理解迭代器与范围库
第 16 章“C++ 标准库概览”介绍了标准库,解释了它的基本设计理念,并概览了其中提供的功能。本章将开始更深入地探索标准库,先讨论贯穿标准库大量组件的迭代器思想,再介绍可用的流迭代器与迭代器适配器。本章后半部分则聚焦 Ranges 库——这是一个非常强大的库,它让你能够以更偏 函数式风格(functional-style programming)的方式编写代码:你描述的是“想完成什么”,而不是“具体怎么做”。
标准库使用迭代器模式,为访问容器元素提供一种通用抽象。每个容器都会提供该容器专属的 iterator。你可以把它看成一种“增强版指针”:它知道如何遍历该特定容器中的元素,也就是说,iterator 支持在容器元素之间前进。不同容器提供的 iterator 虽然各不相同,但都遵循 C++ 标准定义的统一接口。因此,尽管各类容器的内部机制不同,iterator 却向“想处理容器元素的代码”呈现出一致的使用方式。这会带来多方面好处:代码更容易读写、更不容易出错(例如,与指针算术相比,iterator 更容易被正确使用)、通常也更高效(尤其是对那些不支持随机访问的容器,例如 std::list 和 forward_list;见第 16 章),同时也更容易调试(例如,在调试构建中,iterator 可以执行边界检查)。此外,如果你通过 iterator 遍历容器内容,那么即使容器的底层实现将来完全改变,基于 iterator 的代码通常也不需要修改。
你可以把 iterator 理解成“指向容器中某个特定元素的位置”。和数组元素指针一样,iterator 也可以通过 operator++ 移动到下一个元素。类似地,你通常可以对 iterator 使用 operator* 与 operator->,以访问其对应的实际元素,或者访问元素的成员。有些 iterator 还支持使用 operator== 与 operator!= 进行比较,并支持 operator-- 回到前一个元素。
所有 iterator 都必须是可拷贝构造、可拷贝赋值、可析构的;iterator 的 lvalue 还必须可交换。不同容器提供的 iterator,会在这些基础能力之上附加稍有差异的特性。标准一共定义了六种 iterator 类别,如下表所示:
| 迭代器类别 | 必需操作 | 说明 |
|---|---|---|
| 输入(也叫读) | operator++、*、->、=、==、!=、拷贝构造函数 | 提供只读访问,只能向前移动(没有 operator-- 回退)。可以赋值、拷贝,并可比较是否相等。 |
| 输出(也叫写) | operator++、*、=、拷贝构造函数 | 提供只写访问,只能向前移动。可以赋值,但不能比较是否相等。输出 iterator 的一个特点是支持 *iter = value。注意这里没有 operator->。同时提供前置与后置 operator++。 |
| 前向 | 输入 iterator 的全部能力,再加默认构造函数 | 提供只读访问,只能向前移动。可以赋值、拷贝,并可比较是否相等。 |
| 双向 | 前向 iterator 的全部能力,再加 operator-- | 具备前向 iterator 的全部能力,并且还可以向后移动到前一个元素。提供前置与后置 operator--。 |
| 随机访问 | 双向 iterator 的能力,再加:operator+、-、+=、-=、<、>、<=、>=、[] | 等价于原生指针:支持指针算术、数组下标语法,以及全部比较操作。 |
| 连续 | 具备随机访问能力,并且容器中逻辑上相邻的元素在内存中也必须物理相邻 | 例如 std::array、vector(不含 vector<bool>)、string 与 string_view 的 iterator。 |
根据这张表,标准中存在六种 iterator:input、output、forward、bidirectional、random access 和 contiguous。它们之间并不存在正式的类继承层次;不过,根据所要求支持的功能,我们可以自然推导出一种“能力层级”。具体来说,每个 contiguous iterator 也一定是 random access iterator;每个 random-access iterator 也一定是 bidirectional iterator;每个 bidirectional iterator 也一定是 forward iterator;而每个 forward iterator 也一定是 input iterator。额外满足 output iterator 要求的 iterator,被称为 mutable iterator;否则就称为 constant iterator。图 17.1 展示了这一层级关系。图中使用虚线,是因为它并不是真实的类继承关系。
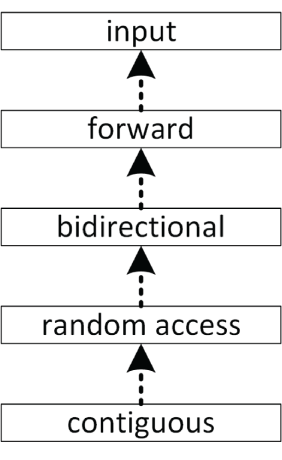
[^图 17.1]
标准算法通常通过类似下面这样的模板类型参数命名,来表达它们所要求的 iterator 类型:InputIterator、OutputIterator、ForwardIterator、BidirectionalIterator、RandomAccessIterator 和 ContiguousIterator。这些名字本身只是名字,并不会自动带来真正的类型约束检查。因此,理论上你完全可以尝试把一个只要求 RandomAccessIterator 的算法,用 bidirectional iterator 去实例化。模板本身无法阻止这种实例化;但一旦函数体中的实现真的用到了 random-access iterator 才具备的能力,代码就会在编译阶段失败。也就是说,要求确实被强制执行了,只不过不是在你最直观以为的地方,因此报错信息往往会有点费解。例如,把要求随机访问 iterator 的泛型 sort() 算法,用在只提供 bidirectional iterator 的 list 上,就可能得到一条相当难懂的编译错误。下面是 Visual C++ 2022 生成的一条错误信息:
…\MSVC\14.37.32705\include\algorithm(8061,45): error C2676: binary '-': 'const std::_List_unchecked_iterator<std::_List_val<std::_List_simple_types<_Ty>>>' does not define this operator or a conversion to a type acceptable to the predefined operator with [ _Ty=int ]本章后半部分会介绍 Ranges 库。该库为大多数标准库算法提供了基于 range 的受约束版本。这些受约束算法会为其模板类型参数附上真正的类型约束(见第 12 章“使用模板编写泛型代码”)。因此,如果你把某个算法用在了“提供错误 iterator 类型”的容器上,编译器通常就能给出更清晰的错误信息。
iterator 的实现方式和 smart pointer 很相似:它们通过重载特定运算符来呈现所需行为。关于运算符重载的细节,请参见第 15 章“重载 C++ 运算符”。
基本的 iterator 操作与原生指针支持的操作很相像,因此原生指针本身就可以充当某些容器的合法 iterator。事实上,vector 的 iterator 从技术上讲完全可以直接实现为普通指针。不过,作为容器的使用者,你不需要关心这些内部实现细节,只要使用 iterator 这一抽象即可。
获取容器的 iterator
Section titled “获取容器的 iterator”标准库中所有支持 iterator 的数据结构,都会公开其 iterator 类型别名,通常命名为 iterator 与 const_iterator。例如,一个 vector<int> 的 const iterator 类型就是 std::vector<int>::const_iterator。支持反向遍历的容器还会额外提供 reverse_iterator 和 const_reverse_iterator 这两个公开类型别名。这样一来,使用者就能在不关心实际底层类型的情况下,直接使用容器提供的 iterator。
容器还会提供 begin() 成员函数,它返回一个指向容器第一个元素的 iterator;end() 成员函数则返回指向该序列“越过末尾位置”的 iterator。也就是说,end() 返回的 iterator,等价于对“指向最后一个元素的 iterator”执行一次 operator++ 后得到的结果。begin() 与 end() 共同定义了一个 左闭右开区间:它包含第一个元素,但不包含最后一个位置。之所以采用这种看起来稍显绕的设计,是为了支持空区间(也就是不含任何元素的容器);在这种情况下,begin() 与 end() 会相等。由 begin() 与 end() 这对 iterator 界定的左闭右开区间,通常记作 [begin, end)。
此外,还提供下列成员函数:
cbegin()与cend():返回constiteratorrbegin()与rend():返回 reverse iteratorcrbegin()与crend():返回constreverse iterator
<iterator> 还提供了若干全局的非成员函数,用于为容器获取对应 iterator:
| 函数名 | 函数概述 |
|---|---|
begin() / end() | 返回序列中第一个元素的非 const iterator,以及越过末尾位置的非 const iterator |
cbegin() / cend() | 返回序列中第一个元素的 const iterator,以及越过末尾位置的 const iterator |
rbegin() / rend() | 返回序列中最后一个元素的非 const reverse iterator,以及位于第一个元素之前位置的非 const reverse iterator |
crbegin() / crend() | 返回序列中最后一个元素的 const reverse iterator,以及位于第一个元素之前位置的 const reverse iterator |
这些非成员函数都定义在 std 命名空间中;不过,尤其是在编写类模板或函数模板这类泛型代码时,推荐按下面这种方式使用它们:
using std::begin;begin(…);注意,这里的 begin() 没有写任何命名空间限定。这样做是为了启用 argument-dependent lookup(ADL,依赖参数的查找)。
