封装。这意味着,你可以改变内部数据表示方式,同时保持 public 和 protected 接口不变。此外,如果不直接暴露数据成员,你就可以很容易地在 public 或 protected setter 中加入对输入数据的检查。成员函数默认也应当是 private。只有那些明确设计给外部使用的成员函数才应设为 public; 如果你只希望派生类访问某些成员函数,则应将它们设为 protected。
下表总结了三个访问说明符的含义:
| 访问说明符 | 含义 | 何时使用 |
|---|---|---|
public | 任何代码都可以调用对象的 public 成员函数,或访问其 public 数据成员。 | 你希望客户端使用的行为(成员函数); 以及用于访问 private 与 protected 数据成员的访问成员函数(getter / setter)。 |
protected | 类的任意成员函数都可以调用 protected 成员函数并访问 protected 数据成员。派生类的成员函数也可以访问基类中的 protected 成员。 | 你不希望客户端直接使用、但希望派生类可用的“辅助”成员函数。 |
private | 只有类自身的成员函数可以调用 private 成员函数并访问 private 数据成员。派生类成员函数不能访问基类的 private 成员。 | 默认情况下,所有东西都应是 private,尤其是数据成员。如果你只想让派生类访问,则可提供 protected 的 getter/setter; 如果你希望客户端也能访问,则提供 public 的 getter/setter。 |
C++ 允许你将一个类标记为 final,这意味着任何试图从该类继承的行为都会导致编译错误。类可以通过在类名后面紧跟 final 关键字的方式被标记为 final。例如,如果某个类试图从下面这个 Foo 类继承,编译器就会报错:
class Foo final { };重写成员函数
Section titled “重写成员函数”从一个类继承的主要原因,是为了增加功能或替换功能。前面 Derived 的定义通过添加额外的成员函数 someOtherFunction(),为其父类增加了新功能。而另一个成员函数 someFunction() 则是从 Base 继承来的,它在派生类中的行为与在基类中完全一致。在很多情况下,你会希望通过替换,也就是重写(override),某个成员函数来改变类的行为。
virtual 关键字
Section titled “virtual 关键字”仅仅在派生类中重新定义一个基类已有的成员函数,并不能正确地重写该成员函数。若要真正正确地重写一个成员函数,就需要用到 C++ 的一个新关键字 virtual。只有那些在基类中被声明为 virtual 的成员函数,才能被派生类正确地重写。这个关键字写在成员函数声明的开头,如下所示,这是修改后的 Base 版本:
class Base{ public: virtual void someFunction(); // Remainder omitted for brevity.};Derived 类也是一样。如果你希望它的成员函数在更深层的派生类中还能继续被重写,那么这些成员函数也应标记为 virtual:
class Derived : public Base{ public: virtual void someOtherFunction();};请注意,在成员函数定义前不需要重复写 virtual,例如:
void Base::someFunction(){ println("This is Base's version of someFunction().");}试图在派生类中重写一个基类的非 virtual 成员函数时,实际上只会隐藏(hide)基类定义,而该新版本只会在派生类语境中被使用。
重写成员函数的语法
Section titled “重写成员函数的语法”若要重写一个成员函数,你需要在派生类定义中重新声明它,并保持与基类声明完全相同的签名,同时添加 override 关键字,并去掉 virtual 关键字。例如,如果你想在 Derived 类中为 someFunction() 提供一个新定义,那么首先必须像下面这样把它添加到 Derived 的类定义中:
class Derived : public Base{ public: void someFunction() override; // Overrides Base's someFunction() virtual void someOtherFunction();};someFunction() 的新定义与 Derived 的其他成员函数定义一起给出。和 virtual 一样,你也不需要在成员函数定义中重复写 override:
void Derived::someFunction(){ println("This is Derived's version of someFunction().");}如果你愿意,也可以在被重写的成员函数前继续写上 virtual,不过这只是冗余。如下所示:
class Derived : public Base{ public: virtual void someFunction() override; // Overrides Base's someFunction()};一旦某个成员函数或析构函数被标记为 virtual,那么对于它的所有派生类来说,它始终都是 virtual,即使在派生类中省略了 virtual 关键字也是如此。
从客户端视角看被重写的成员函数
Section titled “从客户端视角看被重写的成员函数”有了前面的修改后,其他代码调用 someFunction() 的方式与之前完全一样。就像之前那样,这个成员函数既可以在 Base 类型对象上调用,也可以在 Derived 类型对象上调用。不过,现在 someFunction() 的行为会随对象所属的类而变化。
例如,下面这段代码依然与之前一样工作,调用的是 Base 版本的 someFunction():
Base myBase;myBase.someFunction(); // Calls Base's version of someFunction().它的输出如下:
This is Base's version of someFunction().如果代码声明的是 Derived 类型对象,那么另一个版本就会自动被调用:
Derived myDerived;myDerived.someFunction(); // Calls Derived's version of someFunction()这次输出如下:
This is Derived's version of someFunction().Derived 类对象的其他一切仍然与之前相同。那些从 Base 继承来的其他成员函数,除非在 Derived 中被显式重写,否则仍然沿用 Base 提供的定义。
正如你前面学到的那样,指针或引用可以引用某个类的对象,也可以引用其任意派生类对象。对象本身“知道”自己实际上属于哪个类,因此,只要这个成员函数被声明为 virtual,就会调用正确的成员函数版本。例如,如果你有一个 Base 引用,但它实际引用的是一个 Derived 对象,那么调用 someFunction() 时,真正执行的其实是派生类版本,如下所示。请注意,如果你在基类中省略了 virtual 关键字,这种重写行为就不会正确工作。
Derived myDerived;Base& ref { myDerived };ref.someFunction(); // Calls Derived's version of someFunction()请记住,尽管 Base 引用或指针知道自己实际引用的是一个 Derived 实例,你依然不能通过它访问那些未在 Base 中定义的 Derived 类成员。下面的代码无法编译,因为 Base 引用并没有名为 someOtherFunction() 的成员函数:
Derived myDerived;Base& ref { myDerived };myDerived.someOtherFunction(); // This is fine.ref.someOtherFunction(); // Error不过,这种“派生类知识”对于非指针、非引用对象并不成立。你可以把一个 Derived 转换或赋值给一个 Base,因为 Derived is-a Base。但是,一旦发生这种情况,对象就会丢失有关 Derived 类的任何“独特性”信息。
Derived myDerived;Base assignedObject { myDerived }; // Assigns a Derived to a Base.assignedObject.someFunction(); // Calls Base's version of someFunction()要记住这种看似奇怪的行为,一个办法是想象对象在内存中的样子。把 Base 对象想象成一个占据固定大小内存的盒子。Derived 对象则是一个稍大一点的盒子,因为它包含了 Base 的全部内容,外加更多一点。不管你通过 Derived 还是 Base 的引用/指针去访问一个 Derived,那个盒子本身都没有变——你只是多了一种访问它的方式。然而,当你把一个 Derived 转成 Base 时,你是在丢弃 Derived 类的一切“独特性”,从而把它塞进更小的盒子中。
override 关键字
Section titled “override 关键字”override 关键字是可选的,但强烈建议使用。如果不写这个关键字,那么你可能会在派生类里意外创建出一个新的(virtual)成员函数,而不是正确地重写基类中的成员函数,从而实际上把基类成员函数隐藏起来。来看下面这组 Base 和 Derived 类,其中 Derived 正在正确重写 someFunction(),但没有使用 override 关键字:
class Base{ public: virtual void someFunction(double d);};
class Derived : public Base{ public: virtual void someFunction(double d);};你可以像下面这样通过一个引用来调用 someFunction():
Derived myDerived;Base& ref { myDerived };ref.someFunction(1.1); // Calls Derived's version of someFunction()这会正确调用 Derived 类中被重写后的 someFunction()。现在,假设你在重写 someFunction() 时,不小心把参数写成了整数而不是 double,如下所示:
class Derived : public Base{ public: virtual void someFunction(int i);};这段代码并不会重写 Base 中的 someFunction(),而是创建了一个新的 virtual 成员函数。如果你像下面这样通过 Base 引用去调用 someFunction(),那最终调用的将是 Base 中的 someFunction(),而不是 Derived 的版本!
Derived myDerived;Base& ref { myDerived };ref.someFunction(1.1); // Calls Base's version of someFunction()这种问题很容易出现在你修改了 Base 类,却忘记同步更新所有派生类的时候。例如,也许你最初版本的 Base 类里,someFunction() 接受的是整数。于是你编写了 Derived 类,重写了这个接受整数的 someFunction()。后来你决定 Base 里的 someFunction() 应当接受 double 而不是整数,于是你更新了 Base 类中的 someFunction()。这时完全有可能因为疏忽,忘记把派生类中的重写版本也从接受整数改为接受 double。一旦忘了这一点,你实际上就不是在正确地重写基类成员函数,而是在创建一个新的 virtual 成员函数。
你可以通过使用 override 关键字来避免这种情况,如下所示:
class Derived : public Base{ public: void someFunction(int i) override;};这个 Derived 定义会触发编译错误,因为当你写下 override 关键字时,你其实是在告诉编译器: 这个 someFunction() 本应重写某个基类成员函数,但 Base 类中并没有接受整数的 someFunction(),只有一个接受 double 的版本。
当你在基类中重命名某个成员函数,却忘记同步重命名派生类中的重写版本时,也会发生类似的“意外创建了新成员函数”问题。
凡是本意是要重写基类成员函数的成员函数,都应当始终使用 override 关键字。
virtual 的真相
Section titled “virtual 的真相”到这里,你已经知道: 如果一个成员函数不是 virtual,那么试图在派生类中重写它时,实际上只是把基类版本隐藏了。本节将进一步探讨编译器是如何实现 virtual 成员函数的,它带来的性能影响又是什么,同时还会讨论 virtual 析构函数的重要性。
virtual 的实现方式
Section titled “virtual 的实现方式”若要理解“隐藏基类成员函数”是如何被避免的,你需要进一步了解 virtual 关键字究竟做了什么。当一个类在 C++ 中被编译时,会生成一个二进制对象,其中包含该类的所有成员函数。在非 virtual 的情况下,控制转移到合适成员函数的代码是直接根据编译期类型硬编码在调用点上的。这称为静态绑定(static binding),也叫早绑定(early binding)。
如果成员函数被声明为 virtual,那么正确的实现会借助一块称为 vtable(即 virtual table, 虚函数表) 的特殊内存区域来调用。每个拥有一个或多个虚成员函数的类都有一张 vtable,而该类的每个对象中都包含一个指向对应 vtable 的指针。vtable 中存放的是这些 virtual 成员函数实现的指针。这样一来,当你通过对象的指针或引用调用某个成员函数时,就会先通过其 vtable 指针找到对应实现,并根据对象在运行期的实际类型执行合适的成员函数版本。这称为动态绑定(dynamic binding),也叫晚绑定(late binding)。必须记住,这种动态绑定只在通过对象的指针或引用调用时才会生效。如果你直接在对象本身上调用一个 virtual 成员函数,那么这个调用仍然会使用在编译期解析好的静态绑定。
为了更好地理解 vtable 是如何让成员函数重写成为可能的,来看下面这组 Base 和 Derived 类:
class Base{ public: virtual void func1(); virtual void func2(); void nonVirtualFunc();};
class Derived : public Base{ public: void func2() override; void nonVirtualFunc();};在这个例子中,假设你有如下两个实例:
Base myBase;Derived myDerived;图 10.5 展示了这两个实例的 vtable 的高层视图。myBase 对象包含一个指向其 vtable 的指针。这张 vtable 有两个表项,分别对应 func1() 和 func2()。这些表项分别指向 Base::func1() 与 Base::func2() 的实现。
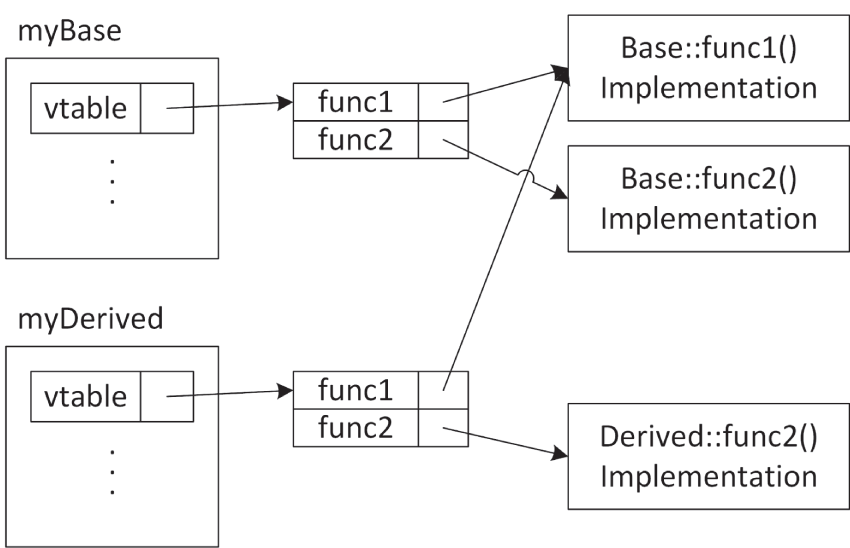
[^图 10.5]
myDerived 同样也包含一个指向其 vtable 的指针,这张 vtable 也有两个表项,分别对应 func1() 与 func2()。其中 func1() 这一项指向 Base::func1(),因为 Derived 并没有重写 func1()。而 func2() 这一项则指向 Derived::func2()。
请注意,这两张 vtable 中都没有 nonVirtualFunc() 的条目,因为该成员函数并不是 virtual。
为什么需要 virtual
Section titled “为什么需要 virtual”在某些语言中,例如 Java,所有成员函数天生都是 virtual,因此它们都可以被正确地重写。而在 C++ 中并不是这样。反对“把一切都做成 virtual”的主要理由——也正是当初引入这个关键字的原因——在于 vtable 带来的开销。为了调用一个 virtual 成员函数,程序需要额外执行一次操作,即解引用指向合适实现代码的那个指针。在大多数情况下,这个性能损耗都微乎其微,但 C++ 的设计者认为,至少在当时,最好还是由程序员自己来决定这点性能损耗是否必要。如果某个成员函数永远都不会被重写,那么就没必要把它声明为 virtual 并承担这点性能开销。不过,在今天的 CPU 上,这点开销通常只是纳秒的几分之一,而随着未来 CPU 的发展,它只会越来越小。在绝大多数应用中,你几乎测不出使用 virtual 成员函数与避免使用它们之间的性能差异。
不过,在某些特定场景中,这点性能开销仍然可能昂贵得无法接受,于是你确实需要一种机制来避免它。例如,假设你有一个 Point 类,其中带有 virtual 成员函数。如果你还有另一个数据结构,它会存储数百万甚至数十亿个 Point,那么在每个点上调用虚成员函数的开销就会积少成多。在这种情况下,或许就应当避免在 Point 类中使用任何 virtual 成员函数。
每个对象的内存占用也会有极其微小的额外成本。除了成员函数实现本身之外,每个对象还需要保存一个指向其 vtable 的指针,而这会占用少量额外空间。在绝大多数场景下,这根本不是问题。不过,有时它确实会变得重要。继续以前面的 Point 类和那个存储数十亿个 Point 的容器为例,此时额外占用的内存就可能变得很可观。
为什么必须使用 virtual 析构函数
Section titled “为什么必须使用 virtual 析构函数”析构函数几乎总是应当是 virtual 的。如果把析构函数写成非 virtual,那么就非常容易出现对象析构时无法释放内存的情况。只有当一个类被标记为 final 时,它的析构函数才可以不做成 virtual。
例如,如果某个派生类在构造函数中动态分配了内存,并在析构函数中释放它,那么只要析构函数没有被调用,这块内存就永远不会被释放。同样地,如果派生类中含有那种会在对象析构时自动被删除的成员,例如 std::unique_ptr,那么一旦析构函数没有被调用,这些成员也都不会被销毁。
下面的代码展示了,如果析构函数不是 virtual,那么其实很容易“骗过”编译器,让它跳过析构函数调用:
class Base{ public: Base() = default; ~Base() {}};
