精通测试
当一个程序员真正意识到“测试本身就是软件开发流程的一部分”时,她在职业生涯中就跨过了一道重要门槛。bug 从来不是偶尔才会出现的意外,它们存在于每一个规模稍微像样的项目中。优秀的质量保证(quality assurance,QA)团队极其宝贵,但测试这件事绝不能全部甩给 QA。作为程序员,你的责任不仅是写出能工作的代码,也要写出测试来证明它是正确的。
人们通常会区分白盒测试(white-box testing)和黑盒测试(black-box testing)。在白盒测试中,测试者了解程序内部实现;而黑盒测试则完全不依赖实现细节,只测试程序功能本身。这两类测试,对专业级项目来说都非常重要。黑盒测试是最基础的方式,因为它往往更贴近真实用户的行为模型。例如,一个黑盒测试可以去检查界面上的按钮:如果测试者点击按钮却什么都没发生,那程序显然就有 bug。
但黑盒测试不可能覆盖一切。现代程序太大了,你不可能靠“模拟点击每一个按钮、输入每一种数据、枚举所有命令组合”来真正穷尽测试。白盒测试因而是必要的:一旦你理解代码——也就是测试是围绕某个具体对象或子系统来写的——你就更容易确保代码中的所有路径都被测试覆盖到。这有助于提高测试覆盖率。相比黑盒测试,白盒测试往往更容易编写,也更容易自动化。本章重点讨论的,就是那些通常会被视为白盒测试技术的主题,因为程序员完全可以在开发过程中直接使用它们。
本章首先从较高层面讨论质量控制,包括观察和跟踪 bug 的一些方式。随后会介绍单元测试——这是最简单、也最实用的一类测试之一。接着,你会看到单元测试的理论与实践,以及几组单元测试实战示例,同时还会了解模糊测试是什么。再之后,本章会覆盖更高层级的测试,包括集成测试、系统测试和回归测试。最后,本章会以一组“如何把测试做成功”的建议收尾。
大型编程项目,几乎从来不会在“feature 已齐全”那一刻真正结束。无论在主开发阶段中,还是在之后,都会持续有 bug 被发现并需要修复。想在团队中把事情做好,你就必须理解质量控制的责任是如何分担的,以及一个 bug 从出现到关闭要经历怎样的生命周期。
测试由谁负责?
Section titled “测试由谁负责?”不同的软件开发组织,对 testing 的责任分配方式并不相同。在小型 startup 中,可能根本没有一个专门全职负责测试产品的团队。测试也许完全由各个开发者自己负责,或者公司里的所有员工都会被动员起来,在产品发布前尽可能“把它搞坏”。而在较大的组织中,通常会有全职 QA 团队,按照一套标准去验证某个 release 是否达标。即便如此,测试中的某些部分仍然可能由开发者负责。哪怕你的组织里,开发者几乎不参与正式测试流程,你也仍然必须清楚:在整个质量控制大流程中,自己到底承担哪些责任。
Bug 的生命周期
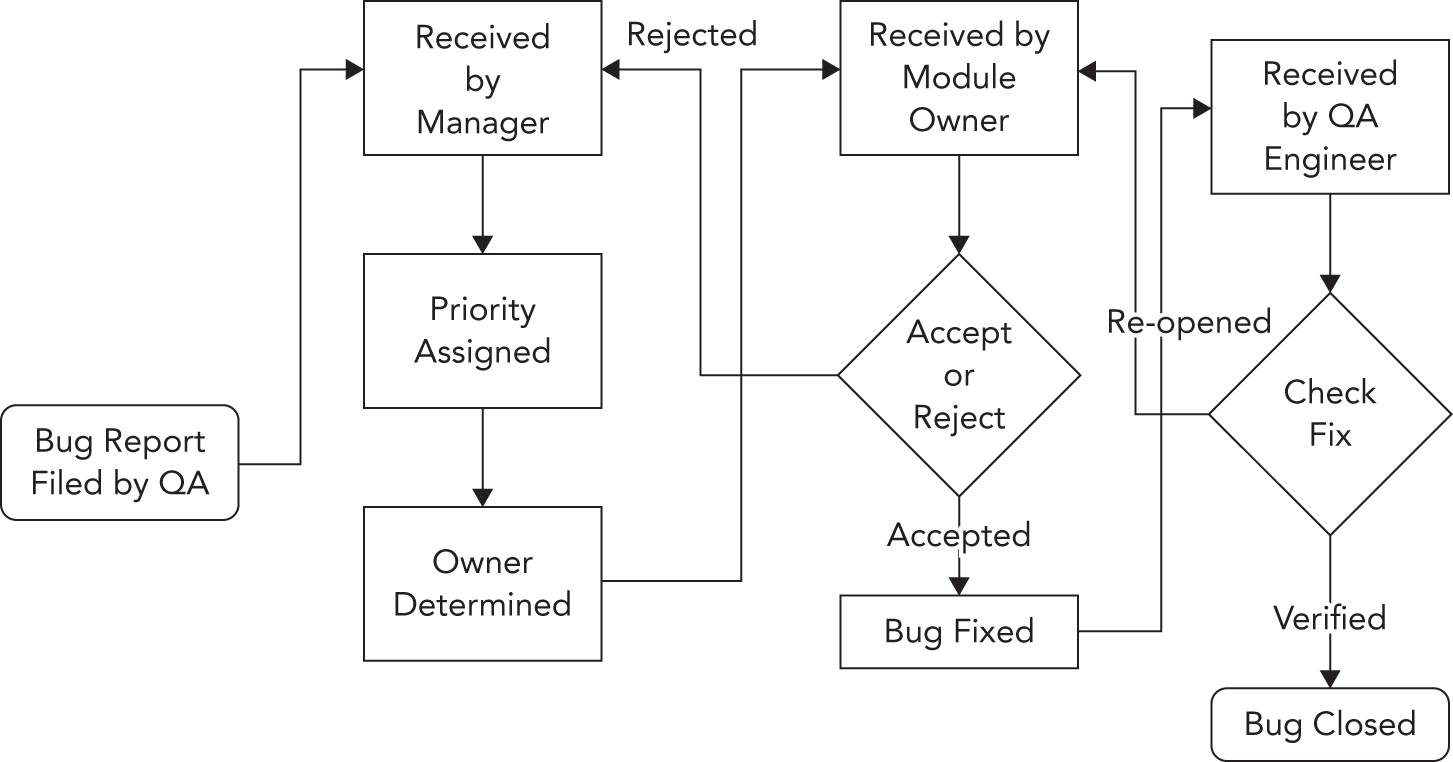
Section titled “Bug 的生命周期”任何靠谱的工程团队都知道,软件在发布前后都会出现 bug。处理这些问题的方式有很多。图 30.1 展示了一种比较正式的 bug 处理流程,以 flow chart 形式表达。在这个具体流程中,bug 总是由 QA 团队成员提出。bug reporting software 会把通知发送给开发经理,由他设置 bug 的优先级,并把 bug 指派给对应 module 的 owner。module owner 可以接受这个 bug,也可以解释为什么它其实属于别的 module,或者根本无效,从而让开发经理把它重新分派出去。
一旦 bug 找到真正的 owner,修复工作就会开始;修复完成后,开发者把 bug 状态标记为 “fixed”。接着,由 QA 工程师验证 bug 是否真的已经消失;如果确实解决了,就把 bug 标记为 “closed”,否则就重新打开它。
[^FIGURE 30.1]
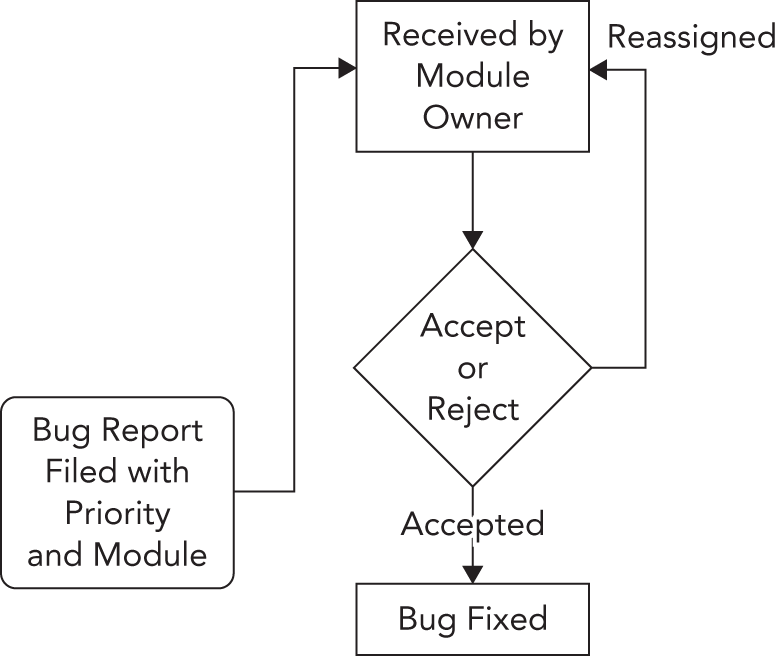
图 30.2 展示了另一种没那么正式的做法。在这个流程里,任何人都可以提交 bug,并给出初始优先级和所属 module。module owner 收到 bug 报告后,可以接受它,也可以把它重新分派给其他工程师或其他 module。一旦修复完成,bug 会被标记为 “fixed”。到测试阶段后期,所有开发者和 QA 工程师会共同分摊这些 fixed bug,逐一验证它们在当前 build 中是否已经真的不存在。当所有 bug 最终都被标记为 “closed” 时,这个 release 才算准备就绪。
[^FIGURE 30.2]
Bug 跟踪工具
Section titled “Bug 跟踪工具”跟踪软件 bug 的方法有很多种:从非正式的 spreadsheet / email 方案,到昂贵的第三方 bug-tracking software,都有人用。对你的组织来说,哪种方案合适,取决于团队规模、软件本身的性质,以及你希望 bug 修复流程有多正式。
同时,也有不少免费的 open-source bug-tracking solution 可选。其中比较流行的一款,是 Bugzilla(bugzilla.org),它出自 Mozilla 和 Firefox 浏览器的作者之手。作为 open-source 项目,Bugzilla 逐步积累了大量实用特性,如今在很多方面已经足以与昂贵的商业 bug-tracking 软件竞争。以下只是它功能中的一小部分:
- 可定制的 bug 属性,例如 priority、所属 component、status 等
- 对新 bug report 或已有 bug 变更的 email 通知
- bug 之间 dependency 的跟踪,以及 duplicate bug 的合并/处理
- reporting 和 searching 工具
- 一个基于 Web 的 bug 提交和更新界面
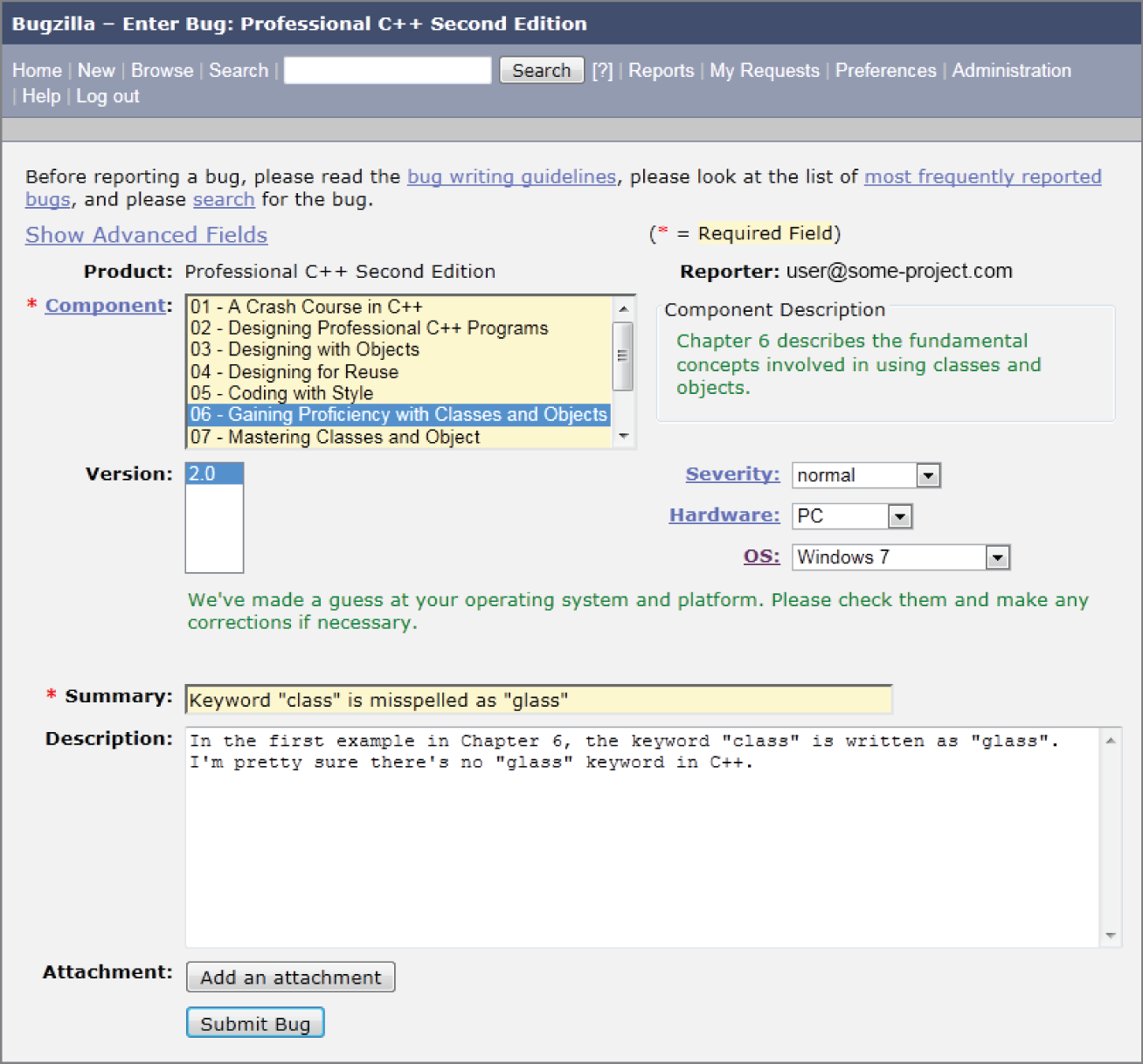