如果你为自己的类型特化了本节这些非成员函数,那么你既可以把这些特化放在 std 命名空间里,也可以把它们放在对应类型所在的同一个命名空间里。后者是推荐方式,因为这样就能利用 ADL。借助 ADL,你在调用这些特化时就不需要显式写命名空间限定了:编译器会根据传入参数的类型,到你的命名空间里自动找到正确的特化版本。
把 ADL(也就是不带命名空间限定地调用 begin(…))与 using std::begin 声明结合起来时,编译器会先通过 ADL,到参数类型所属命名空间里查找合适重载;如果没找到,再由于 using 声明而继续去 std 命名空间里找。若你只是直接写 begin() 而没有 using 声明,那么只有通过 ADL 才可能找到用户自定义重载;如果你直接写 std::begin(),那它则只会在 std 命名空间里查找。
当然,ADL 并不只适用于本节讨论的这些函数,它适用于任意函数调用。
有些算法实现需要拿到 iterator 的额外信息。例如,它们也许需要知道该 iterator 所指向元素的类型,以便声明临时变量;又或者它们想知道该 iterator 是 bidirectional 还是 random access。
C++ 为此提供了一个名为 iterator_traits 的类模板,定义在 <iterator> 中。通过它,你可以提取某个 iterator 类型的这些信息。你只需用目标 iterator 类型实例化 iterator_traits,然后访问其中五个类型别名之一:
value_type:iterator 所引用元素的类型difference_type:能够表示两个 iterator 之间距离(也就是元素个数差)的类型iterator_category:iterator 的类别,即input_iterator_tag、output_iterator_tag、forward_iterator_tag、bidirectional_iterator_tag、random_access_iterator_tag或contiguous_iterator_tagpointer:指向元素的指针类型reference:元素引用类型
例如,下面这个函数模板声明了一个临时变量,其类型就是 IteratorType 所引用元素的类型。注意 iterator_traits 前面的 typename 关键字:只要你访问的是“基于一个或多个模板参数推导出来的类型”,就必须显式写出 typename。这里正是因为模板类型参数 IteratorType 被用于访问 iterator_traits 的 value_type。
template <typename IteratorType>void iteratorTraitsTest(IteratorType it){ typename iterator_traits<IteratorType>::value_type temp; temp = *it; println("{}", temp);}你可以用下面这段代码测试这个函数:
vector v { 5 };iteratorTraitsTest(cbegin(v));在这段测试代码中,iteratorTraitsTest() 里的变量 temp 会是 int 类型,输出结果为 5。
当然,这个例子完全可以使用 auto 来简化代码;不过那样就无法展示 iterator_traits 的用法了。
下面这个例子只是简单地用 for 循环加 iterator,遍历 vector 中的全部元素,并把它们打印到标准输出:
vector values { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };for (auto iter { cbegin(values) }; iter != cend(values); ++iter) { print("{} ", *iter);}你也许会想用 operator< 来判断是否到达公共区间末尾,例如写成 iter < cend(values)。不过不建议这样做。判断是否到达区间末尾的标准写法,是使用 !=,也就是 iter != cend(values)。原因在于:!= 适用于全部 iterator 类型,而 < 则并不支持 bidirectional iterator 和 forward iterator。
你还可以实现一个辅助函数:它接收一个由 begin/end iterator 描述的公共区间,并把其中所有元素输出到标准输出。这里使用 input_iterator concept 来约束模板类型参数,只允许输入 iterator:
template <input_iterator Iter>void myPrint(Iter begin, Iter end){ for (auto iter { begin }; iter != end; ++iter) { print("{} ", *iter); }}这个辅助函数可以像下面这样使用:
myPrint(cbegin(values), cend(values));再看第二个例子:一个 myFind() 函数模板,用于在给定公共区间中查找某个值。如果找不到,就返回该区间的 end iterator。注意 value 参数的类型写法:它使用 iterator_traits 来取得传入 iterator 所指向值的类型。
template <input_iterator Iter>auto myFind(Iter begin, Iter end, const typename iterator_traits<Iter>::value_type& value){ for (auto iter { begin }; iter != end; ++iter) { if (*iter == value) { return iter; } } return end;}这个函数模板可以像下面这样使用。这里借助 std::distance() 来计算容器中两个 iterator 之间的距离。
vector values { 11, 22, 33, 44 };auto result { myFind(cbegin(values), cend(values), 22) };if (result != cend(values)) { println("Found value at position {}", distance(cbegin(values), result));}本章以及后续章节里还会继续给出更多 iterator 使用示例。
使用迭代器特征做函数分发
Section titled “使用迭代器特征做函数分发”标准库提供了 std::advance(iter, n) 函数,用来把给定 iterator iter 前进 n 个位置。这个函数适用于所有 iterator 类型。对 random-access iterator 来说,它本质上只是执行 iter += n;而对其他类型的 iterator 来说,则需要在循环里执行 ++iter 或 --iter 共 n 次,具体取决于 n 是正还是负。你可能会好奇,这样的行为是怎么实现的。一个常见办法是使用 函数分发(function dispatching):根据 iterator 类别,把请求分派给不同的辅助函数。下面给出一个简化版的 myAdvance(iter, n) 实现,用它来展示这种分发技巧:
template <typename Iter, typename Distance>void advanceHelper(Iter& iter, Distance n, input_iterator_tag){ while (n > 0) { ++iter; --n; }}
template <typename Iter, typename Distance>void advanceHelper(Iter& iter, Distance n, bidirectional_iterator_tag){ while (n > 0) { ++iter; --n; } while (n < 0) { --iter; ++n; }}
template <typename Iter, typename Distance>void advanceHelper(Iter& iter, Distance n, random_access_iterator_tag){ iter += n;}
template <typename Iter, typename Distance>void myAdvance(Iter& iter, Distance n){ using category = typename iterator_traits<Iter>::iterator_category; advanceHelper(iter, n, category {});}这份 myAdvance() 实现既可以用于 vector 的 random-access iterator,也可以用于 list 的 bidirectional iterator,等等:
template <typename Iter>void testAdvance(Iter iter){ print("*iter = {} | ", *iter); myAdvance(iter, 3); print("3 ahead = {} | ", *iter); myAdvance(iter, -2); println("2 back = {}", *iter);}
int main(){ vector vec { 1, 2, 3, 4, 5, 6 }; testAdvance(begin(vec)); list lst { 1, 2, 3, 4, 5, 6 }; testAdvance(begin(lst));}输出如下:
*iter = 1 | 3 ahead = 4 | 2 back = 2*iter = 1 | 3 ahead = 4 | 2 back = 2有了 concepts(见第 12 章)之后,myAdvance() 还可以写得更简洁:不再需要辅助函数,直接给 myAdvance() 提供带约束的重载即可:
template <input_iterator Iter, typename Distance>void myAdvance(Iter& iter, Distance n){ while (n > 0) { ++iter; --n; }}