class Derived : public Base{ public: Derived() { m_string = new char[30]; println("m_string allocated"); }
~Derived() { delete[] m_string; println("m_string deallocated"); } private: char* m_string;};
int main(){ Base* ptr { new Derived {} }; // m_string is allocated here. delete ptr; // ~Base is called, but not ~Derived because the destructor // is not virtual!}从下面的输出可以看出,Derived 对象的析构函数从未被调用,也就是说,信息 “m_string deallocated” 根本不会显示:
m_string allocated从技术上讲,前面那段代码里 delete 调用的行为在标准层面是未定义的。对于这种未定义情形,C++ 编译器理论上可以做任何事。不过,大多数编译器只是简单地调用基类析构函数,而不会调用派生类析构函数。
修复方法是把基类中的析构函数标记为 virtual。如果你不需要在该析构函数中执行额外工作,但又希望它是 virtual,那么可以显式将其默认化。示例如下:
class Base{ public: Base() = default; virtual ~Base() = default;};做完这个修改后,输出就会如预期那样:
m_string allocatedm_string deallocated请注意,自 C++11 起,如果某个类声明了用户自定义析构函数,那么为其生成拷贝构造函数和拷贝赋值运算符的行为就被弃用了。基本上,一旦你声明了用户自定义析构函数,规则五(rule of five)就会介入。这意味着你需要声明拷贝构造函数、拷贝赋值运算符、移动构造函数和移动赋值运算符,必要时也许要通过显式默认化它们来完成。为了保持本章示例简洁且聚焦,这里的例子没有这样做。
除非你有非常具体的理由不这样做,或者该类已被标记为 final,否则析构函数都应标记为 virtual。构造函数不能也不需要是 virtual,因为在创建对象时你总是明确指定了正在构造的确切类。
前面本章曾建议: 凡是本意要重写基类成员函数的成员函数,都应使用 override 关键字。实际上,析构函数同样也可以使用 override。这样做可以确保: 如果基类中的析构函数不是 virtual,编译器就会报错。virtual、override 与 default 是可以组合起来使用的。示例如下:
class Derived : public Base{ public: virtual ~Derived() override = default;};除了可以把整个类标记为 final 之外,C++ 还允许你把单个成员函数标记为 final。这种成员函数在更进一步的派生类中就不能再被重写了。例如,如果你试图在 DerivedDerived 中重写下面这个 Derived 类里的 someFunction(),就会触发编译错误:
class Base{ public: virtual ~Base() = default; virtual void someFunction();};class Derived : public Base{ public: void someFunction() override final;};class DerivedDerived : public Derived{ public: void someFunction() override; // Compilation error.};为复用而继承
Section titled “为复用而继承”现在你已经熟悉了继承的基本语法,接下来该探讨继承为何是 C++ 语言中如此重要的一项特性了。继承是一种载体,它使你能够借用和复用既有代码。本节将通过一个示例来展示: 如何为了代码复用而使用继承。
WeatherPrediction 类
Section titled “WeatherPrediction 类”假设你接到的任务是编写一个程序,用于给出简单的天气预测,并且既要支持华氏温度,也要支持摄氏温度。作为程序员,天气预测可能稍微超出了你的专业领域,于是你获得了一个第三方类库,它能够基于当前气温以及木星与火星之间的当前距离来做天气预测(嘿,听上去也还算 plausible)。这个第三方包以编译后库的形式分发,用以保护天气预测算法的知识产权,不过你仍然可以看到它的类定义。weather_prediction 模块接口文件如下:
export module weather_prediction;import std;// Predicts the weather using proven new-age techniques given the current// temperature and the distance from Jupiter to Mars. If these values are// not provided, a guess is still given but it's only 99% accurate.export class WeatherPrediction{ public: // Virtual destructor virtual ~WeatherPrediction(); // Sets the current temperature in Fahrenheit virtual void setCurrentTempFahrenheit(int temp); // Sets the current distance between Jupiter and Mars virtual void setPositionOfJupiter(int distanceFromMars); // Gets the prediction for tomorrow's temperature virtual int getTomorrowTempFahrenheit() const; // Gets the probability of rain tomorrow. 1 means // definite rain. 0 means no chance of rain. virtual double getChanceOfRain() const; // Displays the result to the user in this format: // Result: x.xx chance. Temp. xx virtual void showResult() const; // Returns a string representation of the temperature virtual std::string getTemperature() const; private: int m_currentTempFahrenheit { 0 }; int m_distanceFromMars { 0 };};请注意,这个类把所有成员函数都标记成了 virtual,因为该类假定它们都有可能在派生类中被重写。
这个类为你的程序解决了大部分问题。不过,就像通常发生的那样,它并没有完全满足你的需求。首先,所有温度都以华氏度表示,而你的程序还需要支持摄氏度。其次,showResult() 成员函数展示结果的方式也许并不符合你的要求。
在派生类中增加功能
Section titled “在派生类中增加功能”在 第 5 章 中学习继承时,最先介绍的技巧之一就是“增加功能”。从本质上讲,你的程序需要一个和 WeatherPrediction 类非常相似的东西,但还要附带一点额外的小功能。听起来这正是一个借助继承来复用代码的好场景。首先,定义一个新类 MyWeatherPrediction,让它继承自 WeatherPrediction:
import weather_prediction;
export class MyWeatherPrediction : public WeatherPrediction{};前面的类定义完全可以正常编译。MyWeatherPrediction 已经可以直接替代 WeatherPrediction 使用。它提供了相同的功能,只是暂时还没有任何新增内容。针对第一个修改需求,你可能想要让该类懂得摄氏温标。这里有一点小麻烦,因为你并不知道这个类的内部究竟如何工作。如果内部所有计算都是用华氏度完成的,那你该如何增加摄氏度支持呢? 其中一个办法,就是把派生类当作中间层: 它一头面向可以使用任意温标的用户,另一头面向只懂华氏度的基类。
要支持摄氏度,第一步是添加新的成员函数,让客户端既可以用摄氏度来设置当前温度,又可以用摄氏度来获取明天的预测温度。同时,你还需要一些 private 辅助函数,分别负责摄氏度与华氏度之间的双向转换。由于这些函数对于所有类实例都相同,因此它们可以被声明为 static。
export class MyWeatherPrediction : public WeatherPrediction{ public: virtual void setCurrentTempCelsius(int temp); virtual int getTomorrowTempCelsius() const; private: static int convertCelsiusToFahrenheit(int celsius); static int convertFahrenheitToCelsius(int fahrenheit);};这些新成员函数沿用了父类的命名风格。请记住,从其他代码的视角来看,一个 MyWeatherPrediction 对象同时拥有 MyWeatherPrediction 和 WeatherPrediction 中定义的全部功能。沿用父类命名风格能够呈现出一致的接口。
摄氏度/华氏度转换函数的实现就留给读者作为练习——而且还是个挺有趣的练习! 另外两个成员函数则更有意思。若要以摄氏度设置当前温度,你需要先完成温度转换,然后再把这个结果以基类能够理解的单位传递给它:
void MyWeatherPrediction::setCurrentTempCelsius(int temp){ int fahrenheitTemp { convertCelsiusToFahrenheit(temp) }; setCurrentTempFahrenheit(fahrenheitTemp);}如你所见,一旦温度完成转换,该成员函数就会直接调用基类中已有的功能。类似地,getTomorrowTempCelsius() 的实现会先借助父类的现有功能获取华氏温度,再在返回前把结果转换为摄氏度:
int MyWeatherPrediction::getTomorrowTempCelsius() const{ int fahrenheitTemp { getTomorrowTempFahrenheit() }; return convertFahrenheitToCelsius(fahrenheitTemp);}这两个新成员函数实际上就是在复用父类: 它们以一种新的使用接口把现有功能“包裹”了起来。
你当然也可以添加那些与父类既有功能完全无关的新功能。例如,你可以添加一个成员函数,用来从互联网获取其他天气预报,或者添加一个成员函数,根据预测天气来给出活动建议。
在派生类中替换功能
Section titled “在派生类中替换功能”继承的另一大技巧是替换已有功能。WeatherPrediction 类里的 showResult() 成员函数急需一次大换脸。MyWeatherPrediction 可以重写这个成员函数,用自己的实现来替代原有行为。
MyWeatherPrediction 的新类定义如下:
export class MyWeatherPrediction : public WeatherPrediction{ public: virtual void setCurrentTempCelsius(int temp); virtual int getTomorrowTempCelsius() const; void showResult() const override; private: static int convertCelsiusToFahrenheit(int celsius); static int convertFahrenheitToCelsius(int fahrenheit);};下面是一个全新且更友好的 showResult() 重写实现:
void MyWeatherPrediction::showResult() const{ println("Tomorrow will be {} degrees Celsius ({} degrees Fahrenheit)", getTomorrowTempCelsius(), getTomorrowTempFahrenheit()); println("Chance of rain is {}%", getChanceOfRain() * 100); if (getChanceOfRain()> 0.5) { println("Bring an umbrella!"); }}对于使用这个类的客户端来说,旧版 showResult() 就像从未存在过一样。只要对象的真实类型是 MyWeatherPrediction,被调用的就永远是这个新版本。经过这些修改后,MyWeatherPrediction 已经演化成一个全新的类: 它拥有面向更具体用途的新功能,同时几乎没写多少额外代码,因为它充分借用了其基类中已有的功能。
尊重你的父类
Section titled “尊重你的父类”在编写派生类时,你必须意识到父类与子类之间的相互作用。像创建顺序、构造函数链以及类型转换这样的议题,都可能成为 bug 的来源。
父类构造函数
Section titled “父类构造函数”对象不会一下子凭空完整出现; 它们必须连同自己的父类以及所包含的对象一起被构造出来。C++ 将创建顺序定义如下:
- 如果该类有基类,那么会先执行基类的默认构造函数; 但如果在 ctor-initializer 中显式调用了某个基类构造函数,那么就会改为调用那个构造函数,而不是默认构造函数。
- 该类的非
static数据成员会按照它们在类中声明的顺序被构造。 - 最后执行该类构造函数的函数体。
这些规则还会递归应用。如果一个类还有祖父类,那么祖父类会先于父类被初始化,依此类推。下面这段代码展示了这种创建顺序。若运行正常,其输出会是 123。
class Something{ public: Something() { print("2"); }};
class Base{ public: Base() { print("1"); }};
class Derived : public Base{ public: Derived() { print("3"); } private: Something m_dataMember;};
int main(){ Derived myDerived;}当 myDerived 对象被创建时,首先调用的是 Base 的构造函数,因此输出字符串 "1"。接着初始化 m_dataMember,这会调用 Something 的构造函数,输出字符串 "2"。最后才调用 Derived 的构造函数,输出 "3"。
请注意,Base 的构造函数是自动被调用的。如果父类存在默认构造函数,C++ 会自动调用它。如果父类不存在默认构造函数,或者虽然存在但你想改用另一个父类构造函数,那么你也可以像初始化数据成员那样,在 ctor-initializer 中对构造函数进行链式调用(chain)。例如,下面的代码展示了一个没有默认构造函数的 Base 版本。对应的 Derived 版本就必须显式告诉编译器该如何调用 Base 的构造函数,否则代码无法编译。
class Base{ public: explicit Base(int i) {}};
class Derived : public Base{ public: Derived() : Base { 7 } { /* Other Derived's initialization … */ }};这个 Derived 构造函数会把一个固定值(7)传给 Base 构造函数。当然,Derived 也完全可以传入一个变量:
Derived::Derived(int i) : Base { i } { /* Other Derived's initialization … */ }从派生类向基类传递构造函数参数完全没有问题,而且这是非常常见的做法。不过,如果传递的是数据成员,那就行不通了。代码也许能编译,但请记住,数据成员只有在基类构造完成之后才会被初始化。如果你把某个数据成员当作参数传给父类构造函数,那么它在那个时刻其实还是未初始化的。
父类析构函数
Section titled “父类析构函数”由于析构函数不能接受参数,因此语言总是能够自动调用父类的析构函数。析构顺序很方便地正好与构造顺序相反:
- 先执行该类析构函数的函数体。
- 接着按与构造相反的顺序销毁该类的数据成员。
- 最后销毁父类(如果存在)。
同样地,这些规则也会递归适用。继承链中最底层的成员总是最先被析构。下面的代码在前面示例基础上加入了析构函数。请注意,这些析构函数全部都被声明成了 virtual! 如果运行这段代码,输出将是 123321。
class Something{ public: Something() { print("2"); } virtual ~Something() { print("2"); }};
class Base{ public: Base() { print("1"); } virtual ~Base() { print("1"); }};
class Derived : public Base{ public: Derived() { print("3"); } virtual ~Derived() override { print("3"); } private: Something m_dataMember;};如果前面的析构函数没有声明为 virtual,代码表面上看起来似乎也能正常工作。不过,一旦某段代码对一个实际上指向 Derived 实例的 Base 指针执行 delete,那么析构链就会从错误的位置开始。例如,如果你把前面代码里所有析构函数上的 virtual 和 override 关键字都去掉,那么当一个 Derived 对象通过 Base 指针访问并删除时,问题就出现了,如下所示:
Base* ptr { new Derived{} };delete ptr;这段代码的输出会让人震惊地简短: 1231。当 ptr 变量被删除时,由于析构函数没有声明为 virtual,因此只会调用 Base 的析构函数。结果就是,Derived 的析构函数不会被调用,而它那些数据成员的析构函数也同样不会被调用!