图 30.3 展示的是:有人正在往一个为本书第二版搭建的 Bugzilla 项目中录入 bug。对我自己而言,我把每一章都录成了 Bugzilla 里的一个 component。提交 bug 的人可以指定 bug 的 severity(也就是问题严重程度)。与此同时,还会包含 summary 和 description,便于之后按 bug 搜索,或以报表形式汇总出来。
[^FIGURE 30.3]
写 bug report 时,一定要尽量包含足够多的信息。例如,如果你的 bug report 讨论的是某个 error,请把完整的错误信息以文本形式写进报告里,而不只是贴一张截图。这样,当其他人遇到同样错误时,他们才能通过检索直接找到你这条 bug report。
像 Bugzilla 这样的 bug-tracking tool,是专业软件开发环境中的关键组件。除了能提供一份当前所有未关闭 bug 的中心清单之外,这类工具也构成了一个极其重要的历史档案,保存着过去 bug 及其修复方式。例如,support engineer 可能会在系统里搜索某个与客户反馈相似的问题;如果这个问题曾被修复过,那么 support 人员就能告诉客户:他们需要升级到哪个版本,或者当前有哪些 workaround。
发现 bug 的唯一办法,就是测试。而从开发者视角看,最重要的测试类型之一,就是 unit test。unit test 是一小段专门针对某个 class 或 subsystem 中特定功能的测试代码。它们是你能写出来的最细粒度测试。理想情况下,只要代码中存在某项底层功能,就应至少有一个或多个 unit test 覆盖它。举个例子:如果你正在编写一个能够执行加法和乘法的 math library,那么你的 unit test 套件里可能会有下面这些测试:
- 测试简单加法,例如 1+2
- 测试大整数加法
- 测试负数加法
- 测试一个数加 0
- 测试加法的交换律
- 测试简单乘法
- 测试大数乘法
- 测试负数乘法
- 测试乘以 0
- 测试乘法的交换律
写得好的 unit test 能从多个方面保护你:
- 它们证明某块功能确实能工作。在真正有代码开始使用你的 class 之前,它的行为本质上都还是未知数。
- 当某次新改动破坏了旧功能时,它们会第一时间报警。这种特定用途的测试,叫 regression test;本章后面会专门讨论。
- 当 unit test 被真正纳入开发流程时,它们会逼着开发者从一开始就修问题。如果你的代码在 unit test 失败时根本不允许 check in,那么你就只能立刻面对并修正问题。
- unit test 让你可以在“其他代码尚未就位”时,先试运行自己的代码。你刚开始学编程时,往往会把整个程序写完,再第一次运行它。但专业软件太大了,根本没法这样干,因此你必须能够把 component 单独隔离出来测试。
- 最后但同样重要的是,unit test 本身也提供了用法示例。几乎是副作用式地,unit test 还会自然地变成给其他程序员看的参考代码。如果某位同事想知道你的 math library 该怎么做矩阵乘法,你完全可以直接把对应测试扔给她看。
单元测试的方法
Section titled “单元测试的方法”对于 unit test 这件事,真正最容易出错的地方只有两个:要么你根本不写,要么你写得很差。总体上说,测试越多,覆盖越大;覆盖越大,bug 从缝里漏过去的概率就越低,你也越不需要将来对老板、或者更糟——对客户——说出那句令人窒息的话:“哦,我们从来没测过这个。”
有不少 methodology 专门讨论“如何更有效地写 unit test”。第 28 章“软件工程方法”里提到的 Extreme Programming,就要求追随者在写代码之前先写 unit test。
先写测试,有助于你更早固化 component 的 requirement,也能提供一个标准:何时 coding 才算真正完成。不过,先写测试本身并不轻松,它要求程序员在执行上足够自律。对某些程序员来说,这种方式 simply doesn’t mesh well with their coding style。更宽松的一种做法,是先设计测试,但把测试的实现推迟到编码之后。这样,程序员仍然会被迫认真理解 module 的 requirement,但又不必在 class 还根本不存在时,就硬写出调用它们的代码。
在一些团队里,某个 subsystem 的作者并不会亲自为自己写 unit test。背后的理由是:如果你测试的是自己写的代码,就有可能下意识绕开自己已知的问题,或者只覆盖那些你知道自己代码处理得比较好的情况。除此之外,很多人对“在自己刚写出来的代码里找 bug”天生缺乏热情,于是测试 effort 很容易变得敷衍。让一个开发者为另一个开发者的代码编写 unit test,当然会引入额外的沟通和协调成本;但一旦这套协作真正运转起来,它通常能保证更有效的测试。
Code coverage 是一种衡量“多少代码被 unit test 覆盖到了”的指标。它能帮助你在写 unit test 时尽量提高覆盖率。你可以使用像 gcov(gcc.gnu.org/onlinedocs/gcc/Gcov.html)这样的 code coverage tool,查看 unit test 到底覆盖了多少代码。其核心想法是:一段被充分测试的代码,理应拥有足够多的 unit test,把它可能经过的所有代码路径都走一遍,从而逼近 100% 的 unit-test coverage。不过,不同 coverage tool 对 coverage 的定义并不完全一样。比如:如果某一行是一个单行写成的 if,但其 body 从未执行过,它算不算“已覆盖”?template 的 coverage 怎么定义?它是否支持 branch coverage,从而保证每个分支方向都被覆盖?因此,对你想使用的任何 tool,都应事先做一些研究。