template <bidirectional_iterator Iter, typename Distance>void myAdvance(Iter& iter, Distance n){ while (n > 0) { ++iter; --n; } while (n < 0) { --iter; ++n; }}
template <random_access_iterator Iter, typename Distance>void myAdvance(Iter& iter, Distance n){ iter += n;}标准库提供了四种 stream iterator(流迭代器)。它们是一些“表现得像 iterator 的类模板”,让你可以把输入流和输出流分别当作 input iterator 与 output iterator 来使用。借助这些流迭代器,你就能把输入输出流适配成各种标准库算法的数据源或目标端。可用的流迭代器如下:
ostream_iterator:向basic_ostream写入数据的 output iteratoristream_iterator:从basic_istream读取数据的 input iteratorostreambuf_iterator:向basic_streambuf写入数据的 output iteratoristreambuf_iterator:从basic_streambuf读取数据的 input iterator
输出流迭代器:ostream_iterator
Section titled “输出流迭代器:ostream_iterator”ostream_iterator 是一种 输出流迭代器。它是一个类模板,以元素类型作为模板参数。它的构造函数接收一个输出流,以及一个分隔符字符串;每写出一个元素之后,都会把该分隔符也输出到流中。ostream_iterator 使用 operator<< 来写入元素。
先看一个例子。假设你有下面这样一个 myCopy() 函数模板:它把一个由 begin/end iterator 给出的公共区间复制到另一个由 begin iterator 指定的目标区间。第二个模板类型参数被约束为 output iterator,并且它接收的值类型是 std::iter_reference_t<InputIter>,也就是给定 InputIter 所引用元素的类型。
template <input_iterator InputIter, output_iterator<iter_reference_t<InputIter>> OutputIter>void myCopy(InputIter begin, InputIter end, OutputIter target){ for (auto iter { begin }; iter != end; ++iter, ++target) { *target = *iter; }}myCopy() 的前两个参数是待复制区间的 begin 与 end iterator,第三个参数则是目标区间的 iterator。你必须确保目标区间足够大,能够容纳源区间的全部元素。把 myCopy() 用来把一个 vector 复制到另一个 vector,写法相当直接:
vector myVector { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };// Use myCopy() to copy myVector to vectorCopy.vector<int> vectorCopy(myVector.size());myCopy(cbegin(myVector), cend(myVector), begin(vectorCopy));现在,借助 ostream_iterator,myCopy() 还可以被用来“只写一行代码就打印容器中的元素”。下面这段代码会输出 myVector 与 vectorCopy 的内容:
// Use the same myCopy() to print the contents of both vectors.myCopy(cbegin(myVector), cend(myVector), ostream_iterator<int> { cout, " " });println("");myCopy(cbegin(vectorCopy), cend(vectorCopy), ostream_iterator<int> { cout, " " });println("");输出如下:
1 2 3 4 5 6 7 8 9 101 2 3 4 5 6 7 8 9 10输入流迭代器:istream_iterator
Section titled “输入流迭代器:istream_iterator”你可以使用 输入流迭代器 istream_iterator,以 iterator 抽象的方式从输入流中读取值。它同样是一个类模板,以元素类型作为模板参数;构造函数接收一个输入流。元素通过 operator>> 读取。你可以把 istream_iterator 作为算法或容器成员函数的数据源。
假设你有下面这个 sum() 函数模板,用来对给定公共区间中的所有元素求和:
template <input_iterator InputIter>auto sum(InputIter begin, InputIter end){ auto sum { *begin }; for (auto iter { ++begin }; iter != end; ++iter) { sum += *iter; } return sum;}现在,你就可以使用 istream_iterator 从控制台读取整数,直到流结束为止。在 Windows 上,这通常是在按下 Ctrl+Z 后再回车;在 Linux 上,则是先回车再按 Ctrl+D。然后调用 sum() 计算这些整数的总和。一个默认构造的 istream_iterator 表示 end iterator。
println("请输入以空白分隔的数字。");println("按 Ctrl+Z 再回车以结束输入。");istream_iterator<int> numbersIter { cin };istream_iterator<int> endIter;int result { sum(numbersIter, endIter) };println("总和:{}", result);输入流迭代器:istreambuf_iterator
Section titled “输入流迭代器:istreambuf_iterator”istreambuf_iterator 的一个典型用途,是只用一条语句就读取整个文件内容。默认构造的 istreambuf_iterator 表示 end iterator。示例如下:
ifstream inputFile { "some_data.txt" };if (inputFile.fail()) { println(cerr, "Unable to open file for reading."); return 1;}string fileContents { istreambuf_iterator<char> { inputFile }, istreambuf_iterator<char> { }};println("{}", fileContents);迭代器适配器
Section titled “迭代器适配器”标准库提供了若干 迭代器适配器,也就是特殊形式的 iterator,它们都定义在 <iterator> 中。它们大体分成两类。第一类适配器由容器构造而来,通常作为 output iterator 使用:
back_insert_iterator:通过push_back()向容器插入元素front_insert_iterator:通过push_front()向容器插入元素insert_iterator:通过insert()向容器插入元素
另一类适配器则是基于另一个 iterator 构造出来的,通常作为 input iterator 使用。两种常见的适配器是:
reverse_iterator:把另一个 iterator 的遍历方向反转move_iterator:它的解引用运算符会自动把值转换成 rvalue reference,因此值可以被移动到新目标位置,而不必复制
当然,也可以自己编写迭代器适配器,不过本书不再展开。相关细节请参考附录 B“注释书目”里列出的标准库参考资料。
本章前面实现的 myCopy() 函数模板,并不会真正往容器里插入元素;它只是用新元素覆盖目标区间中原有的旧元素。为了让这类算法更实用,标准库提供了三种真正会往容器里插入元素的 插入迭代器适配器:insert_iterator、back_insert_iterator 和 front_insert_iterator。它们都以容器类型作为模板参数,并在构造函数里接收一个实际容器引用。由于它们满足 iterator 接口要求,因此可以作为诸如 myCopy() 这类算法的目标 iterator 使用。只不过,它们不会覆盖已有元素,而是调用容器自身的插入操作,把新元素真正插入进去。
基础版的 insert_iterator 会对容器调用 insert(position, element);back_insert_iterator 会调用 push_back(element);front_insert_iterator 则调用 push_front(element)。
下面这个例子使用 back_insert_iterator 配合 myCopy(),把 vectorOne 中的所有元素复制插入到 vectorTwo。注意,这里并没有提前把 vectorTwo 调整到足够大小,插入迭代器会负责正确插入新元素:
vector vectorOne { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };vector<int> vectorTwo;
back_insert_iterator<vector<int>> inserter { vectorTwo };myCopy(cbegin(vectorOne), cend(vectorOne), inserter);
println("{:n}", vectorTwo);可以看到,使用插入迭代器时,你不再需要预先调整目标容器大小。
你也可以使用 std::back_inserter() 这个工具函数来创建 back_insert_iterator。对于前面的例子,可以删掉定义 inserter 变量的那一行,并把 myCopy() 改写成:
myCopy(cbegin(vectorOne), cend(vectorOne), back_inserter(vectorTwo));借助类模板实参推导(CTAD),它还可以写成:
myCopy(cbegin(vectorOne), cend(vectorOne), back_insert_iterator { vectorTwo });front_insert_iterator 与 insert_iterator 的工作方式类似,只不过 insert_iterator 的构造函数还需要额外接收一个初始插入位置 iterator,并把它作为第一次调用 insert(position, element) 时的位置。后续插入时用到的位置 hint,则根据每次 insert() 的返回值自动更新。
insert_iterator 的一个好处,是它允许你把关联容器作为“修改型算法”的目标区间。第 20 章“精通标准库算法”会解释:关联容器的问题在于,你不能修改它们正在迭代的 key。而当你使用 insert_iterator 时,你做的是“插入新元素”,而不是“修改现有元素”。关联容器都提供接收 iterator position 的 insert() 成员函数,该 position 只是一个 hint,容器本身可以忽略它。当你在关联容器上使用 insert_iterator 时,可以把容器的 begin() 或 end() 传进去作为这个 hint。insert_iterator 会在每次 insert() 之后,基于其返回值自动调整下一个插入位置,使之位于刚插入元素之后。
下面把前面的例子改成以 set 而不是 vector 作为目标容器:
vector vectorOne { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };set<int> setOne;
insert_iterator<set<int>> inserter { setOne, begin(setOne) };myCopy(cbegin(vectorOne), cend(vectorOne), inserter);
println("{:n}", setOne);类似于前面的 back_insert_iterator 示例,这里也可以使用 std::inserter() 来创建 insert_iterator:
myCopy(cbegin(vectorOne), cend(vectorOne), inserter(setOne, begin(setOne)));或者借助类模板实参推导,写成:
myCopy(cbegin(vectorOne), cend(vectorOne), insert_iterator { setOne, begin(setOne) });标准库提供了 std::reverse_iterator 这个类模板,用来以相反方向遍历某个 bidirectional 或 random-access iterator。标准库中所有可逆容器——也就是除 forward_list 与无序关联容器之外的全部标准容器——都提供了 reverse_iterator 类型别名,以及 rbegin() 和 rend() 成员函数。这些 reverse_iterator 类型别名,本质上都是 std::reverse_iterator<T>,其中 T 就是对应容器的 iterator 类型别名。rbegin() 返回一个指向容器最后一个元素的 reverse_iterator,rend() 则返回一个指向“位于第一个元素之前位置”的 reverse_iterator。对 reverse_iterator 应用 operator++,实际上会对其底层容器 iterator 执行 operator--;反过来也一样。例如,从头到尾遍历一个集合,可以这样写:
for (auto iter { begin(collection) }; iter != end(collection); ++iter) {}而如果想从尾到头遍历它,就可以通过 rbegin() 和 rend() 使用 reverse_iterator。注意,这里依然写的是 ++iter:
for (auto iter { rbegin(collection) }; iter != rend(collection); ++iter) {}std::reverse_iterator 主要适合与那些“本身没有反向版本”的标准库算法或你自己的函数配合使用。本章前面介绍的 myFind() 用于搜索序列中的第一个匹配元素。如果你想找的是最后一个匹配元素,就可以改用 reverse_iterator。注意,当你把 reverse_iterator 传给 myFind() 这类算法时,算法返回的也会是 reverse_iterator。你可以随时通过 base() 成员函数,从 reverse_iterator 取回它内部包装的底层普通 iterator。不过,由于 reverse_iterator 的实现方式,base() 返回的 iterator 总是指向“当前 reverse_iterator 所指元素的后一个位置”。因此,如果你想回到同一个元素,就必须再减一。
下面是使用 reverse_iterator 调用 myFind() 的示例:
vector myVector { 11, 22, 33, 22, 11 };auto it1 { myFind(begin(myVector), end(myVector), 22) };auto it2 { myFind(rbegin(myVector), rend(myVector), 22) };if (it1 != end(myVector) && it2 != rend(myVector)) { println("Found at position {} going forward.", distance(begin(myVector), it1)); println("Found at position {} going backward.", distance(begin(myVector), --it2.base()));} else { println("Failed to find.");}程序输出如下:
Found at position 1 going forward.Found at position 3 going backward.第 9 章“精通类与对象”讨论了 移动语义(move semantics)。在你确信源对象在赋值或拷贝构造之后会被销毁的场景中,或者你显式使用 std::move() 的时候,移动语义可以避免不必要的复制。标准库为此提供了一个迭代器适配器:std::move_iterator。它的解引用运算符会自动把值转换成 rvalue reference,也就是说,这个值可以被移动到新目标位置,而不需要承担复制的开销。使用移动语义之前,前提是你自己的对象类型已经正确支持它。下面这个 MoveableClass 就支持移动语义。更多细节请见第 9 章。
class MoveableClass{ public: MoveableClass() { println("Default constructor"); } MoveableClass(const MoveableClass& src) { println("Copy constructor"); } MoveableClass(MoveableClass&& src) noexcept { println("Move constructor"); } MoveableClass& operator=(const MoveableClass& rhs) { println("Copy assignment operator"); return *this; } MoveableClass& operator=(MoveableClass&& rhs) noexcept { println("Move assignment operator"); return *this; }};这些构造函数和赋值运算符本身并没有真正做什么有意义的事情;它们只是打印一条消息,方便你观察当前到底调用的是哪一个。现在,有了这个类之后,你可以这样定义一个 vector,并往里面放入几个 MoveableClass 实例:
vector<MoveableClass> vecSource;MoveableClass mc;vecSource.push_back(mc);vecSource.push_back(mc);输出可能如下所示。每行后面的编号并不是程序输出的一部分,而是为了便于后文解释:
Default constructor // [1]Copy constructor // [2]Copy constructor // [3]Move constructor // [4]代码第二行通过默认构造函数创建了一个 MoveableClass 实例,也就是 [1]。第一次调用 push_back() 时,会触发拷贝构造函数,把 mc 复制进 vector 中,对应 [2]。此时 vector 中有空间存放一个元素,也就是 mc 的第一份副本。需要说明的是:这里的讨论基于 Microsoft Visual C++ 2022 中 vector 的增长策略和初始容量行为。C++ 标准本身并没有规定 vector 的初始容量和扩容策略,所以不同编译器的输出可能不同。
第二次调用 push_back() 时,会导致 vector 扩容,为第二个元素分配更多空间。扩容会触发移动构造函数,把旧 vector 中已有的元素移动到新的、更大的存储区里,对应 [4]。与此同时,拷贝构造函数还会再次被调用,把 mc 的第二份副本复制到 vector 中,对应 [3]。移动和复制发生的先后顺序未定义,因此 [3] 与 [4] 的顺序也有可能相反。
你可以像下面这样创建一个新的 vector vecOne,让它包含 vecSource 中元素的副本:
vector<MoveableClass> vecOne { cbegin(vecSource), cend(vecSource) };如果不使用 move_iterator,这段代码会触发两次拷贝构造函数——vecSource 中每个元素各拷贝一次:
Copy constructorCopy constructor但如果你使用 std::make_move_iterator() 创建 move_iterator,那么被调用的就不再是拷贝构造,而是 MoveableClass 的移动构造:
vector<MoveableClass> vecTwo { make_move_iterator(begin(vecSource)), make_move_iterator(end(vecSource)) };这会产生如下输出:
Move constructorMove constructor你也可以结合类模板实参推导来写 move_iterator:
vector<MoveableClass> vecTwo { move_iterator { begin(vecSource) }, move_iterator { end(vecSource) } };请记住,一旦某个对象已经被移动到别处,就不应再继续使用它。
Ranges 库
Section titled “Ranges 库”标准库中的 iterator 机制,使算法能够脱离具体容器类型而独立工作,因为 iterator 屏蔽了“如何在容器元素之间移动”的底层细节。正如你在本章前面所有 iterator 示例中看到的那样,大多数算法都需要一对 iterator:一个 begin iterator,指向序列的第一个元素;一个 end iterator,指向越过末尾的位置。这样的设计确实让算法能够适配各种容器,但每次都要手动传入两个 iterator,既显得有点繁琐,也容易不小心传错,形成不匹配的 iterator 组合。Ranges 是建立在 iterator 之上的一层抽象。它消除了 begin/end iterator 不匹配这类错误,并带来了更多功能,例如借助 range adapter 对底层元素序列做惰性过滤与变换。定义在 <ranges> 中的 Ranges 库,主要由以下几大部分组成:
- Ranges: range 是一个 concept(见第 12 章),它规定了一个类型如果想支持对自身元素的迭代,需要满足哪些要求。任何支持
begin()与end()的数据结构,都是合法的 range。例如std::array、vector、string_view、span、定长 C 风格数组等,全部都属于合法 range。 - 受约束算法: 第 16 章与第 20 章介绍了那些通过 iterator 对来工作的标准库算法。对于其中大多数算法,标准库都提供了等价的、基于 range 的受约束版本,它们既可以接收 iterator 对,也可以直接接收 range。
- Projection(投影): 很多受约束算法都支持 projection 回调。算法会对 range 中的每个元素先调用该回调,把元素投影为另一个值,再将这个值交给算法后续处理。
- Views(视图): 视图可以用来对某个底层 range 的元素执行变换或过滤。多个视图还可以组合起来,形成一个对 range 逐步施加操作的管线。
- Factories(工厂): 范围工厂用来构造“按需生成值”的视图。
对 range 元素的遍历,可以通过 ranges::begin()、end()、rbegin() 等访问器拿到相应 iterator 来完成。range 还支持 ranges::empty()、data()、cdata() 与 size()。其中 size() 只有在可以常数时间取得元素个数时才可用;否则,就该使用 std::distance() 来计算 range 的 begin iterator 与 end iterator 之间的距离。所有这些访问器都不是成员函数,而是独立的自由函数,并且都需要以 range 作为参数。
此外,std::format()、print() 与 println() 都原生支持对 range 进行格式化和打印,本节中的不少例子都会展示这一点。
std::sort() 就是一个典型例子:它要求你传入一个由 begin 与 end iterator 构成的元素序列。标准库算法在第 16 章中做过介绍,并会在第 20 章中详细展开。sort() 的用法很直接。例如,下面这段代码会对一个 vector 中的全部元素排序:
vector data { 33, 11, 22 };sort(begin(data), end(data));这段代码确实能对 data 容器的全部元素排序,但你必须显式把该序列写成 begin/end iterator 对。有没有一种方式,能让代码更直接地表达你的真实意图?这正是 基于 range 的受约束算法(在本书中简称 受约束算法)要解决的问题。这些算法位于 std::ranges 命名空间中,并定义在与其不受约束版本相同的头文件中。借助它们,你就可以直接写成:
ranges::sort(data);这段代码更准确地表达了你的意图:对 data 容器中的全部元素排序。既然你不再显式传入 iterator,那么这类受约束算法也就顺便消除了“误传不匹配 begin/end iterator”的可能性。此外,受约束算法会为其模板类型参数施加真正的类型约束(见第 12 章),因此如果你把某个“不能提供算法所要求 iterator 类型”的容器传进去,编译器通常能给出更清晰的错误信息。例如,把 ranges::sort() 用在 std::list 上时,编译器就会更明确地指出:sort() 需要的是 random-access range,而 list 并不满足这一点。和 iterator 一样,range 也有 input、output、forward、bidirectional、random-access 与 contiguous 等分类,对应的 concept 例如 ranges::contiguous_range、ranges::random_access_range 等。
很多受约束算法都带有一个 projection(投影)参数。它是一个回调,用来在元素真正交给算法前,先把元素转换成另一个值。来看个例子。假设你有一个简单的 Person 类:
class Person{ public: explicit Person(string first, string last) : m_firstName { move(first) }, m_lastName { move(last) } { } const string& getFirstName() const { return m_firstName; } const string& getLastName() const { return m_lastName; } private: string m_firstName; string m_lastName;};下面这段代码把几个 Person 对象存入一个 vector:
vector persons { Person {"John", "White"}, Person {"Chris", "Blue"} };由于 Person 类没有实现 operator<,你无法直接用普通的 std::sort() 来对这个 vector 排序,因为默认排序比较的是元素的 operator<。因此,下面这行代码无法编译:
sort(begin(persons), end(persons)); // Error: does not compile.表面上看,切换到受约束版本的 ranges::sort() 似乎也没有立刻解决问题,因为算法依然不知道该如何比较 range 中的 Person 元素:
ranges::sort(persons); // Error: does not compile.不过,你可以通过 projection,让 sort 按 first name 对 persons 排序:也就是在比较每个 Person 时,先把它投影为自己的名字。projection 是 sort 的第三个参数,因此第二个参数——比较器——也必须一并写出来;默认比较器是 std::ranges::less。下面这个调用里,{} 表示使用默认比较器,而 projection(投影)则由一个 lambda expression 给出;相关细节见后面的说明。
ranges::sort(persons, {}, [](const Person& person) { return person.getFirstName(); });还可以写得更简洁:
ranges::sort(persons, {}, &Person::getFirstName);视图 允许你对某个底层 range 的元素执行操作,例如过滤或转换。多个视图还可以串接/组合起来,形成一个对元素依次施加多步处理的 管线。组合视图非常简单:把不同操作通过按位或运算符 operator| 串起来即可。比如,你可以先过滤某个 range 的元素,再对过滤后的结果做转换。相对而言,如果你想用不受约束算法去完成类似“先过滤、再转换”的工作,代码往往会更难读,也可能更低效,因为你常常不得不引入临时容器保存中间结果。
视图具有以下几个重要特性:
- 惰性求值: 仅仅构造一个视图时,并不会立刻执行任何操作。只有当你真正开始遍历这个视图的元素,并解引用它的 iterator 时,这些操作才会实际发生。
- 非拥有1: 视图不拥有任何元素。正如名字所示,它只是“对某个 range 元素的一种视图”;这些元素通常真正存放在某个容器里,而那个容器才是数据的拥有者。视图只是让你以不同方式观察那份数据。因此,视图中元素数量的多少,并不会影响视图本身的拷贝、移动或析构成本。这与第 2 章“使用字符串与字符串视图”中介绍的
std::string_view,以及第 18 章“标准库容器”中介绍的std::span十分相似。 - 不修改底层数据: 视图本身永远不会去修改底层 range 中的数据。
视图自己也是一种 range;不过并不是每个 range 都是视图。容器就是 range,但它不是视图,因为它拥有自己的元素。
视图可以通过 range adapter(范围适配器)来构造。范围适配器接收一个底层元素序列,并可选接收一些额外参数,然后返回一个新的视图。下表列出了标准库提供的范围适配器。如果这些标准适配器都不能满足你的需求,你也可以自己编写范围适配器,并让它与现有适配器正常互操作。不过,要写出一个真正完善、可用于生产环境的范围适配器并不简单,这超出了本书的范围。更详细的内容请参考你熟悉的标准库资料。
| 范围适配器 | 说明 |
|---|---|
views::all | 创建一个包含某个 range 全部元素的视图。 |
filter_view / views::filter | 基于给定谓词过滤底层序列中的元素。若谓词返回 true,元素被保留;否则跳过。 |
transform_view / views::transform | 对底层序列中的每个元素调用回调,将其转换为另一个值,甚至可变成不同类型。 |
take_view / views::take | 取另一个视图的前 n 个元素,组成新的视图。 |