从技术上讲,要修复这个问题,你只需把 Base 的析构函数标记为 virtual 就够了。因为“虚属性”会自动作用于任何派生类。不过,我更提倡显式把所有析构函数都写成 virtual,这样你就永远不必再为此操心。
始终把你的析构函数写成 virtual! 编译器生成的默认析构函数并不是 virtual,因此至少对于那些不是 final 的基类,你都应当自己定义(或显式默认化)一个 virtual 析构函数。
在构造函数和析构函数中调用 virtual 成员函数
Section titled “在构造函数和析构函数中调用 virtual 成员函数”virtual 成员函数在构造函数和析构函数中的行为有所不同。如果你的派生类重写了某个基类的 virtual 成员函数,那么从基类构造函数或析构函数中调用这个成员函数时,执行的会是基类实现,而不是派生类中你重写后的那个版本! 换句话说,发生在构造函数或析构函数内部的 virtual 成员函数调用,会在编译期以静态方式解析。
构造函数之所以这样,原因与构造派生类实例时的初始化顺序有关。创建派生类实例时,任何基类的构造函数都会先执行,而此时派生类实例尚未完成初始化。因此,如果在这个阶段就调用尚未完全初始化好的派生类中的重写 virtual 成员函数,将是非常危险的。由于对象析构时也存在相应的销毁顺序,析构函数中的情况同理。
如果你确实需要在构造函数中拥有多态行为——尽管并不推荐——你可以在基类中定义一个 initialize() virtual 成员函数,并让派生类去重写它。这样一来,创建你这个类实例的客户端代码就必须在构造完成之后,再调用这个 initialize() 成员函数。
类似地,如果你在析构之前确实需要某种多态行为——同样不推荐——那么你也可以定义一个 shutdown() virtual 成员函数,让客户端在对象被销毁前显式调用它。
引用父类名字
Section titled “引用父类名字”当你在派生类中重写一个成员函数时,从其他代码的视角来看,你实际上已经把原来的那个成员函数替换掉了。不过,父类版本的成员函数依然存在,而你有时可能会希望用到它。例如,某个被重写的成员函数也许想保留基类实现所做的一切,并在此基础上再额外做一些事情。来看 WeatherPrediction 类中的 getTemperature() 成员函数,它会返回当前温度的 string 表示:
export class WeatherPrediction{ public: virtual std::string getTemperature() const; // Remainder omitted for brevity.};你可以在 MyWeatherPrediction 类中这样重写这个成员函数:
export class MyWeatherPrediction : public WeatherPrediction{ public: std::string getTemperature() const override; // Remainder omitted for brevity.};假设派生类想在这个字符串末尾加上 °F,办法是先调用基类的 getTemperature() 成员函数,然后再把 °F 追加上去。你也许会像下面这样写:
string MyWeatherPrediction::getTemperature() const{ // Note: \u00B0 is the ISO/IEC 10646 representation of the degree symbol. return getTemperature() + "\u00B0F"; // BUG}然而,这样是行不通的。因为按照 C++ 的名字解析规则,它会先在局部作用域中解析,然后再在类作用域中解析,最终结果是它又调用回了 MyWeatherPrediction::getTemperature() 自己。这样就会导致无限递归,直到栈空间耗尽(有些编译器会检测到这个错误,并在编译期就报出来)。
若要让它工作,你需要像下面这样使用作用域解析运算符:
string MyWeatherPrediction::getTemperature() const{ // Note: \u00B0 is the ISO/IEC 10646 representation of the degree symbol. return WeatherPrediction::getTemperature() + "\u00B0F";}调用当前成员函数的父类版本,是 C++ 中一个非常常见的模式。如果你拥有一条由多个派生类组成的继承链,那么其中每一层派生类都可能希望先执行基类中已经定义好的操作,然后再附加上自己的额外功能。
我们再来看一个例子。假设存在一个图书类型的类层次结构,如 图 10.6 所示。
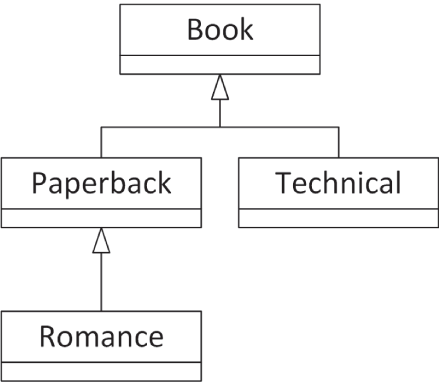
[^图 10.6]
由于这个层次结构中越往下的类,对图书类型的描述就越具体,因此一个用来获取图书描述的成员函数实际上就需要把整个继承层次中的所有级别都考虑进去。这可以通过链式调用父类成员函数来实现。下面的代码展示了这种模式:
class Book{ public: virtual ~Book() = default; virtual string getDescription() const { return "Book"; } virtual int getHeight() const { return 120; }};
class Paperback : public Book{ public: string getDescription() const override { return "Paperback " + Book::getDescription(); }};
class Romance : public Paperback{ public: string getDescription() const override { return "Romance " + Paperback::getDescription(); } int getHeight() const override { return Paperback::getHeight() / 2; }};
class Technical : public Book{ public: string getDescription() const override { return "Technical " + Book::getDescription(); }};
int main(){ Romance novel; Book book; println("{}", novel.getDescription()); // Outputs "Romance Paperback Book" println("{}", book.getDescription()); // Outputs "Book" println("{}", novel.getHeight()); // Outputs "60" println("{}", book.getHeight()); // Outputs "120"}Book 基类中有两个 virtual 成员函数:getDescription() 和 getHeight()。所有派生类都重写了 getDescription(),但只有 Romance 类通过调用其父类(Paperback)上的 getHeight(),并将结果除以二,来重写了 getHeight()。Paperback 本身并没有重写 getHeight(),但 C++ 会沿着类层次结构向上查找那个真正实现了 getHeight() 的类。在这个例子中,Paperback::getHeight() 最终会解析到 Book::getHeight()。
向上转换与向下转换
Section titled “向上转换与向下转换”正如你前面已经看到的那样,一个对象可以被转换或赋值为其父类。示例如下:
Derived myDerived;Base myBase { myDerived }; // Slicing!在这种情况下就会发生 slicing,因为最终结果是一个 Base 对象,而 Base 对象并不具备 Derived 类中定义的那些额外功能。不过,如果把派生类赋给其基类的指针或引用,那就不会发生 slicing:
Base& myBase { myDerived }; // No slicing!这通常才是以基类形式引用派生类的正确方式,也就是所谓的向上转换(upcasting)。这也是为什么,函数总是应当尽量接受对类的引用,而不是直接按值使用那些类对象的原因。通过引用,派生类就可以在不发生 slicing 的情况下被传入。
做向上转换时,请使用指向基类的指针或引用,以避免 slicing。
而从基类向其某个派生类进行转换,也就是所谓的向下转换(downcasting),通常会被专业 C++ 程序员所警惕,因为你根本无法保证这个对象真的属于那个派生类,而且向下转换往往也是设计不佳的征兆。例如,考虑如下代码:
void presumptuous(Base* base){ Derived* myDerived { static_cast<Derived*>(base) }; // Proceed to access Derived member functions on myDerived.}如果 presumptuous() 的作者也恰好编写了调用它的那段代码,那事情大概率不会出问题——尽管仍然很丑陋——因为作者知道这个函数预期接收到的其实是 Derived* 类型参数。然而,如果有其他程序员去调用 presumptuous(),他们就可能传进来一个 Base*。编译期没有任何办法强制检查这种参数类型,而该函数却一厢情愿地假定 base 实际上就是一个指向 Derived 对象的指针。
向下转换有时确实是必要的,而且在受控场景下也可以被有效使用。不过,如果你确实必须做向下转换,那就应当使用 dynamic_cast(),因为它会借助对象对自身类型的内建认知,拒绝那些不合理的转换。这种内建的类型认知通常就保存在 vtable 中,这意味着 dynamic_cast() 只能用于带有 vtable 的对象,也就是至少拥有一个 virtual 成员的对象。如果一个针对指针的 dynamic_cast() 失败,结果将是 nullptr,而不是一个指向毫无意义数据的指针。如果一个针对对象引用的 dynamic_cast() 失败,则会抛出 std::bad_cast 异常。本章最后一节会更详细地讨论各种类型转换选项。
前面的例子可以改写成下面这样:
void lessPresumptuous(Base* base){ Derived* myDerived { dynamic_cast<Derived*>(base) }; if (myDerived != nullptr) { // Proceed to access Derived member functions on myDerived. }}不过,仍然要记住: 向下转换的使用往往是设计欠佳的信号。你应当重新思考并修改设计,尽量让向下转换不再需要。例如,lessPresumptuous() 实际上只对 Derived 对象真正有效,那它就不应该接受一个 Base 指针,而应当直接接受一个 Derived 指针。这样就彻底消除了向下转换的需要。如果该函数需要同时适用于多个不同的派生类,而它们都继承自 Base,那么就该去寻找一种利用多态的解决方案——这正是下一节要讨论的内容。
只有在真正必要时才使用向下转换,并且一定要使用 dynamic_cast()。
为多态而继承
Section titled “为多态而继承”现在你已经理解了派生类与其父类之间的关系,接下来就可以把继承用于它最强大的场景——多态。第 5 章 已经讨论过,多态使你能够把拥有共同父类的对象互换使用,也能够用子类对象来代替其父类对象。
Spreadsheet 的回归
Section titled “Spreadsheet 的回归”第 8 章 和 第 9 章 使用电子表格程序作为一个非常适合面向对象设计的应用示例。SpreadsheetCell 代表一个单独的数据单元。到目前为止,这个单元始终只存储一个 double 值。下面是一个简化版的 SpreadsheetCell 类定义。请注意,一个单元格既可以通过 double 设置,也可以通过 string_view 设置,但在这个例子中,它始终以 double 形式存储。不过,单元格当前值总是以 string 形式返回。
class SpreadsheetCell{ public: virtual void set(double value); virtual void set(std::string_view value); virtual std::string getString() const; private: static std::string doubleToString(double value); static double stringToDouble(std::string_view value); double m_value;};而在真正的电子表格应用中,单元格可以存储各种不同的东西。某个单元格可以存储 double,但也完全可能只是存储一段文本。还可能需要额外类型的单元格,例如公式单元格或日期单元格。那该如何支持这些类型呢?
设计多态的 SpreadsheetCell
Section titled “设计多态的 SpreadsheetCell”SpreadsheetCell 类简直在大声呼喊,要求被改造成一个层次结构。一个看似合理的做法,是把 SpreadsheetCell 的职责收窄为只处理 string,甚至顺便把它重命名为 StringSpreadsheetCell。若要处理 double,则可以再定义第二个类 DoubleSpreadsheetCell,让它继承自 StringSpreadsheetCell,并提供适合其自身格式的功能。图 10.7 展示了这样的设计。这种做法更像是在为了复用而使用继承,因为 DoubleSpreadsheetCell 从 StringSpreadsheetCell 继承,只是为了复用后者已有的一部分功能。
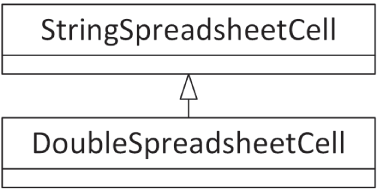
[^图 10.7]
如果你真的按 图 10.7 所示那样去实现,你很快就会发现: 派生类也许会重写基类的大多数功能,甚至几乎全部功能。因为 double 与 string 在几乎所有场景下的处理方式都不同,所以它们之间的关系其实并不像最初设想得那么贴切。不过,一个“存储字符串的单元格”和一个“存储 double 的单元格”之间显然又确实存在某种关系。与其使用 图 10.7 那种暗示 DoubleSpreadsheetCell somehow “is-a” StringSpreadsheetCell 的模型,更好的设计是让这两个类成为平级兄弟,并拥有一个共同父类 SpreadsheetCell。图 10.8 展示了这样一种设计。
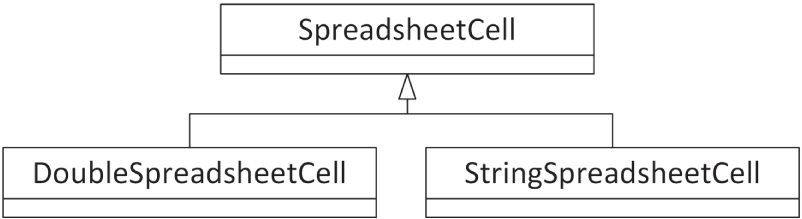
[^图 10.8]
图 10.8 所示的设计,体现的是一种面向 SpreadsheetCell 层次结构的多态方案。由于 DoubleSpreadsheetCell 与 StringSpreadsheetCell 都继承自共同父类 SpreadsheetCell,因此在其他代码看来,它们是可以互换的。用更实际的话说,这意味着:
- 这两个派生类都支持由基类定义的同一套接口(即同一组成员函数)。
- 使用
SpreadsheetCell对象的代码,可以调用接口中的任意成员函数,甚至完全不需要知道当前单元格究竟是DoubleSpreadsheetCell还是StringSpreadsheetCell。 - 借助
virtual成员函数的魔法,接口中每个成员函数最终都会根据对象所属的类,自动调用到恰当的实现版本。 - 其他数据结构——例如 第 9 章 中介绍的
Spreadsheet类——就可以通过引用基类类型的方式,在一个集合里同时容纳多种不同类型的单元格。
SpreadsheetCell 基类
Section titled “SpreadsheetCell 基类”既然所有电子表格单元格都要从 SpreadsheetCell 基类派生出来,那么先写好这个类显然是个不错的主意。在设计一个基类时,你需要认真考虑各派生类彼此之间的关系。从这些关系里,你就能够抽取出那些应当被放进父类中的共性。例如,字符串单元格与 double 单元格的共同点在于,它们都只包含一份数据。而由于这些数据既来自用户输入,最终也会回显给用户,因此值被设置时可以看作字符串,取回时也应能表示成字符串。这些行为就是构成基类的共享功能。
SpreadsheetCell 基类负责定义所有从 SpreadsheetCell 派生出来的类都必须支持的行为。在这个例子中,所有单元格都需要能够把自己的值设置为字符串; 同时,所有单元格也都需要能够把当前值作为字符串返回。因此,基类定义中声明了这些成员函数,同时还声明了一个显式默认化的 virtual 析构函数。不过请注意,它没有任何数据成员。这个定义位于一个名为 spreadsheet_cell 的模块中。
export module spreadsheet_cell;import std;
export class SpreadsheetCell{ public: virtual ~SpreadsheetCell() = default; virtual void set(std::string_view value); virtual std::string getString() const;};可一旦你开始为这个类编写 .cpp 文件,很快就会撞上一个问题。既然电子表格单元格的基类既不包含 double 数据成员,也不包含 string 数据成员,那它该如何实现呢? 更一般地说,当你想写一个基类,它只声明派生类将会支持的行为,却并不真正提供这些行为的实现时,你该怎么做?