单元测试流程
Section titled “单元测试流程”为代码提供 unit test 这件事,其实在真正开始写代码之前就已经开始了。在 design 阶段就把“是否容易测试”纳入考虑,往往会直接影响你做出的 design 决策。即便你并不信奉“先写测试,再写代码”的 methodology,至少也应该在 design 阶段就开始思考:你准备提供哪些测试。这样做的好处是,你可以把整个任务拆成边界清晰的小块,而每一块都有自己可通过测试验证的标准。比如,如果你的任务是写一个数据库访问类,那么你可能会先实现“向数据库插入数据”的功能;等这部分通过了一整套 unit test,再继续写 update、delete 和 select 的支持代码,并在过程中边写边测。
下面这组步骤,是一种我比较推荐的设计和实现 unit test 的方式。当然,和所有 methodology 一样,最好的流程,永远是那个能为你带来最好结果的流程。我建议你在不同使用方式之间多做实验,找出最适合自己的 unit testing 节奏。
定义测试粒度
Section titled “定义测试粒度”写 unit test 确实需要时间——这一点没有任何捷径可走。软件开发者往往总是时间紧张。为了赶 deadline,开发者很容易跳过 unit test,心想这样反而能更快把功能做完。但这种想法忽略了全局成本。长远看,不写 unit test 往往一定会反噬你。bug 被越早发现,代价就越低。如果开发者在 unit testing 阶段就发现 bug,那么它可以被立即修掉,甚至来不及让其他人遇见它。但如果 bug 是 QA 才发现的,那么它的成本立刻就高出一大截:它会引发额外的开发循环,需要进入 bug 管理流程,被送回开发团队修正,再送回 QA 验证。如果 bug 最终穿过了 QA 流程,直接到了客户手里,那么成本只会更高。
测试的 granularity 指的是测试的作用范围。如下表所示,你完全可以一开始只用少量测试函数为某个数据库类做单元测试,然后再逐步补充更多测试,直到你确信它在各种场景下都能正确工作:
| 粗粒度测试 | 中粒度测试 | 细粒度测试 |
|---|---|---|
testConnection() testInsert() testUpdate() testDelete() testSelect() | testConnectionDropped() testInsertBadData() testInsertStrings() testInsertIntegers() testUpdateStrings() testUpdateIntegers() testDeleteNonexistentRow() testSelectComplicated() testSelectMalformed() | testConnectionThroughHTTP() testConnectionLocal() testConnectionErrorBadHost() testConnectionErrorServerBusy() testInsertWideCharacters() testInsertLargeData() testInsertMalformed() testUpdateWideCharacters() testUpdateLargeData() testUpdateMalformed() testDeleteWithoutPermissions() testDeleteThenUpdate() testSelectNested() testSelectWideCharacters() testSelectLargeData() |
你会发现,表中的每一列都比前一列更具体。随着你从粗粒度测试走向更细粒度的测试,你开始考虑错误条件、不同输入数据集、不同运行模式等等。
当然,最初为测试选择的粒度并不是一成不变的。也许这个数据库类眼下只是 proof of concept,甚至最后都未必会真的投入使用,那么眼下只写少量简单测试也许已经够了,将来完全可以再补。又或者,use case 在后续某个时间点发生变化。比如,数据库类最初可能根本没考虑过 international character;等这类 feature 被加入后,就应立刻再增加专门针对这些新能力的 targeted unit test。
把 unit test 视为 feature 真正实现的一部分。当你修改某个功能时,不要只是顺手把已有测试调整到“还能过”(当然,这一步你也该做)。你还应当为新的变化写新测试,并重新审视旧测试。当 bug 被找出并修复后,还应补上专门验证这次修复的 unit test,这类测试就是 regression test。
Unit test 本身就是被测试 subsystem 的一部分。随着 subsystem 被增强和演进,你也必须同步增强和演进这些测试。
梳理各项单独测试
Section titled “梳理各项单独测试”随着经验积累,你会逐渐形成一种直觉:哪些代码点理应被写成 unit test。某些函数、某些输入,光看一眼你就会觉得“这里就应该测”。这种直觉来自试错,也来自阅读团队其他人写的 unit test。通常,谁最擅长写 unit test,其实很容易看出来:他们的测试往往结构清晰,而且会被频繁维护更新。
在 unit test 的编写还没变成你的第二天性之前,想清楚“到底该写哪些测试”,最有效的办法之一仍然是认真 brainstorm。为了帮助你打开思路,可以问自己这些问题:
- 这段代码原本是为了完成哪些事情而写的?
- 每个函数典型的调用方式是什么?
- 调用者可能会违反哪些前置条件?
- 每个函数可能会怎样被误用?
- 你预期的输入数据是什么样?
- 你不预期的输入数据又有哪些?
- 哪些是边界情况或异常情况?
