随机数设施
本章介绍如何在 C++ 中生成随机数。在软件里生成“质量足够好”的随机数,本身是一个相当复杂的话题。本章不会深入讨论那些用于生成随机数的复杂数学公式;不过,它会说明如何利用标准库提供的能力来生成随机数。
C++ 的随机数库支持使用不同的算法和分布来生成随机数。它定义在 std 命名空间下的 <random> 中,整体上由三大部分组成:引擎(engine)、引擎适配器(engine adapter)和分布(distribution)。随机数引擎负责真正产出随机数,并维护继续生成后续随机数所需的状态;分布决定生成结果落在哪个范围内,以及这些结果在该范围内按照怎样的数学规律分布;随机数引擎适配器则会修改它所关联的随机数引擎产生的结果。
在深入讲解这套 C++ 随机数库之前,我们先快速回顾一下旧式 C 风格随机数生成方式,以及它存在的问题。
C 风格随机数生成
Section titled “C 风格随机数生成”在 C++11 之前,生成随机数通常依赖 C 风格的 srand() 和 rand()。srand() 需要在程序中调用一次,用于初始化随机数生成器,这个过程也叫设种(seeding)。通常,人们会把当前系统时间作为种子。
软件随机数生成器的种子一定要足够“好”。如果你每次都用同一个种子初始化随机数生成器,那么每次得到的都会是同一串随机数序列。这也是为什么人们通常会拿当前系统时间来当种子。
生成器初始化完成后,就可以通过 rand() 取出随机数。下面的例子展示了 srand() 和 rand() 的基本用法。定义在 <ctime> 中的 time() 会返回系统时间,通常表示为自系统纪元(epoch)以来经过的秒数;纪元可以理解为系统定义的“时间起点”。
srand(static_cast<unsigned int>(time(nullptr)));println("{}", rand());如果你想生成落在某个区间内的随机数,可以写出下面这样的函数:
int getRandom(int min, int max){ return static_cast<int>(rand() % (max + 1UL - min)) + min;}旧式 C 风格的 rand() 生成的随机数范围是 0 到 RAND_MAX,而标准只要求 RAND_MAX 至少为 32767。也就是说,你根本无法用它生成大于 RAND_MAX 的随机数。在某些系统上,例如 GCC,RAND_MAX 等于 2147483647,也就是有符号 int 的最大值。为了避免在这种平台上发生算术溢出,getRandom() 里的公式刻意使用了 unsigned long 计算,也就是写成 1UL 而不是单纯的 1。
此外,rand() 的低位通常并不够随机。这意味着,如果你用前面这个 getRandom() 在很小的范围里取值,例如 1 到 6,那么生成出来的结果随机性并不理想。
除了随机质量不高,旧式 srand() / rand() 在灵活性上也很有限。比如,你没法改变生成结果的分布形式。总之,强烈建议尽快停止使用 srand() 和 rand(),改用接下来要介绍的 <random> 标准库设施。
现代 C++ 随机数库的第一部分是随机数引擎,它负责真正生成随机数。正如前面提到的,相关定义都在 <random> 中。
可用的随机数引擎包括:
random_devicelinear_congruential_enginemersenne_twister_enginesubtract_with_carry_engine
random_device 不是软件伪随机生成器。它是一种特殊引擎,需要计算机具备某种硬件随机源,才能生成真正的、非确定性的随机数,例如借助某些物理现象。一种经典做法,是通过统计放射性同位素衰变时单位时间内出现的粒子数量来生成随机性;当然,也有很多其他基于物理噪声的方案,例如测量反向偏置二极管中的噪声(这样就不用担心电脑里放着放射源了)。这些底层细节不在本书讨论范围之内。如果计算机上没有这样的硬件设备,那么 random_device 也可以退而求其次,改用某种软件算法;具体使用哪种算法,取决于标准库实现者。幸运的是,大多数现代计算机对真正的 random_device 都已经有了相当不错的支持。
随机数生成器的质量通常用熵(entropy)衡量。random_device 的成员函数 entropy() 会在它退化为软件伪随机实现时返回 0.0;如果它使用的是硬件设备,则会返回非零值。这个非零值表示对硬件熵水平的一个估计。
random_device 的用法很直接:
random_device rnd;println("Entropy: {}", rnd.entropy());println("Min value: {}, Max value: {}", rnd.min(), rnd.max());println("Random number: {}", rnd());这个程序的一种可能输出如下:
Entropy: 32Min value: 0, Max value: 4294967295Random number: 3590924439不过,random_device 通常比伪随机数引擎慢得多。因此,如果你需要批量生成随机数,更常见的做法是:用 random_device 生成一个种子,再用这个种子去初始化伪随机数引擎。本章后面的“生成随机数”一节会演示这种方式。
除了 random_device 之外,还有三类伪随机数引擎:
- 线性同余引擎(linear congruential engine): 状态占用内存极少。它的状态就是一个整数,保存上一次生成的随机数;如果还没生成过随机数,那就保存初始种子。它的周期取决于算法参数,最多可达
2^64,但通常更短。因此,如果你需要高质量随机数,不建议使用线性同余引擎。 - Mersenne Twister 引擎(Mersenne twister): 在这三类伪随机数引擎里,它通常能生成质量最高的随机数。它的周期是一个梅森素数,也就是比某个 2 的幂小 1 的素数,因此通常远大于线性同余引擎。它保存状态所需的内存也更多。例如,预定义的
mt19937周期为2^19937 - 1,内部状态包含 625 个整数,约 2.5 KB。不过它也是最快的引擎之一。 - 带进位减法引擎(subtract with carry engine): 需要大约 100 字节的状态;但它生成的随机数质量不如 Mersenne Twister,同时速度也更慢。
这些引擎的数学原理,以及“随机质量”如何度量,都超出了本书范围。如果你对这些话题感兴趣,可以查阅附录 B“带注释的参考书目”中“随机数”部分的参考资料。
random_device 使用起来很简单,不需要任何参数。但如果你要手动实例化三类伪随机数引擎中的某一种,就必须提供若干数学参数,这往往会让人望而却步。更重要的是,这些参数的选择会直接影响随机数质量。比如,mersenne_twister_engine 这个类模板的定义就长这样:
template<class UIntType, size_t w, size_t n, size_t m, size_t r, UIntType a, size_t u, UIntType d, size_t s, UIntType b, size_t t, UIntType c, size_t l, UIntType f> class mersenne_twister_engine {…}它足足需要 14 个参数。linear_congruential_engine 和 subtract_with_carry_engine 这两个类模板同样也需要多项类似的数学参数。正因为如此,标准库预先定义了一些现成可用的引擎类型。其中一个典型例子,就是 mt19937 这个 Mersenne Twister 引擎:
using mt19937 = mersenne_twister_engine<uint_fast32_t, 32, 624, 397, 31, 0x9908b0df, 11, 0xffffffff, 7, 0x9d2c5680, 15, 0xefc60000, 18, 1812433253>;如果你不了解 Mersenne Twister 算法的数学细节,那么这些参数看起来几乎全是魔法数字。一般来说,除非你本身就是伪随机数生成器领域的专家,否则不要随意改它们。更实际的做法,是直接使用标准库提供好的类型别名,例如 mt19937。本章后面会给出一张完整的预定义引擎列表。
随机数引擎适配器
Section titled “随机数引擎适配器”随机数引擎适配器会修改它所关联的随机数引擎输出结果;被关联的那个引擎称为基础引擎(base engine)。这其实就是适配器模式的一个例子(参见第 33 章“应用设计模式”)。标准库定义了下面三种适配器模板:
template<class Engine, size_t p, size_t r> class discard_block_engine {…}template<class Engine, size_t w, class UIntT> class independent_bits_engine {…}template<class Engine, size_t k> class shuffle_order_engine {…}discard_block_engine 会丢弃基础引擎生成的一部分值,从而得到新的随机序列。它需要三个参数:要适配的引擎、块大小 p 和保留块大小 r。基础引擎先生成 p 个随机数,适配器再丢弃其中的 p - r 个,只返回剩下的 r 个。