一种可能的办法是,为这些行为提供“什么也不做”的实现。例如,在 SpreadsheetCell 基类上调用 set() 成员函数时,它不会产生任何效果,因为基类本身并没有什么可设置的内容。不过,这种做法依然让人感觉不对劲。理想情况下,根本就不应当存在一个真正属于基类本身的对象实例。调用 set() 本应始终产生效果,因为它本应总是调用在 DoubleSpreadsheetCell 或 StringSpreadsheetCell 之类的具体类对象上。一个好的解决方案应当强制保证这一点。
纯虚成员函数与抽象基类
Section titled “纯虚成员函数与抽象基类”纯虚成员函数(pure virtual member function)是指那些在类定义中被显式声明为“没有定义”的成员函数。把一个成员函数写成纯虚,就等于你在告诉编译器: 当前这个类并不提供该成员函数的定义。凡是至少含有一个纯虚成员函数的类,都称为抽象类(abstract class),因为其他代码无法实例化它。编译器会强制保证: 只要一个类含有一个或多个纯虚成员函数,它就绝不可能被用来构造出该类型对象。
有一种专门的语法可以将成员函数声明为纯虚成员函数。做法是在成员函数声明后面跟上 =0。这种情况下,你无需为它编写实现。
export class SpreadsheetCell{ public: virtual ~SpreadsheetCell() = default; virtual void set(std::string_view value) = 0; virtual std::string getString() const = 0;};一旦基类变成抽象类,你就不可能再创建 SpreadsheetCell 对象。下面这段代码无法编译,并会报出类似“SpreadsheetCell: cannot instantiate abstract class”这样的错误:
SpreadsheetCell cell; // Error! Attempts creating abstract class instance.不过,一旦 StringSpreadsheetCell 类被实现好,下面这段代码就可以正常编译,因为它实例化的是抽象基类的某个派生类:
unique_ptr<SpreadsheetCell> cell { new StringSpreadsheetCell {} };请注意,SpreadsheetCell 类本身没有任何需要实现的内容。它所有成员函数都是纯虚的,析构函数则显式默认化了。
各个具体派生类
Section titled “各个具体派生类”编写 StringSpreadsheetCell 和 DoubleSpreadsheetCell 类,本质上只是去实现父类中定义出来的那些功能。既然你希望客户端能够实例化并使用字符串单元格与 double 单元格,那么这些单元格类就不能是抽象类——它们必须实现从父类继承来的全部纯虚成员函数。如果某个派生类没有实现基类中的所有纯虚成员函数,那么它自身也仍然是抽象类,客户端也就无法实例化它的对象。
StringSpreadsheetCell 类定义
Section titled “StringSpreadsheetCell 类定义”StringSpreadsheetCell 类定义在它自己的模块 string_spreadsheet_cell 中。编写 StringSpreadsheetCell 类定义的第一步,就是让它继承自 SpreadsheetCell。为此,必须导入 spreadsheet_cell 模块。
接下来,需要重写继承而来的纯虚成员函数,这一次当然不再将它们设为 0。
最后,字符串单元格增加了一个私有数据成员 m_value,用于保存实际的单元格数据。这个数据成员是一个 std::optional,它在 第 1 章“C++ 与标准库速成”中已经介绍过。通过使用 optional,就可以区分“这个单元格的值从未被设置过”与“它被设置成了空字符串”这两种情况。
export module string_spreadsheet_cell;export import spreadsheet_cell;import std;
export class StringSpreadsheetCell : public SpreadsheetCell{ public: void set(std::string_view value) override; std::string getString() const override; private: std::optional<std::string> m_value;};StringSpreadsheetCell 实现
Section titled “StringSpreadsheetCell 实现”set() 成员函数非常直接,因为它的内部表示本来就是字符串。getString() 成员函数则必须考虑到 m_value 的类型是 optional,也就是它可能根本没有值。当 m_value 没有值时,getString() 应当返回一个默认字符串——在本例中就是空字符串。借助 optional 的 value_or() 成员函数,这一点很容易实现。通过使用 m_value.value_or(""),如果 m_value 中含有真实值,那么就返回该值; 否则就返回空字符串。
void set(std::string_view value) override { m_value = value; }std::string getString() const override { return m_value.value_or(""); }DoubleSpreadsheetCell 类定义与实现
Section titled “DoubleSpreadsheetCell 类定义与实现”double 版本遵循相似模式,但内部逻辑不同。除了从基类继承来的那个接受 string_view 的 set() 成员函数之外,它还额外提供了一个新的 set() 成员函数,让客户端可以通过 double 参数来设置值。同时,它还提供一个新的 getValue() 成员函数,用来以 double 形式取回该值。它还包含两个新的 private static 成员函数,分别负责在 string 与 double 之间双向转换。和 StringSpreadsheetCell 一样,它也有一个名为 m_value 的数据成员,不过这里它的类型是 optional<double>。
export module double_spreadsheet_cell;export import spreadsheet_cell;import std;
export class DoubleSpreadsheetCell : public SpreadsheetCell{ public: virtual void set(double value); virtual double getValue() const;
void set(std::string_view value) override; std::string getString() const override; private: static std::string doubleToString(double value); static double stringToDouble(std::string_view value); std::optional<double> m_value;};那个接受 double 的 set() 成员函数很直接,getValue() 的实现也同样 straightforward。接受 string_view 的重载则会使用 private static 成员函数 stringToDouble()。getString() 成员函数会把当前存储的 double 值作为 string 返回; 如果尚未存储任何值,则返回空字符串。这里它使用 std::optional 的 has_value() 成员函数来判断 optional 是否包含值。如果包含值,则用 value() 成员函数将其取出。
virtual void set(double value) { m_value = value; }virtual double getValue() const { return m_value.value_or(0); }
void set(std::string_view value) override { m_value = stringToDouble(value); }std::string getString() const override{ return (m_value.has_value() ? doubleToString(m_value.value()) : "");}你现在也许已经能看出,将电子表格单元格实现为层次结构所带来的一个重要优点——代码明显更简单了。每个类都可以“以自我为中心”,只专注处理自身那部分功能。
请注意,doubleToString() 和 stringToDouble() 的实现这里没有给出,因为它们与 第 8 章 中的实现相同。
既然 SpreadsheetCell 层次结构现在已经具备多态性,客户端代码就可以利用多态带来的诸多好处。下面这个测试程序会探索其中不少特性。
为了演示多态,这个测试程序声明了一个包含三个 SpreadsheetCell 指针的 vector。请记住,由于 SpreadsheetCell 是抽象类,你不能创建该类型对象本身。不过,你依然可以拥有一个指向 SpreadsheetCell 的指针或引用,因为它实际会指向某个派生类对象。这个 vector 之所以是 SpreadsheetCell 父类类型的 vector,意味着你可以在其中存储两种派生类的异构混合体。也就是说,vector 中的元素既可能是 StringSpreadsheetCell,也可能是 DoubleSpreadsheetCell。
vector<unique_ptr<SpreadsheetCell>> cellArray;vector 的前两个元素被设为指向新的 StringSpreadsheetCell,第三个则是一个新的 DoubleSpreadsheetCell。
cellArray.push_back(make_unique<StringSpreadsheetCell>());cellArray.push_back(make_unique<StringSpreadsheetCell>());cellArray.push_back(make_unique<DoubleSpreadsheetCell>());现在,既然 vector 中装的是多类型数据,那么所有由基类声明的成员函数都可以直接应用到其中的对象上。代码这里只是通过 SpreadsheetCell 指针来操作——编译器在编译期根本不知道这些对象的实际类型是什么。不过,因为这些对象都继承自 SpreadsheetCell,所以它们就必须支持 SpreadsheetCell 的那套成员函数接口。
cellArray[0]->set("hello");cellArray[1]->set("10");cellArray[2]->set("18");当调用 getString() 成员函数时,每个对象都会正确返回其值的 string 表示。这里重要而且某种程度上也很神奇的一点是: 不同对象是以不同方式完成这件事的。StringSpreadsheetCell 会返回其存储值,若没有值则返回空字符串。DoubleSpreadsheetCell 如果含有值,则先执行一次转换; 若没有值,也返回空字符串。作为程序员,你并不需要知道对象内部到底怎么实现这些——你只需要知道: 既然它是一个 SpreadsheetCell,它就能执行这项行为。
println("Vector: [{},{},{}]", cellArray[0]->getString(), cellArray[1]->getString(), cellArray[2]->getString());从面向对象设计的视角看,新的 SpreadsheetCell 层次结构无疑是比原来更好的。不过,出于多种原因,它大概仍不足以成为一个现实世界电子表格程序中真正可用的类层次结构。
首先,尽管设计改善了,但有一个特性仍然缺失: 从一种单元格类型转换到另一种单元格类型的能力。由于我们把它们拆分成了两个类,这些单元格对象之间就变得更松散了。若要支持从 DoubleSpreadsheetCell 转换到 StringSpreadsheetCell,你可以添加一个转换构造函数(converting constructor),也称为类型化构造函数(typed constructor)。它在外观上有点类似拷贝构造函数,但它接收的不是同一类对象的引用,而是某个兄弟类对象的引用。还要注意的是,此时你也必须显式声明一个默认构造函数(可以显式默认化),因为一旦你自己声明了任何构造函数,编译器就不会再自动生成默认构造函数。
export class StringSpreadsheetCell : public SpreadsheetCell{ public: StringSpreadsheetCell() = default; StringSpreadsheetCell(const DoubleSpreadsheetCell& cell) : m_value { cell.getString() } { } // Remainder omitted for brevity.};有了这个转换构造函数,你就可以很容易地根据一个 DoubleSpreadsheetCell 来创建一个 StringSpreadsheetCell。不过,别把这与“强制转换指针或引用”混为一谈。从一个兄弟类的指针或引用转换到另一个兄弟类的指针或引用,本身是行不通的,除非你像 第 15 章“重载 C++ 运算符”中所述那样,去重载类型转换运算符。
你总是可以沿着继承层次向上转换,也有时可以向下转换。而跨层次的横向转换,则只能通过改变类型转换运算符的行为,或者使用 reinterpret_cast() 来完成——这两种做法都不推荐。
其次,如何为这些单元格实现重载运算符也是一个很有意思的问题,而且存在多种可能做法。
一种做法是,为每一种单元格组合都单独实现对应版本的运算符。对于这里只有两个派生类的情况,这仍然是可管理的。比如,你可以有一个 operator+,专门处理两个 double 单元格相加; 另一个处理两个 string 单元格相加; 再另一个处理 double 单元格与 string 单元格相加。对于每一种组合,你都自行决定结果该是什么。例如,两个 double 单元格相加的结果,可以是它们数值上的数学加和。两个 string 单元格相加的结果,则可以是二者字符串拼接后的 string,等等。
另一种做法是,选定一个共同表示形式。前面的实现其实已经在某种程度上把 string 标准化成了共同表示。于是,一个单独的 operator+ 就可以借助这种共同表示来覆盖所有情况。
还有一种折中式的混合做法。你可以先提供一个 operator+,用来相加两个 DoubleSpreadsheetCell,并返回一个 DoubleSpreadsheetCell。这个运算符可以在 double_spreadsheet_cell 模块中实现如下:
export DoubleSpreadsheetCell operator+(const DoubleSpreadsheetCell& lhs, const DoubleSpreadsheetCell& rhs){ DoubleSpreadsheetCell newCell; newCell.set(lhs.getValue() + rhs.getValue()); return newCell;}这个运算符可以这样测试:
DoubleSpreadsheetCell doubleCell; doubleCell.set(8.4);DoubleSpreadsheetCell result { doubleCell + doubleCell };println("{}", result.getString()); // Prints 16.800000然后,你还可以为“至少有一个操作数是 StringSpreadsheetCell”的情况提供第二个 operator+。你也许会决定,这个运算符的结果始终应当是一个字符串单元格。这样的运算符可以加到 string_spreadsheet_cell 模块中,并按如下方式实现:
export StringSpreadsheetCell operator+(const StringSpreadsheetCell& lhs, const StringSpreadsheetCell& rhs){ StringSpreadsheetCell newCell; newCell.set(lhs.getString() + rhs.getString()); return newCell;}只要编译器有办法把某个特定单元格转换成 StringSpreadsheetCell,这个运算符就能够工作。以前面那个接受 DoubleSpreadsheetCell 参数的 StringSpreadsheetCell 构造函数为前提,编译器就会在这是让 operator+ 工作的唯一方式时,自动执行该转换。这意味着,下面这段“把一个 double 单元格加到一个 string 单元格上”的代码是可以工作的,尽管这里只提供了两个 operator+ 实现: 一个用于相加两个 double 单元格,另一个用于相加两个 string 单元格。
DoubleSpreadsheetCell doubleCell; doubleCell.set(8.4);StringSpreadsheetCell stringCell; stringCell.set("Hello ");StringSpreadsheetCell result { stringCell + doubleCell };println("{}", result.getString()); // Prints Hello 8.400000如果你对多态还有点拿不准,那就从本节这个例子的代码开始自己动手试一试。它是实验代码的一个绝佳起点,你可以在上面练习多态的各种面向。
为纯虚成员函数提供实现
Section titled “为纯虚成员函数提供实现”从技术上说,确实可以为一个纯 virtual 成员函数提供实现。这个实现不能写在类定义内部,而必须在类定义之外给出。不过,该类仍然依旧是抽象类,而且任何派生类依然都必须为这个纯 virtual 成员函数提供自己的实现。既然这个类依旧是抽象的,那么它的实例依然无法被创建。尽管如此,它对这个纯 virtual 成员函数的实现仍然可以被调用——例如从某个派生类中调用。下面的代码片段展示了这一点:
class Base{public: virtual void doSomething() = 0; // Pure virtual member function.};
// An out-of-class implementation of a pure virtual member function.void Base::doSomething() { println("Base::doSomething()"); }