你不需要把这些问题一条条写成正式答案(除非你的 manager 特别信奉本书或某种 testing methodology),但它们足以帮助你生出许多 unit test 的思路。前面那个数据库类测试表中的每一个 test function,本质上都是从这类问题里长出来的。
当你已经为若干测试生成了想法之后,可以进一步思考如何把它们组织成几个类别;测试整体结构往往就会由此自然成形。比如,对数据库类而言,测试完全可以拆成以下几类:
- 基础测试
- 错误测试
- 本地化测试
- 非法输入测试
- 复杂场景测试
把测试拆成不同类别,有助于你辨认和扩展它们,也能让你更容易发现:代码的哪些方面已经测得比较充分,哪些方面还明显缺一批测试。
大量简单测试当然好写,但别忘了那些更复杂、更刁钻的情况!
准备示例数据与结果
Section titled “准备示例数据与结果”写 unit test 时,最常见的陷阱之一,是让测试去迎合代码的当前行为,而不是让测试去验证代码是否正确。比如,你写了一个 unit test,会对数据库做一次 select,查询一条“肯定存在”的数据;如果测试失败了,那么到底是代码有问题,还是测试本身有问题?很多时候,人会下意识觉得“代码大概没错”,于是顺手去改测试,让它重新匹配当前行为。但这种做法通常是错的。
为了避免掉进这个坑,你应当在真正运行测试之前,就先明确输入是什么、预期输出又是什么。说起来容易,做起来却未必简单。假设你写了一段代码,要使用某个特定 key 对一段任意文本进行加密。一个合理的 unit test,就是构造一段固定文本,把它交给加密模块处理,然后检查结果是否是“正确的加密结果”。
但真到了要写这个测试时,人很容易先用加密模块跑一下,看看输出长什么样;只要看起来差不多,就把那个输出写成“预期值”。可这样做其实并没有真正测试任何东西!你不过是写了一个测试,来确保代码将来继续产出“同样那个值”而已。很多时候,要想写出真正靠谱的测试,必须做一些额外工作:你需要在加密模块之外、独立地得到正确答案,才能用它来验证模块。如果你甚至并不知道底层加密算法细节——比如它来自第三方库——那么至少也应写出类似 decrypt(encrypt(x)) == x 和 encrypt(a) != encrypt(b) 这类性质测试。
在真正运行测试之前,就先决定好该测试的“正确输出”应该是什么。
测试代码究竟长什么样,取决于你使用的是哪种 test framework。本章稍后会讨论其中一种:Microsoft Visual C++ Testing Framework。不过,无论你实际采用什么框架,下面这些原则都有助于保证测试的有效性:
- 每个 test 只测试一件事。这样一旦失败,你就能直接定位到某个具体功能点。
- 在 test 内部写得尽量具体。失败到底是因为抛了 exception,还是因为返回值不对?
- 在测试代码中大量使用 logging。如果某天测试失败,你至少会留下一点线索,知道发生了什么。
- 避免测试之间彼此依赖,或者互相关联。test 应尽可能 atomic、隔离。
- 如果测试必须依赖其他 subsystem,可以考虑写 stub 或 mock 来模拟那些 subsystem。stub / mock 会实现与真实 subsystem 相同的 interface,从而可以替代任何具体实现。例如,如果某个 unit test 需要数据库,但数据库本身又不是它正在测试的 subsystem,那么就可以用 stub / mock 去实现数据库 interface,并模拟真实数据库行为。这样一来,跑这个 unit test 时就不需要真的连数据库,真实数据库实现里的 bug 也不会反过来污染这个测试。甚至更妙的是:你还可以用 mock 去模拟一些用真实数据库几乎无法稳定复现的错误情形。
- code review 不应只 review 代码本身,也应 review 对应的 unit test。当你做 code review 时,也应明确告诉对方:你觉得还可以在哪些地方继续补测试。
正如你稍后会看到的,unit test 通常都是很小、很简单的代码片段。在大多数情况下,写一个单独的 unit test 也许只需要几分钟,因此它几乎是你时间投入回报率最高的活动之一。
一旦写完某个 test,就应当立刻运行它,别等到好奇心把人折磨坏。看着满屏绿色通过的 unit test,带来的愉悦感不应被低估。对大多数程序员来说,这是最直观、也最令人满足的一种量化反馈:你的代码至少“有用”,并且——在你目前所知范围内——是正确的。
即使你采用的是“先写测试、后写代码”的做法,你也依然应在测试写完后立刻跑一次。这样,你才能先证明:这些测试最开始确实应该失败。等代码写完之后,你再获得一份可量化的证据,证明它已经完成了本该完成的事。
当然,你写的每一个 test 都第一次就得到预期结果的可能性其实很低。理论上,如果你是在代码之前先写测试,那么所有测试一开始本来就应该失败。如果某个测试反而通过了,那要么代码奇迹般地自己出现了,要么测试本身就写错了。如果代码已经完成而测试仍然失败(有些人会认为:只要测试失败,coding 从定义上就还没完成),那无非就两种可能:代码错了,或者测试错了。
运行 unit test 必须自动化。这可以通过多种方式实现。一种常见方式,是准备一台专门系统,在每次 continuous integration build 之后——或者至少每天夜里一次——自动执行全部 unit test。这样的系统还应自动给开发者发送邮件,通知他们哪些 unit test 出现失败。另一种做法,则是把本地开发环境配置成“每次编译代码时都自动跑 unit test”。若要采用这种方式,你的 unit test 就必须保持足够小、足够高效。至于那些确实运行时间较长的 unit test,最好单独拆出去,交给专门的 test system 运行。
单元测试实战
Section titled “单元测试实战”现在,你已经从理论层面读过 unit testing,接下来该真正写点测试了。下面这个例子,会基于第 29 章“编写高效 C++”里的 object pool 实现来展开。简单回顾一下:object pool 是一种 class,它可以避免程序反复分配大量 object。通过跟踪那些已经分配过的 object,这个 pool 就像一个 broker,把“需要某种 object 的代码”与“已经存在的那些 object”连接起来。
ObjectPool class template 的 public interface 如下;完整细节可参见第 29 章:
exporttemplate <typename T, typename Allocator = std::allocator<T>>class ObjectPool final{ public: ObjectPool() = default; explicit ObjectPool(const Allocator& allocator); ~ObjectPool();
// Prevent move construction and move assignment. ObjectPool(ObjectPool&&) = delete; ObjectPool& operator=(ObjectPool&&) = delete;
// Prevent copy construction and copy assignment. ObjectPool(const ObjectPool&) = delete; ObjectPool& operator=(const ObjectPool&) = delete;
// Reserves and returns an object from the pool. Arguments can be // provided which are perfectly forwarded to a constructor of T. template <typename... Args> std::shared_ptr<T> acquireObject(Args&&... args);};认识 Microsoft Visual C++ Testing Framework
Section titled “认识 Microsoft Visual C++ Testing Framework”Microsoft Visual C++ 自带了一套 testing framework。使用 unit testing framework 的好处在于:它能让开发者把注意力集中在“写测试”本身,而不必把大量精力浪费在“搭测试环境、围绕测试写胶水逻辑、收集结果”这些事情上。下面的讨论,基于 Visual C++ 2022。
要开始使用 Visual C++ Testing Framework,首先要新建一个测试项目。下面这些步骤说明了:如何为 ObjectPool class template 建立测试:
- 启动 Visual C++,新建项目,选择 Native Unit Test Project,然后点击 Next。
- 为项目命名,再点击 Create。
- 向导会自动创建一个新的 test project,其中包含一个名为