independent_bits_engine 会把基础引擎产生的多个随机数拼接组合起来,从而生成位宽为 w 的随机数。
shuffle_order_engine 生成的数字本质上仍来自基础引擎,但它会以不同的顺序把这些数字“重新洗牌”后再输出。模板参数 k 表示适配器内部使用的缓冲表大小。每次请求随机数时,它会先从这张表中随机取一个值返回,然后再用基础引擎生成的新值补回去。
和随机数引擎一样,标准库也提供了一些预定义的引擎适配器。下一节会统一概览这些预定义引擎与适配器。
预定义引擎与引擎适配器
Section titled “预定义引擎与引擎适配器”前面已经提到过,一般不建议你自己去指定伪随机数引擎和引擎适配器的模板参数,而是直接使用标准库预定义好的版本。C++ 标准库在 <random> 中定义了下列预定义生成器。它们背后当然仍然对应复杂的模板参数,但在使用这些类型时,你并不需要理解那些参数本身。
| 预定义生成器 | 类模板 |
|---|---|
minstd_rand0 | linear_congruential_engine |
minstd_rand | linear_congruential_engine |
mt19937 | mersenne_twister_engine |
mt19937_64 | mersenne_twister_engine |
ranlux24_base | subtract_with_carry_engine |
ranlux48_base | subtract_with_carry_engine |
ranlux24 | discard_block_engine |
ranlux48 | discard_block_engine |
knuth_b | shuffle_order_engine |
default_random_engine | 由实现决定 |
default_random_engine 的具体实现取决于编译器和标准库实现。
接下来,我们就通过实际示例看看这些预定义引擎该怎么使用。
在真正生成随机数之前,你首先要创建一个引擎对象。如果你使用的是软件伪随机引擎,还需要再定义一个分布。所谓分布,本质上是描述随机数如何在某个范围内分布的数学规则。创建引擎时,最推荐的方式仍然是直接选用前一节提到的某个预定义引擎。
下面这个例子使用的是预定义引擎 mt19937,也就是 Mersenne Twister 引擎。这是一种软件伪随机生成器。和旧式 rand() 一样,它也需要一个种子来初始化。过去 srand() 的种子通常来自当前时间;而在现代 C++ 中,更推荐用 random_device 来生成这个种子:
random_device seeder;mt19937 engine { seeder() };正如前面所说,大多数现代系统中的 random_device 都有足够好的熵来源。但如果你并不确定代码运行的平台是否真的提供了高质量熵,那么也可以准备一个基于时间的后备种子:
random_device seeder;const auto seed { seeder.entropy() ? seeder() : time(nullptr) };mt19937 engine { static_cast<mt19937::result_type>(seed) };接下来需要定义一个分布。下面这个例子使用的是 1 到 99 范围内的均匀整数分布。分布的细节会在下一节系统讲解,不过这个均匀分布已经足够用来演示:
uniform_int_distribution<int> distribution { 1, 99 };一旦引擎和分布都准备好,就可以通过调用分布对象的函数调用运算符,并把引擎作为参数传进去,来生成随机数。这里写作 distribution(engine):
println("{}", distribution(engine));你可以看到,使用软件伪随机引擎生成随机数时,总是需要同时指定“引擎”和“分布”。std::bind()(已在第 19 章“函数指针、函数对象与 Lambda 表达式”中介绍过)可以把“每次都要手写引擎和分布”这件事简化掉。下面的例子仍然使用和前面一样的 mt19937 引擎与均匀分布,但通过 std::bind() 把 engine 绑定为 distribution() 的第一个参数,从而定义出 generator。这样你只要直接调用 generator(),就能拿到一个随机数。这个例子还顺带演示了如何把 generator() 与受约束的 ranges::generate() 算法组合起来,用随机数填充一个包含十个元素的 vector。generate() 已在第 20 章“掌握标准库算法”中讨论过。