class Derived : public Base{public: void doSomething() override { // Call pure virtual member function implementation from base class. Base::doSomething(); println("Derived::doSomething()"); }};
int main(){ Derived derived; Base& base { derived }; base.doSomething();}输出如预期所示:
Base::doSomething()Derived::doSomething()正如你在 第 5 章 中读到的那样,多重继承常常被视为面向对象编程中复杂且没必要的一部分。至于它是否有用,我把这个判断交给你和你的同事。本节将解释 C++ 中多重继承的运作机制。
从多个类继承
Section titled “从多个类继承”从语法角度看,定义一个拥有多个父类的类其实非常简单。你只需要在声明类名时,逐个列出所有基类即可。
class Baz : public Foo, public Bar { /* Etc. */ };通过列出多个父类,一个 Baz 对象将具备如下特征:
Baz对象同时支持Foo和Bar的public成员函数,并且也包含这两个类中的数据成员。Baz类的成员函数可以访问Foo与Bar中的protected数据及成员函数。Baz对象既可以向上转换为Foo,也可以向上转换为Bar。- 创建一个新的
Baz对象时,会自动调用Foo和Bar的默认构造函数,顺序与它们在类定义中列出的顺序一致。 - 删除一个
Baz对象时,会自动调用Foo与Bar的析构函数,顺序与它们在类定义中列出顺序相反。
下面的例子展示了一个 DogBird 类,它拥有两个父类——Dog 类和 Bird 类,如 图 10.9 所示。狗鸟(dog-bird)是个荒诞示例,并不应被解读为“多重继承本身很荒诞”。老实说,这个判断还是留给你自己。
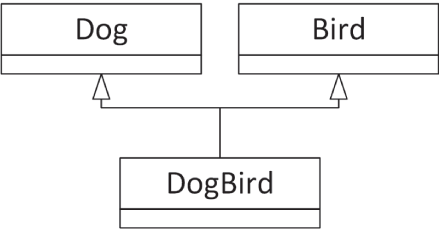
[^图 10.9]
class Dog{ public: virtual void bark() { println("Woof!"); }};
class Bird{ public: virtual void chirp() { println("Chirp!"); }};
class DogBird : public Dog, public Bird{};使用带有多个父类的类对象,与使用普通类对象并无本质区别。实际上,客户端代码甚至不必知道该类有两个父类。真正重要的只是这个类支持哪些属性和行为。在这里,DogBird 对象支持 Dog 和 Bird 的全部 public 成员函数。
DogBird myConfusedAnimal;myConfusedAnimal.bark();myConfusedAnimal.chirp();程序输出如下:
Woof!Chirp!命名冲突与歧义基类
Section titled “命名冲突与歧义基类”构造出一个“看似会让多重继承失效”的场景并不难。接下来的例子展示了一些在使用多重继承时必须考虑的边界情况。
如果 Dog 类和 Bird 类都拥有一个名为 eat() 的成员函数,那会怎样? 由于 Dog 和 Bird 彼此之间没有任何关系,其中一个版本并不会重写另一个——它们会同时继续存在于 DogBird 这个派生类中。
只要客户端代码从不尝试调用 eat() 成员函数,这就不成问题。即便 DogBird 拥有两个 eat() 版本,它依然可以正常编译。不过,一旦客户端代码试图在 DogBird 上调用 eat(),编译器就会报出错误,指出对 eat() 的调用是歧义的。编译器根本不知道该调用哪一个版本。下面的代码就会触发这种歧义错误:
class Dog{ public: virtual void bark() { println("Woof!"); } virtual void eat() { println("The dog ate."); }};
class Bird{ public: virtual void chirp() { println("Chirp!"); } virtual void eat() { println("The bird ate."); }};
class DogBird : public Dog, public Bird{};
int main(){ DogBird myConfusedAnimal; myConfusedAnimal.eat(); // Error! Ambiguous call to member function eat()}如果你把 main() 中调用 eat() 的最后一行注释掉,这段代码就能顺利编译。
解决这种歧义的方法,要么是通过 dynamic_cast() 显式将对象向上转换,本质上就是把“不想要的那个版本”从编译器视野中隐藏掉; 要么使用消歧语法(disambiguation syntax)。例如,下面的代码展示了两种调用 Dog 版本 eat() 的方式:
dynamic_cast<Dog&>(myConfusedAnimal).eat(); // Calls Dog::eat()myConfusedAnimal.Dog::eat(); // Calls Dog::eat()派生类自身的成员函数,同样也可以通过与访问父类成员函数时相同的语法,即 :: 作用域解析运算符,来显式地在多个同名成员函数之间做出区分。例如,DogBird 类可以通过定义它自己的 eat() 成员函数,从而避免其他代码中出现歧义错误。在这个成员函数内部,它会自行决定调用哪一个父类版本。
class DogBird : public Dog, public Bird{ public: void eat() override { Dog::eat(); // Explicitly call Dog's version of eat() }};还有一种避免歧义错误的方法,就是使用 using 声明显式指明 DogBird 应当继承哪一个 eat() 版本。示例如下:
class DogBird : public Dog, public Bird{ public: using Dog::eat; // Explicitly inherit Dog's version of eat()};另一种会导致歧义的情况,是从同一个类继承两次。当多个父类本身拥有共同父类时,就会发生这种事。例如,也许 Bird 和 Dog 都继承自一个 Animal 类,如 图 10.10 所示。
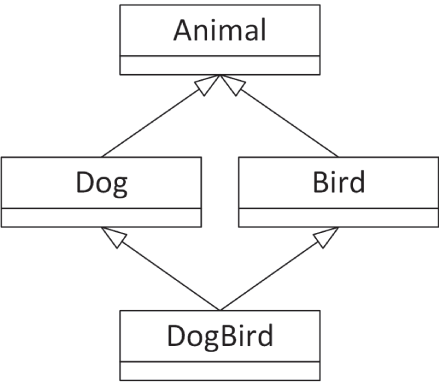
[^图 10.10]
在 C++ 中,这种类层次结构是被允许的,不过名字歧义依然可能发生。例如,如果 Animal 类有一个名为 sleep() 的 public 成员函数,那么你就无法在 DogBird 对象上调用这个成员函数,因为编译器不知道你到底是要调用经由 Dog 继承来的版本,还是经由 Bird 继承来的版本。
使用这种“菱形”类层次结构的最佳方式,是让最顶层的类成为一个抽象基类,并把它的所有成员函数都声明为纯虚。由于这个类只声明成员函数而不提供定义,因此在这个顶层基类里没有真正可调用的成员函数,从而也就不会在那个层面产生歧义。
下面的例子实现了一个菱形类层次结构,其中 Animal 抽象基类拥有一个纯虚 eat() 成员函数,每个派生类都必须为其提供定义。DogBird 类依然需要显式指明自己要使用哪一个父类的 eat() 成员函数,不过这里的歧义来自 Dog 和 Bird 同时拥有同名成员函数,而不是因为它们继承自同一个类。
class Animal{ public: virtual void eat() = 0;};
class Dog : public Animal{ public: virtual void bark() { println("Woof!"); } void eat() override { println("The dog ate."); }};
class Bird : public Animal{ public: virtual void chirp() { println("Chirp!"); } void eat() override { println("The bird ate."); }};
class DogBird : public Dog, public Bird{ public: using Dog::eat;};关于如何更优雅地处理菱形层次结构中顶层类的问题——也就是虚基类(virtual base class)——本章稍后还会继续解释。
多重继承的用途
Section titled “多重继承的用途”说到这里,你大概会开始疑惑: 程序员为什么要在自己的代码里主动去碰多重继承呢? 最直观的用途,是定义一种对象类型,它既 is-a 某物,同时也 is-a 另一物。正如 第 5 章 中所说,现实世界中那些真正符合这种模式的对象,往往并不容易被直接、自然地映射成代码。
多重继承最有说服力、同时也最简单的一种用途,是实现混入类(mixin class)。混入类在 第 5 章 中已经介绍过,并会在 第 32 章“融入设计技术与框架”中更详细讨论。
人们有时使用多重继承的另一种原因,是想把它拿来建模组件化类(component-based class)。第 5 章 中举过飞机模拟器的例子。Airplane 类拥有引擎、机身、控制系统以及其他组件。尽管 Airplane 类最常见的实现方式是把这些组件作为各自独立的数据成员,但从技术上说,你也可以用多重继承。飞机类可以从 engine、fuselage 和 controls 继承,从而“获得”其所有组件的行为与属性。我不建议你写这种代码,因为它把一个清晰的 has-a 关系与继承混淆了——而继承本应只用于表示 is-a 关系。推荐的解法是让 Airplane 类包含类型为 Engine、Fuselage 和 Controls 的数据成员。
有趣而冷门的继承问题
Section titled “有趣而冷门的继承问题”扩展一个类会带来各种各样的问题。类的哪些特征可以改变,哪些不可以? 什么是非公有继承? 什么是虚基类? 这些问题,以及更多相关问题,都会在接下来的各节中得到解答。
改变被重写成员函数的返回类型
Section titled “改变被重写成员函数的返回类型”绝大多数情况下,你重写成员函数只是为了改变其实现。不过,有时你也可能想改变这个成员函数的其他特征,例如返回类型。
一个很好的经验法则是: 重写成员函数时,尽量保持与基类完全相同的成员函数声明,也就是成员函数原型(member function prototype)。实现可以改变,但原型保持一致。
不过,事情也并非必须如此。在 C++ 中,只要满足如下条件,重写的成员函数就可以改变返回类型: 基类中的成员函数返回类型必须是指向某个类的指针或引用,而派生类中的返回类型则必须是指向其后代类——也就是更具体的类——的指针或引用。这样的返回类型称为协变返回类型(covariant return type)。当基类与派生类同时又与另一组平行层次结构中的对象协作时,这个特性有时会很方便。所谓平行层次结构(parallel hierarchy),指的是另一组与当前类层次结构切线相关、但又彼此相关联的类。
例如,考虑一个基础的汽车模拟器。你可能会有两组类层次结构,它们分别建模不同的现实世界对象,但又明显彼此相关。第一组是 Car 层次结构: 基类是 Car,派生类有 GasolineCar 和 ElectricalCar。类似地,另一组类层次结构则以 PowerSource 为基类,派生类包括 GasolinePowerSource 和 ElectricalPowerSource。图 10.11 展示了这两套类层次结构。
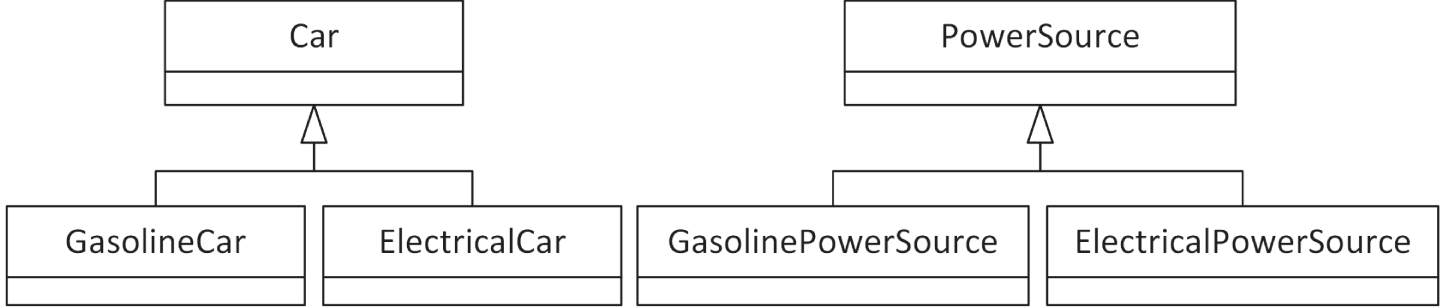
[^图 10.11]
先假设动力源(power source)能够打印出自己的类型,并且汽油动力源拥有一个 fillTank() 成员函数,而电力动力源则拥有一个 chargeBatteries() 成员函数:
class PowerSource{ public: virtual void printType() = 0;};
class GasolinePowerSource : public PowerSource{ public: void printType() override { println("GasolinePowerSource"); } virtual void fillTank() { println("Gasoline tank filled up."); }};
class ElectricalPowerSource : public PowerSource{ public: void printType() override { println("ElectricalPowerSource"); } virtual void chargeBatteries() { println("Batteries charged."); }};现在再假设 Car 有一个名为 getFilledUpPowerSource() 的 virtual 成员函数,它会返回某辆具体汽车当前“已补充完毕”的动力源引用:
class Car{ public: virtual PowerSource& getFilledUpPowerSource() = 0;};这是一个纯 virtual 抽象成员函数,因为真正的实现只在具体派生类中才有意义。由于 GasolinePowerSource 是一种 PowerSource,GasolineCar 类可以这样实现该成员函数:
class GasolineCar : public Car{ public: PowerSource& getFilledUpPowerSource() override { m_engine.fillTank(); return m_engine; } private: GasolinePowerSource m_engine;};而 ElectricalCar 则可以这样实现:
class ElectricalCar : public Car{ public: PowerSource& getFilledUpPowerSource() override { m_engine.chargeBatteries(); return m_engine; } private: ElectricalPowerSource m_engine;};这些类可以这样测试:
GasolineCar gc;gc.getFilledUpPowerSource().printType();println("");ElectricalCar ev;ev.getFilledUpPowerSource().printType();输出如下:
Gasoline tank filled up.GasolinePowerSource
Batteries charged.ElectricalPowerSource这种实现当然没问题。不过,既然你知道 GasolineCar 的 getFilledUpPowerSource() 总是返回 GasolinePowerSource,而 ElectricalCar 的则总是返回 ElectricalPowerSource,那么你其实可以通过改变返回类型,把这一事实直接表达给这些类的潜在使用者,如下所示:
class GasolineCar : public Car{ public: GasolinePowerSource& getFilledUpPowerSource() override { /* omitted for brevity */ }};
class ElectricalCar : public Car{ public: ElectricalPowerSource& getFilledUpPowerSource() override { /* omitted for brevity */ }};判断“是否可以改变某个被重写成员函数的返回类型”的一个好方法,是思考已有代码是否仍然能够正常工作; 这正是所谓的里氏替换原则(Liskov substitution principle, LSP)。在前面的例子中,改变返回类型是安全的,因为任何此前假定 getFilledUpPowerSource() 总会返回一个 PowerSource 的代码,仍然都可以正常编译并正确工作。由于 ElectricalPowerSource 与 GasolinePowerSource 都是 PowerSource,因此凡是以前在 PowerSource 返回值上可以调用的成员函数,现在在 ElectricalPowerSource 或 GasolinePowerSource 的返回值上同样也都可以调用。
但你显然不能把返回类型改成一个毫不相关的东西,例如 int&。下面这段代码就无法编译:
class ElectricalCar : public Car{ public: int& getFilledUpPowerSource() override // Error! { /* omitted for brevity */ }};这会生成一个类似如下的编译错误:
'ElectricalCar::getFilledUpPowerSource': overriding virtual function return type differs and is not covariant from 'Car::getFilledUpPowerSource'请注意,这个例子使用的是对 PowerSource 的引用,而不是智能指针。当返回类型改成例如 shared_ptr 时,返回类型就不能这样变化了。假设 Car::getFilledUpPowerSource() 返回的是 shared_ptr<PowerSource>。在这种情况下,你就不能把 ElectricalCar::getFilledUpPowerSource() 的返回类型改成 shared_ptr<ElectricalPowerSource>。原因在于,shared_ptr 是一个类模板。此时会分别创建 shared_ptr<PowerSource> 与 shared_ptr<ElectricalPowerSource> 这两个 shared_ptr 实例化类型。而这两个实例化类型是完全不同的类型,它们之间没有任何继承关系。你无法把一个被重写成员函数的返回类型改成一个完全不同的类型。
在派生类中为 virtual 基类成员函数增加新的重载
Section titled “在派生类中为 virtual 基类成员函数增加新的重载”可以在派生类中为基类的 virtual 成员函数增加新的重载。也就是说,你可以在派生类中为某个 virtual 成员函数增加一个新的原型版本,同时继续继承基类中的原版本。这种技巧需要使用 using 声明,显式地把基类中该成员函数的定义引入到派生类中。示例如下:
class Base{ public: virtual void someFunction();};
class Derived : public Base{ public: using Base::someFunction; // Explicitly inherits the Base version. virtual void someFunction(int i); // Adds a new overload of someFunction(). virtual void someOtherFunction();};继承构造函数