<ProjectName>.cpp的文件。在 Solution Explorer 中选中它并删除,因为我们会自己添加文件。如果你看不到 Solution Explorer,可以到 View ➪ Solution Explorer 打开。 - 在 Solution Explorer 中右键项目,选择 Properties。进入 Configuration Properties ➪ C/C++ ➪ Precompiled Headers,把 Precompiled Header 选项设为 Not Using Precompiled Headers,然后点击 OK。接着,再把
pch.cpp和pch.h两个文件从 Solution Explorer 中删掉。precompiled headers 是 Visual C++ 用来提升 build 时间的特性,但这个测试项目里不需要它。 - 往测试项目中添加两个空文件:
ObjectPoolTest.h和ObjectPoolTest.cpp。
现在你就可以开始往代码中加入 unit test 了。
最常见的组织方式,是把 unit test 按逻辑分组,形成若干 test class。接下来我们创建一个名为 ObjectPoolTest 的 test class。最开始所需的 ObjectPoolTest.h 内容如下:
#pragma once#include <CppUnitTest.h>
TEST_CLASS(ObjectPoolTest){ public:};这段代码定义了一个名为 ObjectPoolTest 的 test class,不过它的语法看起来和标准 C++ 稍有不同。这是为了让 framework 能自动发现所有测试。
如果你希望在某个 test class 的测试运行之前先做一些准备工作,或者在测试结束之后统一清理资源,那么可以实现 initialize 和 cleanup 成员函数。示例如下:
TEST_CLASS(ObjectPoolTest){ public: TEST_CLASS_INITIALIZE(setUp); TEST_CLASS_CLEANUP(tearDown);};由于这里对 ObjectPool 的测试比较简单、彼此也比较独立,因此 setUp() 和 tearDown() 写成空实现就够了,甚至你完全可以把它们删掉。如果确实要保留,ObjectPoolTest.cpp 的开头部分可以是这样:
#include "ObjectPoolTest.h"
void ObjectPoolTest::setUp() { }void ObjectPoolTest::tearDown() { }到这里,开始开发 unit test 所需的初始代码就已经齐了。
编写第一个测试
Section titled “编写第一个测试”既然这可能是你第一次接触 Visual C++ Testing Framework,甚至可能是第一次认真接触 unit test,那么第一个 test 就故意写得非常简单:它只测试 0 < 1 是否为真。
一个单独的 unit test,本质上只是 test class 的一个成员函数。要创建这个简单测试,先把它的声明加到 ObjectPoolTest.h 中:
TEST_CLASS(ObjectPoolTest){ public: TEST_CLASS_INITIALIZE(setUp); TEST_CLASS_CLEANUP(tearDown);
TEST_METHOD(testSimple); // Your first test!};testSimple 的实现会用到定义在 Microsoft::VisualStudio::CppUnitTestFramework 命名空间中的 Assert::IsTrue()。这个函数会验证某个表达式是否返回 true;若表达式结果是 false,则该测试失败。Assert 还提供了许多其他辅助函数,例如 AreEqual()、IsNull()、Fail()、ExpectException() 等等。对 testSimple 而言,它只是断言:0 的确小于 1。更新后的 ObjectPoolTest.cpp 如下:
#include "ObjectPoolTest.h"
using namespace Microsoft::VisualStudio::CppUnitTestFramework;
void ObjectPoolTest::setUp() { }void ObjectPoolTest::tearDown() { }
void ObjectPoolTest::testSimple(){ Assert::IsTrue(0 < 1);}就这么简单。当然,大多数 unit test 都会比“做一次简单断言”稍微复杂一点。你很快会发现:常见模式其实就是先执行某种计算,再断言结果等于你预期的值。在 Visual C++ Testing Framework 中,连 exception 处理你都不用操心;框架会自动捕获并汇报它们。
构建并运行测试
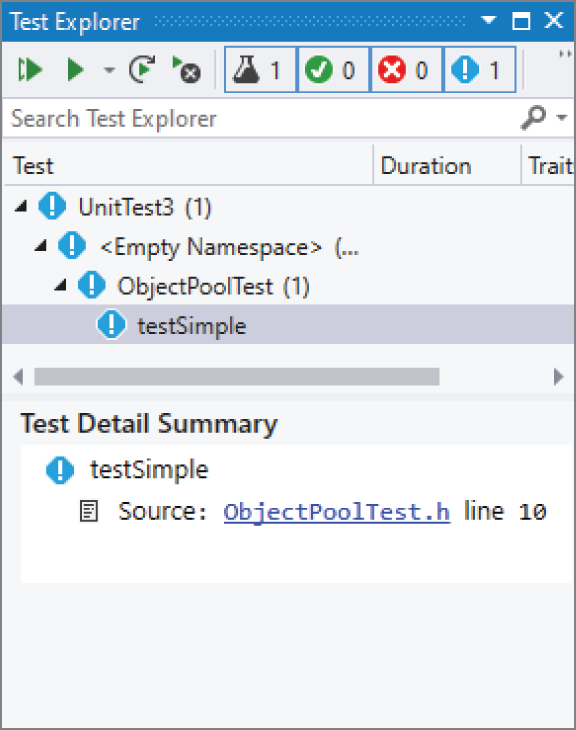
Section titled “构建并运行测试”点击 Build ➪ Build Solution 来构建 solution,然后打开 Test Explorer(Test ➪ Test Explorer),界面如图 30.4 所示。
[^FIGURE 30.4]
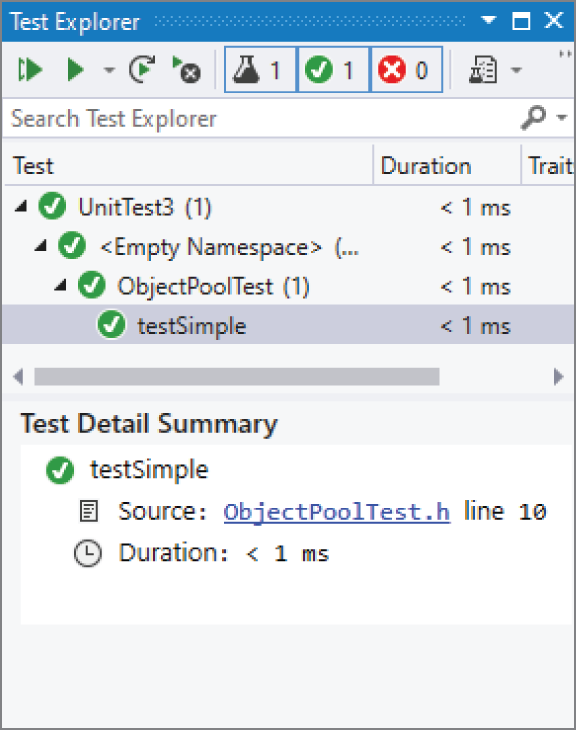
在 solution 构建完成之后,Test Explorer 会自动显示所有已发现的 unit test。此时它会显示 testSimple 这个测试。你可以点击窗口左上角的 Run All Tests 按钮来运行所有测试。运行后,Test Explorer 会显示哪些 unit test 成功、哪些失败。对这个例子来说,唯一的 unit test 会通过,如图 30.5 所示。
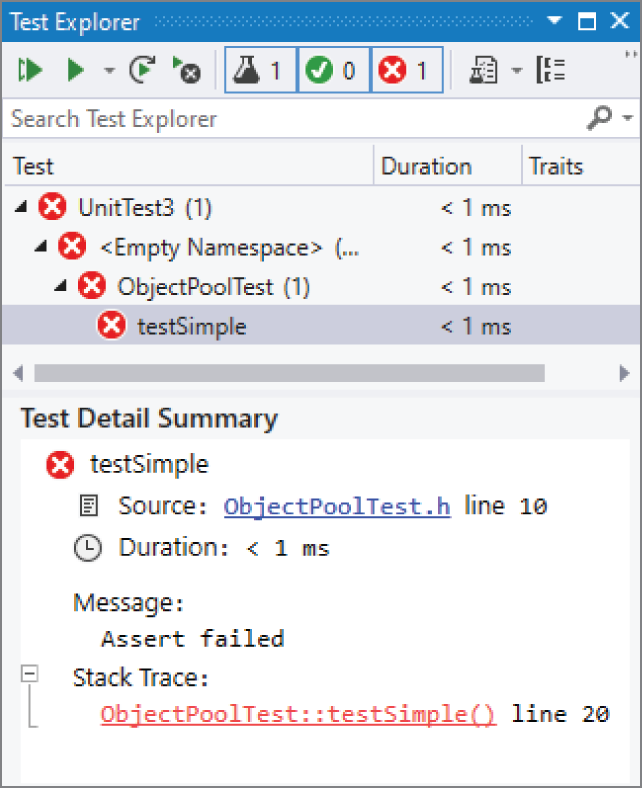
如果你把代码改成断言 1 < 0,那么测试就会失败,而 Test Explorer 会像图 30.6 那样报告失败。
[^FIGURE 30.5]
[^FIGURE 30.6]
Test Explorer 窗口下半部分会显示与当前选中 unit test 相关的有用信息。如果某个 unit test 失败了,它会准确告诉你失败点在哪里。例如,在当前这个例子中,它会指出某个 assertion 失败了。它还会附上一条在失败当时捕获的 stack trace,而且你可以点击其中的超链接,直接跳到出错代码行——这对调试来说非常方便。
你也可以写 negative test——也就是去测试某件“本来就应该失败”的事情。例如,你可以写一个 negative test,验证某个函数确实会抛出预期 exception。Visual C++ Testing Framework 提供了 Assert::ExpectException() 来处理这种场景。下面这个 unit test 使用 ExpectException() 去执行一个抛出 std::invalid_argument 的 lambda expression(std::invalid_argument 定义在 <stdexcept> 中)1。传给 ExpectException() 的模板类型参数,就是你期望捕获到的 exception 类型。
void ObjectPoolTest::testException(){ Assert::ExpectException<std::invalid_argument>( []{ throw std::invalid_argument { "Error" }; });}加入真正的测试
Section titled “加入真正的测试”现在,framework 已经搭好,简单测试也跑通了,是时候真正对 ObjectPool class template 下手,写一点能验证它真实行为的测试了。下面所有这些测试,都会像前面那样,分别添加到 ObjectPoolTest.h 和 ObjectPoolTest.cpp 中。
首先,把 ObjectPool.cppm module interface file 复制到你刚创建的 ObjectPoolTest.h 文件旁边,并把它添加进项目。ObjectPool.cppm 使用了 C++23 功能,而截至本书写作时,这些功能在 Visual C++ 2022 中并未默认开启。要启用它们,请打开项目属性,进入 Configuration Properties ➪ General,把 C++ Language Standard 设为 “Preview - Features from the Latest C++ Working Draft”。在未来版本的 Visual C++ 中,你将能够直接选择 “ISO C++23 Standard”。
在真正写测试之前,你还需要一个辅助类来搭配 ObjectPool 使用。ObjectPool 会创建某种特定类型的 object,并在需要时把它们发给调用方。有些测试需要检查:后来拿到的 object 是否与之前拿到的是同一个。实现这一点的一种简单方式,就是创建一类“带 serial number 的对象”——每个新对象都会拿到一个单调递增的序号。下面这段代码展示了 Serial.cppm module interface file,其中定义了这样的类:
export module serial;