auto generator { bind(distribution, engine) };
vector<int> values(10);ranges::generate(values, generator);
println("{:n}", values);即便你并不知道 generator 的确切类型,仍然可以把它传给其他需要使用该生成器的函数。做法主要有两种:要么把参数写成 std::function<int()>,要么使用函数模板。前面的示例可以改写成一个名为 fillVector() 的函数,用它专门负责生成随机数并填充向量。下面是 std::function 版本:
void fillVector(vector<int>& values, const function<int()>& generator){ ranges::generate(values, generator);}也可以写成带约束的函数模板版本:
template <invocable T>void fillVector(vector<int>& values, const T& generator){ ranges::generate(values, generator);}进一步还可以使用缩写函数模板语法,写得更简洁:
void fillVector(vector<int>& values, const auto& generator){ ranges::generate(values, generator);}最后,这个函数就可以像下面这样使用:
vector<int> values(10);fillVector(values, generator);随机数生成器不是线程安全的。如果你需要在多个线程中生成随机数,应当在每个线程中各自创建生成器,而不要在线程之间共享同一个生成器。第 27 章“C++ 多线程编程”会介绍多线程相关内容。
分布是描述随机数如何在某个范围内分布的数学公式。标准库中的随机数工具提供了多种分布,可与伪随机数引擎搭配使用,以决定生成结果的分布方式。下面采用的是一种压缩列举形式:每种分布先给出名称和类模板参数(如果有),再给出一个构造函数原型,只是为了让你对该类有个整体印象。至于每种分布全部构造函数与成员函数的完整列表,请查阅标准库参考资料(见附录 B)。
以下是可用的均匀分布:
template<class IntType = int> class uniform_int_distribution uniform_int_distribution(IntType a = 0, IntType b = numeric_limits<IntType>::max());template<class RealType = double> class uniform_real_distribution uniform_real_distribution(RealType a = 0.0, RealType b = 1.0);以下是可用的伯努利类分布(第一种生成随机布尔值;后三种则按照离散概率分布生成随机非负整数值):
class bernoulli_distribution bernoulli_distribution(double p = 0.5);template<class IntType = int> class binomial_distribution binomial_distribution(IntType t = 1, double p = 0.5);template<class IntType = int> class geometric_distribution geometric_distribution(double p = 0.5);template<class IntType = int> class negative_binomial_distribution negative_binomial_distribution(IntType k = 1, double p = 0.5);以下是可用的泊松类分布(按离散概率分布生成随机非负整数,或与之相关的连续分布):