Section titled “继承构造函数”在上一节中,你已经看到可以借助 using 声明把基类中的成员函数显式引入到派生类中。这种做法不仅适用于普通成员函数,也适用于构造函数,从而让你可以从基类继承构造函数。来看下面这组 Base 与 Derived 类定义:
class Base{ public: virtual ~Base() = default; Base() = default; explicit Base(int i) {}};
class Derived : public Base{ public: explicit Derived(int i) : Base(i) {}};这里的 Derived 构造函数唯一做的事情,就是把自己的参数传给一个 Base 构造函数。
你只能使用 Base 所提供的那些构造函数来构造 Base 对象,也就是默认构造函数或接受一个 int 的构造函数。另一方面,构造 Derived 对象时,当前只能使用它自己提供的那个 Derived 构造函数,也就是必须提供一个整数参数的版本。你不能用 Base 类中的默认构造函数来构造 Derived 对象。示例如下:
Base base { 1 }; // OK, calls integer Base ctor.Derived derived1 { 2 }; // OK, calls integer Derived ctor.Derived derived2; // Error, Derived does not have a default ctor.既然 Derived 构造函数只是把参数传给某个 Base 构造函数,并没有做其他事情,那你完全可以像下面这样,通过 using 声明显式继承 Base 的构造函数:
class Derived : public Base{ public: using Base::Base;};这条 using 声明会继承 Base 的所有构造函数,因此现在你就可以用如下方式构造 Derived 对象:
Derived derived1 { 2 }; // OK, calls inherited integer Base ctor.Derived derived2; // OK, calls inherited default Base ctor.派生类中的这些继承构造函数,其访问说明符(public、protected 或 private)与基类中的构造函数保持一致。如果某个继承来的构造函数在基类中通过 =delete 被显式删除,那么它在派生类中同样也会被删除。
继承构造函数的隐藏
Section titled “继承构造函数的隐藏”Derived 类完全可以定义一个参数列表与某个来自 Base 的继承构造函数完全相同的构造函数。在这种情况下,Derived 自己定义的构造函数会优先于继承来的构造函数。下面的例子中,Derived 通过 using 声明继承了 Base 的全部构造函数。不过,由于 Derived 又自己定义了一个带单个 float 参数的构造函数,因此从 Base 继承来的那个同样带单个 float 参数的构造函数就会被隐藏。
class Base{ public: virtual ~Base() = default; Base() = default; explicit Base(std::string_view str) {} explicit Base(float f) {}};
class Derived : public Base{ public: using Base::Base; explicit Derived(float f) {} // Hides inherited float Base ctor.};在这个定义下,Derived 类型对象可以按如下方式创建:
Derived derived1 { "Hello" }; // OK, calls inherited string_view Base ctor.Derived derived2 { 1.23f }; // OK, calls float Derived ctor.Derived derived3; // OK, calls inherited default Base ctor.用 using 声明从基类继承构造函数时,还存在几条限制:
- 一旦你选择继承某个基类的构造函数,你继承的是全部构造函数。无法只继承其中的一部分。
- 构造函数在派生类中继承后的访问说明符,与它们在基类中保持一致,与
using声明本身位于哪个访问说明符区域下无关。
继承构造函数与多重继承
Section titled “继承构造函数与多重继承”继承构造函数的另一个限制与多重继承有关。如果另一个基类中存在参数列表完全相同的构造函数,那么你就不能只从其中一个基类继承该构造函数,因为这会导致歧义。要解决这个问题,Derived 类就需要显式定义那些发生冲突的构造函数。例如,下面这个 Derived 类试图同时从 Base1 和 Base2 继承全部构造函数,从而在基于 float 的构造函数上产生了歧义。
class Base1{ public: virtual ~Base1() = default; Base1() = default; explicit Base1(float f) {}};
class Base2{ public: virtual ~Base2() = default; Base2() = default; explicit Base2(std::string_view str) {} explicit Base2(float f) {}};
class Derived : public Base1, public Base2{ public: using Base1::Base1; using Base2::Base2; explicit Derived(char c) {}};
int main(){ Derived d { 1.2f }; // Error, ambiguity.}Derived 中第一条 using 声明会继承 Base1 的全部构造函数。这意味着,Derived 获得了如下构造函数:
Derived(float f); // Inherited from Base1.而 Derived 中第二条 using 声明又试图继承 Base2 的全部构造函数。可这意味着 Derived 会再得到第二个 Derived(float) 构造函数。解决办法,是在 Derived 类中显式声明那些冲突的构造函数,如下所示:
class Derived : public Base1, public Base2{ public: using Base1::Base1; using Base2::Base2; explicit Derived(char c) {} explicit Derived(float f) {}};现在,Derived 类显式声明了一个带单个 float 参数的构造函数,从而消除了歧义。如果你愿意,这个 Derived 类中显式声明的 float 构造函数依然可以在其 ctor-initializer 中把调用转发给 Base1 和 Base2 的构造函数,如下所示:
Derived::Derived(float f) : Base1 { f }, Base2 { f } {}数据成员的初始化
Section titled “数据成员的初始化”在使用继承构造函数时,一定要确保所有数据成员都被正确初始化。例如,来看下面这个新的 Base 与 Derived 定义。这两个定义并不能在所有情况下正确初始化 m_int 数据成员,而你已经知道,未初始化的数据成员是不推荐的。
class Base{ public: virtual ~Base() = default; explicit Base(std::string_view str) : m_str { str } {} private: std::string m_str;};
class Derived : public Base{ public: using Base::Base; explicit Derived(int i) : Base { "" }, m_int { i } {} private: int m_int;};你可以像下面这样创建一个 Derived 对象:
Derived s1 { 2 };这会调用 Derived(int) 构造函数,它初始化 Derived 类中的 m_int 数据成员,并通过给 Base 传递一个空字符串来初始化 Base 类中的 m_str 数据成员。
由于 Base 构造函数被继承到了 Derived 中,你也可以像下面这样构造一个 Derived 对象:
Derived s2 { "Hello World" };这会调用 Derived 类中继承来的 Base 构造函数。不过,这个继承来的 Base 构造函数只会初始化 Base 类中的 m_str,却不会初始化 Derived 类中的 m_int,从而让它保持未初始化状态。这当然是不推荐的!
这种情况下的解决方案,是使用类内成员初始化器(in-class member initializer),它在 第 8 章 中已经讨论过。下面的代码使用类内成员初始化器,把 m_int 初始化为 0。当然,Derived(int) 构造函数依然可以覆盖这一点,把 m_int 初始化为构造函数参数 i。
class Derived : public Base{ public: using Base::Base; explicit Derived(int i) : Base { "" }, m_int { i } {} private: int m_int { 0 };};重写成员函数时的特殊情况
Section titled “重写成员函数时的特殊情况”在重写成员函数时,有一些特殊情况需要特别留意。本节会概述那些你最有可能遇到的情形。
基类成员函数是 static
Section titled “基类成员函数是 static”在 C++ 中,你不能重写一个 static 成员函数。对大多数场景来说,你只需要记住这一点就够了。不过,围绕它还有一些推论需要理解。
首先,一个成员函数不可能同时既是 static 又是 virtual。这其实已经是第一个信号: 试图重写一个 static 成员函数,并不会得到你想要的效果。如果你的派生类中有一个与基类 static 成员函数同名的 static 成员函数,那么你拥有的其实是两个彼此完全独立的成员函数。
下面的代码展示了两个类,它们恰好都拥有名为 beStatic() 的 static 成员函数。这两个成员函数之间没有任何关系。
class BaseStatic{ public: static void beStatic() { println("BaseStatic being static."); }};
class DerivedStatic : public BaseStatic{ public: static void beStatic() { println("DerivedStatic keepin' it static."); }};由于 static 成员函数属于类而不属于具体对象,因此通过两个不同类名调用同名成员函数时,调用的就是各自类里的那个版本。
BaseStatic::beStatic();DerivedStatic::beStatic();它的输出如下:
BaseStatic being static.DerivedStatic keepin' it static.只要是通过类名来访问这些成员函数,一切都完全符合直觉。当对象参与进来时,行为就没那么直观了。在 C++ 中,你可以通过对象来调用 static 成员函数,但由于这个成员函数是 static,它没有 this 指针,也无法访问对象本身,因此这在本质上等价于通过类名调用它。继续沿用前面的示例类,你可以写出下面这样的代码,但结果可能会让你惊讶。
DerivedStatic myDerivedStatic;BaseStatic& ref { myDerivedStatic };myDerivedStatic.beStatic();ref.beStatic();第一次调用 beStatic() 显然会调用 DerivedStatic 版本,因为它是通过一个明确声明为 DerivedStatic 的对象调用的。第二次调用可能就不会如你预想。这个对象表面上是一个 BaseStatic 引用,尽管它实际引用的是一个 DerivedStatic 对象。在这种情况下,被调用的是 BaseStatic 的 beStatic() 版本。原因在于,调用 static 成员函数时,C++ 根本不关心对象的实际运行时类型是什么。它只关心编译期类型。而此处的编译期类型是一个 BaseStatic 引用。
前面那段代码的输出如下:
DerivedStatic keepin' it static.BaseStatic being static.基类成员函数存在重载
Section titled “基类成员函数存在重载”当你通过指定某个名字和一组参数来重写成员函数时,编译器会隐式地隐藏基类中所有其他同名版本。这里的设计思想是: 如果你已经重写了某个给定名字的一个成员函数,那也许你原本是想重写该名字下的所有成员函数,只是忘了而已,因此这种情况应当被视为错误。从这个角度看,这其实很合理——如果你要改变某个成员函数的部分重载版本,为什么会不想改变其他重载版本呢? 看下面这个 Derived 类,它重写了一个成员函数,却没有同时重写与之同名的其他重载兄弟:
class Base{ public: virtual ~Base() = default; virtual void overload() { println("Base's overload()"); } virtual void overload(int i) { println("Base's overload(int i)"); }};
class Derived : public Base{ public: void overload() override { println("Derived's overload()"); }};如果你试图在一个 Derived 对象上调用那个接受 int 参数的 overload() 版本,代码就无法编译,因为它并没有被显式重写。
Derived myDerived;myDerived.overload(2); // Error! No matching member function for overload(int).不过,你依然可以从 Derived 对象上访问这个成员函数版本。你所需要的只是一个指向 Base 的指针或引用。
Derived myDerived;Base& ref { myDerived };ref.overload(7);在 C++ 中,这种“未被实现的重载版本被隐藏”的行为其实只是表面现象。对于那些明确声明为派生类实例的对象来说,这些成员函数并不可见; 但只要简单地转成基类,它们又会重新出现。
如果你真正只想改变其中一个重载版本,而不想费力地把所有重载都重写一遍,那就可以使用 using 声明来帮你。在下面的代码中,Derived 类定义使用了来自 Base 的一个 overload() 版本,同时显式重写了另一个:
class Derived : public Base{ public: using Base::overload; void overload() override { println("Derived's overload()"); }};不过,using 声明也伴随着一定风险。假设日后 Base 中又新增了第三个 overload() 成员函数,而这个新函数其实原本也应该在 Derived 中被重写。现在这件事将不会被检测为错误,因为一旦你写下 using 声明,就等于设计者明确表示:“对于这个成员函数的其他重载版本,我愿意直接接受父类中的实现。”
为了避免在重写基类成员函数时埋下隐蔽 bug,请同时重写该成员函数的所有重载版本。
基类成员函数是 private
Section titled “基类成员函数是 private”重写一个 private 成员函数并没有任何问题。请记住,成员函数的访问说明符只决定“谁能够调用这个成员函数”。派生类无法调用父类的 private 成员函数,并不意味着它无法重写它们。事实上,模板成员函数模式(template member function pattern)就是 C++ 中一种很常见的模式,它正是通过重写 private 成员函数来实现的。它允许派生类定义自己的某些“独特性”,而这些独特性会在基类内部被引用。顺便一提,例如 Java 和 C# 只允许重写 public 与 protected 成员函数,而不允许重写 private 成员函数。
例如,下面这个类属于某个汽车模拟器的一部分,它会基于汽车的油耗和剩余燃料量来估算还能行驶多少英里。getMilesLeft() 成员函数就是那个模板成员函数。通常,模板成员函数本身并不是 virtual 的。它们的典型角色,是在基类中定义某种算法骨架,并在内部调用若干 virtual 成员函数来获取所需信息。这样一来,派生类就能够通过重写这些 virtual 成员函数,来改变算法的某些方面,而不必修改基类中的算法本体。
export class MilesEstimator{ public: virtual ~MilesEstimator() = default; int getMilesLeft() const { return getMilesPerGallon() * getGallonsLeft(); } virtual void setGallonsLeft(int gallons) { m_gallonsLeft = gallons; } virtual int getGallonsLeft() const { return m_gallonsLeft; } private: int m_gallonsLeft { 0 }; virtual int getMilesPerGallon() const { return 20; }};getMilesLeft() 成员函数会基于其自身两个成员函数的结果来完成计算: 一个是 public 的 getGallonsLeft(),另一个则是 private 的 getMilesPerGallon()。下面的代码使用 MilesEstimator 来计算在还剩两加仑汽油时还能行驶多少英里:
MilesEstimator myMilesEstimator;myMilesEstimator.setGallonsLeft(2);println("Normal estimator can go {} more miles.", myMilesEstimator.getMilesLeft());输出如下:
Normal estimator can go 40 more miles.为了让模拟器更有意思,你可能会想引入不同类型的车辆,例如一辆更省油的车。现有的 MilesEstimator 假定所有车每加仑都能跑 20 英里,但这个值恰恰是通过一个独立成员函数返回的,目的就是让派生类可以重写它。下面展示了这样的一个派生类:
export class EfficientCarMilesEstimator : public MilesEstimator{ private: int getMilesPerGallon() const override { return 35; }};仅仅通过重写这一个 private 成员函数,这个新类就彻底改变了基类中现有、未修改的 public 成员函数的行为。基类中的 getMilesLeft() 成员函数会自动调用这个被重写后的 private getMilesPerGallon() 成员函数。下面是使用新类的示例:
EfficientCarMilesEstimator myEstimator;myEstimator.setGallonsLeft(2);println("Efficient estimator can go {} more miles.", myEstimator.getMilesLeft());这一次,输出就会体现出被重写后的行为:
Efficient estimator can go 70 more miles.基类成员函数带有默认参数
Section titled “基类成员函数带有默认参数”派生类中被重写的成员函数,可以与基类版本使用不同的默认参数。最终使用哪一套默认参数,取决于变量的声明类型,而不是对象的真实底层类型。下面就是一个简单例子,派生类在其重写成员函数中提供了不同的默认参数:
class Base{ public: virtual ~Base() = default; virtual void go(int i = 2) { println("Base's go with i={}", i); }};
class Derived : public Base{ public: void go(int i = 7) override { println("Derived's go with i={}", i); }};如果你在一个 Derived 对象上调用 go(),Derived 版本的 go() 会被执行,并使用默认参数 7。如果你在一个 Base 对象上调用 go(),则调用的是 Base 版本,并使用默认参数 2。然而(这也是诡异之处),如果你通过一个实际指向 Derived 对象的 Base 指针或 Base 引用来调用 go(),那么最终被调用的是 Derived 版本的 go(),但使用的默认参数却来自 Base,也就是 2。下面的示例展示了这种行为:
Base myBase;Derived myDerived;Base& myBaseReferenceToDerived { myDerived };myBase.go();myDerived.go();myBaseReferenceToDerived.go();其输出如下:
Base's go with i=2Derived's go with i=7Derived's go with i=2出现这种行为的原因在于,C++ 绑定默认参数时依据的是表达式的编译期类型,而不是运行时类型。默认参数在 C++ 中不会被“继承”。如果本例中的 Derived 类没有像其父类那样为 go() 提供默认参数,那么你就无法在不传参的情况下对 Derived 对象调用 go()。
基类成员函数拥有不同的访问说明符
Section titled “基类成员函数拥有不同的访问说明符”你可能想改变一个成员函数的访问说明符,大致有两种方向: 要么想让它更严格,要么想让它更宽松。在 C++ 中,这两种做法本身都不算特别自然,不过在少数情况下,确实也存在一些合理理由。
若想对某个成员函数(数据成员也一样)施加更严格的访问限制,你可以采用两种办法。其中一种是改变整个基类的访问说明符——这种做法会在本章后面介绍。另一种办法则是,像下面这个 Shy 类那样,直接在派生类中重新定义其访问级别:
class Gregarious{ public: virtual void talk() { println("Gregarious says hi!"); }};
class Shy : public Gregarious{ protected: void talk() override { println("Shy reluctantly says hello."); }};Shy 中这个 protected 版本的 talk() 确实正确重写了 Gregarious::talk()。任何试图在 Shy 对象上调用 talk() 的客户端代码都会得到编译错误:
Shy myShy;myShy.talk(); // Error! Attempt to access protected member function.不过,这个成员函数并没有被“完全保护”起来。你只需要拿到一个 Gregarious 的引用或指针,就又能够访问这个你原以为已经被保护起来的成员函数了:
Shy myShy;Gregarious& ref { myShy };ref.talk();这段代码的输出如下:
Shy reluctantly says hello.这证明了: 把成员函数在派生类中改成 protected 的确完成了重写(因为被正确调用的是派生类版本),但它也同时证明,如果基类把它做成了 public,那么这种 protected 访问是无法被彻底强制执行的。
相比之下,在派生类中放宽访问限制要容易得多,而且通常也更有意义。最简单的方式,就是在派生类中提供一个 public 成员函数,由它去调用基类中的某个 protected 成员函数,如下所示:
class Secret{ protected: virtual void dontTell() { println("I'll never tell."); }};
class Blabber : public Secret{ public: virtual void tell() { dontTell(); }};一个客户端调用 Blabber 对象的 public tell() 成员函数时,实际上就间接访问到了 Secret 类中的 protected 成员函数。当然,这并没有真正改变 dontTell() 的访问说明符; 它只是提供了一条 public 的访问路径。
你也可以在 Blabber 中显式重写 dontTell(),并让它以 public 方式对外可见,同时赋予它新的行为。这种做法比“单纯降低访问限制”更有意义,因为对于基类指针或引用而言,最终会发生什么是完全清晰的。例如,假设 Blabber 真的把 dontTell() 做成了 public:
class Blabber : public Secret{ public: void dontTell() override { println("I'll tell all!"); }};现在你就可以在 Blabber 对象上调用 dontTell():
myBlabber.dontTell(); // Outputs "I'll tell all!"如果你并不想改变这个被重写成员函数的实现,而只是想改变它的访问说明符,那么你可以使用 using 声明。示例如下:
class Blabber : public Secret{ public: using Secret::dontTell;};这样同样也能让你在 Blabber 对象上调用 dontTell(),不过这一次输出将是 “I’ll never tell.”:
myBlabber.dontTell(); // Outputs "I'll never tell."不过,在前面这两种情况下,基类中的 protected 成员函数依然保持着 protected,因为任何试图通过 Secret 指针或引用去调用 Secret::dontTell() 的代码,都不会通过编译:
Blabber myBlabber;Secret& ref { myBlabber };Secret* ptr { &myBlabber };ref.dontTell(); // Error! Attempt to access protected member function.ptr->dontTell(); // Error! Attempt to access protected member function.派生类中的拷贝构造函数与赋值运算符
Section titled “派生类中的拷贝构造函数与赋值运算符”第 9 章 解释过: 只要类中存在动态分配内存,那么提供拷贝构造函数和赋值运算符就是必须的。在定义派生类时,你同样也必须小心处理拷贝构造函数和 operator=。
如果你的派生类本身并不含有任何需要自定义拷贝构造函数或 operator= 的特殊数据(通常是指针),那么无论基类是否有自定义版本,你都不需要自己再写。若派生类省略了拷贝构造函数或 operator=,那么编译器将为派生类中声明的数据成员生成默认拷贝构造或赋值行为,而基类部分则会使用基类自己的拷贝构造函数或 operator=。
另一方面,如果你确实在派生类中自己定义了拷贝构造函数,那么就必须显式调用父类的拷贝构造函数,如下例所示。否则,对象中属于父类的那一部分会调用默认构造函数(而不是拷贝构造函数!)。
class Base{ public: virtual ~Base() = default; Base() = default; Base(const Base& src) { }};
class Derived : public Base{ public: Derived() = default; Derived(const Derived& src) : Base { src } { }};类似地,如果派生类重写了 operator=,那么几乎总是也需要同时调用父类版本的 operator=。唯一例外是某种非常诡异的场景,在那种场景里,你只希望在赋值发生时,对象中的某一部分被赋值。下面这段代码展示了如何在派生类中调用父类的赋值运算符:
Derived& Derived::operator=(const Derived& rhs){ if (&rhs == this) { return *this; } Base::operator=(rhs); // Calls parent's operator=. // Do necessary assignments for derived class. return *this;}如果你的派生类没有定义自己的拷贝构造函数或 operator=,那么基类功能会继续正常生效。不过,只要派生类自己提供了拷贝构造函数或 operator=,它就必须显式调用基类版本。
运行时类型设施
Section titled “运行时类型设施”与其他面向对象语言相比,C++ 更偏重编译期。正如你前面学到的那样,成员函数重写之所以能够工作,依赖的是成员函数与其实现之间那一层间接性,而不是对象本身真的内建了对于自身类类型的完整认知。
不过,C++ 的确提供了一些能够从运行时视角观察对象的特性。这些特性通常被统称为运行时类型信息(run-time type information, RTTI)。RTTI 提供了若干有用能力,让你能够处理与对象所属类相关的信息。其中一项能力就是 dynamic_cast(),它允许你在面向对象层次结构内部安全地进行类型转换——这一点前面已经讨论过了。若在一个没有 vtable 的类上使用 dynamic_cast(),也就是在一个没有任何 virtual 成员函数的类上使用它,将会导致编译错误。
RTTI 的另一项特性是 typeid 运算符,它允许你在运行时查询类型信息。对该运算符求值后得到的是一个对 std::type_info 对象的引用,这个类定义在 <typeinfo> 中。type_info 类有一个名为 name() 的成员函数,返回该类型的编译器相关名称。typeid 运算符的行为如下:
typeid(type): 得到的是一个对type_info对象的引用,该对象表示给定的类型。typeid(expression)- 如果对
expression求值后得到的是一个多态类型,那么expression会被实际求值,并且typeid运算符的结果将是一个对type_info对象的引用,该对象表示这个表达式求值后对象的动态类型。 - 否则,
expression不会被求值,其结果将是一个对type_info对象的引用,表示静态类型。
- 如果对
大多数时候,你其实根本不应当需要使用 typeid,因为任何“基于对象类型来条件执行代码”的场景,通常都更适合通过 virtual 成员函数等机制来处理。
下面的代码使用 typeid 根据对象类型打印一条消息:
class Animal { public: virtual ~Animal() = default; };class Dog : public Animal {};class Bird : public Animal {};
void speak(const Animal& animal){ if (typeid(animal) == typeid(Dog)) { println("Woof!"); } else if (typeid(animal) == typeid(Bird)) { println("Chirp!"); }}每当你看到这样的代码,都应当立刻思考: 能否把它改写成 virtual 成员函数的形式。在这个例子中,更好的实现办法,是直接在 Animal 基类中声明一个名为 speak() 的 virtual 成员函数。Dog 重写它来打印 "Woof!",Bird 重写它来打印 "Chirp!"。这种做法更符合面向对象编程的精神,因为与对象相关的行为应由对象自己掌握。
typeid 运算符只有在类至少拥有一个 virtual 成员函数、也就是类拥有 vtable 时,才能正确工作。此外,typeid 运算符会去掉其实参中的引用和 const 限定符。
typeid 运算符的一个可能使用场景,是用于日志与调试。下面这段代码就利用 typeid 来做日志输出。logObject() 函数接受一个“可记录日志”的对象作为参数。其设计是这样的: 任何可记录日志的对象都继承自 Loggable 类,并支持一个名为 getLogMessage() 的成员函数。
class Loggable{ public: virtual ~Loggable() = default; virtual string getLogMessage() const = 0;};
class Foo : public Loggable{ public: string getLogMessage() const override { return "Hello logger."; }};
void logObject(const Loggable& loggableObject){ print("{}: ", typeid(loggableObject).name()); println("{}", loggableObject.getLogMessage());}logObject() 会先把对象所属类的名称打印到控制台,再接着打印其日志消息。这样以后阅读日志时,你就能知道每一行究竟是由哪个对象产生的。下面是当 logObject() 用一个 Foo 实例调用时,Microsoft Visual C++ 2022 所生成的输出:
输出如下:
class Foo: Hello logger.如你所见,typeid 运算符返回的名字是 class Foo。不过,这个名字依赖于具体编译器。例如,如果你用 GCC 来编译并运行同样的代码,输出如下:
输出为:
3Foo: Hello logger.非 public 继承
Section titled “非 public 继承”在前面的所有例子中,父类总是使用 public 关键字列出。你可能会想: 父类关系能不能是 private 或 protected 呢? 事实上,可以,尽管这两种方式都远不如 public 常见。如果你完全不为父类写出访问说明符,那么对 class 而言它默认是 private 继承,而对 struct 而言则默认是 public 继承。
如果将与父类之间的关系声明为 protected,这意味着基类中的所有 public 成员函数和数据成员,在派生类语境中都会变成 protected。类似地,如果指定 private 继承,那么基类中的所有 public 和 protected 成员函数以及数据成员,都会在派生类中变成 private。
你确实可能会出于少数几个原因,想统一降低父类成员的访问级别,但大多数这类理由都暗示着层次结构本身存在设计缺陷。一些程序员会滥用这一语言特性,尤其是把它与多重继承结合,来实现类的“组件”。例如,他们不会去写一个包含 engine 数据成员和 fuselage 数据成员的 Airplane 类,而是写出一个“是一个 protected engine,也是一个 protected fuselage”的 Airplane 类。这样一来,Airplane 对客户端代码来说既不像 engine 也不像 fuselage(因为相关能力都变成了 protected),但它在内部又能使用这些全部功能。
本章前面你已经了解过“歧义基类”问题: 当多个父类拥有共同父类时,就会出现这种情况,如 图 10.12 再次展示的那样。前面推荐的解决方案是,确保那个共享父类自身不拥有任何实现功能。这样一来,它的成员函数就永远不会被调用,也就不会产生歧义问题。
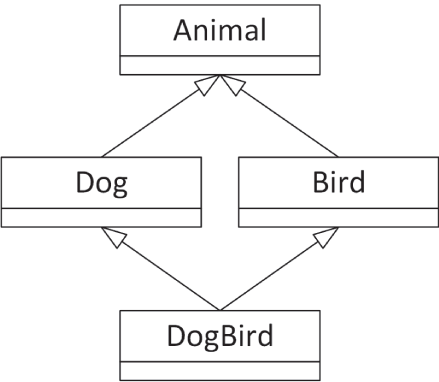
[^图 10.12]
C++ 还提供了另一种机制,称为虚基类(virtual base class),用于在你确实希望共享父类拥有自身功能时解决这一问题。如果把共享父类标记为虚基类,那就不会再产生歧义。下面的代码给 Animal 基类添加了一个带实现的 sleep() 成员函数,并把 Dog 和 Bird 修改为以虚基类方式继承 Animal。如果不使用虚基类,那么在 DogBird 对象上调用 sleep() 就会出现歧义并触发编译错误,因为此时 DogBird 将拥有两个 Animal 子对象——一个来自 Dog,另一个来自 Bird。而当 Animal 被虚继承时,DogBird 只会拥有一个 Animal 子对象,因此调用 sleep() 时就不再歧义。
class Animal{ public: virtual void eat() = 0; virtual void sleep() { println("zzzzz...."); }};
class Dog : public virtual Animal{ public: virtual void bark() { println("Woof!"); } void eat() override { println("The dog ate."); }};
class Bird : public virtual Animal{ public: virtual void chirp() { println("Chirp!"); } void eat() override { println("The bird ate."); }};
class DogBird : public Dog, public Bird{ public: void eat() override { Dog::eat(); }};