take_while_view / views::take_while | 从底层序列开头开始取元素,直到遇到某个让谓词返回 false 的元素为止。 |
drop_view / views::drop | 丢弃另一个视图的前 n 个元素,得到新的视图。 |
drop_while_view / views::drop_while | 丢弃底层序列起始处所有让谓词持续返回 true 的元素,直到遇到返回 false 的元素为止。 |
join_view / views::join | 把“由多个 range 组成的视图”拍平成单一视图。例如把 vector<vector<int>> 拍平成 vector<int> 的视图。 |
lazy_split_view / views::lazy_split / split_view / views::split | 给定分隔符,把某个视图按该分隔符拆成多个子区间。分隔符可以是单个元素,也可以是一个元素视图。 |
reverse_view / views::reverse | 创建一个按相反顺序遍历另一个视图元素的视图。要求底层视图至少是 bidirectional view。 |
elements_view / views::elements | 要求底层视图的元素是 tuple-like,对其提取每个 tuple-like 元素的第 n 个成员,形成视图。 |
keys_view / views::keys | 要求底层视图的元素是 pair-like,提取每个 pair 的第一个成员,形成视图。 |
values_view / views::values | 要求底层视图的元素是 pair-like,提取每个 pair 的第二个成员,形成视图。 |
common_view / views::common | 在某些 range 中,begin() 和 end() 返回的类型可能不同,例如一个返回 begin iterator、一个返回 end sentinel。这意味着这对对象不能直接传给那些要求“二者类型相同”的函数。common_view 可把这种 range 转换成 common range,也就是 begin() 与 end() 返回同类型的 range。本章习题中你会用到它。 |
| 范围适配器 | 说明 |
|---|---|
as_const_view / views::as_const | 创建一个视图,在这个视图中不能修改底层序列的元素。 |
as_rvalue_view / views::as_rvalue | 创建一个由底层序列所有元素的 rvalue 组成的视图。 |
enumerate_view / views::enumerate | 创建一个视图,其中每个元素都同时表示底层序列中某个元素的位置和值。 |
zip_view / views::zip | 给定多个视图,创建一个由 tuple 组成的视图,其中每个 tuple 都包含各个视图对应位置元素的引用。 |
zip_transform_view / views::zip_transform | 给定多个视图与一个 callable,创建一个视图,其第 i 个元素是该 callable 作用于所有视图第 i 个元素后的结果。 |
adjacent_view / views::adjacent | 给定 n,创建一个视图,其第 i 个元素是一个 tuple,包含原始视图第 i 到第 (i + n − 1) 个元素的引用。 |
adjacent_transform_view / views::adjacent_transform | 给定 n 与一个 callable,创建一个视图,其第 i 个元素是该 callable 作用于原始视图第 i 到第 (i + n − 1) 个元素后的结果。 |
views::pairwise / views::pairwise_transform | 分别是 views::adjacent<2> 与 views::adjacent_transform<2> 的辅助别名。 |
join_with_view / views::join_with | 给定一个分隔符,对某个视图进行扁平化,并在每个元素之间插入分隔符中的元素。分隔符可以是单个元素,也可以是一个元素视图。 |
stride_view / views::stride | 给定 n,创建一个视图:它每次前进 n 个元素,而不是逐个前进。 |
slide_view / views::slide | 给定 n,创建一个视图,其第 i 个元素本身又是一个视图,覆盖原始视图中第 i 到第 (i + n − 1) 个元素。它和 views::adjacent 类似,但 slide 的窗口大小 n 是运行时参数,而 adjacent 的 n 是模板参数。 |
chunk_view / views::chunk | 给定 n,把原始视图的元素按顺序分成多个大小为 n、互不重叠的连续块,返回由这些子视图组成的 range。 |
chunk_by_view / views::chunk_by | 根据给定谓词,把一个视图拆成若干子区间;每当相邻两个元素让谓词返回 false 时,就在它们之间切开。 |
cartesian_product_view / views::cartesian_product | 给定若干个 range,创建一个由 tuple 组成的视图,这些 tuple 来自所有给定 range 的笛卡尔积。 |
上面两张表第一列中列出的名字,同时包含了位于 std::ranges 命名空间中的类名,以及位于 std::ranges::views 命名空间中的对应 range adapter object(范围适配器对象)。标准库还提供了一个命名空间别名 std::views,它等价于 std::ranges::views。
每个范围适配器都可以通过调用其构造函数来构造,并传入所需参数。第一个参数永远是待处理的 range,后面还可以跟零个或多个附加参数:
std::ranges::operation_view { range, arguments… }不过,在实际使用中,你通常不会直接调用这些适配器的构造函数,而更常见的是使用 std::ranges::views 命名空间中的 range adapter object(范围适配器对象),再配合按位或运算符 | 来形成管线:
range | std::ranges::views::operation(arguments…)下面通过一个完整示例来看看这些范围适配器是如何工作的。示例首先定义了一个缩写函数模板 printRange(),用来输出一条消息以及给定 range 中的全部元素。接着,在 main() 函数里先创建一个整数 vector,内容为 1…10,然后依次对它应用多个范围适配器;每做一步,都调用 printRange() 输出当前结果,便于你观察每一步发生了什么。之后,这个示例还演示了若干 C++23 新增的范围适配器。示例里还会用到本章前面介绍过的 myCopy()。
void printRange(string_view msg, auto&& range) { println("{}{:n}", msg, range); }
int main(){ vector values { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; printRange("原始序列:", values);
// 过滤掉所有奇数值,只保留偶数值。 auto result1 { values | views::filter([](const auto& value) { return value % 2 == 0; }) }; printRange("仅保留偶数:", result1);
// 把所有值都变成原来的两倍。 auto result2 { result1 | views::transform([](const auto& value) { return value * 2.0; }) }; printRange("数值翻倍后:", result2);
// Drop the first 2 elements. auto result3 { result2 | views::drop(2) }; printRange("First two dropped: ", result3);
// Reverse the view. auto result4 { result3 | views::reverse }; printRange("Sequence reversed: ", result4);
// C++23: views::zip vector v1 { 1, 2 }; vector v2 { 'a', 'b', 'c' }; auto result5 { views::zip(v1, v2) }; printRange("views::zip: ", result5);
// C++23: views::adjacent vector v3 { 1, 2, 3, 4, 5 }; auto result6 { v3 | views::adjacent<2> }; printRange("views::adjacent: ", result6);
// C++23: views::chunk auto result7 { v3 | views::chunk(2) }; printRange("views::chunk: ", result7);
// C++23: views::stride auto result8 { v3 | views::stride(2) }; printRange("views::stride: ", result8);
// C++23: views::enumerate + views::split string lorem { "Lorem ipsum dolor sit amet" }; for (auto [index, word] : lorem | views::split(' ') | views::enumerate) { print("{}:'{}' ", index, string_view { word }); } println("");
// C++23: views::as_rvalue vector<string> words { "Lorem", "ipsum", "dolor", "sit", "amet" }; vector<string> movedWords; auto rvalueView { words | views::as_rvalue }; myCopy(begin(rvalueView), end(rvalueView), back_inserter(movedWords)); printRange("movedWords: ", movedWords);