export class Serial{ public: // A new object gets a next serial number. Serial() : m_serialNumber { ms_nextSerial++ } { } unsigned getSerialNumber() const { return m_serialNumber; } private: static inline unsigned ms_nextSerial { 0 }; // The first serial number is 0 unsigned m_serialNumber { 0 };};现在,真正开始写测试。作为最基础的 sanity check,你大概会想先写一个“创建 object pool 本身是否会出问题”的测试。如果对象池创建过程中抛出任何 exception,Visual C++ Testing Framework 会自动报告错误。下面这段测试代码遵循 AAA principle:Arrange、Act、Assert。也就是说,测试先做准备,再执行动作,最后断言结果。这种写法也常被称为 if-when-then principle。我建议你在 unit test 里直接写上以 IF、WHEN 和 THEN 开头的注释,让测试的三个阶段更清楚地显露出来。
void ObjectPoolTest::testCreation(){ // IF nothing
// WHEN creating an ObjectPool ObjectPool<Serial> myPool;
// THEN no exception is thrown}别忘了同时在头文件里加上 TEST_METHOD(testCreation);。后面所有测试也都一样。你还需要在 ObjectPoolTest.cpp 里添加对 object_pool 和 serial module 的 import 声明:
import object_pool;import serial;第二个测试 testAcquire() 会验证一项具体 public 功能:ObjectPool 能否真正发放出 object。这个例子里,断言本身并不复杂。为了证明拿到的 Serial object 合法,测试会断言:它的 serial number 大于或等于 0。
void ObjectPoolTest::testAcquire(){ // IF an ObjectPool has been created for Serial objects ObjectPool<Serial> myPool; // WHEN acquiring an object auto serial { myPool.acquireObject() }; // THEN we get a valid Serial object Assert::IsTrue(serial->getSerialNumber()>= 0);}接下来这个测试就稍微有意思一些了。ObjectPool 不应该两次发出同一个 Serial object。这个测试会通过连续取出一批 object,来验证 ObjectPool 的 exclusivity 性质。所有取出的 Serial 的 serial number 都会被放进一个 set 里。如果 pool 确实一直发出了互不相同的 object,那么这些 serial number 就不应该有任何重复。
void ObjectPoolTest::testExclusivity(){ // IF an ObjectPool has been created for Serial objects ObjectPool<Serial> myPool; // WHEN acquiring several objects from the pool const size_t numberOfObjectsToRetrieve { 20 }; set<unsigned> seenSerialNumbers;
for (size_t i { 0 }; i < numberOfObjectsToRetrieve; ++i) { auto nextSerial { myPool.acquireObject() }; seenSerialNumbers.insert(nextSerial->getSerialNumber()); }
// THEN all retrieved serial numbers are different. Assert::AreEqual(numberOfObjectsToRetrieve, seenSerialNumbers.size());}最后一个(至少目前最后一个)测试,会验证释放功能。也就是说,一旦 object 被归还,ObjectPool 就应当能够再次把它发放出来。在它把所有已释放 object 都 recycle 掉之前,pool 不应无谓地去额外分配新 object。
这个测试会先从 pool 里取出 10 个 Serial object,把它们保存到一个 vector 中以维持存活,并记录每个 Serial 的 raw pointer。等这 10 个对象都取出来后,再把它们统一释放回 pool。
测试第二阶段会再次从 pool 中取出 10 个 object,同样保存到 vector 中保持存活。此时,这些 object 的 raw pointer 都应当已经在第一阶段里见过;这就证明 pool 的对象确实被重用了。
void ObjectPoolTest::testRelease(){ // IF an ObjectPool has been created for Serial objects ObjectPool<Serial> myPool; // AND we acquired and released 10 objects from the pool, while // remembering their raw pointers const size_t numberOfObjectsToRetrieve { 10 }; // A set to remember all raw pointers that have been handed out by the pool. set<Serial*> retrievedSerialPointers; vector<shared_ptr<Serial>> retrievedSerials; for (size_t i { 0 }; i < numberOfObjectsToRetrieve; ++i) { auto object { myPool.acquireObject() }; retrievedSerialPointers.push_back(object.get()); // Add the retrieved Serial to the vector to keep it 'alive'. retrievedSerials.push_back(object); } // Release all objects back to the pool. retrievedSerials.clear();
// The above loop has created 10 Serial objects, with 10 different // addresses, and released all 10 Serial objects back to the pool.
// WHEN again retrieving 10 objects from the pool, and // remembering their raw pointers. set<Serial*> newlyRetrievedSerialPointers; for (size_t i { 0 }; i < numberOfObjectsToRetrieve; ++i) { auto object { myPool.acquireObject() }; newlyRetrievedSerialPointers.push_back(object.get()); // Add the retrieved Serial to the vector to keep it 'alive'. retrievedSerials.push_back(object); } // Release all objects back to the pool. retrievedSerials.clear();
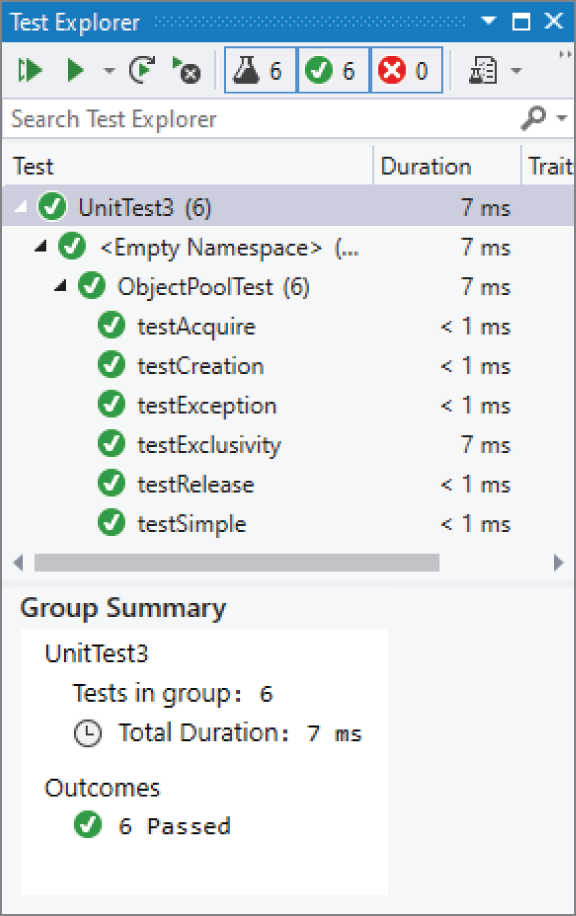
// THEN all addresses of the 10 newly acquired objects must have been // seen already during the first loop of acquiring 10 objects. // This makes sure objects are properly re-used by the pool. Assert::IsTrue(retrievedSerialPointers == newlyRetrievedSerialPointers);}如果你把这些测试都加进去并运行,Test Explorer 应当会长成图 30.7 那样。当然,如果一个或多个测试失败,那你就会撞上 unit testing 中最经典的问题:到底是测试坏了,还是代码坏了?