int main(){ DogBird myConfusedAnimal; myConfusedAnimal.sleep(); // Not ambiguous because of virtual base class.}在这样的类层次结构里,一定要特别小心构造函数。例如,下面的代码为不同类添加了一些数据成员,增加了用于初始化这些数据成员的构造函数,并且——出于代码片段后面会解释的原因——给 Animal 增加了一个 protected 默认构造函数。
class Animal{ public: explicit Animal(double weight) : m_weight { weight } {} virtual double getWeight() const { return m_weight; } protected: Animal() = default; private: double m_weight { 0.0 };};
class Dog : public virtual Animal{ public: explicit Dog(double weight, string name) : Animal { weight }, m_name { move(name) } {} protected: explicit Dog(string name) : m_name { move(name) } {} private: string m_name;};
class Bird : public virtual Animal{ public: explicit Bird(double weight, bool canFly) : Animal { weight }, m_canFly { canFly } {} protected: explicit Bird(bool canFly) : m_canFly { canFly } {} private: bool m_canFly { false };};
class DogBird : public Dog, public Bird{ public: explicit DogBird(double weight, string name, bool canFly) : Dog { weight, move(name) }, Bird { weight, canFly } {}};
int main(){ DogBird dogBird { 22.33, "Bella", true }; println("Weight: {}", dogBird.getWeight());}当你运行这段代码时,输出会出乎意料: 输出如下:
Weight: 0看起来,在 main() 中构造 DogBird 时给出的 22.33 这个重量值丢失了。为什么? 这段代码使用的是虚 Animal 基类,因此 DogBird 实例只会有一个 Animal 子对象。DogBird 构造函数会调用 Dog 和 Bird 的构造函数,而这两个构造函数又都会继续转发给它们的 Animal 基类构造函数。这样一来,Animal 就会被构造两次,而这是不允许的。在这种情况下,当 Dog 和 Bird 的构造函数是从某个更下层派生类构造函数里被调用时,编译器会禁用它们内部对 Animal 构造函数的调用,转而调用 Animal 的默认构造函数。这也正是为什么 Animal 需要一个 protected 默认构造函数。所有这些归结为一点: 最底层、也就是最派生的那个类,必须自己负责调用共享基类的某个构造函数。正确实现如下:
class Animal { /* Same as before. */ };
class Dog : public virtual Animal{ public: explicit Dog(double weight, string name) : Animal { weight }, m_name { move(name) } {} protected: explicit Dog(string name) : m_name { move(name) } {} private: string m_name;};
class Bird : public virtual Animal{ public: explicit Bird(double weight, bool canFly) : Animal { weight }, m_canFly { canFly } {} protected: explicit Bird(bool canFly) : m_canFly { canFly } {} private: bool m_canFly { false };};
class DogBird : public Dog, public Bird{ public: explicit DogBird(double weight, string name, bool canFly) : Animal { weight }, Dog { move(name) }, Bird { canFly } {}};在这个实现中,Dog 和 Bird 都增加了 protected 的单参数构造函数。之所以是 protected,是因为它们只应被派生类使用。客户端代码只能通过那两个双参数构造函数来构造 Dog 和 Bird。
经过这些修改后,输出就是正确的了: 输出为:
Weight: 22.33第 1 章 回顾了 C++ 中的基本类型,而 第 8 章 到 第 10 章 展示了如何借助类来编写自己的类型。本节将探讨把一种类型转换成另一种类型时,那些更棘手的方面。
C++ 提供了五种专门的类型转换: const_cast()、static_cast()、reinterpret_cast()、dynamic_cast() 和 std::bit_cast()。第一种在 第 1 章 中已经讨论过。第 1 章 也介绍了 static_cast(),用于在某些基本类型之间进行转换,不过在继承语境下,它还有更多内容值得一提。既然你现在已经熟练掌握了自己编写类以及类继承,也到了进一步深入理解这些类型转换的时候了。
请注意,像 (int)myFloat 这样的旧式 C 风格类型转换在 C++ 中依然可用,而且在现有代码库中仍被广泛使用。C 风格类型转换几乎涵盖了除 bit_cast() 之外的所有 C++ 类型转换,因此它也更容易出错,因为你并不总是能一眼看出它到底想实现什么,而且结果也可能完全出乎意料。我强烈建议,在新代码中只使用 C++ 风格类型转换,因为它们更安全,在语法和视觉上也更醒目。
static_cast()
Section titled “static_cast()”你可以使用 static_cast() 来执行那些语言本身直接支持的显式转换。例如,如果你在一个算术表达式中需要把 int 转成 double,以避免整数除法,就应当使用 static_cast()。在下面这个例子中,只对 i 使用 static_cast() 就已经足够了,因为这样会让两个操作数之一变成 double,从而确保 C++ 执行的是浮点除法。
int i { 3 };int j { 4 };double result { static_cast<double>(i) / j };你也可以使用 static_cast() 来执行那些由于用户自定义构造函数或类型转换机制而被允许的显式转换。例如,如果类 A 有一个接受类 B 对象的构造函数,那么你就可以使用 static_cast() 把一个 B 对象转换成 A 对象。不过,在大多数你真正需要这种行为的场景里,编译器其实都会自动完成这类转换。
static_cast() 的另一种用途,是在继承层次结构中执行向下转换,例如下面这个例子:
class Base{ public: virtual ~Base() = default;};
class Derived : public Base{ public: virtual ~Derived() = default;};
int main(){ Base* b { nullptr }; Derived* d { new Derived {} }; b = d; // Don't need a cast to go up the inheritance hierarchy. d = static_cast<Derived*>(b); // Need a cast to go down the hierarchy.
Base base; Derived derived; Base& br { derived }; Derived& dr { static_cast<Derived&>(br) };}这些类型转换既适用于指针,也适用于引用,但不适用于对象本身。
请注意,使用 static_cast() 进行这种转换时,并不会执行运行时类型检查。它会允许你把任何 Base 指针转换成 Derived 指针,或者把 Base 引用转换成 Derived 引用,即使该 Base 在运行时实际上根本不是一个 Derived。例如,下面这段代码可以编译并执行,但后续使用这个指针 d 时,可能会导致潜在灾难性后果,包括越界写坏对象外部内存。
Base* b { new Base {} };Derived* d { static_cast<Derived*>(b) };若要在这类场景下进行带有运行时类型检查的安全转换,应使用 dynamic_cast(),本章稍后会解释。
static_cast() 当然也并非无所不能。你不能用它把一种类型的指针转换成另一种毫不相关类型的指针。若不存在可用的转换构造函数,你也不能直接把一种类型的对象 static_cast() 成另一种完全不同的对象。你不能用 static_cast() 把 const 类型转成非 const 类型。你也不能用它把指针转成 int。总的来说,你只能做那些按照 C++ 类型规则本身就“说得通”的事。
reinterpret_cast()
Section titled “reinterpret_cast()”reinterpret_cast() 比 static_cast() 更强大一些,相应地也更不安全一些。你可以用它执行某些按 C++ 类型规则来说并不真正被允许、但在某些特定情形下程序员认为“有意义”的类型转换。例如,你可以使用 reinterpret_cast() 把某种类型的引用转换成另一种类型的引用,即使这两种类型彼此无关。类似地,你也可以用它把某种指针类型转换成另一种完全不同的指针类型,即便它们在继承层次结构中毫无关系。不过,把某个指针转换成 void* 可以隐式完成,根本不需要显式类型转换。要把 void* 再转回正确类型的指针,使用 static_cast() 就足够了。void* 指针本质上只是一个“指向内存中某处”的指针,它本身不携带任何类型信息。下面给出一些例子:
class X {};class Y {};
int main(){ X x; Y y; X* xp { &x }; Y* yp { &y }; // Need reinterpret_cast for pointer conversion from unrelated classes // static_cast doesn't work. xp = reinterpret_cast<X*>(yp); // No cast required for conversion from pointer to void* void* p { xp }; // static_cast is enough for pointer conversion from void* xp = static_cast<X*>(p); // Need reinterpret_cast for reference conversion from unrelated classes // static_cast doesn't work. X& xr { x }; Y& yr { reinterpret_cast<Y&>(x) };}reinterpret_cast() 同样也不是无所不能的; 它也受到相当多“什么能转、什么不能转”的限制。本书不会继续展开这些细节,因为我建议你极其谨慎地使用这类类型转换。
总体来说,你应当格外小心 reinterpret_cast(),因为它允许你在完全不做类型检查的情况下进行转换。
你也可以使用 reinterpret_cast() 把指针转换成整数类型,再转换回来。不过,你只能把指针转换成足够大的整数类型。例如,试图用 reinterpret_cast() 把一个 64 位指针转换成 32 位整数,会导致编译错误。
dynamic_cast()
Section titled “dynamic_cast()”dynamic_cast() 为继承层次结构中的类型转换提供运行时检查。你既可以把它用于指针,也可以用于引用。dynamic_cast() 会在运行时检查底层对象的运行时类型信息。如果该类型转换没有意义,那么 dynamic_cast() 在指针版本上会返回空指针,在引用版本上则会抛出 std::bad_cast 异常。
例如,假设你有如下类层次结构:
class Base{ public: virtual ~Base() = default;};
class Derived : public Base{ public: virtual ~Derived() = default;};下面这个例子展示了 dynamic_cast() 的正确用法:
Base* b;Derived* d { new Derived {} };b = d;d = dynamic_cast<Derived*>(b);而下面这个针对引用的 dynamic_cast() 则会导致异常被抛出:
Base base;Derived derived;Base& br { base };try { Derived& dr { dynamic_cast<Derived&>(br) };} catch (const bad_cast&) { println("Bad cast!");}请注意,你也可以使用 static_cast() 或 reinterpret_cast() 来执行同样的向下转换。与 dynamic_cast() 的区别在于,dynamic_cast() 会做运行时(动态)类型检查,而 static_cast() 和 reinterpret_cast() 即使在转换本身是错误的情况下,也依然会硬做转换。
请记住,运行时类型信息存储在对象的 vtable 中。因此,若要使用 dynamic_cast(),你的类就必须至少拥有一个 virtual 成员函数。若类中没有 vtable,试图使用 dynamic_cast() 就会触发编译错误。例如,Microsoft Visual C++ 会给出类似如下的错误:
error C2683: 'dynamic_cast' : 'Base' is not a polymorphic type.std::bit_cast()
Section titled “std::bit_cast()”std::bit_cast() 定义在 <bit> 中。它是唯一一个属于标准库的类型转换; 其他类型转换都是 C++ 语言本身的一部分。bit_cast() 与 reinterpret_cast() 有些相似,但它会创建一个给定目标类型的新对象,并把源对象中的位模式复制到这个新对象中。它本质上就是把源对象的那些位,当作目标对象的位来解释。bit_cast() 要求源对象和目标对象大小完全相同,并且两者都必须是可平凡复制的(trivially copyable)。
下面是一个例子:
float asFloat { 1.23f };auto asUint { bit_cast<unsigned int>(asFloat) };if (bit_cast<float>(asUint) == asFloat) { println("Roundtrip success."); }bit_cast() 的一个用例,是在对 trivially copyable 类型进行二进制 I/O 时使用。例如,你可以把这类类型的各个字节单独写入文件。当你再把文件读回内存时,就可以使用 bit_cast() 来正确解释从文件中读回来的这些字节。
各类类型转换小结
Section titled “各类类型转换小结”下表总结了不同场景下你应使用的类型转换。
| 场景 | 使用的类型转换 |
|---|---|
去掉 const 属性 | const_cast() |
语言本身支持的显式类型转换(例如 int 到 double,int 到 bool) | static_cast() |
| 用户自定义构造函数或转换所支持的显式类型转换 | static_cast() |
| 某一类对象到另一无关类对象 | bit_cast() |
| 同一继承层次结构中,一种类对象的指针转成另一种类对象的指针 | 推荐 dynamic_cast(),也可用 static_cast() |
| 同一继承层次结构中,一种类对象的引用转成另一种类对象的引用 | 推荐 dynamic_cast(),也可用 static_cast() |
| 某种类型的指针转成无关类型的指针 | reinterpret_cast() |
| 某种类型的引用转成无关类型的引用 | reinterpret_cast() |
| 函数指针到函数指针 | reinterpret_cast() |
本章覆盖了大量与继承相关的细节。你学习了继承的诸多用途,包括代码复用与多态。你也看到了继承容易被滥用的地方,例如设计糟糕的多重继承方案。一路上,你还识别出不少需要特别留意的特殊情况。
继承是一项强大的语言特性,需要花些时间去适应。在你认真跑通本章示例并亲自实验之后,我希望继承能成为你进行面向对象设计时的得力工具。
通过完成下面这些练习,你可以练习本章讨论过的内容。所有练习的解答都包含在本书网站 www.wiley.com/go/proc++6e 的代码下载包中。不过,如果你在某道练习上卡住了,请先回头重读本章的相关部分,尽量自己找到答案,然后再查看网站上的解答。
-
练习 10-1: 以练习 9-2 中的
Person类为基础,增加一个名为Employee的派生类。你可以省略练习 9-2 中operator<=>的重载。Employee类应增加一个数据成员,表示员工编号。请提供一个合适的构造函数。接着,再从Employee派生出另外两个类:Manager和Director。请把你的所有类——包括
Person类——都放进一个名为HR的命名空间中。注意,你可以像下面这样从模块中导出命名空间里的全部内容:export namespace HR { /* … */ } -
练习 10-2: 在练习 10-1 解答的基础上,为
Person类增加一个toString()成员函数,返回某个人的字符串表示。然后在Employee、Manager和Director类中重写这个成员函数,并通过把部分工作委托给父类,构造出完整的字符串表示。 -
练习 10-3: 练习你在练习 10-2 中构建出的
Person层次结构的多态行为。定义一个vector,其中混合存储 persons、employees、managers 和 directors,并填入一些测试数据。最后,使用单个基于范围的for循环,对vector中的所有元素调用toString()。 -
练习 10-4: 在现实公司里,员工可能会晋升为经理或总监,而经理也可能会晋升为总监。你是否能想到一种方式,把这种支持加入到练习 10-3 的类层次结构中?