// C++23: Cartesian product of vector v with itself. vector v { 0, 1, 2 }; for (auto&&[a, b] : views::cartesian_product(v, v)) {print("({},{}) ", a, b);}}程序输出如下:
Original sequence: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10Only even values: 2, 4, 6, 8, 10Values doubled: 4, 8, 12, 16, 20First two dropped: 12, 16, 20Sequence reversed: 20, 16, 12views::zip: (1, 'a'), (2, 'b')views::adjacent: (1, 2), (2, 3), (3, 4), (4, 5)views::chunk: (1, 2), (3, 4), (5)views::stride: 1, 3, 50:'Lorem' 1:'ipsum' 2:'dolor' 3:'sit' 4:'amet'movedWords: Lorem, ipsum, dolor, sit, amet(0,0) (0,1) (0,2) (1,0) (1,1) (1,2) (2,0) (2,1) (2,2)值得再次强调的是,视图是惰性求值的。在这个例子中,仅仅构造 result1 这个视图时,并不会真的执行过滤;真正的过滤发生在 printRange() 开始遍历 result1 元素的那一刻。
上面的代码使用的是 std::ranges::views 中的 range adapter object(范围适配器对象)。你当然也可以直接通过构造函数来创建这些范围适配器。例如,result1 也可以这样构造:
auto result1 { ranges::filter_view { values, [](const auto& value) { return value % 2 == 0; } } };这个例子为了方便你观察每一步发生了什么,特意创建了若干中间视图:result1、result2、result3 和 result4。如果你并不需要这些中间视图,那么完全可以把所有操作串成单一管线:
vector values { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };printRange("Original sequence: ", values);
auto result { values | views::filter([](const auto& value) { return value % 2 == 0; }) | views::transform([](const auto& value) { return value * 2.0; }) | views::drop(2) | views::reverse };printRange("Final sequence: ", result);输出如下。最后一行可以看到,这个最终序列与前面得到的 result4 视图完全一致:
Original sequence: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10Final sequence: 20, 16, 12通过视图修改元素
Section titled “通过视图修改元素”有些 range 是只读的。例如,views::transform 的结果就是只读视图,因为它生成的是“变换后的元素视图”,而不是直接改写底层 range 中的真实值。如果某个 range 不是只读的,那么你就可以通过视图来修改其中元素。下面看一个例子。
下例先构造了一个包含十个元素的 vector,然后依次构造出一个“只看偶数”的视图、一个“丢掉前两个偶数”的视图,以及一个“逆序”的视图。随后,range-based for 循环会把最终视图中的元素全部乘以 10。最后一行再输出原始 values vector 的内容,用来证明:这些元素确实是通过视图被修改了。
vector values { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };printRange("Original sequence: ", values);
// Filter out all odd values, leaving only the even values.auto result1 { values | views::filter([](const auto& value) { return value % 2 == 0; }) };printRange("Only even values: ", result1);
// Drop the first 2 elements.auto result2 { result1 | views::drop(2) };printRange("First two dropped: ", result2);
// Reverse the view.auto result3 { result2 | views::reverse };printRange("Sequence reversed: ", result3);
// Modify the elements using a range-based for loop.for (auto& value : result3) { value *= 10; }printRange("After modifying elements through a view, vector contains:\n", values);输出如下:
Original sequence: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10Only even values: 2, 4, 6, 8, 10First two dropped: 6, 8, 10Sequence reversed: 10, 8, 6After modifying elements through a view, vector contains: 1, 2, 3, 4, 5, 60, 7, 80, 9, 100对一个 range 做 transform,并不要求结果中的元素类型必须和原来相同。你完全可以把元素 映射(map)成另一种类型。下面这个例子从一组整数开始,先过滤掉所有奇数,再保留前三个偶数,最后用 std::format() 把它们变成字符串:
vector values { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };printRange("Original sequence: ", values);
auto result { values | views::filter([](const auto& value) { return value % 2 == 0; }) | views::take(3) | views::transform([](const auto& v) { return format("{}", v); }) };printRange("Result: ", result);输出如下:
Original sequence: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10Result: "2", "4", "6"Ranges 库还提供了若干 范围工厂,用于构造“按需、惰性地产生元素”的视图:
| 范围工厂 | 说明 |
|---|---|
empty_view | 创建一个空视图。 |
single_view | 创建一个只包含单个给定元素的视图。 |
iota_view | 创建一个无限或有界的视图:从初始值开始,后续每个元素都等于前一个元素加一。 |
repeat_view | 创建一个重复给定值的视图。它既可以是无界(无限)的,也可以被限制为固定数量的元素。 |
basic_istream_view / istream_view | 创建一个视图,其元素通过对底层输入流调用提取运算符 operator>> 得到。 |
和前面介绍的范围适配器一样,表中这些名字都是位于 std::ranges 命名空间中的类名,因此你可以直接通过构造函数来创建它们。另一种方式,是使用位于 std::ranges::views 命名空间中的工厂函数。例如,下面这两条语句是等价的,都会创建一个从 10 开始、无限延伸为 10、11、12…… 的视图:
std::ranges::iota_view { 10 }std::ranges::views::iota(10)下面看一个实际示例。这个例子与本章前面的某个示例有些相似,只不过它不再预先构造一个包含 10 个元素的 vector,而是通过 iota 范围工厂创建一个从 10 开始的惰性无限整数序列。接着,它过滤掉所有奇数,把剩余元素翻倍,最后只保留前十个元素,再通过 printRange() 输出到控制台:
// Create an infinite sequence of the numbers 10, 11, 12, …auto values { views::iota(10) };// Filter out all odd values, leaving only the even values.auto result1 { values | views::filter([](const auto& value) { return value % 2 == 0; }) };// Transform all values to their double value.auto result2 { result1 | views::transform([](const auto& value) { return value * 2.0; }) };// Take only the first ten elements.auto result3 { result2 | views::take(10) };printRange("Result: ", result3);输出如下:
Result: 20, 24, 28, 32, 36, 40, 44, 48, 52, 56这里的 values 代表的是一个无限 range,随后它又被过滤和变换。之所以还能安全处理无限 range,正是因为这些操作都是惰性求值的:只有在 printRange() 真正遍历视图时才会发生。这也意味着,在这个例子里,你不能直接对 values、result1 或 result2 调用 printRange(),因为那会导致 printRange() 进入无限循环——它们都是无限 range。
当然,你完全可以去掉这些中间视图,直接构造一个单一的大管线。下面的代码会得到和刚才完全一样的输出:
auto result { views::iota(10) | views::filter([](const auto& value) { return value % 2 == 0; }) | views::transform([](const auto& value) { return value * 2.0; }) | views::take(10) };printRange("Result: ", result);另一个范围工厂的示例展示了如何使用 repeat_view:
printRange("Repeating view: ", views::repeat(42, 5));它会输出:
Repeating view: 42, 42, 42, 42, 42把输入流当作视图
Section titled “把输入流当作视图”basic_istream_view / istream_view 这个范围工厂,可以用来在输入流(例如标准输入)之上构造一个视图。元素通过 operator>> 读取。
例如,下面这段代码会持续从标准输入读取整数。对于每一个小于 5 的输入值,它会把该值乘以 2 并输出到标准输出;一旦你输入 5 或更大的整数,循环就会结束。
println("Type integers, an integer>= 5 stops the program.");for (auto value : ranges::istream_view<int> { cin } | views::take_while([](const auto& v) { return v < 5; }) | views::transform([](const auto& v) { return v * 2; })) { println("> {}", value);}println("Terminating…");可能的输出如下:
Type integers, an integer>= 5 stops the program.1 2> 2> 43> 64> 85Terminating…
Section titled “ 把范围转成容器”在 C++23 之前,把一个 range 转换成容器并不容易。C++23 引入了 std::ranges::to(),让这种转换变得非常直接。由于视图本身也是 range,因此它同样可以把视图中的元素转成容器。更进一步,因为容器本身也是 range,所以你甚至可以用 ranges::to() 把一个容器转换成另一个容器,哪怕两者的元素类型也不相同。
下面这段代码展示了 ranges::to() 的几种用法。例子里还展示了 set 与 string 的特殊构造函数:它们可以把 std::from_range 标签作为第一个参数,并直接从给定 range 构造出 set 或 string。现在所有标准库容器都已经支持这样的构造函数。
// Convert a vector to a set with the same element type.vector vec { 33, 11, 22 };auto s1 { ranges::to<set>(vec) };println("{:n}", s1);
// Convert a vector of integers to a set of doubles, using the pipe operator.auto s2 { vec | ranges::to<set<double>>() };println("{:n}", s2);
// Convert a vector of integers to a set of doubles, using from_range constructor.set<double> s3 { from_range, vec };println("{:n}", s3);
// Lazily generate the integers from 10 to 14, divide these by 2,// and store the result in a vector of doubles.auto vec2 { views::iota(10, 15) | views::transform([](const auto& v) { return v / 2.0; }) | ranges::to<vector<double>>() };println("{:n}", vec2);
// Use views::split() and views::transform() to create a view// containing individual words of a string, and then convert// the resulting view to a vector of strings containing all the words.string lorem { "Lorem ipsum dolor sit amet" };auto words { lorem | views::split(' ') | views::transform([](const auto& v) { return string { from_range, v }; }) | ranges::to<vector>() };println("{:n:?}", words);输出如下:
11, 22, 3311, 22, 3311, 22, 335, 5.5, 6, 6.5, 7"Lorem", "ipsum", "dolor", "sit", "amet"C++23 还为标准库容器引入了一批新的成员函数,以加强容器与 range 之间的互操作性。这些成员函数命名模式为 xyz_range(…),其中 xyz 可能是 insert、append、prepend、assign、replace、push、push_front 或 push_back。第 18 章会详细讨论各类标准库容器,但如果你想知道到底哪些容器支持哪些成员函数,还是应当查阅标准库参考资料。下面这个例子演示了 vector 的 append_range() 与 insert_range():
vector<int> vec3;vec3.append_range(views::iota(10, 15));println("{:n}", vec3);vec3.insert_range(begin(vec3), views::iota(10, 15) | views::reverse);println("{:n}", vec3);输出如下:
10, 11, 12, 13, 1414, 13, 12, 11, 10, 10, 11, 12, 13, 14本章解释了 iterator 背后的思想:它是一种抽象,使你无需了解容器的具体内部结构,也能在容器元素之间导航。你已经看到,输出流迭代器可以把标准输出当作基于 iterator 的算法的目标,而输入流迭代器则能把标准输入作为算法的数据来源。本章还介绍了插入迭代器、反向迭代器和移动迭代器这些适配器,它们能够对其他 iterator 进行适配。
本章最后讨论了 Ranges 库——它是 C++ 标准库的一部分。借助它,你可以以更偏函数式的方式编写代码:你描述“想做什么”,而不是“每一步怎么做”。你可以构造由多个操作组成的管线,按顺序作用于某个 range 的元素。而这些管线都是惰性执行的;也就是说,只有当你真正开始遍历结果视图时,它们才会做实际工作。
通过完成下面这些练习,你可以巩固本章讨论过的内容。所有习题解答都包含在本书网站 www.wiley.com/go/proc++6e 提供的代码下载包中。不过,如果你在某个练习上卡住了,建议先回头重读本章相关部分,尽量先自己找到答案,再去查看网站上的解答。
- 练习 17-1: 编写一个程序,惰性构造元素序列 10-100,对每个数字求平方,移除所有能被 5 整除的数,再把剩余值通过
std::to_string()转换成字符串。 - 练习 17-2: 编写一个程序,创建一个
vector,其中每个元素都是一个pair;pair里包含本章前面介绍的Person类实例,以及该人的年龄。然后使用 Ranges 库构造一个单一管线,从这个vector的全部pair中提取年龄,移除所有小于 12 和大于 65 的年龄。最后,使用本章前面介绍过的sum()算法,计算剩余年龄的平均值。由于你要把一个 range 传给sum(),因此你需要处理公共区间(common range)。 - 练习 17-3: 在练习 17-2 解法的基础上,为
Person类补充operator<<的实现。
接着,构造一个管线:从 vector<pair<…>> 中提取每个 pair 里的 Person,并只保留前四个 Person。使用本章介绍过的 myCopy() 算法,把这四个人的名字输出到标准输出,每行一个。
最后,再构造一个类似管线,但这次还要把筛选后的 Person 投影为其姓氏。然后只用一条 println() 语句,把这些姓氏输出到标准输出。
4. 练习 17-4: 编写一个程序,结合 range-based for 循环和 ranges::istream_view(),从标准输入读取整数,直到输入 -1 为止。把读取到的整数存入 vector,随后再把 vector 内容输出到控制台,以确认它保存了正确的值。
5. 附加练习: 你能否把练习 17-4 的解法改成完全不显式使用循环?提示:一种办法是使用 std::ranges::copy() 算法,把某个 range 从源复制到目标。它的第一个参数可以是一个 range,第二个参数则是一个 output iterator。
Footnotes
Section titled “Footnotes”-
C++23 对 view 的定义做了轻微调整:它允许某个视图拥有自己的元素,但前提是它必须保证自己要么不可复制,要么可以在常数时间
O(1)内完成复制。绝大多数视图仍然是非拥有的,因此本书不再专门讨论拥有型视图。 ↩