template<class IntType = int> class poisson_distribution poisson_distribution(double mean = 1.0);template<class RealType = double> class exponential_distribution exponential_distribution(RealType lambda = 1.0);template<class RealType = double> class gamma_distribution gamma_distribution(RealType alpha = 1.0, RealType beta = 1.0);template<class RealType = double> class weibull_distribution weibull_distribution(RealType a = 1.0, RealType b = 1.0);template<class RealType = double> class extreme_value_distribution extreme_value_distribution(RealType a = 0.0, RealType b = 1.0);以下是可用的正态类分布:
template<class RealType = double> class normal_distribution normal_distribution(RealType mean = 0.0, RealType stddev = 1.0);template<class RealType = double> class lognormal_distribution lognormal_distribution(RealType m = 0.0, RealType s = 1.0);template<class RealType = double> class chi_squared_distribution chi_squared_distribution(RealType n = 1);template<class RealType = double> class cauchy_distribution cauchy_distribution(RealType a = 0.0, RealType b = 1.0);template<class RealType = double> class fisher_f_distribution fisher_f_distribution(RealType m = 1, RealType n = 1);template<class RealType = double> class student_t_distribution student_t_distribution(RealType n = 1);以下是可用的采样分布:
template<class IntType = int> class discrete_distribution discrete_distribution(initializer_list<double> wl);template<class RealType = double> class piecewise_constant_distribution template<class UnaryOperation> piecewise_constant_distribution(initializer_list<RealType> bl, UnaryOperation fw);template<class RealType = double> class piecewise_linear_distribution template<class UnaryOperation> piecewise_linear_distribution(initializer_list<RealType> bl, UnaryOperation fw);每一种分布都需要一组参数。和前面一样,这些数学参数的详细含义不在本书的讨论范围内。本节剩下的内容会通过几个例子,让你直观感受“分布”究竟会如何影响最终生成的随机数。
理解分布最直接的方式,就是看图形。下面这段代码会生成一百万个 1 到 99 之间的随机数,并统计每个数字出现了多少次,把结果记录到直方图中。计数器被存放在一个 map 里:键是 1 到 99 之间的数字,值则是这个数字被随机选中的次数。循环结束后,程序会把结果写入一个以分号分隔的 CSV 文件,方便用电子表格软件打开。