[^FIGURE 30.7]
Visual C++ Testing Framework 让调试失败中的 unit test 变得很轻松。Test Explorer 会显示测试失败时捕获的 stack trace,其中还包含能直接跳到出错代码行的超链接。
不过,有时直接在 debugger 里跑某个 unit test 仍然会更方便,因为这样你就能在运行期查看变量、逐行单步执行代码,等等。做法也很直接:先在某个 unit test 的代码行上打一个 breakpoint,然后在 Test Explorer 里右键这个 unit test,点击 Debug。testing framework 会在 debugger 中启动所选测试,并在你的 breakpoint 处停下。从那一刻起,你就可以像调普通程序一样调它。
享受单元测试结果带来的成就感
Section titled “享受单元测试结果带来的成就感”前一节那些测试,应该已经足以让你对“如何开始为真实代码编写专业质量的测试”形成一个初步概念。当然,这还只是冰山一角。前面的示例也应当能帮助你继续想到:对 ObjectPool class template,你还能再补哪些额外测试。
例如,你完全可以为 ObjectPool 再加一个 capacity() 成员函数,返回“已借出 object 的数量 + 当前仍可使用、无需再分配新 chunk 的 object 数量”的总和。这和 vector 的 capacity() 很相似——后者返回的是“在不发生重新分配的前提下,vector 总共能容纳的元素数”。有了这样的成员函数后,你就可以再写一个测试,验证:pool 每次扩张时,其容量总是相对于前一次翻倍。
一个给定功能,到底可以写多少 unit test?答案是:没有上限——而这恰恰就是 unit test 最美妙的地方。如果你开始琢磨“代码在某种情况下会怎么反应”,那通常就意味着那里值得写一个 unit test。如果你的 subsystem 某个方面总是在出问题,那就应当提高那个区域的 unit test coverage。即便你只是想暂时把自己放到 client 的位置,看看自己的 class 用起来到底像什么,写 unit test 也仍然是获取不同视角的一种极好方式。你甚至可以在实现代码之前就先把 unit test 写出来。那样一来,你会先于实现本身去使用你规划中的 interface,并因此提前发现一些本来没想到的 use case 或 error condition。
Fuzz testing,也叫 fuzzing,是指使用 fuzzer 自动生成随机输入数据,去轰击某个程序或组件,以尝试找到那些未被妥善处理的 edge case。通常,你需要先给出一份“输入数据应当如何组织”的 recipe,让 fuzzer 知道什么样的数据结构才算可能被目标程序接受。如果你直接给程序塞一坨显然乱七八糟的输入,那它的 parser 多半会第一时间拒绝掉。fuzzer 的工作,正是在这种基础上,尽量生成那些“看起来不明显错误、不会立刻被拒绝,但在程序执行更深层时可能触发错误逻辑”的输入数据。由于 fuzzer 生成的是随机输入,因此为了覆盖尽可能大的输入空间,它往往非常吃资源。一个可行选项,是把 fuzz testing 场景放到 cloud 上跑。实现 fuzz testing 的现成库也有不少,例如 libFuzzer(llvm.org/docs/LibFuzzer.html)和 honggfuzz(github.com/google/honggfuzz)。
更高层级的测试
Section titled “更高层级的测试”尽管 unit test 是抵御 bug 的第一道、也是最重要的一道防线,但它们毕竟只是更大 testing process 的一部分。更高层级的测试,关注的是产品各个部分如何协同工作,而不只是 unit test 那种比较窄、比较局部的视角。从某种意义上说,这类 higher-level test 更难写,因为并没有那么清晰地告诉你“具体要写什么测试”。不过,不真正测试“这些部分如何一起工作”,你其实很难说程序真的能工作。
Integration test 专注于组件交汇的地方。不同于通常只聚焦单个 class 的 unit test,一个 integration test 通常会同时涉及两个或更多 class。integration test 最擅长验证两个 component 之间的交互,而这两个 component 很可能还分别出自两个不同程序员之手。事实上,编写 integration test 这个过程本身,经常就会暴露出设计之间原本隐藏的重要不兼容点。
集成测试示例
Section titled “集成测试示例”并不存在一套死板规则,告诉你“到底该写哪些 integration test”,所以一些具体例子会更有帮助。下面这些场景展示了 integration test 何时是合适的做法。当然,它们并没有涵盖所有可能情形。和 unit test 一样,随着经验增加,你会逐渐形成对“哪些 integration test 真有价值”的直觉。
基于 JSON 的文件序列化器
Section titled “基于 JSON 的文件序列化器”假设你的项目中有一层 persistence layer,负责把某些类型的 object 保存到磁盘,再从磁盘中读取回来。如今一个很自然的序列化方式,是使用 JSON 格式,于是比较合理的组件划分可能是:一个 JSON 转换层,坐在你自定义的 file API 之上。这两个组件本身都可以被彻底做 unit test:JSON 层可以验证“不同类型 object 是否被正确转换为 JSON、又是否能从 JSON 正确还原”;file API 则可以测试磁盘上文件的读、写、更新和删除。
而当这两个 module 开始一起工作时,integration test 就变得合适了。至少,你应该有一个 integration test:通过 JSON 层把 object 存到磁盘,再读回来,然后和原对象做比较。因为这个测试同时覆盖了两个 module,所以它就是一个最基础的 integration test。
共享资源的读写方
Section titled “共享资源的读写方”再想象一个程序:其中有一份由多个 component 共享的数据结构。比如,一个股票交易程序里可能有一个买卖请求队列。负责接收交易请求的 component 会把订单放进队列,而负责真正执行交易的 component 则会从队列中取数据。你当然可以把 queue class 本身测得很彻底;但在它真正和未来会使用它的那些 component 组合起来之前,你其实并不能确定:自己当初的某些假设是否完全正确。
因此,一个好的 integration test 应该把“股票请求组件”和“股票交易组件”都当作 queue class 的 client。你可以构造一些示例订单,验证它们确实能通过这些 client component 顺利进入队列、再顺利离开队列。
第三方库的包装层
Section titled “第三方库的包装层”integration test 不一定非得只发生在你自己代码的集成点上。很多时候,integration test 是用来验证“你的代码与某个 third-party library 之间的交互”的。
例如,你可能在使用某个数据库连接库与 relational database system 通信。假设你又在这个库外面包了一层 object-oriented wrapper,加入了 connection caching,或者提供了更友好的 interface。这显然是一个非常值得测试的重要 integration point,因为 wrapper 虽然通常让数据库操作更好用,但它也同时带来了误用底层库的可能。
换句话说,写 wrapper 本身当然是件好事;但如果你写出来的 wrapper 反而引入 bug,那就会非常糟糕。
集成测试技术
Section titled “集成测试技术”说到真正落笔写 integration test,你很快会发现 unit test 与 integration test 之间其实有一条很细的边界。一个 unit test 只要稍微改一下,开始接触另一个 component,它是不是就突然变成 integration test 了?从某种意义上说,这个问题其实没那么重要——因为只要测试写得好,它就是好测试,不论它最终被归类为什么。我的建议是:把 unit testing 和 integration testing 当作两种视角来理解,而不要执着于给每一个测试都精确贴上标签。
在实现层面,integration test 也常常直接使用 unit testing framework 来写,这也进一步模糊了它们的边界。毕竟,unit testing framework 最擅长的事,就是让你轻松写出某种“是/否”判断型测试,并输出清晰结果。从 framework 的角度看,测试的是“单个功能单元”,还是“两个组件交汇处”,其实差别并不大。
不过,出于 performance 或组织管理上的原因,你有时仍然会希望把 unit test 与 integration test 分开。例如,你的团队可能会规定:每个人 check in 代码前都必须跑 integration test,但对一些与当前改动无关的 unit test 则可以稍微宽松一点。把这两类测试分开,也会让结果更有价值。如果某次失败发生在 JSON class 的 unit test 中,那么你就能比较确定:问题出在这个 class 本身,而不是它与 file API 的交互上。
System test 的层级甚至比 integration test 还更高。这类测试关注的是整个程序,而不是某个局部交汇点。system test 往往会引入 virtual user 来模拟人类用户与程序的交互。当然,这个 virtual user 本身也必须通过脚本来描述动作序列。也有些 system test 依赖脚本或一组固定的输入与预期输出。
和 unit test、integration test 一样,每个独立的 system test 都是:执行一项特定测试,并期待一个特定结果。system test 很常被用来验证“多个 feature 一起使用时是否正常工作”。
理论上,一个被完整 system-tested 的程序,应该对每个 feature 的每一种排列组合都至少有一个 test。但这种方式会迅速膨胀到不可维护。不过,即便如此,你仍然应尽量测试“多个 feature 联合使用”的情形。例如,一个图形程序完全可以有这样的 system test:导入一张图像、旋转它、对它做 blur filter、把它转换为 black and white,然后保存。该测试再把保存结果与一份“预期输出图像文件”做比对。
不幸的是,关于 system test,几乎没有多少“对所有应用都成立”的规则,因为它们高度依赖实际应用类型。对于那些只处理文件、几乎没有用户交互的程序,system test 可能会写得很像 unit test 或 integration test;对图形程序来说,virtual user 方式可能更合适;对 server application,则往往需要先构造 stub client 去模拟网络流量。最重要的是:你测试的必须是程序的真实使用方式,而不只是它的某一个局部零件。
Regression testing 更像是一种测试理念,而不是某一类特定测试。它的核心思想是:一旦某个 feature 工作正常,开发者往往就会把它放在一边,默认它今后会一直保持正常。但现实是,新的 feature 与其他代码改动,常常会联手把原本工作的功能弄坏。
因此,regression test 经常会被放进系统中,作为那些“基本已经完成并正常工作”的 feature 的 sanity check。只要 regression test 写得足够好,一旦后续某次修改破坏了该 feature,它就会立刻停止通过。
如果你的公司拥有一整支 QA 大军,那么 regression testing 可能会更多体现为手工测试。测试人员会像真实用户那样,一步步走完整个流程,逐渐验证上一个 release 中那些已经工作的 feature 是否仍然可用。这种做法如果执行得足够仔细,会非常可靠,但显然不够 scalable。
而在另一个极端,你也可以构建一套完全自动化系统,让 virtual user 执行每一个功能。当然,这对脚本编写能力会提出很高要求,不过市面上已经有不少商业和非商业软件包,可以帮助你对不同类型 application 进行脚本化测试。
介于两者之间的一种折中方案,叫 smoke testing。这类测试通常只覆盖那一小部分“最关键、最基本、必须工作”的 feature。它的思路是:如果哪里坏了,它应该立刻就能冒烟显现出来。一旦 smoke test 通过,接下来就可以继续做更彻底的手工测试或自动化测试。Smoke testing 这个词其实很老,最早来自电子工程。电路板焊好之后,工程师最先想知道的是:“这玩意儿装对了吗?”当时一个朴素办法就是:“插电,开机,看看会不会冒烟。”如果真冒烟了,那要么 design 有问题,要么装配有问题;通过看哪个部件冒烟,就能缩小错误位置。
有些 bug 就像噩梦:既可怕,又反复出现。Recurring bug 既令人沮丧,也是对工程资源的低效消耗。为了防止 bug 一次次重现,你应当在修掉 bug 之后,为它补上 regression test。这样做既能证明该 bug 的确已被修复,又能建立一个报警器:如果它将来再次出现——例如你的改动被回滚,或者被别的改动意外覆盖,或者两个 branch 在 merge 到主干时处理不当——这个 regression test 就会立刻失败。一旦某个“曾修复过”的 bug 的 regression test 重新失败,通常也更容易修,因为测试本身可以直接引用原始 bug 编号,并说明它第一次是如何被修掉的。
成功测试的建议
Section titled “成功测试的建议”作为 software engineer,你在 testing 中的角色可能介于“只负责基础 unit testing”到“完整管理一套自动化测试系统”之间。正因为 testing 的角色和风格差异很大,下面这些来自我个人经验的建议,也许会在不同测试场景下对你有所帮助:
- 花一些时间认真设计你的自动化测试系统。一个整天持续运行的系统,能非常快地发现失败。一个会自动给工程师发邮件、或者在房间中央高声播放 show tune 来宣布失败的系统,会显著提高问题的可见性。
- 别忘了做 stress testing。即使数据库访问类的整套 unit test 全绿,它也可能在几十个线程同时使用时当场垮掉。你应当在产品可能遭遇的最极端真实条件下测试它。
- 尽量在多种平台上测试,或者至少在一个与客户系统足够接近的平台上测试。多平台测试的一种常见技巧,是使用 virtual machine 环境,在同一台物理机器上同时跑多个不同平台。
- 有些测试可以故意注入 fault。例如,你可以写一个测试,让文件在被读取时突然被删除,或者在一次网络操作过程中模拟网络中断。
- bug 与测试是高度相关的。bug fix 应当通过 regression test 来证明,而测试中的注释也可以直接引用原始 bug 编号。
- 不要删除那些正在失败的测试。当某位同事正为了修 bug 焦头烂额时,如果他发现你把测试删了,他一定会来找你算账。
我能给你的最重要建议就是:始终记住,testing 本身就是软件开发的一部分。如果你在开始 coding 之前就已经接受这一点,那么当 feature 完成时,你就不会再因为“原来后面还有这么多活要做,才能证明它真的能工作”而感到措手不及。
本章覆盖了所有专业程序员都应掌握的 testing 基本知识。尤其是 unit testing,它是提升自己代码质量最简单、也最有效的手段之一。更高层级的测试则覆盖 use case、module 之间的协同关系,以及对 regression 的防护。无论你在 testing 方面承担怎样的角色,本章之后,你都应该能够更有把握地设计、编写和评审不同层级的测试。
现在,你已经知道如何找出 bug;下一步,就是学习如何真正把它们修掉。为此,第 31 章“调试攻坚”会介绍有效 debugging 的技巧与策略。
通过完成下面这些练习,你可以巩固本章讨论的内容。所有练习的参考解答都包含在本书网站 www.wiley.com/go/proc++6e 提供的代码下载包中。不过,如果你在某道题上卡住了,建议先回过头重读本章相关部分,尽量自己找到答案,再去看网站上的解答。
-
练习 30-1: testing 的三种类型分别是什么?
-
练习 30-2: 请为下面这段代码,列出你能想到的一组 unit test:
export class Foo{public:// Constructs a Foo. Throws invalid_argument if a >= b.explicit Foo(int a, int b) : m_a { a }, m_b { b }{if (a >= b) {throw std::invalid_argument { "a should be less than b." };}}int getA() const { return m_a; }int getB() const { return m_b; }private:int m_a { 0 };int m_b { 0 };}; -
练习 30-3: 如果你使用的是 Visual C++,请把你在练习 30-2 中列出的 unit test,使用 Visual C++ Testing Framework 实现出来。
-
练习 30-4: 假设你写了一个函数,用来计算 factorial。一个数 n 的 factorial,写作 n !,表示从 1 到 n 的连乘。例如,3! = 1×2×3。你决定遵循本章建议,为代码编写 unit test。于是你先运行代码来计算 10!,得到结果 36288000。接着你写了一个 unit test,验证“当要求计算 10 的 factorial 时,代码会返回 36288000”。你如何评价这样的 unit test?
Footnotes
Section titled “Footnotes”-
在本书写作时,Visual C++ 2022 存在一个 bug:它无法同时处理
#include <CppUnitTest.h>和import std;。作为 workaround,应把import std;改成针对所需 header 的#include,例如#include <stdexcept>。至于不同 source file 所需的完整 header 列表,请参考下载源码包。 ↩