const unsigned int Start { 1 };const unsigned int End { 99 };const unsigned int Iterations { 1'000'000 };
// 均匀分布的 Mersenne Twister。random_device seeder;mt19937 engine { seeder() };uniform_int_distribution<int> distribution { Start, End };auto generator { bind(distribution, engine) };map<int, int> histogram;for (unsigned int i { 0 }; i < Iterations; ++i) { int randomNumber { generator() }; // 在 map 中搜索键为 randomNumber 的项。如果找到,将该键关联的值加 1。 // 如果没找到,则将该键加入 map,并设置其值为 1。 ++(histogram[randomNumber]);}
// 写入 CSV 文件。ofstream of { "res.csv" };for (unsigned int i { Start }; i <= End; ++i) { of << i << ";" << histogram[i] << endl;}接下来,就可以用这些数据生成图形。图 23.1 展示了所得直方图。
横轴表示随机数生成区间。可以很清楚地看到,在 1 到 99 这个范围内,每个数字大约都被随机选中了 10000 次,说明生成结果在整个区间上呈现出非常均匀的分布。
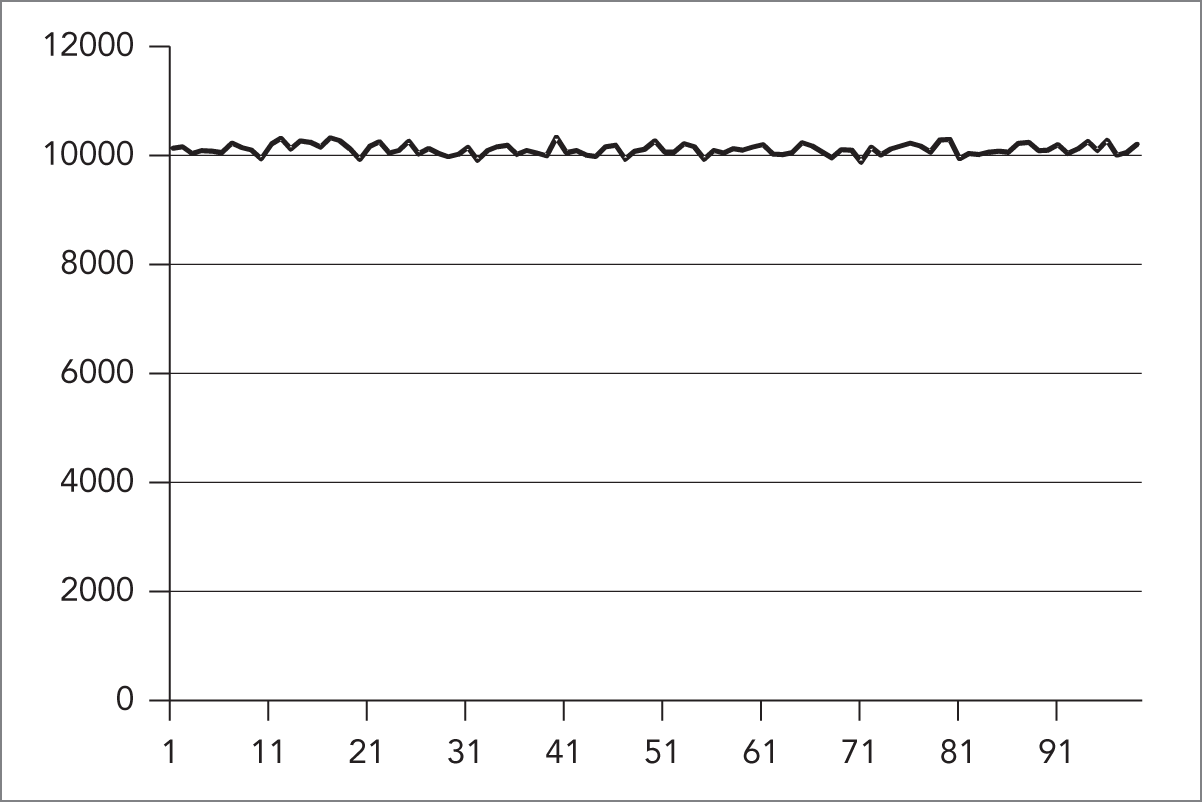
[^FIGURE 23.1]
这个示例也可以改成生成服从正态分布的随机数,而不是均匀分布。只需要做两处小修改。首先,把分布对象改成下面这样:
normal_distribution<double> distribution { 50, 10 };由于正态分布生成的是 double 而不是整数,因此对 generator() 的调用也要稍作调整:
int randomNumber { static_cast<int>(generator()) };图 23.2 展示了在这种正态分布下生成随机数所得到的图形。
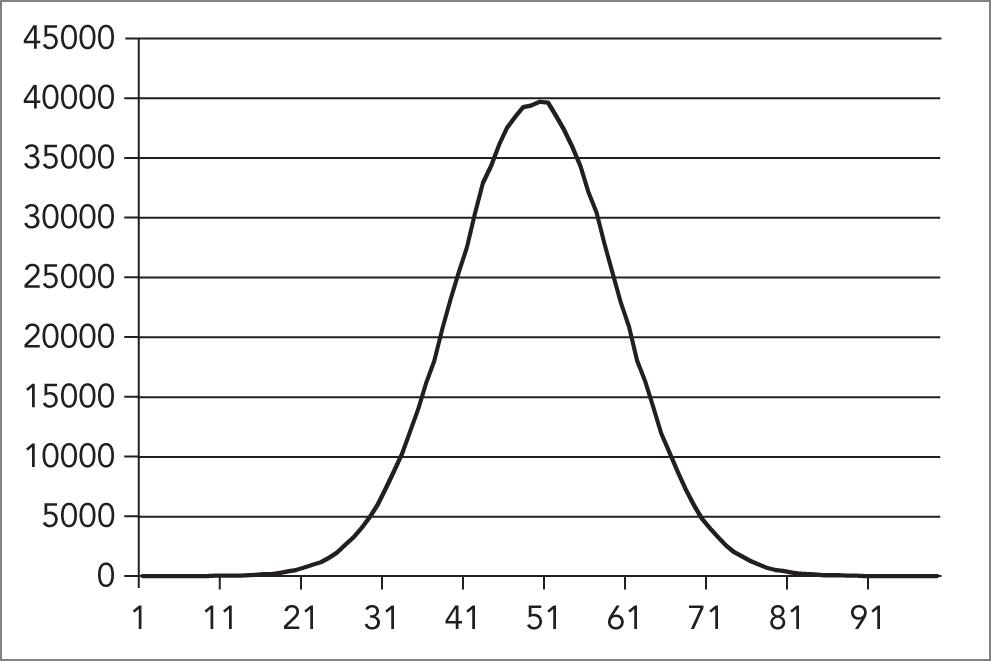
[^FIGURE 23.2]
从图中可以清楚看出,大多数随机数都会集中在区间中央附近。在这个例子里,数值 50 大约会被随机选中 40000 次,而像 20 和 80 这样的数值则只会出现大约 500 次。
本章介绍了如何使用 C++ 标准库提供的随机数生成设施来生成质量较好的随机数,也介绍了如何改变给定区间内随机数的分布方式。
下一章将进入本书第 3 部分的最后一章,介绍几种在日常编码中经常会用到的其他常用词汇类型(vocabulary types)。
通过完成下面这些练习,你可以巩固本章讨论的内容。所有练习的参考解答都包含在本书网站 www.wiley.com/go/proc++6e 提供的代码下载包中。不过,如果你在某道题上卡住了,建议先回过头重读本章相关部分,尽量自己找到答案,再去看网站上的解答。
-
练习 23-1: 写一个循环,询问用户是否要掷骰子。如果回答是,就使用均匀分布掷两次骰子,并把结果输出到屏幕上;如果回答否,就结束程序。请使用标准的
mt19937Mersenne Twister 引擎。不要在真正需要随机数的函数里直接创建生成器对象,而是编写一个createDiceValueGenerator()函数,由它创建正确的随机数生成器并返回。 -
练习 23-2: 在练习 23-1 的基础上,把引擎从 Mersenne Twister 改成
ranlux48。 -
练习 23-3: 继续修改练习 23-1。不要直接使用
mt19937Mersenne Twister 引擎,而是通过shuffle_order_engine适配器来包装该引擎。 -
练习 23-4: 使用本章前面用于生成直方图、绘制分布图的示例代码,尝试不同分布做一些实验。把结果导入电子表格软件中绘图,观察分布带来的差异。相关代码可在下载源码包的
Ch23\01_Random目录中找到。根据你的分布使用的是整数还是双精度数,可以选择07_uniform_int_distribution.cpp或08_normal_distribution.cpp。附加题: 除了把数据导出到 CSV 文件之外,再尝试用字符直接在标准输出上画出直方图。